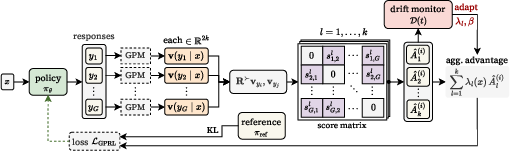
General Preference Reinforcement Learning
Abstract: Post-training has split LLM alignment into two largely disconnected tracks. Online reinforcement learning (RL) with verifiable rewards drives emergent reasoning on math and code but depends on a programmatic verifier that cannot reach open-ended tasks, while preference optimization handles open-ended generation yet forgoes the continuous exploration that powers online RL. Closing this gap requires a verifier for open-ended quality, but a scalar reward model is the wrong shape for the job. Quality is multi-dimensional, and any scalar score is an incomplete proxy that lets online RL collapse onto whichever axis the score is most sensitive to. We turn instead to the General Preference Model (GPM), which embeds responses into $k$ skew-symmetric subspaces and represents preference as a structured, intransitivity-aware comparison. Building on this, we propose General Preference Reinforcement Learning (GPRL), which carries the $k$-way structure through to the policy update. GPRL computes per-dimension group-relative advantages, normalizes each on its own scale so no axis can dominate, and aggregates them with context-dependent eigenvalues. The same structure powers a closed-loop drift monitor that detects single-axis exploitation and corrects it on the fly by reweighting dimensions and tightening the trust region. Starting from $\texttt{Llama-3-8B-Instruct}$, GPRL reaches a length-controlled win rate of $56.51\%$ on AlpacaEval~2.0 while also outperforming SimPO and SPPO on Arena-Hard, MT-Bench, and WildBench by resisting reward hacking across extended training runs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
General Preference Reinforcement Learning — A Simple Explanation
What is this paper about?
This paper is about teaching LLMs to give better, more human-friendly answers. The authors argue that most current training methods either:
- work great for problems with a clear right/wrong answer (like math or code with tests), or
- work for open-ended tasks (like writing or advice) but can be gamed or drift off course during training.
They introduce a new method called General Preference Reinforcement Learning (GPRL) that aims to combine the best of both worlds: keep exploring and improving online (like reinforcement learning) while respecting the many different qualities humans care about (like helpfulness, honesty, safety, clarity, and style).
What questions are they trying to answer?
- How can we train LLMs for open-ended tasks (no single right answer) without them “gaming the system”?
- Can we represent human preferences as many qualities at once instead of one single score?
- Can we automatically detect and stop “reward hacking” (when the model improves a score in a sneaky way that hurts overall quality) during training?
How do they do it? (Methods in everyday language)
Think of judging an answer like grading a report card with multiple subjects:
- Old way: give one overall grade (a single score). The problem? The model can “raise the average” by over-focusing on one subject (like writing longer answers) while ignoring others (like truthfulness).
- New way: give grades in several subjects at once (many dimensions), then combine them fairly.
Here’s the main idea:
- A multi-skill judge (GPM): The authors use a “General Preference Model” (GPM) that compares two answers and scores them across several hidden “quality axes” (like sliders on a mixing board). It can handle tricky human preferences, including rock-paper-scissors-like cycles (A is better than B, B better than C, yet C better than A).
- Group comparison: For each question, they ask the model to generate several answers. The GPM compares each answer to the others along each quality axis.
- Fair balancing: Each axis is normalized on its own scale (so one axis can’t dominate just because its numbers are larger). Then the axes are combined using context-based weights (some qualities matter more for some questions).
- Online improvement (policy update): They use a standard reinforcement learning step (a safe, clipped update) guided by this balanced, multi-axis signal. You can think of it as telling the model, “Improve in the directions that are helpful across many qualities, not just one.”
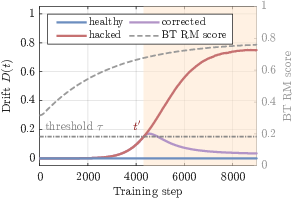
- Drift monitor (anti-hacking safety): During training, they watch which axis is getting most of the attention. If one axis starts to overwhelm the others (for example, the model keeps making responses longer to win the judge), the method:
- lowers the weight of that axis, and
- tightens a “safety leash” (limits how fast the model can change). This nudges training back toward a healthy balance.
Key analogies for tricky terms:
- Multi-dimensional preferences: like a report card with multiple subjects instead of one overall grade.
- Intransitive preferences: like rock-paper-scissors—there isn’t a single best choice for everything.
- Normalization per dimension: scoring each subject on a fair scale so none can drown out the others.
- KL trust region (safety leash): a setting that stops the model from changing too much in one step.
What did they find, and why does it matter?
The authors tested GPRL starting from Llama-3-8B-Instruct and compared it to popular methods on open-ended benchmarks. Highlights:
- Stronger results on open-ended tasks: GPRL beat other methods on AlpacaEval 2.0 (length-controlled win rate 56.51%), Arena-Hard, MT-Bench, and WildBench.
- Less “reward hacking”: Unlike single-score training, GPRL didn’t drift into easy shortcuts (like endlessly longer answers) to cheat the judge. In fact, it got higher scores while keeping answers relatively shorter and more balanced.
- Stable training over time: GPRL kept improving and stayed stable over longer training runs, thanks to the drift monitor and rebalancing controller.
- Better on reasoning-heavy categories: It showed especially strong gains in math/coding-style tasks where structure and correctness matter, not just style.
Why it matters: Open-ended tasks are what most people want from AI (helpful, honest, safe, clear, and concise answers). Using many “quality axes” together makes it harder for the model to game one trick and easier to guide it toward overall good behavior.
What could this change in the future?
- Safer, more reliable AI: By balancing many qualities at once and correcting drift automatically, GPRL can help produce models that behave well over long training runs.
- Better generalization: The method doesn’t need a rigid “right/wrong” checker (like unit tests); it can handle open-ended tasks where taste, context, and trade-offs matter.
- A broader lesson: The authors argue that the “shape” of the training signal (multi-dimensional vs. single number) is as important as the strength of that signal. This idea may help in other areas where we use learned proxies instead of perfect measurements.
In short: GPRL is like giving a model a fair, multi-subject report card, watching for signs it’s over-focusing on one subject, and gently steering it back—so it learns to be well-rounded, not just good at gaming the grade.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address:
- Theory: No convergence or stability guarantees for the closed-loop GPRL dynamics (policy update + variance-profile controller). Provide conditions on controller hyperparameters (e.g., τ, γ, κ, δ) under which oscillations are ruled out and training converges or remains bounded.
- Theory: The “single-axis hacking” result gives only a sufficient condition; no characterization of when the condition holds with high probability under realistic rollout distributions, nor extensions to multi-axis or more subtle exploitation patterns.
- Theory: Unanalyzed interaction between per-dimension normalization and the GRPO clipping surrogate. Quantify bias/variance changes in the policy gradient and provide guidelines for safe normalization/clipping ranges.
- Identifiability/interpretability: No method to map GPM subspaces to human-interpretable facets (e.g., helpfulness, factuality, safety). Develop diagnostics to identify, name, and validate each axis and detect subspace entanglement.
- Model selection: No principled procedure to choose k (number of subspaces) per corpus or per prompt. Explore data-driven selection (e.g., information criteria, rank tests, sparsity) or adaptive per-prompt k.
- Weighting robustness: The learned eigenvalue gate is treated as a black box; no ablation of its stability, sensitivity, or vulnerability to gaming. Analyze failure modes where eigenvalues saturate or collapse and how the controller interacts with such behavior.
- Controller target: Drift control centers the variance profile around its initialization α0, which may reflect a suboptimal or biased baseline. Investigate alternative targets (e.g., human-validated profiles, moving averages, trust-region schedules per axis) and their impact.
- Hyperparameter sensitivity: Limited guidance on τ, γ, κ, δ, ε, and KL schedules. Provide robust tuning heuristics, adaptive rules (e.g., PID-style control, Bayesian optimization), and stress tests across datasets/models.
- Granularity of control: Dimensional multipliers m_l(t) are global (shared across prompts). Explore prompt- or domain-conditional control (context-aware reweighting) to avoid over-penalizing axes that legitimately dominate in certain contexts.
- Frozen reward model: GPM is not updated online, risking reward-model staleness as the policy distribution shifts. Study co-training, active preference collection, or confidence-weighted updates that mitigate non-stationarity without inducing co-adaptation/hacking.
- Data requirements: Unclear data sufficiency for reliably learning k subspaces (pairwise preference coverage, diversity, intransitivity frequency). Specify minimal sample complexity and data collection protocols that elicit distinct axes.
- Generalization: Results use one base policy (Llama-3-8B-Instruct), one reward-model corpus (Skywork-Reward), and one rollout corpus (UltraFeedback). Evaluate across stronger/weaker bases (e.g., 70B), multilingual settings, domain-specialized prompts, and long-context tasks.
- Missing baselines: No empirical comparison with multi-objective RLHF variants (e.g., Rewarded Soups, MODPO) or robust scalar-RM approaches (e.g., RM ensembles, RM regularization, debate/oversight). Benchmark head-to-head to isolate improvements due to structure vs training regime.
- Hybrid rewards: Unexplored combination of GPM with programmatic verifiers (RLVR) or other structured signals (e.g., fact-checkers, safety classifiers) as additional subspaces or constraints. Assess complementarity and conflict resolution among reward sources.
- Human evaluation: Heavy reliance on LLM judges with known biases and limited LC correction. Add blinded human ratings, cross-judge consistency checks (e.g., Claude, GPT-4o, Gemini), and bias audits (length, verbosity, politeness, style conformity).
- Safety/factuality auditing: No targeted safety, hallucination, or toxicity evaluation. Introduce dedicated safety suites and factuality probes; measure whether drift control inadvertently downweights safety under performance pressure.
- Adversarial robustness: No tests for sycophancy, prompt injection, or targeted exploitation that manipulates the variance profile (e.g., artificially inflating one axis). Design adversarial suites to probe the controller’s failure modes.
- Token-level credit assignment: The method is sequence-level; no exploration of token-level per-dimension advantages or value functions for finer credit assignment. Study whether token-level shaping improves stability and sample efficiency.
- Reference policy choice: The impact of the reference policy π_ref (fixed vs moving, EMA vs base) on stability and drift is unstudied. Provide ablations and guidance for selecting and scheduling π_ref.
- Sigma-zero handling: When σ_l(x) = 0, per-dimension advantages are zeroed, potentially stalling learning on that axis and biasing αt. Quantify frequency, propose smoothing/regularization, and analyze training impacts.
- Group size vs reliability: While G = 8 works empirically, there is no theoretical or empirical curve linking group size to reliable variance-profile estimation and control effectiveness. Provide sample complexity analyses and adaptive G selection.
- Compute and throughput: The overhead and scaling behavior of adding a GPM forward pass and drift controller are not measured. Report wall-clock, GPU memory, and throughput vs. baseline GRPO across model sizes and rollout lengths.
- Diversity and mode collapse: No analysis of response diversity under multi-dimensional control. Track entropy, n-gram diversity, and topical coverage to ensure axes balancing does not induce homogenization.
- Intransitivity in practice: Although GPM models intransitive preferences, there is no empirical evidence that real intransitivity is present or beneficial. Construct datasets with known cycles and measure whether GPRL exploits them constructively.
- Fairness/bias: No audits for demographic or topical biases per axis or after reweighting. Evaluate fairness impacts and whether the controller unintentionally amplifies unfair dimensions present in the reward model.
- Length dynamics beyond AlpacaEval: The length-variance interplay is central to claims but is only quantified on AlpacaEval. Analyze length vs quality across other benchmarks and under hard caps to verify the mechanism is general.
- Initialization dependence: Drift metrics and controller behavior depend on the initial variance profile. Study sensitivity to different initial policies and whether “better” initializations reduce or exacerbate drift interventions.
- Reproducibility: Implementation details (e.g., eigenvalue gate architecture, training seeds, code) are not provided. Release code, checkpoints, and evaluation scripts to validate results and encourage adoption.
Practical Applications
Immediate Applications
These applications can be deployed now with modest engineering effort, leveraging the paper’s GPRL training recipe, per-dimension advantages, and drift monitoring within existing post-training infrastructure (e.g., TRL, vLLM, distributed RL).
- LLM post-training pipelines (software/AI infrastructure)
- Use GPRL in place of scalar-RM PPO/GRPO to reduce reward hacking (e.g., verbosity drift) while improving open-ended quality. Drop-in integration with existing rollout infrastructure; monitor the per-dimension variance profile to catch and correct axis exploitation in real time.
- Tools/workflows: “GPRL Trainer” plugin for TRL/TRLX/DeepSpeed; a frozen GPM “Reward Server”; drift-monitor dashboards (variance profile, KL-to-initial-profile); controller config (τ, γ, κ) packs.
- Dependencies/assumptions: Availability of a trained GPM with meaningful axes; adequate compute for online RL; preference data quality (multi-faceted supervision like Skywork-Reward or in-house labels).
- Customer support assistants and chatbots (software, customer service)
- Fine-tune assistants to balance helpfulness, concision, tone, and safety without collapsing onto stylistic axes (e.g., longer = better). Per-prompt eigenvalue weighting aligns to context (e.g., troubleshooting vs. policy explanation).
- Tools/workflows: Domain GPM (axes: helpfulness, factuality, tone, safety); GPRL training on real ticket logs; production drift alarms to flag single-axis exploitation.
- Dependencies/assumptions: Axis definitions that reflect business KPIs; consented and de-identified logs; human QA loops for early-stage monitoring.
- Coding assistants and developer documentation (software/engineering)
- Balance correctness, security, readability, and brevity for open-ended code tasks (design, docstrings, explanations) where verifiers are incomplete. Combine verifiers (unit tests) for correctness with GPM axes for non-verifiable quality (style).
- Tools/workflows: Hybrid reward aggregator (verifier + GPM); CI-integrated drift monitor to prevent over-optimization on “verbose explanations” or “overly strict linting.”
- Dependencies/assumptions: Partial programmatic verifiers; domain-specific GPM calibrated on code reviews and style guides.
- Enterprise summarization, email drafting, and knowledge management (software/productivity)
- Train models to produce concise, complete, and neutral summaries without length inflation or style gaming; per-dimension normalization keeps brevity and fidelity in balance.
- Tools/workflows: Internal GPM axes (brevity, completeness, neutrality); GPRL fine-tunes on enterprise corpora; length-aware evaluation harness (LC metrics).
- Dependencies/assumptions: Secure data pipelines; information governance; staff-annotated multi-attribute preferences for internal style.
- Education tutoring systems (education)
- Align tutors on rigor, encouragement, clarity, and concision per topic. Use context-dependent eigenvalues to adjust axes for student proficiency or task type (proof vs. summary).
- Tools/workflows: Curriculum-specific GPM; GPRL on tutoring dialogues; per-student axis profiles for cohorts (without personal data if not available).
- Dependencies/assumptions: Curated multi-attribute educational judgments; safeguarding/ethics reviews; teacher-in-the-loop validation.
- Healthcare information and triage assistants (healthcare)
- Balance factual accuracy, safety/compliance, empathy, and clarity for informational tasks (not diagnosis). The drift controller prevents over-optimization on empathy or verbosity at the expense of accuracy.
- Tools/workflows: Medical-domain GPM (axes include safety and factuality); GPRL training with clinical editing guidelines; red-team drift reports for risk committees.
- Dependencies/assumptions: Expert-curated, domain-labeled preferences; institutional approvals; disclaimers and routing for human oversight.
- Financial and legal advisory assistants (finance, legal services)
- Balance helpfulness, clarity, and compliance/risk disclaimers; resist persuasive but non-compliant outputs by reweighting axis variance when drift is detected.
- Tools/workflows: Compliance-focused GPM; GPRL on internal advisory scripts; per-policy axis gates configured by compliance officers.
- Dependencies/assumptions: Up-to-date policy/rule corpora; legal review; audit logging.
- Content moderation and safety tuning (platform safety)
- Train multi-dimensional moderation models that optimize across harmlessness, fairness, and helpfulness (e.g., avoid both under- and over-filtering). Drift monitor alerts on over-suppression or leniency.
- Tools/workflows: Safety GPM (toxicity, contextual nuance, fairness); GPRL on policy-violation and edge-case datasets; controller thresholds integrated with policy dashboards.
- Dependencies/assumptions: High-quality, calibrated safety labels; fairness governance; clear escalation paths.
- Model evaluation and audit (industry/academia)
- Use the variance-profile drift metric as an online KPI for reward-hacking risk; compare axis balance across model versions; set “variance budgets” as guardrails.
- Tools/workflows: GPRL drift monitor as an MLOps service; periodic reports in model cards (axis weights, drift over time).
- Dependencies/assumptions: Baseline profile selection and version control; governance alignment on thresholds.
- Alignment research and curriculum (academia)
- Study intransitive human preferences and multi-axial alignment by training/ablation on the k-subspace structure; analyze emergent reasoning under online RL with structured rewards.
- Tools/workflows: Open-sourced GPRL training setups; ablation suites (k, normalization modes, controller on/off); per-category benchmarks and length-controlled metrics.
- Dependencies/assumptions: Compute access; reproducible datasets; community baselines for GPMs.
Long-Term Applications
These applications require additional research, data, scaling, or regulatory groundwork before wide deployment.
- Personalized and context-aware alignment at inference time (software, consumer AI)
- Dynamically tailor eigenvalue weights per user/session (e.g., concise mode vs. exploratory mode) and per task (brainstorming vs. compliance). Real-time controllers adjust axis weights to user preferences without retraining.
- Tools/workflows: Lightweight on-device GPM heads; preference sliders; policy-side controllers with rapid reweighting APIs.
- Dependencies/assumptions: Fast per-prompt GPM inference; privacy-preserving preference storage; UX validation; safeguards to avoid undesirable personalization.
- Multimodal and embodied agents (robotics, autonomous systems)
- Extend GPM/GPRL to vision, speech, and action, balancing safety, comfort, speed, and task success with intransitive human preferences. Closed-loop drift control prevents single-axis optimization (e.g., speed over safety).
- Tools/workflows: Multimodal GPMs; sim-to-real pipelines with human preference feedback; safety cones integrated with controllers.
- Dependencies/assumptions: Rich multimodal preference datasets; safety assurance frameworks; real-world evaluation protocols.
- Hybrid verifier + preference RL for complex tasks (software, scientific/technical domains)
- Combine programmatic verifiers (math/code tests) with GPM axes (style, clarity, pedagogy) in a single aggregation and controller loop for holistic optimization on complex outputs.
- Tools/workflows: Unified reward router and aggregator; axis-aware GRPO with modular verifier adapters.
- Dependencies/assumptions: Coverage gaps in verifiers acknowledged; calibrated fusion of heterogeneous signals; robust conflict resolution policies.
- Sector-specific multi-dimensional datasets and standards (policy, industry consortia)
- Establish taxonomies and benchmarks of axes per sector (healthcare: safety, factuality, empathy; finance: compliance, clarity, helpfulness), with shared GPM checkpoints and metrics.
- Tools/workflows: Annotation standards and labeler training; public leaderboards tracking per-axis performance and drift.
- Dependencies/assumptions: Cross-organization coordination; funding for high-quality labels; legal frameworks for data sharing.
- Safety-critical deployments with formal guarantees (healthcare, aviation, critical infrastructure)
- Develop controllers with stability/convergence guarantees and certify axis-weight trajectories under worst-case drifts; integrate into assurance cases for regulated settings.
- Tools/workflows: Verified controller designs; formal monitoring; audit-ready logs of λ-weights and multipliers.
- Dependencies/assumptions: Theoretical advances in closed-loop RL stability; regulatory acceptance; extensive testing.
- Fairness and bias mitigation via axis-aware control (policy, platforms)
- Use axes related to fairness/equity and apply drift monitors to prevent over-optimization on aggregate performance that harms subgroups. Dynamically reweight axes in deployment as bias signals emerge.
- Tools/workflows: Fairness GPM components; demographically-aware (or proxy) evaluation pipelines; intervention playbooks.
- Dependencies/assumptions: Ethical use of sensitive attributes or validated proxies; governance for reweighting decisions; stakeholder oversight.
- Continual/online learning at production scale (MLOps)
- Run GPRL in always-on training regimes with canarying and dimension “budgets,” turning drift signals into automated rollback/slowdown decisions.
- Tools/workflows: Canary deployments with axis KPIs; automated controller parameter tuning; incident runbooks for axis spikes.
- Dependencies/assumptions: Robust data and model versioning; strong observability; resilient rollback paths.
- On-device/edge alignment for small models (mobile, embedded)
- Distill GPM and GPRL-trained policies into compact models that retain axis structure; provide local controllers to maintain balance offline.
- Tools/workflows: Axis-preserving distillation; quantization-aware preference embeddings; mobile-friendly monitoring.
- Dependencies/assumptions: Efficient GPM approximation; acceptable accuracy/latency trade-offs; memory constraints.
- Search, recommendation, and ranking beyond scalar proxies (consumer platforms)
- Replace single-metric proxies (clicks) with multi-dimensional preference embeddings reflecting long-term satisfaction, diversity, and well-being; resist exploitation of a single behavioral signal.
- Tools/workflows: Pairwise preference logging and embedding; online reweighting controllers; cohort-specific axis profiles.
- Dependencies/assumptions: Robust feedback elicitation; prevention of metric gaming; privacy protections.
- Scientific and technical writing assistants (R&D, publishing)
- Balance rigor, concision, citation fidelity, and accessibility; control drift away from factual density toward persuasive style.
- Tools/workflows: Domain GPM axes (rigor, citation accuracy, clarity); hybrid verifier hooks (citation checks) + GPM.
- Dependencies/assumptions: Curated datasets with per-attribute labels; citation-verification tools; editorial policies.
- Energy and industrial operations assistants (energy, manufacturing)
- Generate procedures and reports that balance safety, efficiency, and regulatory compliance; avoid optimizing for expedience at the expense of safety.
- Tools/workflows: Sector GPM; integration with SOP databases and compliance checklists; controller thresholds tied to safety KPIs.
- Dependencies/assumptions: High-stakes domain labeling; alignment with HSE (Health, Safety, Environment) policies; rigorous testing.
Notes on feasibility across items:
- Core dependency: a well-trained GPM reflecting the target axes; otherwise, GPRL faithfully optimizes whatever the GPM encodes, including its biases.
- Controller stability: parameter choices (τ, γ, κ) affect dynamics; additional tuning or theoretical guarantees may be required for safety-critical contexts.
- Data: multi-attribute preference labeling is costlier than scalar wins; taxonomy design and annotator training are critical.
- Compute: online RL with multiple generations per prompt and GPM inference adds cost; batching and model serving optimizations mitigate this.
Glossary
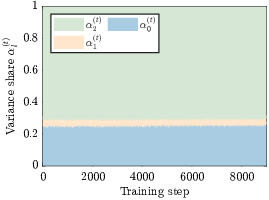
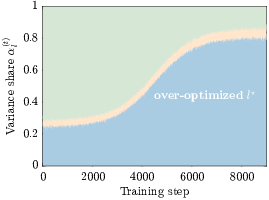
- advantage variance profile: The distribution of variance across preference dimensions used to detect drift during training. "flags reward hacking from the shape of the advantage variance profile"
- aggregate advantage: The single combined advantage obtained by weighting and summing per-dimension advantages. "The aggregate advantage of Eq.~\eqref{eq:gprl_advantage} acts as a lever the policy gradient pulls on"
- binary verifier: A programmatic checker that returns a 0/1 reward indicating correctness. "In RLVR~\citep{guo2025deepseek,zhang2025extending}, is a binary verifier that checks correctness"
- block-diagonal skew-symmetric operator: A matrix composed of 2×2 skew-symmetric blocks used to score pairwise preferences across subspaces. "computes preferences with a block-diagonal skew-symmetric operator on independent two-dimensional subspaces"
- Bradley-Terry (BT) model: A classic scalar model of pairwise preferences where win probabilities depend on score differences. "The BT model~\citep{bradley1952rank} sets "
- constant-sum two-player game: A game-theoretic formulation where one model’s preference gain equals the other’s loss. "the resulting preference probabilities define a constant-sum two-player game"
- context-dependent eigenvalues: Prompt-specific weights that scale each preference subspace when aggregating scores. "aggregates across subspaces with context-dependent eigenvalues"
- critic-free variant: An RL method that avoids learning a value function by using group-based normalization. "GRPO~\citep{shao2024deepseekmath} is a critic-free variant of PPO"
- Direct Preference Optimization (DPO): An offline alignment method that optimizes a model directly from preference pairs without an explicit reward model. "Offline methods such as Direct Preference Optimization (DPO)~\citep{rafailov2023direct} dominate this track"
- dimensional drift: Unbalanced concentration of training signal on one preference dimension, indicative of reward hacking. "Dimensional drift distinguishes healthy training from reward hacking."
- eigenvalue scale gate: A learned mechanism that produces per-prompt scaling coefficients for preference subspaces. "They are produced for each prompt by a learned ``eigenvalue scale gate'' on the LLM's prompt encoding"
- General Preference Model (GPM): A multi-dimensional, skew-symmetric preference model that can represent intransitive preferences. "We turn instead to the General Preference Model (GPM)"
- General Preference Optimization (GPO): An iterative optimization scheme that regresses policy ratios onto GPM scores. "pair GPM with an iterative SPPO-style scheme called General Preference Optimization (GPO)."
- General Preference Reinforcement Learning (GPRL): An online RL method that uses GPM’s multi-dimensional signal with per-dimension advantages and drift control. "we propose General Preference Reinforcement Learning (GPRL)"
- Group Relative Policy Optimization (GRPO): An online RL algorithm that estimates advantages by normalizing rewards within sampled response groups. "Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath} has emerged as the standard algorithm here."
- group-relative advantages: Advantage estimates computed by comparing each response to others sampled for the same prompt. "computes per-dimension group-relative advantages"
- importance ratio: The likelihood ratio between current and behavior policies used for off-policy correction. "With importance ratio $r_i = \pi_\theta(y_i \mid x) / \pi_{\theta_{\text{old}(y_i \mid x)$"
- intransitive preferences: Preference cycles where A is preferred to B, B to C, and C to A, violating total ordering. "represents intransitive preferences () that scalar models cannot express"
- KL regularization: Penalizing divergence from a reference policy using Kullback–Leibler divergence during training. "where controls KL regularization toward a reference policy"
- KL trust region: A constraint that limits updates by bounding KL divergence, stabilizing policy optimization. "tightening the KL trust region"
- Pareto family: A set of policies that represent different trade-offs among multiple objectives without a single scalar optimum. "returns a Pareto family from independent scalar rewards"
- per-dimension normalization: Rescaling each preference dimension separately to unit variance before aggregation. "The per-dimension normalization in Eq.~\eqref{eq:gprl_per_dim} is what makes Eq.~\eqref{eq:hack_condition} likely to hold"
- programmatic verifier: An automated checker (e.g., unit tests, math solvers) used to compute rewards for verifiable tasks. "depends on a programmatic verifier that cannot reach open-ended tasks"
- Proximal Policy Optimization (PPO): A trust-region policy gradient algorithm that uses clipping to stabilize updates. "optimizes a policy against it with Proximal Policy Optimization (PPO)"
- reinforcement learning with verifiable rewards (RLVR): RL setup where rewards are given by verifiers (e.g., correctness checks) rather than learned models. "the resulting reinforcement learning with verifiable rewards (RLVR) framework powers modern LLMs"
- reward hacking: Exploiting weaknesses in a reward signal to increase the score while degrading true quality. "gives way to reward hacking once pushed at scale"
- reward model (RM): A learned function that predicts preference or quality scores used to guide policy optimization. "fits a scalar reward model (RM) to human preferences"
- skew-symmetric bilinear form: A bilinear mapping A(x, y) = −A(y, x) used to model pairwise preferences and allow cycles. "models preferences with a skew-symmetric bilinear form"
- variance-reduction property: The benefit of normalizing within groups to reduce variance of advantage estimates. "does not break the variance-reduction property that makes group-relative methods well-behaved"
- von Neumann-Morgenstern utility: The classical expected-utility framework that GPM generalizes to allow intransitive comparisons. "generalizing von Neumann-Morgenstern utility"
- zero-mean advantages: The property that normalized advantages within each group sum to zero, stabilizing gradients. "Zero-mean advantages"
Collections
Sign up for free to add this paper to one or more collections.