- The paper presents CUJBench, a pioneering benchmark that requires LLM agents to integrate browser artifacts and backend signals for diagnosing critical user journey failures.
- The study reveals that browser-only configurations achieve up to 52% accuracy while full-toolset agents suffer from reduced submission rates and performance, highlighting unexpected challenges.
- The findings identify key failure modes—formatting instabilities, runaway exploration, and synthesis failures—establishing cross-modal evidence integration as a critical bottleneck in automated RCA.
Expert Summary of "CUJBench: Benchmarking LLM-Agent on Cross-Modal Failure Diagnosis from Browser to Backend" (2604.23455)
Motivation and Scope
CUJBench addresses persistent gaps in LLM-agent benchmarking for software reliability, specifically the lack of benchmarks that evaluate agentic reasoning across both browser-visible and backend observability evidence in failure diagnosis. Existing AIOps and RCA benchmarks exclusively operate on backend telemetry, while web and GUI agent benchmarks focus strictly on task completion over healthy applications—none frame diagnostic tasks requiring modality crossing. CUJBench introduces the first diagnostic benchmark where agents must synthesize browser artifacts (screenshots, HAR files, console logs) and backend signals (traces, metrics, logs) to diagnose failures arising during Critical User Journeys (CUJs), reflecting industry need for end-to-end failure analysis.
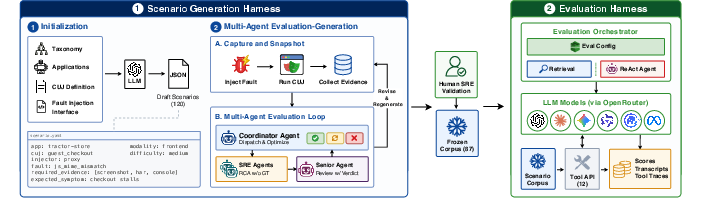
Figure 1: Overview of CUJBench's snapshot-based harness, scenario taxonomy, evidence capture, and multi-agent annotation protocol.
Benchmark Architecture
CUJBench implements a snapshot-based evaluation paradigm: failures are captured under controlled fault injection conditions and packaged into immutable, deterministic multi-modal scenario snapshots. Each scenario contains an alert, precomputed browser and backend evidence caches, and operational context, exposed through a fixed tool interface. The corpus spans 87 scenarios with coverage across five fault families—including browser proxy faults, backend flag faults, compound failures, frontend mutations, and healthy baselines—constructed over two open-source applications (OpenTelemetry Demo and Tractor Store) to ensure diagnostic contrast.
Scenario generation leverages LLM-assisted authoring with a multi-agent review loop and a layered annotation protocol. Candidates are generated by a GPT-5.4-based agent, curated via independent SRE agent reviews and adjudicated by a senior reviewer, with ground-truth labels constructed through injection mapping, evidence-grounded review, and human validation.
Evaluation Protocol and Metrics
Agents interact with scenario snapshots through a 12-tool evidence-access interface, mirroring browser, backend, and context modalities. Three baseline conditions are evaluated:
- B1: Retrieval-only — text evidence chunked and retrieved with BM25, fed into a single LLM context.
- B2: Browser-only agent — agentic tool-calling via browser-visible evidence only.
- B3: Full-agent — agentic tool-calling across the entire toolset.
Metrics comprise both outcome and process measures: A@1 (exact component/type match), per-field matches (CM, LM, TM), Partial Credit (PCE, PCW), Evidence Recall (ER), Tool Coverage (TC), Submission Rate (SR), Tool Calls (Calls), and Extra Calls (EC).
Numerical Results and Behavioral Findings
CUJBench yields an overall A@1 accuracy of 19.7% across 446 completed runs, with a ceiling of 52%—demonstrating substantial diagnostic difficulty. The highest-performing configuration is Claude Sonnet 4.6 and Gemini 3.1 Pro under browser-only, both achieving 52% A@1. Notably, browser-only agents outperform full-toolset agents in aggregate, contradicting the intuition that expanded evidence access aids diagnostic synthesis; richer toolsets induce unfocused exploration and reduced submission rates in frontier models, especially Gemini 3.1 Pro (SR drops from 92% to 40%, A@1 decreases from 52% to 12%).
Agent-specific behavioral analysis reveals three dominant failure modes:
- Formatting Instabilities: Smaller and open-weight models fail to emit syntactically valid tool invocations, despite coherent NL reasoning, blocking completion.
- Runaway Exploration: Models with expanded evidence access exhaust turn or context budgets without converging, accumulating excessive tool calls with low A@1.
- Synthesis Failures: Even with high ER and TC, agents systematically fail at component attribution, especially in cross-modal scenarios.
Cross-modal synthesis is identified as the structural bottleneck: all evaluated agents retrieve decisive evidence but fail to bind artifacts across modalities for precise attribution. Neither model scale nor richer tool APIs suffice to resolve this, as demonstrated by consistent performance ceilings and uniform failure modes across proprietary and open-weight models.
Implications and Future Directions
CUJBench exposes limitations in current LLM-agent frameworks for AIOps, specifically their inability to effectively synthesize evidence across browser and backend, a capability central to end-to-end reliability engineering. The benchmark's snapshot protocol enables deterministic evaluation and process-level trajectory analysis, setting new requirements for multi-step hypothesis revision, modality-aware observation correlation, and evidence-binding protocols.
Practically, improvement in agentic RCA will require protocol-level advances: mechanisms for structured multi-modal artifact binding, enhanced tool invocation contracts, and cross-channel reasoning steps. Theoretically, CUJBench establishes modality-crossing as a fundamental challenge for agentic diagnosis, motivating future research on hierarchical evidence processing and integrated observation models for agentic systems.
Conclusion
CUJBench provides the first reproducible, multi-modal benchmark for agentic failure diagnosis spanning browser to backend, empirically revealing that cross-modal synthesis, not evidence retrieval or tool access, is the dominant obstacle for LLM-based diagnostic agents. The findings suggest that advances in agent architecture, observation binding, and reasoning protocols are prerequisites for closing the gap in automated RCA accuracy. CUJBench offers a foundation for rigorous evaluation and protocol development in LLM-agent reliability research.