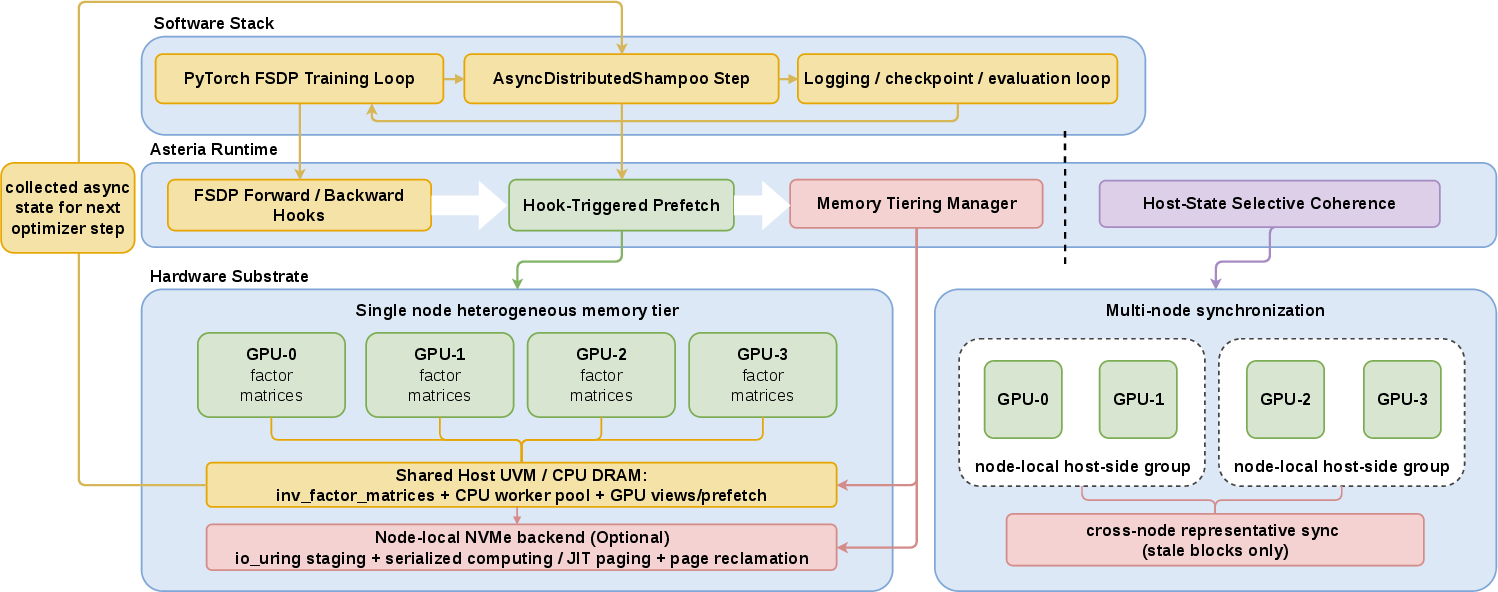
- The paper introduces Asteria, which decouples optimizer state management from GPU training to enable efficient second-order LLM training.
- It deploys architecture-adaptive memory tiering and asynchronous shadow-stream scheduling to hide latency and reduce energy consumption.
- Asteria achieves near-constant GPU throughput and superior loss reduction efficiency compared to first-order baselines like AdamW.
Runtime-Orchestrated Second-Order Optimization for Scalable LLM Training: An Expert Analysis
Introduction
Second-order optimization promises improved sample efficiency and asymptotic performance for LLM training by leveraging curvature-aware updates, as found in methods like Shampoo, SOAP, and KL-Shampoo. However, the systems cost—O(N3) compute and O(N2) memory for handling optimizer state—has rendered such methods often impractical, particularly in memory-constrained or bandwidth-constrained environments. The paper "Runtime-Orchestrated Second-Order Optimization for Scalable LLM Training" (2605.16184) introduces Asteria, an architecture-aware runtime system that incorporates second-order optimization into large-scale LLM training without sacrificing system efficiency, throughput, or scalability.
Core Innovations in Asteria Runtime
Asteria isolates optimizer state management from the critical GPU training path and orchestrates the handling of second-order statistics across heterogeneous memory tiers—GPU, CPU, and NVMe—adapting to hardware constraints and runtime pressure. The approach includes key mechanisms:
Heterogeneous Memory Tiering and Lifecycle-Aware State Placement
Second-order optimizers exhibit a sharply asymmetric lifecycle of matrix state: factor matrices are updated frequently on accelerators, but inverse-root computations are infrequent, expensive, and unneeded on the critical path. Asteria's memory tiering strategy renders possible second-order LLM training even when GPU capacity is limited, by leveraging UVM-backed host memory and (optionally) NVMe storage to persist intermediate states and offload cold data. When necessary, explicit reclamation (madvise) shrinks the working set.
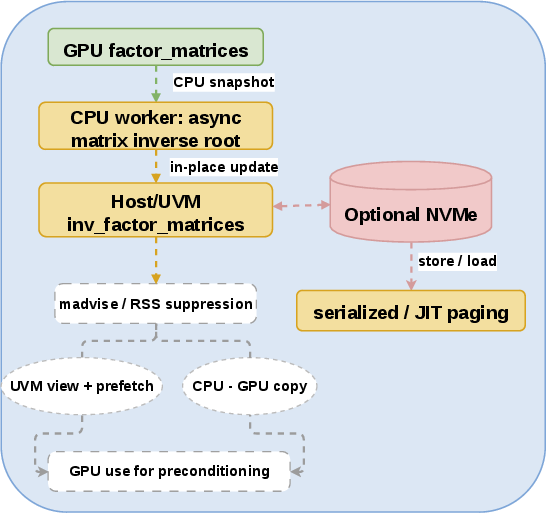
Figure 2: Memory tiering path for second-order state in Asteria, showing selective placement and flow of preconditioner matrices across devices and storage tiers.
Shadow-Stream Scheduling and Asynchronous Preconditioner Computation
Asteria’s utilization of shadow streams and CPU-based asynchronous computation is critical for flattening the notorious O(N3) latency spikes observed in naïve second-order training. By staging updates and enabling just-in-time prefetch via hooks, Asteria ensures that heavy numeric compute (e.g., eigendecompositions or matrix roots) is fully overlapped with GPU execution, relegating synchronization strictly to the boundaries needed by the algorithm.
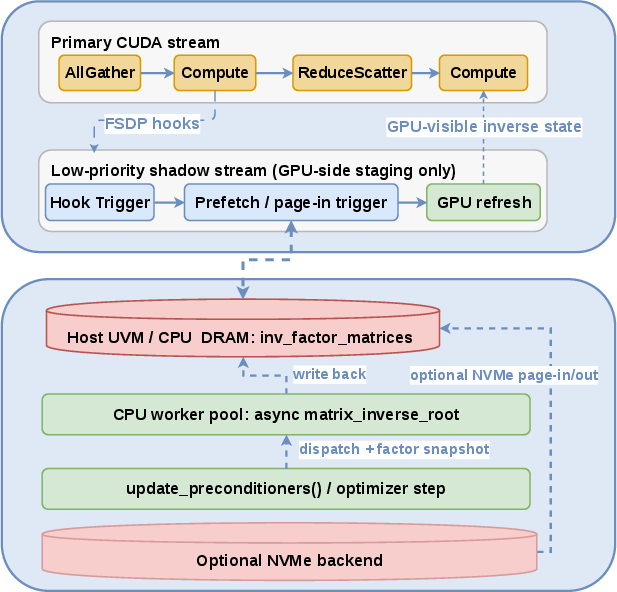
Figure 3: Shadow-stream staging and host-side asynchronous inverse-root updates in Asteria, decoupling critical path training from second-order state maintenance.
Evaluation: Throughput, Latency, and Energy Efficiency
Latency Hiding in Memory-Constrained Environments
Asteria eliminates the stochastic latency spikes of native SOAP and KL-Shampoo by backgrounding the expensive second-order steps (preconditioner updates), achieving near-constant GPU throughput and negligible exposed step-wise overhead relative to AdamW.
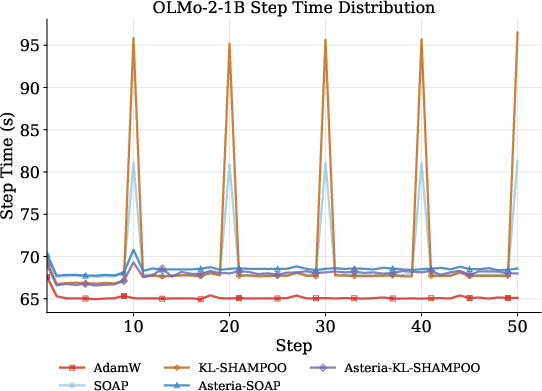
Figure 4: Step time distribution across training steps for OLMo-2-1B on the DGX Spark, demonstrating the removal of periodic second-order latency spikes by Asteria.
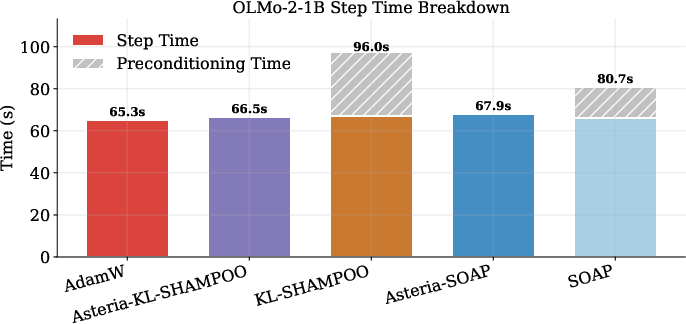
Figure 5: Step-time breakdown at the preconditioning boundary, with Asteria almost entirely hiding preconditioning cost from the critical path.
Energy and Power Dynamics
Naïve second-order implementations incur substantially higher energy per unit loss reduction; Asteria reduces both total energy and SoC energy, shifting execution to a higher-power, shorter-duration regime that enables improved hardware utilization.
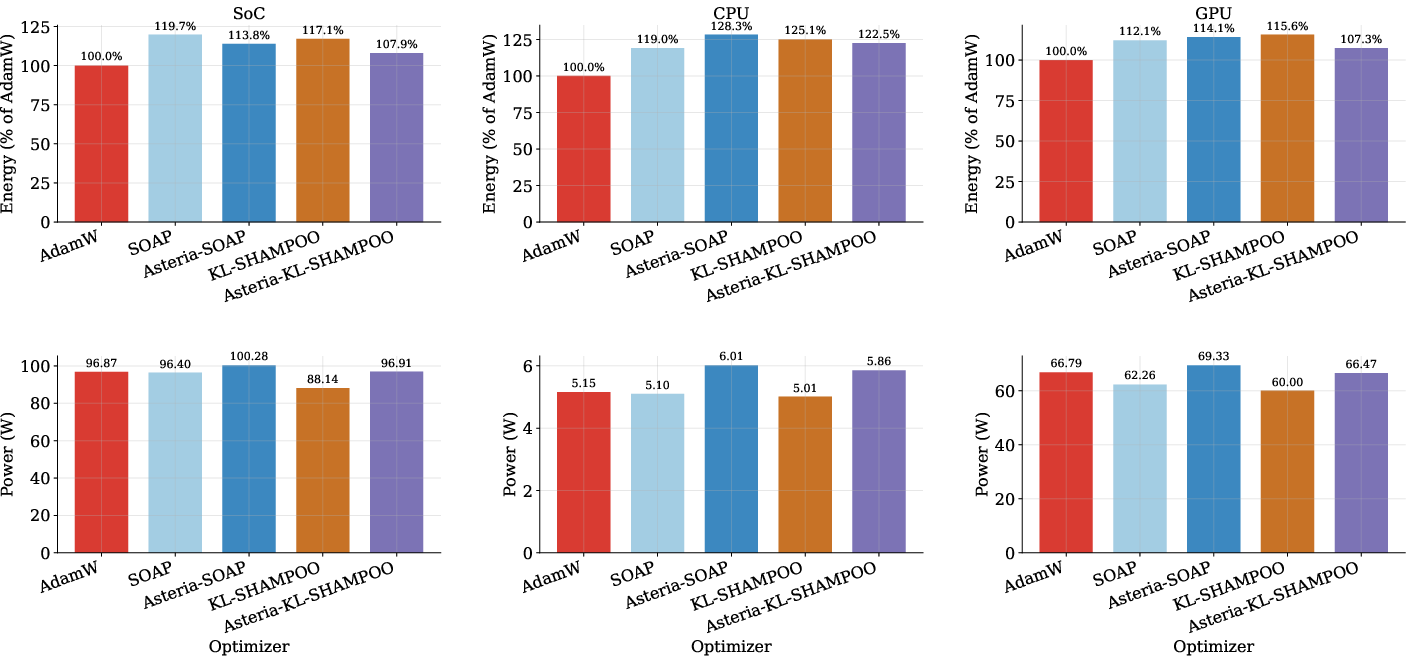
Figure 6: Energy and power comparison for OLMo-2-1B training, with Asteria reducing total energy relative to native second-order baselines and improving the SoC energy tradeoff.
Asteria-KL-Shampoo produces the best normalized loss-reduction efficiency among all tested variants, surpassing even the AdamW baseline in terms of loss reduction per joule expended.
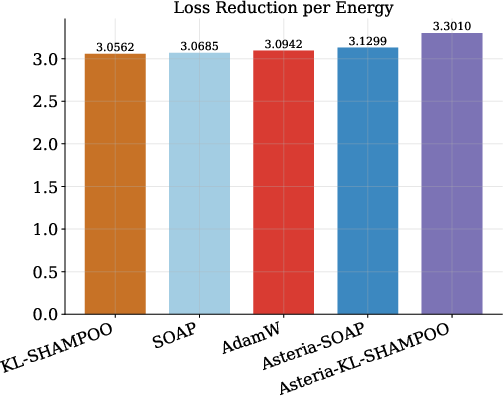
Figure 7: Energy-loss tradeoff for OLMo-2-1B, where Asteria yields higher efficiency than both first-order and native second-order optimizers.
Distributed Scaling, Staleness Tolerance, and Convergence Behavior
Asynchrony and Bounded Staleness
Asteria's capability to tolerate bounded staleness without degrading optimization performance is empirically validated for both loss and wall-clock time. In distributed training, a moderate staleness window (S=3 to S=5) suffices to hide nearly all overhead, with no adverse impact on convergence.
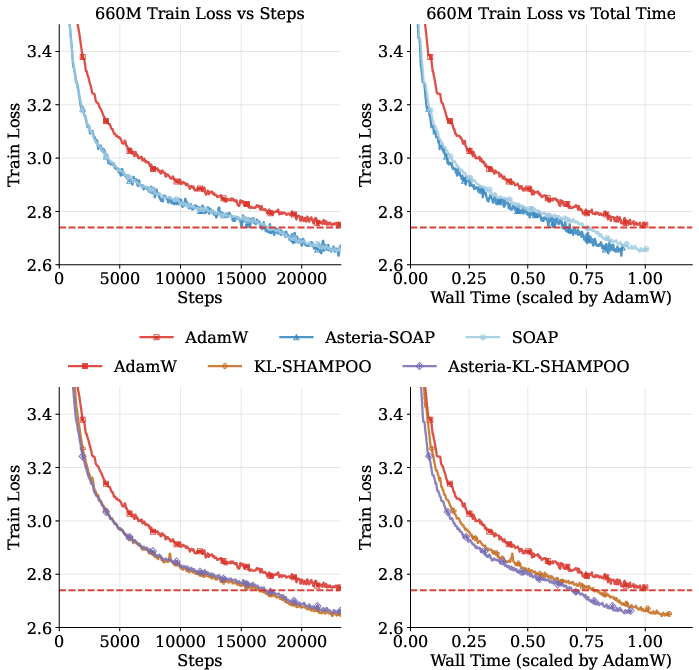
Figure 8: Training loss for 660M pretraining runs, demonstrating Asteria's preservation of the second-order convergence advantage in both optimizer steps and wall time.
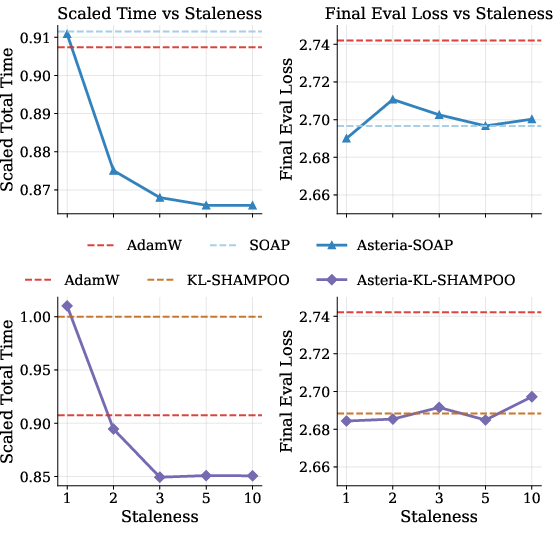
Figure 9: Effect of staleness budget on training time and final evaluation loss, confirming that increased staleness reduces overhead with negligible impact on accuracy.
Scalability on Large Clusters
Asteria's efficacy persists at scale, with strong-scaling efficiency maintained even as node and model size increase. For 1B and 7B models, Asteria-based second-order optimizers outpace AdamW in time-to-target-loss.
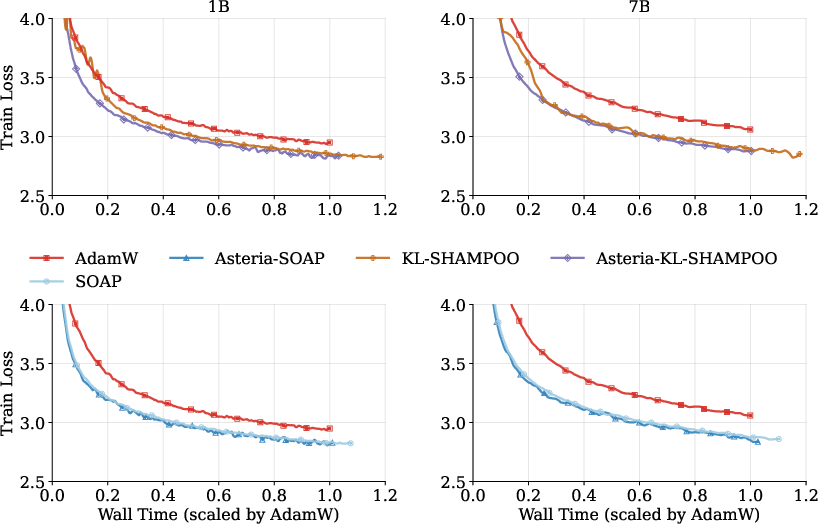
Figure 10: Training loss over wall time for 1B and 7B pretraining runs, revealing Asteria's maintenance of second-order advantages at scale.
Strong-scaling experiments demonstrate higher realized parallel efficiency and lower per-step execution time with Asteria across a 2–16 node range.
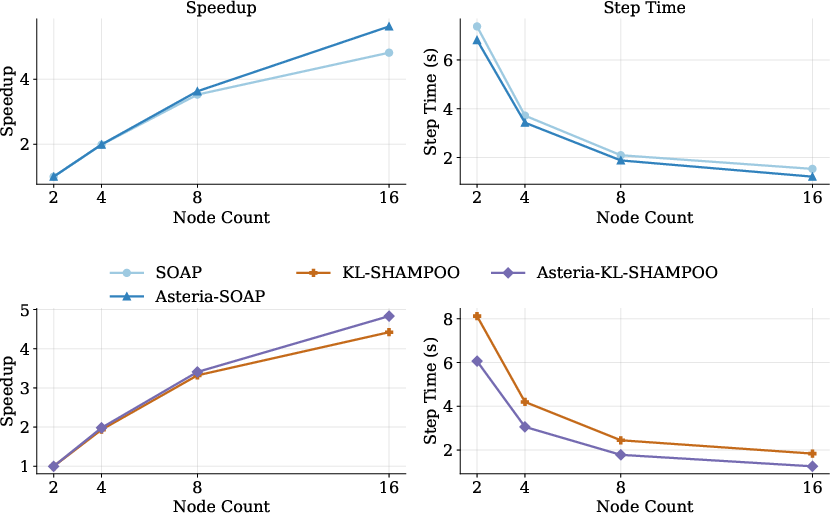
Figure 11: Strong-scaling for 7B training, with Asteria achieving superior scaling efficiency compared to native second-order baselines.
Theoretical and Practical Implications
The research concretely demonstrates that the bottleneck in large-scale second-order optimization is more systemic (state management and synchronization) than purely algorithmic. By decoupling matrix updates and taking a lifecycle-aware approach to memory, Asteria renders previously infeasible training configurations (single-GPU, tight-DRAM nodes) tractable for second-order methods. This mandates a shift in the community's perspective—practical second-order optimization at scale requires careful hardware-software co-design, runtime orchestration, and staleness-aware communication.
Practically, Asteria opens new deployment scenarios for second-order optimization on both commodity workstations and bandwidth-sensitive distributed clusters. The approach’s energy-efficiency improvements further reinforce the system’s value for institutions operating under power constraints.
Theoretically, the results suggest that for LLM training, the statistical gains of curvature-aware optimization may be reliably realized in real-world, large-scale settings with appropriate runtime engineering.
Future Directions
Further work could adapt Asteria to tensor- and pipeline-parallel regimes, exploit emerging memory technologies (e.g., HBM-NVMe interleaving), or refine asynchrony-control policies based on online monitoring of loss and hardware counters. There is also potential for integrating capability detection to automatically configure the system’s memory and staging behaviors per hardware node.
Conclusion
Asteria establishes that with jointly engineered runtime, memory, and communication strategies, sample-efficient second-order optimization becomes feasible, scalable, and efficient for LLM pretraining in hardware-constrained and distributed systems. These results substantively change the calculus of optimizer selection in practical deep learning, providing a robust path by which the statistical advantages of second-order methods can be harvested at scale and across heterogeneous compute environments.