UAM: A Dual-Stream Perspective on Forgetting in VLA Training
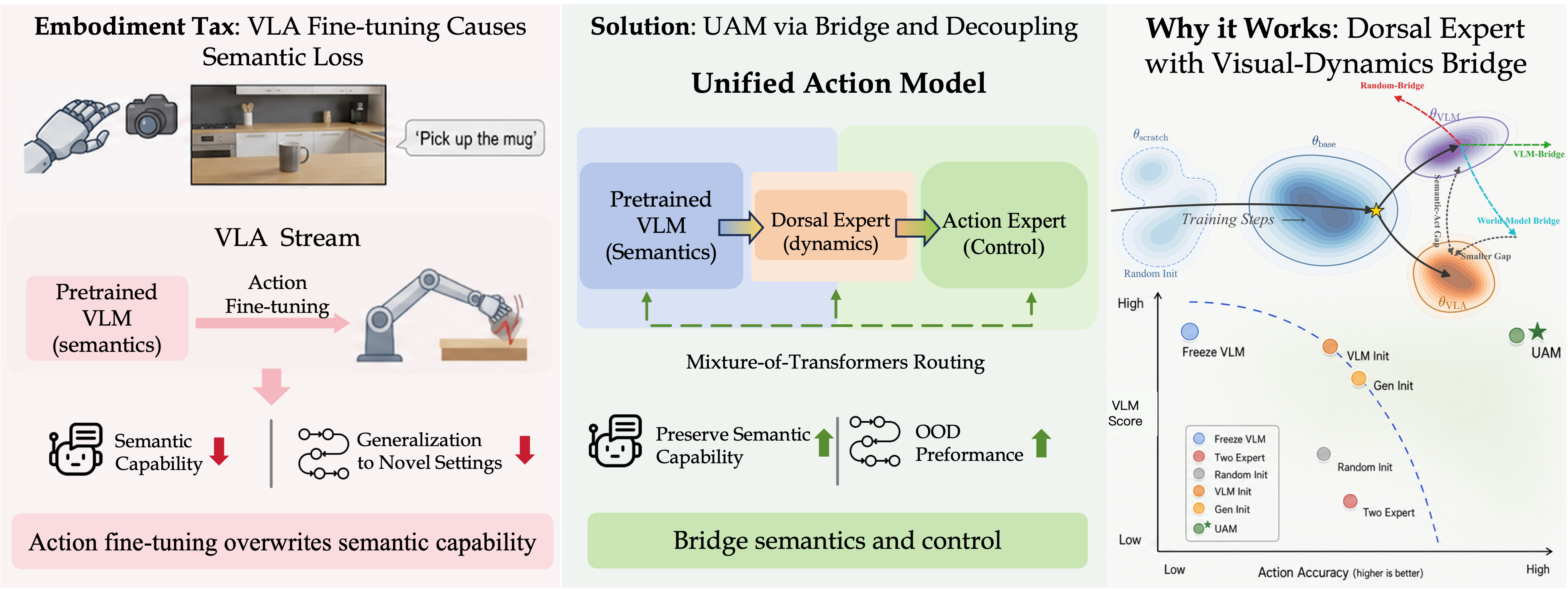
Abstract: Vision--language--action (VLA) models are typically built by fine-tuning a pretrained vision--LLM (VLM) on action data. However, we show that this standard recipe systematically erodes the VLM's multimodal competence, a side effect we call the embodiment tax. But do VLAs have to forget? Inspired by the two-stream organization of biological vision, we trace this degradation to a structural bottleneck: current VLAs ask a single encoder to support both language-grounded semantics and control-relevant visual features, whereas biological vision separates recognition and visuomotor control into distinct pathways. Building on this view, we propose the Unified Action Model (UAM), which adds a parallel Dorsal Expert, an analog of the brain's dorsal pathway. To make the Dorsal Expert an effective second pathway and reduce the control-learning burden on the VLM, we initialize it from a pretrained generative model and train it with a mid-level reasoning objective that predicts visual dynamics. This design allows us to train the whole VLA end-to-end on action data alone: with no parameter freezing, no gradient stopping, and no auxiliary VL co-training, UAM retains over $95\%$ of the underlying VLM's multimodal capability and at the same time achieves the highest average success rate among baselines on a variety of manipulation tasks that probe out-of-distribution generalization, including unseen objects, novel object--target compositions, and instruction variation. Together, these results suggest that semantic preservation in VLAs can emerge from architectural separation itself, rather than being enforced by frozen weights or auxiliary data replay, and that this preserved semantic capability can naturally transfer from VLMs to semantic generalization in actions.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to build robot brains that can see, read, and act at the same time. Today, many robot models start from a vision–LLM (a system that can understand pictures and text) and then get trained to control a robot arm. The authors discovered a common problem: when you train these models to act, they often “forget” some of what they previously knew about seeing and reading. They call this the “embodiment tax” — the price a model pays when it becomes a physical actor.
To fix this, the authors propose a new design called UAM (Unified Action Model). It adds a second visual pathway focused on movement and spatial control, inspired by how the human brain has two visual streams: one for recognizing “what” things are, and another for “where/how” to interact with them.
What questions did the researchers ask?
- Can a robot model learn to act without forgetting its earlier skills in understanding images and language?
- Is there an architectural reason why forgetting happens — and can separating “what” and “where/how” pathways reduce it?
- What kind of second pathway works best: one started from scratch, one copied from a vision–LLM, or one copied from a generative video model that understands how scenes change over time?
How did they study it?
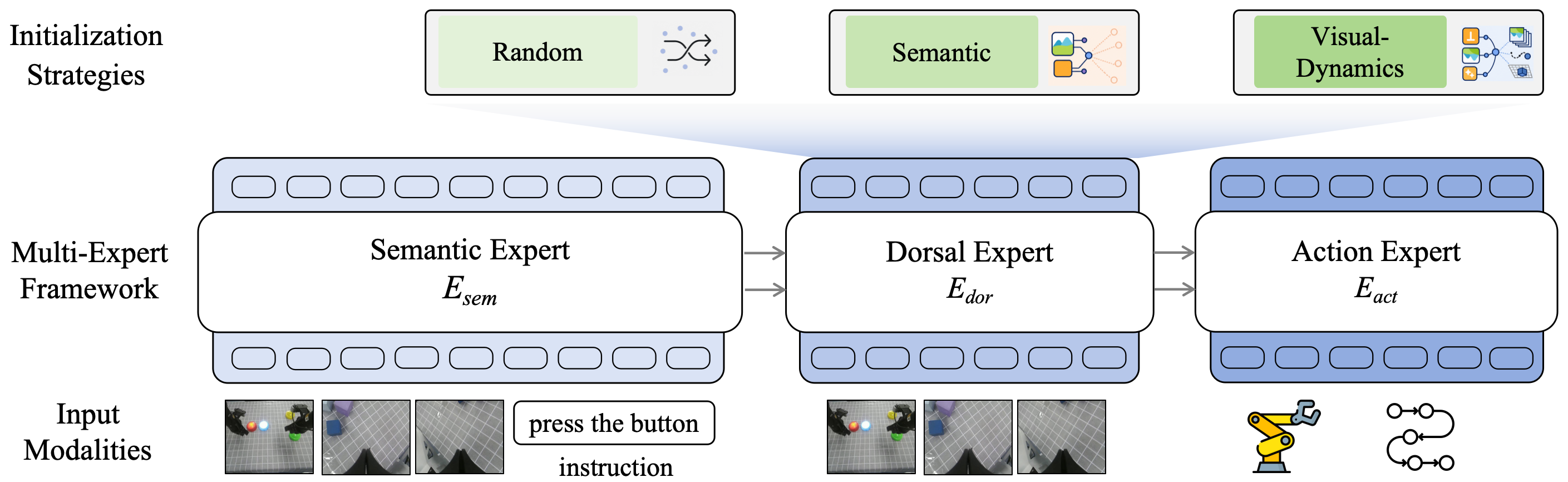
Think of a robot brain as a team with different specialists:
- A “Semantic Expert” that’s good at understanding pictures and text (e.g., “the red mug on the table”).
- An “Action Expert” that decides what the robot should do next (e.g., move left, grasp, lift).
- The paper adds a new “Dorsal Expert,” whose job is to focus on motion, positions, and how scenes evolve — like predicting what will happen next if the robot moves its arm.
They connect these experts with a “smart router” (called a Mixture-of-Transformers), which lets the action head attend to the right information from each expert.
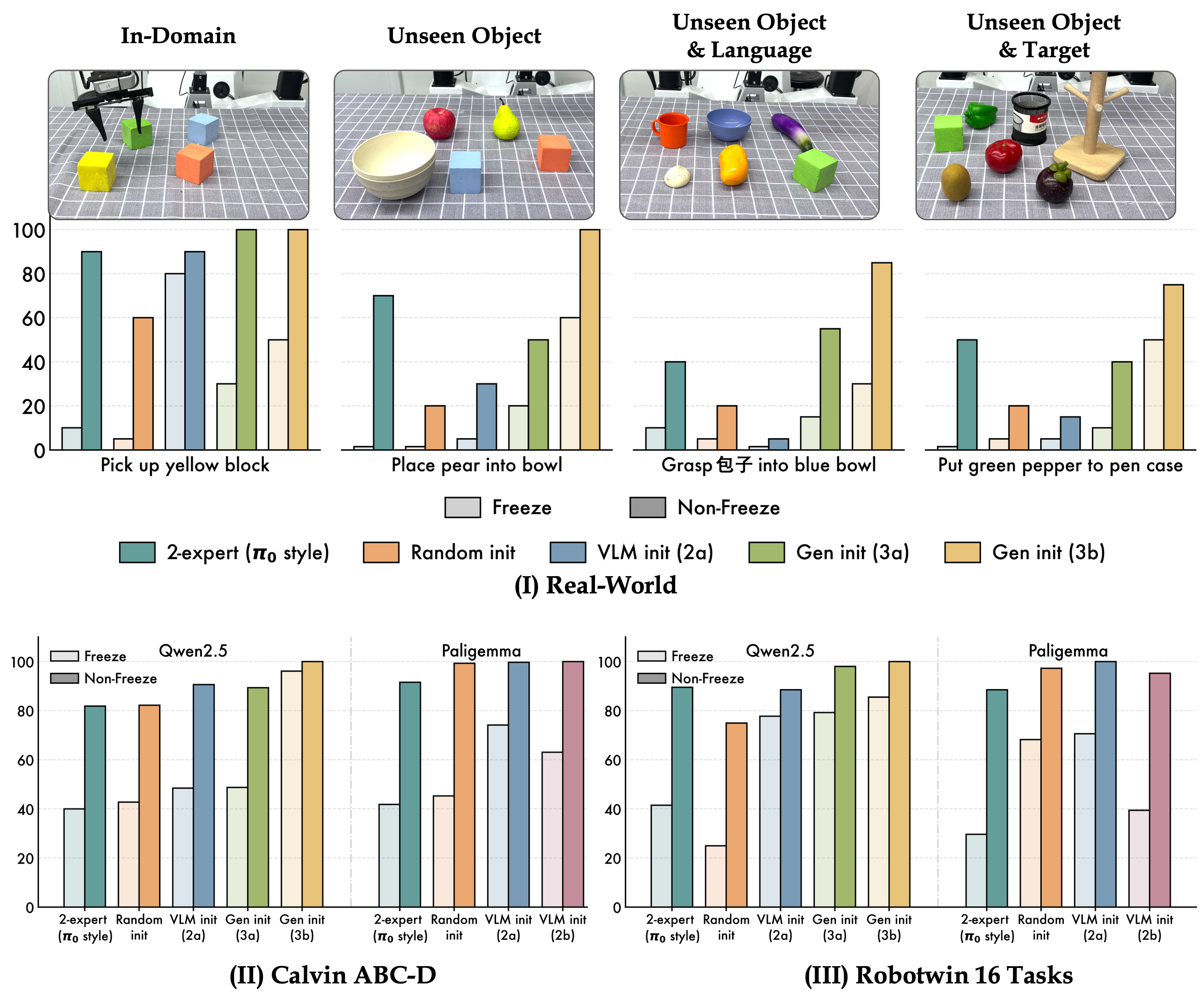
To see why forgetting happens, they first measure it: they check how well a model answers vision–language questions before and after training on robot actions. They test different setups:
- Freezing the original vision–LLM (so it can’t change) keeps its knowledge but hurts robot control.
- Letting everything learn improves robot control but causes forgetting.
Then they try different ways to build the Dorsal Expert:
- Randomly initialized (no prior knowledge).
- Copied from a vision–LLM (knows “what” and language).
- Copied from a generative video model (knows how scenes change), with or without an extra training goal to predict visual dynamics (like guessing the next frame of a video).
Explaining the technical bits in everyday terms:
- “Fine-tuning” = practicing new skills on top of what you already know.
- “Freezing parameters” = locking parts of the brain so they don’t change.
- “Generative model” = a model that can imagine or predict future images.
- “Visual dynamics” = understanding how things move and change in a scene.
- “Out-of-distribution (OOD)” = tests that are different from what the model saw during training, like new objects or instructions in another language.
What did they find?
- The embodiment tax is real: training a single pathway to both understand and control causes the model to overwrite some of its earlier visual–language knowledge.
- Simply adding capacity isn’t enough: a second pathway with random weights didn’t help.
- Copying the second pathway from a vision–LLM helped somewhat, but not reliably on harder, real-world tests.
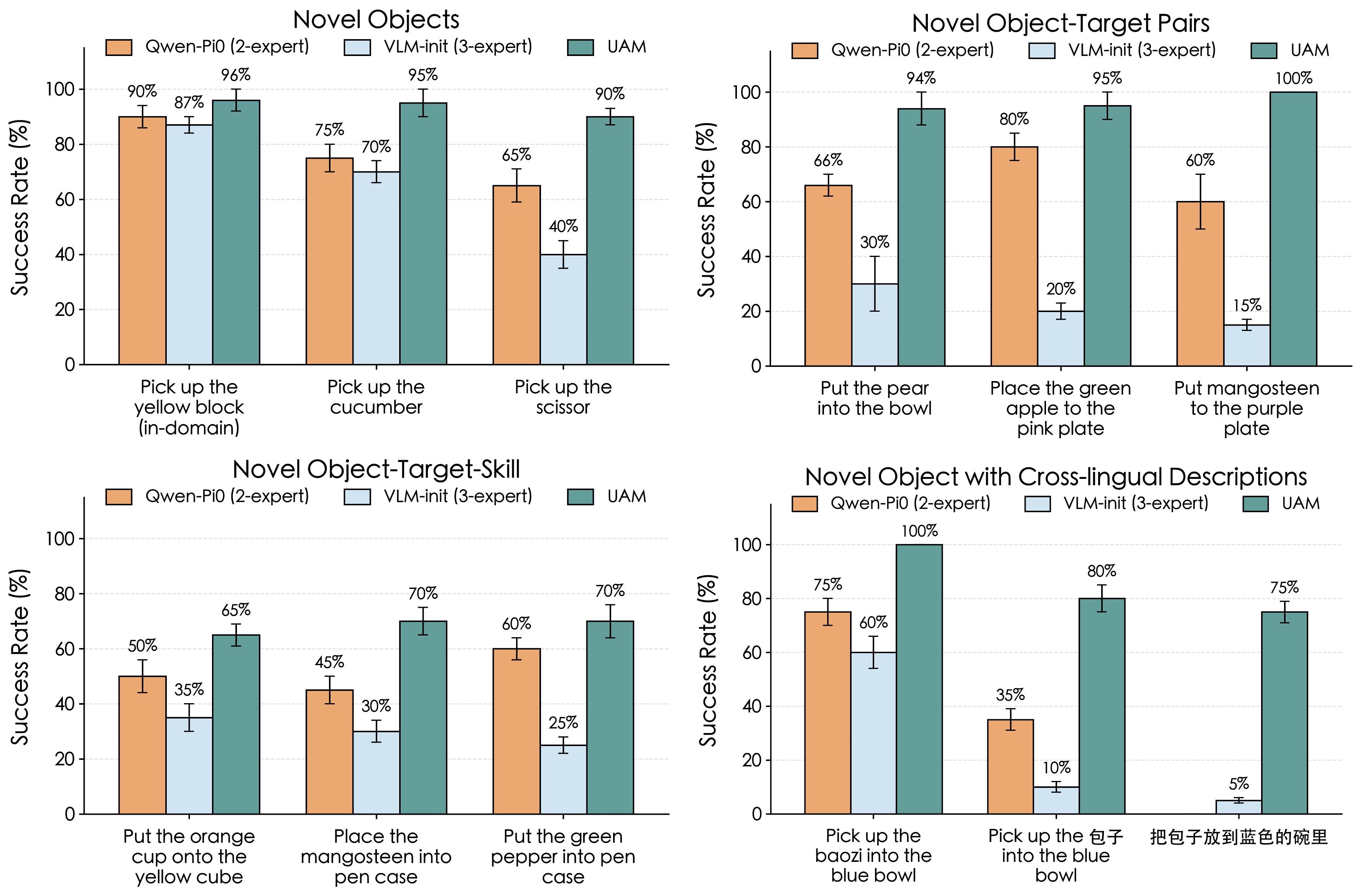
- The best solution was a Dorsal Expert initialized from a generative video model and trained with a visual-dynamics objective (predicting how the scene changes). This setup:
- Kept over 95% of the original vision–language abilities on standard benchmarks.
- Achieved the strongest robot performance on a range of tasks, especially tough ones with new objects, new object–target combinations, and varied instructions (including language variations).
- Did all this without freezing parts of the model, stopping gradients, or co-training on extra question–answer data.
Why this matters:
- With the “what” and “where/how” streams separated, each can get better at its own job. The semantic pathway stays sharp at understanding images and text; the dorsal pathway learns control-friendly visual features and predicts how the scene will change when the robot acts.
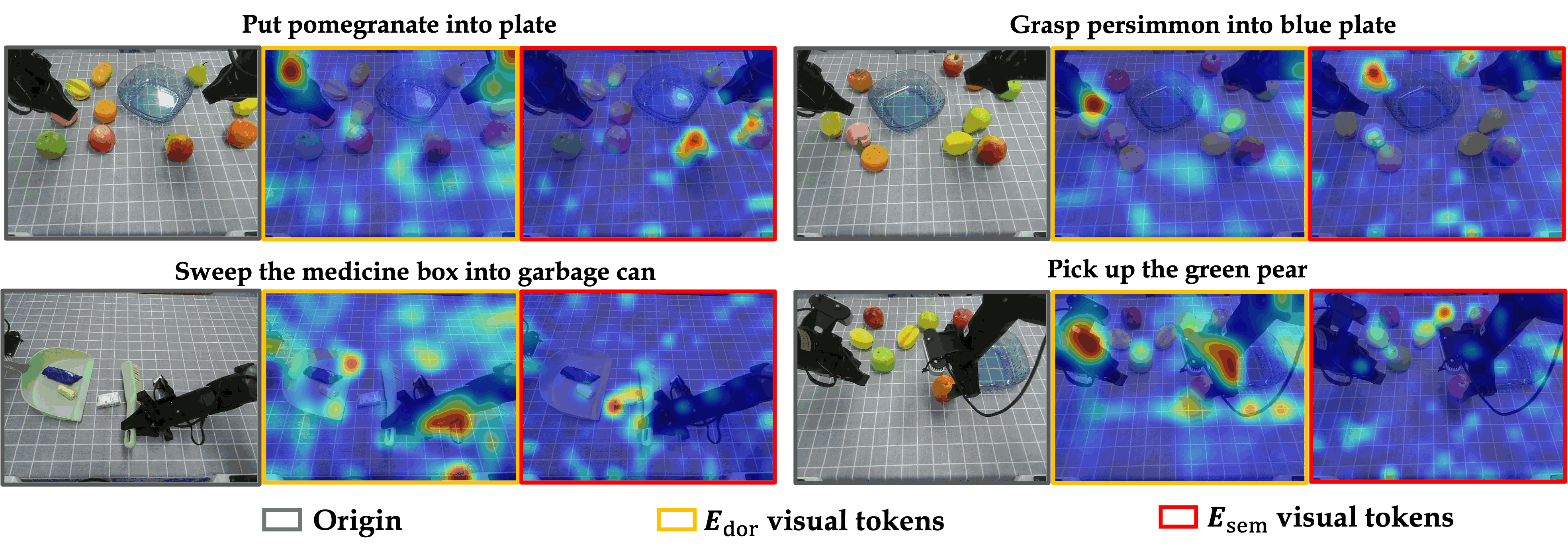
- Attention visualizations showed this split in action: the semantic stream focused on task-relevant objects and text meaning, while the dorsal stream focused on the robot arm, contact areas, and scene layout.
Why does this matter?
- More reliable robots: Keeping the model’s original visual and language skills means robots can better handle new situations, understand varied instructions, and use prior knowledge to solve tasks they weren’t explicitly trained on.
- Simpler training recipe: UAM reaches strong action performance and preserves understanding without needing extra datasets for vision–language co-training or special tricks like freezing parts of the model.
- Brain-inspired design works: Building in a structural separation between “recognition” and “control” — like the human visual system — reduces forgetting and improves generalization.
Bottom line
The paper shows that forgetting isn’t inevitable. By giving robot models two distinct visual pathways — one for understanding “what” is in the scene and another for “where/how” to act — and by teaching the control pathway to predict visual changes, we can train robots end-to-end on action data while largely preserving their original seeing-and-reading skills. This could lead to more capable, adaptable robots that learn faster and perform better in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of missing, uncertain, or unexplored aspects that future work could address:
- External validity across backbones: UAM’s main results use a Bagel-based setup; it remains unclear whether the observed <5% “embodiment tax” holds for diverse VLMs (e.g., CLIP-LLaVA families, PaliGemma, Qwen2.5-VL) and parameter scales.
- Dependence on a specific generative prior: The dorsal expert is initialized from a generative unified multimodal model (Bagel). Whether other generative priors (diffusion, autoregressive video LMs, masked video transformers) yield similar retention and control gains is untested.
- Objective design ambiguity: The visual-dynamics loss is presented as predicting I_{t+1}, but details are sparse (single-step vs multi-step rollout, action-conditioning vs unconditional prediction, stochastic vs deterministic modeling, loss type, λ scheduling), making it hard to reproduce or optimize.
- Action-conditioning in the world model: It is unclear if the dorsal expert’s prediction explicitly conditions on the executed or planned action; testing action-conditioned vs action-agnostic dynamics could clarify what information the dorsal pathway must carry.
- Temporal horizon sensitivity: The approach’s dependence on lookahead depth for visual dynamics (short vs long horizons) and its impact on semantic retention and OOD control remains unexplored.
- Role of proprioception and other modalities: The dorsal expert currently ingests only vision; adding proprioception, tactile, force/torque, and wrist camera inputs may strengthen control features but was not investigated.
- 3D structure and geometry: The dorsal stream appears to operate on 2D tokens (ViT/VAE-like); incorporating depth, 3D scene graphs, or differentiable rendering may improve visuomotor fidelity, but this is not explored.
- Robustness to viewpoint and camera changes: The real-world evaluation emphasizes a third-view camera; systematic tests under camera pose shifts, lens changes, lighting, and occlusion are missing.
- Task diversity and long-horizon control: Real-world tasks focus on short-horizon bimanual manipulation; it is unclear how UAM scales to long-horizon, contact-rich, or multi-stage tasks, and whether semantic retention persists under extended credit assignment.
- Generalization across embodiments: Cross-robot transfer (single-arm to bimanual, gripper to dexterous hand, mobile manipulation) is not studied, leaving embodiment invariance an open question.
- Data scaling laws: The relationship between action dataset size, dorsal capacity, and semantic retention is not characterized (e.g., does more action data reintroduce forgetting without stronger dynamics objectives?).
- Seed and stability analysis: Variability across random seeds, routing stability in Mixture-of-Transformers, and failure-to-engage of the dorsal pathway without auxiliary loss are not quantified.
- Head-to-head baselines with matched compute/data: Comparisons to strong “freeze + adapters,” “freeze + routing,” or “co-training + KI” baselines at similar model sizes and data budgets are limited, making it hard to isolate architectural vs data advantages.
- Inference and training cost: The paper notes added complexity but does not quantify latency, memory, throughput, or real-time feasibility on robot hardware; profiling and optimization targets are missing.
- Safety and reliability under perturbations: No evaluation under disturbances (slippage, adversarial distractors, dynamic obstacles), failure recovery, or safety constraints; robustness guarantees are unknown.
- Multilingual grounding breadth: Language tests include pinyin/code-mix/Chinese, but broader multilingual coverage, systematic evaluation across languages/scripts, and domain-specific jargon are unreported.
- Negative transfer and catastrophic interference: Although average drops are small, per-category retention (e.g., OCR, spatial reasoning, math, fine-grained attributes) could degrade unevenly; detailed per-skill analyses and significance tests are missing.
- Interaction between co-training and dual streams: UAM deliberately avoids VL co-training; whether UAM combined with selective VL replay or KI could further reduce the embodiment tax or enable zero tax remains open.
- Effect of gating/routing design: Alternative routing (learned vs hard gates, token-level vs layer-level routing, sparsity constraints) may change how semantics/control decouple; this design space is largely unexplored.
- Auxiliary objective variants: Testing contrastive temporal objectives, inverse dynamics, affordance prediction, subgoal/skill discovery, or latent planning losses as dorsal supervision could clarify what best supports control without semantic erosion.
- Policy optimization regime: Results are imitation-only; it is unknown how UAM behaves under RL fine-tuning, offline RL, or DAgger-like iterative data collection, and whether dorsal/ventral roles persist.
- Compositional and systematic generalization: Beyond unseen objects/compositions, compositional instruction structures (coreference, quantifiers, conditionals, multi-step plans) are not systematically probed.
- Failure analysis and ablations: Detailed error typology, per-task breakdowns, and ablations on dorsal input type, capacity, loss weight λ, and training schedules are needed to make the method actionable.
- Distillation and deployment: Whether the three-expert model can be distilled to a lighter controller while retaining both control and semantic competence is unaddressed.
- Reproducibility artifacts: Several critical implementation specifics are relegated to the appendix; releasing full training scripts, configs, checkpoints, and exact evaluation prompts would improve reproducibility and external validation.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging UAM’s dual-stream architecture (ventral VLM + generative Dorsal Expert with visual-dynamics supervision), its end-to-end action-only training, and the forgetting metric Δ to monitor semantic retention.
- Bold: Drop-in dual-stream upgrade for existing VLA stacks (Robotics, Software)
- Replace or augment RT-2/OpenVLA/Octo/π0-style controllers with UAM’s Dorsal Expert to reduce the embodiment tax while improving OOD manipulation.
- Tools/products/workflows: Mixture-of-Transformers (MoT) routing module; Dorsal Expert initialized from a generative unified multimodal model (e.g., Bagel); auxiliary visual-dynamics objective; training scripts that use action-only trajectories; evaluation harness for Δ.
- Assumptions/dependencies: Access to a robust VLM backbone and a compatible generative model checkpoint; sufficient compute to handle the added dorsal pathway; moderate-size action datasets (e.g., ~3k demos) and calibrated camera views.
- Bold: Cost- and data-efficient robot training pipelines (Industry, Academia)
- Train language-conditioned policies on action-only data without co-training on VQA corpora, reducing data costs, IP/licensing risks, and engineering complexity.
- Tools/products/workflows: Action-only data collection and curation; end-to-end fine-tuning with no frozen weights; Δ-based regression guardrails; multilingual instruction tests.
- Assumptions/dependencies: Action data covers core task distribution; pretraining choices (VLM, generative dorsal) match target domain; basic multilingual VLM support.
- Bold: OOD-robust picking, kitting, and rework cells (Manufacturing, Logistics)
- Improve success on unseen objects, new object–target compositions, and instruction variants in warehouses and factories.
- Tools/products/workflows: Site-specific action datasets; UAM-trained policy; camera placements capturing both workspace and robot arm; continuous monitoring of Δ for each software update.
- Assumptions/dependencies: Safety-certified low-level controllers; well-lit scenes; stable latencies for real-time inference; change management processes for model updates.
- Bold: Multilingual instruction following in robotics workflows (Consumer Robotics, Enterprise Ops)
- Execute tasks with code-mixed and non-English instructions (e.g., pinyin, Chinese–English) by preserving the VLM’s language grounding during action fine-tuning.
- Tools/products/workflows: Multilingual prompt templates; unit tests for language variants; ops playbooks mapping synonyms to canonical intents.
- Assumptions/dependencies: Underlying VLM supports target languages; speech-to-text or text-only interface quality.
- Bold: Regression and release gating via embodiment tax dashboards (Policy, Industry QA, Academia)
- Adopt Δ as a go/no-go metric to prevent semantic regressions after action fine-tuning and before deployment to robots in production/labs.
- Tools/products/workflows: Δ computation across a benchmark suite (e.g., MMMU, MMBench, TextVQA); CI/CD integration; model versioning with retention criteria.
- Assumptions/dependencies: Benchmarks correlate with deployment semantics; governance policies codify acceptable Δ thresholds (e.g., ≤5%).
- Bold: Teleoperation assist with visual-dynamics overlays (Robotics, Human–Machine Interfaces)
- Use the Dorsal Expert’s predictive capability to show likely next-frame changes or interaction regions to human operators for faster, safer teleop.
- Tools/products/workflows: Lightweight goal-observation prediction head; GUI overlay tooling; operator-in-the-loop workflows.
- Assumptions/dependencies: Accurate calibration between cameras and GUI; low latency; clear human factors validation.
- Bold: Sim2Real classroom and lab kits for embodied AI (Education, Academia)
- Teach dual-stream design, forgetting measurement, and OOD generalization using UAM ablations (random/VLM/generative dorsal; with/without dynamics loss).
- Tools/products/workflows: Reference repo and assignments; small tabletop robot platforms; standardized OOD test suites.
- Assumptions/dependencies: Availability of open weights or substitutes for VLM/generative models; modest GPU access.
- Bold: Retrofittable “DorsalKit” library (Software tooling)
- A minimal package providing MoT routing, dorsal initialization hooks, visual-dynamics auxiliary loss, and Δ evaluation utilities for popular VLA baselines.
- Tools/products/workflows: PyTorch/JAX components; model cards capturing Δ; adapters for common backbones (Qwen2.5-VL, PaliGemma, etc.).
- Assumptions/dependencies: License compatibility for target backbones; maintainers to track upstream model changes.
Long-Term Applications
These applications require further research, scaling, safety validation, or systems engineering, but are natural extensions of the paper’s findings.
- Bold: General-purpose home assistants with resilient semantics (Consumer Robotics)
- Household robots that learn new skills from a handful of demos without forgetting object recognition, OCR, or language grounding.
- Potential tools/products/workflows: Continual learning with dual-stream routing; home-specific data flywheels; on-device Δ monitoring; multilingual dialogue + action.
- Assumptions/dependencies: Robust safety, compliance, and fail-safe control; long-horizon memory; low-cost edge inference for dorsal forecasts.
- Bold: Healthcare and assistive manipulation (Healthcare)
- Robots for hospital logistics or assistive care that maintain medical-semantic competence while adapting to new rooms/tools and language variations.
- Potential tools/products/workflows: FDA-grade validation of Δ and task success; dataset governance; structured error taxonomies; haptic integration.
- Assumptions/dependencies: Stringent safety, privacy, and auditability; clinically validated datasets; redundancy and human oversight.
- Bold: Autonomous driving perception–control decoupling (Autonomous Systems)
- Apply the dorsal–ventral separation to driving: retain VLM semantics (signs, OCR, grounding) while training a generative dorsal for dynamics/planning.
- Potential tools/products/workflows: Video world-model dorsal; closed-loop planning interfaces; Δ-like retention metrics for perception.
- Assumptions/dependencies: Scalable driving datasets; real-time constraints; formal verification for safety-critical decisions.
- Bold: Cross-embodiment skill transfer via dorsal world models (Robotics)
- Share a common Dorsal Expert across robot arms/platforms, reusing dynamics priors while swapping minimal action heads per embodiment.
- Potential tools/products/workflows: Embodiment adapters; skill libraries indexed by dynamics regimes; fleet-wide continual learning.
- Assumptions/dependencies: Standardized interfaces and calibration; domain adaptation for varying kinematics and sensors.
- Bold: Cloud “World-Model Dorsal” services (AI Platforms)
- Offer Dorsal Expert inference as a managed service that any VLM-driven agent can query to obtain predictive visual features for control.
- Potential tools/products/workflows: gRPC/REST APIs for dorsal tokens/forecasts; SLAs for latency; usage-based billing.
- Assumptions/dependencies: Network reliability; privacy/security guarantees; cost of high-throughput video inference.
- Bold: Standards and certification for semantic retention (Policy, Standards Bodies)
- Introduce Δ (or an analog) as a required KPI in certification of embodied AI systems to ensure action training does not erase foundational multimodal skills.
- Potential tools/products/workflows: Reference benchmark suites; conformance tests; procurement guidelines emphasizing architectural separation (or equivalent guarantees).
- Assumptions/dependencies: Cross-industry consensus; mappings between benchmark gains and real-world risk reduction.
- Bold: Continual, multi-task robot fleets without replay (Robotics Ops)
- Maintain performance across many tasks/sites through architectural separation instead of massive replay buffers or auxiliary VL co-training.
- Potential tools/products/workflows: Schedule-aware fine-tuning; per-task Δ tracking; automated routing diagnostics (attention heatmaps) for drift detection.
- Assumptions/dependencies: Tooling for online evaluation; robust ops telemetry; policies for rollbacks when Δ thresholds are breached.
- Bold: Hardware–software co-design for efficient dual-stream inference (Semiconductors, Edge AI)
- Accelerators and compilers tuned for MoT routing and visual-dynamics heads to meet tight latency/energy budgets.
- Potential tools/products/workflows: Kernel fusion for token routing; VAE/ViT co-execution pipelines; quantization-aware training for dorsal modules.
- Assumptions/dependencies: Stable model architectures; vendor collaboration; acceptance of minor accuracy trade-offs for efficiency.
Notes on Assumptions and Dependencies (common across applications)
- Model availability and licensing: Requires access to a strong VLM and a generative unified multimodal model (e.g., Bagel or equivalent), with compatible licenses.
- Compute and latency: The dorsal pathway adds training/inference cost; edge deployment may need pruning, distillation, or accelerator support.
- Data quality: While UAM reduces reliance on VL co-training, diverse, clean action trajectories (and camera coverage) remain crucial.
- Safety and compliance: Particularly for healthcare/industrial uses, additional validation beyond benchmark Δ and lab OOD tests is necessary.
- Generalization bounds: UAM improves retention and OOD robustness but does not eliminate the need for domain adaptation or safety envelopes in highly novel scenarios.
By separating recognition (“what”) from visuomotor control (“where/how”) through a generative, dynamics-aware Dorsal Expert and measuring retention with Δ, the paper’s methods enable practical, immediately deployable upgrades to current VLA systems and lay the groundwork for safer, more general embodied AI over the long term.
Glossary
- Action-conditioned outcomes: Outcomes in video or robotics that depend on the actions taken. "Such approaches capture scene evolution and action-conditioned outcomes, yet multimodal understanding and reasoning abilities are not guaranteed when policies are built primarily on video backbones."
- Action expert: A specialized module in the architecture that consumes features and outputs low-level robot actions. "To probe how strongly VLA training interferes with VLM features, we attach an action expert to two representative backbones, Qwen2.5-7B and PaliGemma, and train the resulting VLA exclusively on action data."
- Action head: The output layer or component that produces the action tokens or continuous controls. "In this sense, the value of a VLA is not just its action head."
- CALVIN: A robotics benchmark used to evaluate action prediction and manipulation performance. "All three configurations are evaluated on CALVIN for Action Accuracy and on the multimodal benchmark suite for VLM Score S."
- Catastrophic forgetting: A phenomenon where fine-tuning on new tasks degrades performance on previously learned capabilities. "Does the UAM paradigm effectively mitigate catastrophic forgetting in VLMs during action fine-tuning?"
- Co-training: Jointly training on auxiliary vision–language data alongside action data to preserve semantics. "Co-training with auxiliary vision--language data keeps the gradients flowing, but retention then depends on the scale, diversity, and availability of an auxiliary corpus."
- Dorsal Expert: A parallel, control-oriented visual pathway in the model, analogous to the brain’s dorsal stream. "We equip the VLA with a Dorsal Expert: a parallel, visually grounded pathway that, by analogy with the dorsal stream, gives the policy a control-oriented visual route in addition to the semantic VLM."
- Dorsal pathway: The biological visual stream specialized for spatial processing and visuomotor control. "adds a parallel Dorsal Expert, an analog of the brain's dorsal pathway."
- Embodiment tax: The systematic drop in multimodal capability that occurs when a VLM is fine-tuned for actions. "We refer to this systematic capability loss, in which general-purpose competence is sacrificed as the price of becoming an action model, as the embodiment tax of current VLA fine-tuning."
- End-to-end training: Training all components jointly on the task without freezing parameters or blocking gradients. "This design allows us to train the whole VLA end-to-end on action data alone: with no parameter freezing, no gradient stopping, and no auxiliary VL co-training."
- Freeze-VLM: A training configuration where the VLM’s parameters are fixed and only downstream modules are trained. "Freeze-VLM, the VLM parameters are kept fixed and only the action expert is trained."
- Generative unified-multimodal model: A model that jointly handles multiple modalities and can generate visual content, used to initialize the Dorsal pathway. "We finally initialize E_{\text{dor} from a pretrained generative unified-multimodal model, which carries a prior over visual generation and scene change rather than over recognition and language."
- Heterogeneous robot data: Datasets comprising diverse robots, tasks, and action formats. "and study generalist pretraining, continuous action heads, and heterogeneous robot data."
- Knowledge-insulation mechanisms: Techniques that restrict parameter updates or gradient flow to prevent interference between objectives. "Recent work mitigates this through co-training or knowledge-insulation mechanisms, preserving semantics by adding external multimodal signals or restricting which parameters receive control gradients."
- Mixture-of-Transformers (MoT) routing: A coupling mechanism that routes tokens through parallel transformer experts. "utilizes a Mixture-of-Transformers routing to decouple semantics and control via a dorsal expert."
- Multimodal-understanding benchmarks: Standard evaluation suites that measure visual–language reasoning and comprehension. "We summarize VLM capability by the average score over a standard collection of multimodal-understanding benchmarks."
- Open-vocabulary recognition: The ability to recognize objects beyond a fixed label set. "including open-vocabulary recognition, attribute and spatial reasoning, OCR, multilingual grounding, and instruction following."
- Out-of-distribution (OOD) generalization: Robust performance on inputs that differ from the training distribution. "on a variety of manipulation tasks that probe out-of-distribution generalization, including unseen objects, novel object--target compositions, and instruction variation."
- Representational bottleneck: A structural constraint where a single encoder must serve conflicting roles, causing interference. "We hypothesize that this {representational bottleneck}, recognition and control forced through a single encoder that nature keeps separate, is a principal driver of VLA forgetting."
- Two-streams organization: The division of visual processing into ventral (what) and dorsal (where/how) pathways in primate cortex. "Neuroscience offers a direct hint: the two-streams organization of primate cortex separates a ventral pathway for object identity and semantics from a dorsal pathway for spatial layout and visuomotor control."
- UAM (Unified Action Model): The proposed three-expert VLA architecture that structurally separates semantics and control. "We propose the Unified Action Model (UAM), which adds a parallel Dorsal Expert, an analog of the brain's dorsal pathway."
- Ventral pathway: The biological visual stream specialized for object identity and semantics. "separates a ventral pathway for object identity and semantics from a dorsal pathway for spatial layout and visuomotor control"
- Visual-dynamics objective: A training loss that predicts how visual scenes evolve over time, encouraging mid-level reasoning. "train it with a mid-level reasoning objective that predicts visual dynamics."
- Vision–language–action (VLA) model: A model that maps visual observations and language instructions to robot actions. "Vision--language--action (VLA) models have rapidly become the default recipe for language-conditioned robot control."
- Vision–LLM (VLM): A pretrained multimodal backbone that understands both visual and textual inputs. "These systems are usually initialized from a pretrained vision--LLM (VLM) and then fine-tuned to emit low-level actions."
- Visual-routing analysis: An attention-based study of how visual information is routed between experts during action generation. "visual-routing analysis shows the Dorsal pathway developing action-relevant visual representations."
- World Model: A learned predictive model of environment dynamics used to improve control and generalization. "employing a World Model as the dorsal expert effectively bridges the inherent gap between vision-language representations and action execution."
Collections
Sign up for free to add this paper to one or more collections.

