- The paper introduces a unified transformer architecture that simulates various Lagrangian particle dynamics with a prediction-correction scheme, enabling cross-phenomenon generalization.
- The paper details a hierarchical token merging process that efficiently transfers local to global interaction information, significantly improving rollout fidelity and efficiency.
- The paper demonstrates superior performance against traditional neural simulation methods by accurately simulating fluids, cloth, solids, and granular media with real-time interactivity.
Unified Transformer-Based Simulation of Lagrangian Particle Dynamics
Motivation and Context
Traditional simulation pipelines for physics modeling are highly compartmentalized; each physical phenomenon—fluids, solids, cloth, granular media, or molecular dynamics—typically employs discretizations and solver backends specialized for its governing equations. This paradigm impedes cross-phenomenon coupling, increases engineering cost, and limits the flexibility of simulation systems. Recent attempts to unify the representation layer, e.g., particle-based Lagrangian methods and hybrid schemes like MPM, have demonstrated partial coverage but remain limited by solver-specific constraints and computational expense.
Learning-based simulation surrogates, especially neural approaches, have furthered the ability to sidestep explicit PDE formulation or hand-designed constitutive laws, but existing models either bind their architectures tightly to problem domains, restrict their generalizability, or fail to efficiently propagate global information in large particle systems.
This paper, "Unified Simulation of Lagrangian Particle Dynamics via Transformer" (2605.15305), introduces a transformer-based architecture designed to generalize across all major classes of Lagrangian particle dynamics, with a fixed model structure that is independent of underlying equations or discretizations. The focus is on capturing both local and global inter-particle interactions efficiently and enabling practical downstream tasks such as interactive control, inverse design, and learning from real data.
Model Architecture
Prediction-Correction Scheme
The simulation pipeline employs a prediction-correction approach. The explicit predictor integrates external forces via Newtonian update, yielding an intermediate particle state that encapsulates externally driven motion. The learned corrector then predicts interaction-driven residual position and velocity updates.
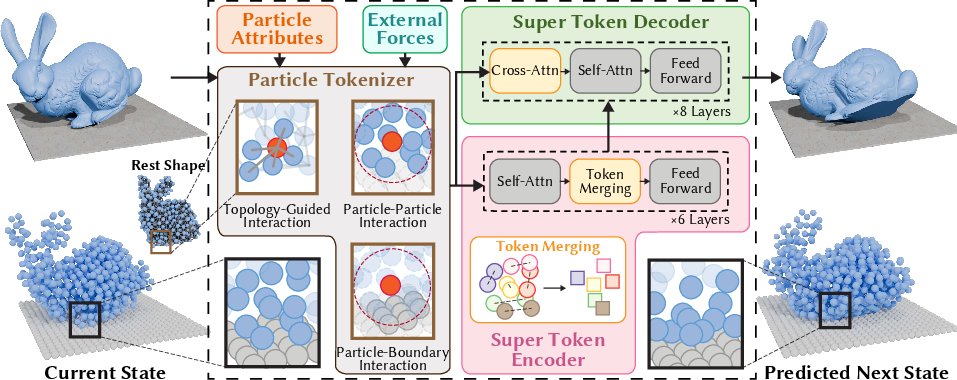
Figure 1: The prediction-correction transformer pipeline: explicit prediction of externally-driven states followed by three-stage correction for inter-particle interactions.
The corrector consists of three modular stages:
The explicit separation of external force integration from interaction modeling allows the architecture to remain equation-agnostic; phenomena only differ by training data distribution rather than architectural or interface modification.
Experimental Evaluation
Coverage and Generalization
The model is evaluated across six categories: Newtonian fluids, non-Newtonian fluids, cloth, elastic solids, granular sand, and molecular dynamics (proteins). Separate networks are trained per category, but each employs identical architecture and prediction-correction interface.
Qualitative rollouts showcase robust dynamics propagation across a spectrum of materials and boundary conditions. Notably, the architecture generalizes to previously unseen materials, boundary geometries, initial states, and external force configurations.

Figure 3: Predicted rollouts for Newtonian/non-Newtonian fluids, cloth, granular sand, and elastic solids; blue spheres denote predicted particles, white denote boundaries.
The model maintains stable long-horizon prediction and outperforms neural simulation baselines in rollout error and qualitative fidelity, avoiding artifacts such as particle instability or interpenetration common in GNS, DeepLagrangian, and neural operator surrogates. The architecture's combination of local tokenization and global communication is critical: ablation studies demonstrate that removing either pathway significantly degrades rollout quality.
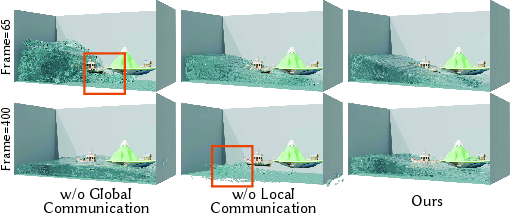
Figure 4: Ablation study: removal of super-token encoder/decoder (local only) or neighborhood-branch tokenizer (global only) both yield inferior results.
Strong claims include:
- The same transformer architecture, modulo training data, can faithfully simulate all six physical categories.
- Global communication via super tokens enables faster propagation of long-range effects (e.g., pressure, stress) than traditional graph message passing.
- The system generalizes well to unseen densities and geometries due to reliance on relative features and dynamic super-token construction.
Numerical Results
Across all categories, the model achieves lower rollout MSE for position and velocity than prior neural simulation surrogates—often by significant margins (e.g., velocity error for cloth tasks: 0.454×10−3) with competitive computation cost and throughput (11–25 frames/sec per 50k particles on A100).
Downstream Applications
The explicit predictor and differentiable architecture enable practical simulation-driven applications:
- Interactive Control: Arbitrary user-specified force applications are handled, even outside the training distribution, courtesy of explicit force integration and autoregressive rollout.
- Inverse Design: Physical parameters can be optimized via gradient descent through differentiable rollouts, facilitating tasks like recovering friction coefficients or material properties for target trajectories.
- Learning from Real Data: Direct training on particle trajectories extracted from real-world manipulation video (via PhysTwin+3D Gaussian Splatting) is possible without classical solvers. Rollouts closely track observed motion, validating practical applicability.
Practical and Theoretical Implications
The unified transformer establishes a paradigm for simulation surrogates capable of cross-phenomenon generalization and differentiable parameter recovery, shifting solver design from per-equation engineering to data-driven, representation-agnostic modeling. The hierarchical token merging scheme advances efficient scaling for large particle systems and bridges local and global communication—a recurrent bottleneck in neural physics, especially for high degrees-of-freedom and multiscale phenomena.
Remaining limitations are primarily computational: matrix attention in the first encoder layer restricts the feasible number of particles in a single batch, albeit sparse attention variants could mitigate this. Currently, weights are category-specific; scaling to a single multitask model covering all phenomena presents both data and optimization challenges, though architectural foundation is established.
Broader integration of additional per-particle attributes or observables (e.g., temperature, strain) could further enlarge the scope of addressable physical systems. Coupling with differentiable observation pipelines will bridge simulation with real-world deployment, advancing digital twin and AI-driven design workflows.
Conclusion
The presented prediction-correction transformer, through principled local tokenization, hierarchical global communication, and equation-agnostic architecture, demonstrates robust simulation surrogacy across the full range of Lagrangian particle dynamics. It empowers real-time interactive applications, differentiable design, and learning from real data—providing a foundation for future research in unified, scalable neural simulation architectures and cross-domain physical modeling.
