- The paper introduces a mesh-free neural simulator that leverages an object-centric Transformer to efficiently predict multi-object rigid-body dynamics.
- It employs innovative techniques such as anchor-based state encoding, ARoPE for geometry-aware attention, and differentiable SE(3) projection to enforce rigidity.
- Experimental results highlight lower orientation RMSE, improved computational speed (23.9 FPS), and robustness even with partial observations and large-scale scenes.
RigidFormer: Transformer-Based Mesh-Free Rigid-Body Dynamics Prediction
Introduction
"RigidFormer: Learning Rigid Dynamics using Transformers" (2605.09196) introduces a novel, mesh-free neural simulator for multi-object rigid-body dynamics, formulated around the Transformer architecture. Conventional learned simulators generally rely on mesh connectivity and vertex-level message passing, incurring high computational overhead and necessitating mesh-based geometric inputs. RigidFormer shifts the paradigm by reasoning at the object level using point clouds and anchor-based representations, thereby achieving computational efficiency, explicit rigidity enforcement, and strong generalization properties. This essay provides a detailed technical overview of the methodology, experimental validation, and implications of RigidFormer, emphasizing its object-centric approach, geometry-aware attention with ARoPE, and robust long-horizon prediction via differentiable rigid projection.
Methodology
RigidFormer operates on sequences of point clouds, where each rigid object is represented by variable-density points with optional control signals and temporal discretization input. The pipeline comprises four main stages:
- Encoding: Each object's point cloud is encoded into a single object token via a hierarchical PointNet-based network, aggregating multi-scale geometry and physical parameters (mass, friction, restitution).
- Object-Level Transformer: Object tokens are processed via multi-layer Transformers with permutation-equivariant attention, modeling direct object-to-object interactions (object-level self-attention) with optional film-style temporal conditioning.
- Anchor-Based State Advancement: Each object selects Na anchors via FPS, summarizing object state. Compact anchor features, enriched by local context through Anchor-Vertex Pooling (AVP), are used as queries into the object tokens. Anchor dynamics are advanced via a learnable acceleration predictor followed by Verlet integration.
- Rigidity Enforcement: Anchor updates are rigidly projected onto the SE(3) manifold via differentiable Kabsch alignment. The resulting transform updates all object points, ensuring exact intra-object rigidity.
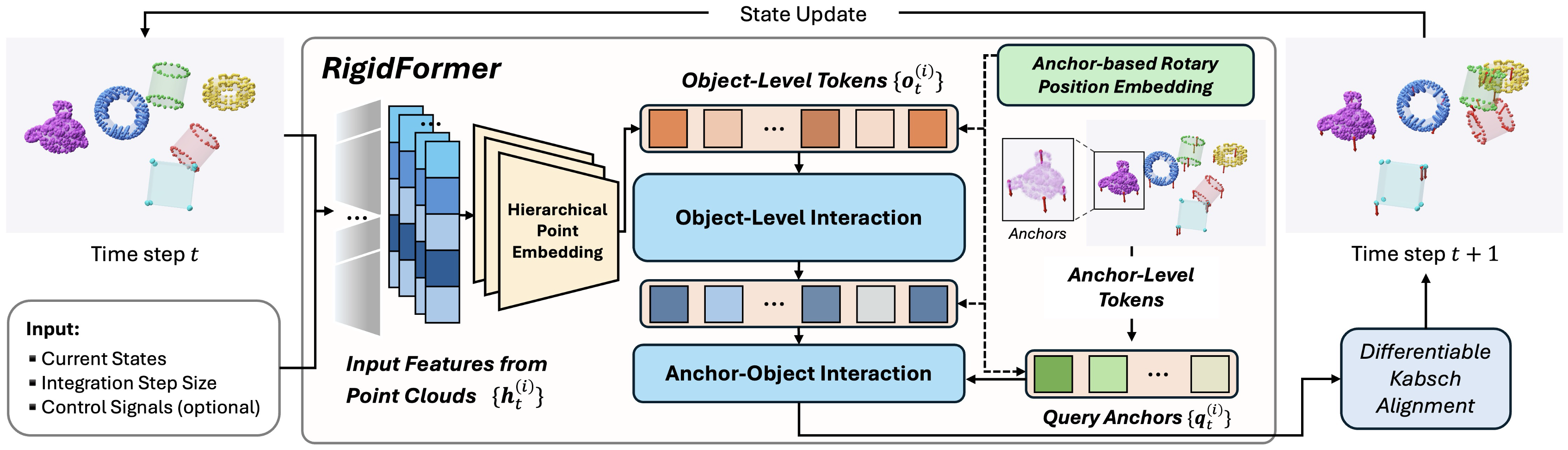
Figure 1: RigidFormer pipeline, highlighting object-to-token encoding, anchor selection, object- and anchor-level attention, and rigid body update via differentiable SE(3) projection.
This architecture reduces interaction costs from O((MNv)2) in vertex-level models to O((MNa)2), with a typical setup using M≤200 and Na=4, resulting in substantial efficiency gains.
Geometry-Aware Attention: Anchor-based RoPE (ARoPE)
Positional encoding is addressed via Anchor-based Rotary Positional Embedding (ARoPE), which encodes the spatial extent and geometry of each object using a mean-pooled rotary mapping over its set of anchors. This encoding preserves permutation-equivariance over objects and invariance to anchor reindexing, while being efficient and generalizable across arbitrary shape collections and object counts. ARoPE is integrated into the attention mechanism, modulating geometry-encoded queries and keys.
Local Geometry Injection and Rigid Projection
Contact phenomena depend on localized surface interactions, so each anchor, although representing global object motion, aggregates local geometric features from nearby vertices using AVP. This ensures contact geometry is not lost when compressing object state. After predicting anchor updates, rigid transformations are recovered via differentiable SVD-based Kabsch alignment, guaranteeing SE(3) consistency and allowing stable long-horizon rollouts.
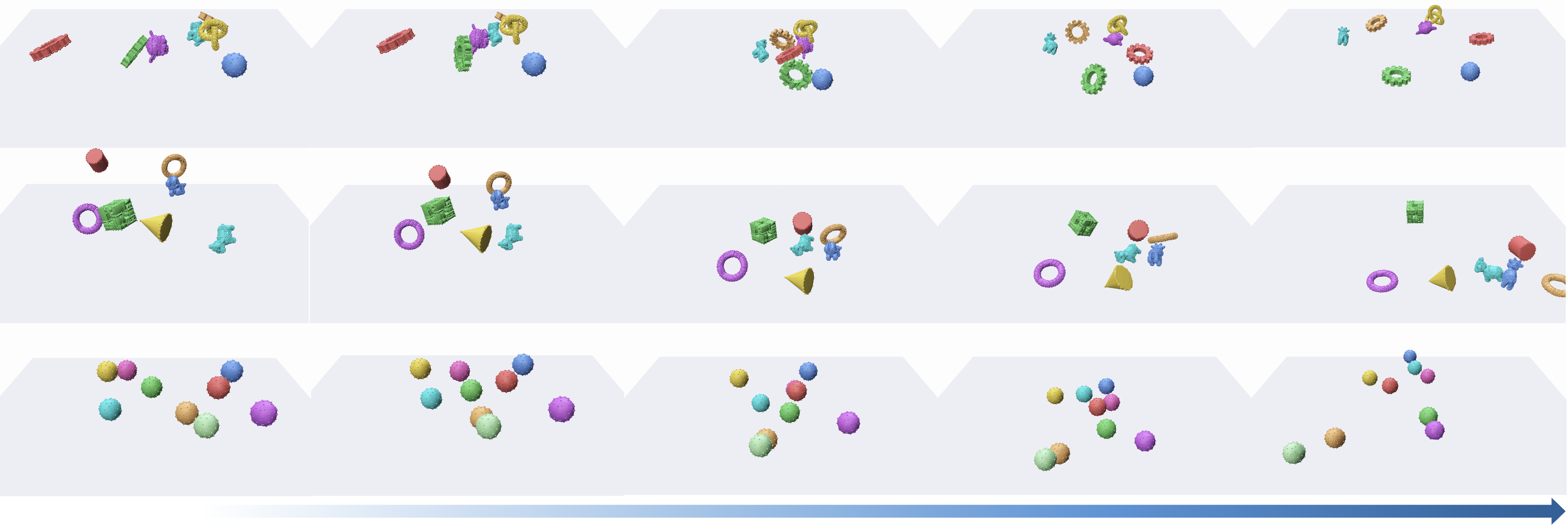
Figure 2: Qualitative results: mesh overlays show the accuracy of point-based RigidFormer rollouts; the model uses only point clouds as direct input.
Experimental Evaluation
Benchmarks and Baselines
Evaluations are conducted on the MOVi benchmarks (MOVi-A, MOVi-B, MOVi-Sphere), featuring varying object complexities and shapes. RigidFormer is compared against mesh-based baselines (HopNet, FIGNet, MGN), point-based methods (VPD), and transformer-based models (HCMT).
Numerical Results and Ablations
Scalability, Controllability, and Articulated Bodies
RigidFormer is validated on large-scale scenes (up to 216 cubes) and direction-conditioned articulated bodies (humanoid, Unitree G1) by treating each body part as an interacting object. The model follows control commands while maintaining coherent part-level dynamics, indicating extensibility beyond independent rigid bodies.
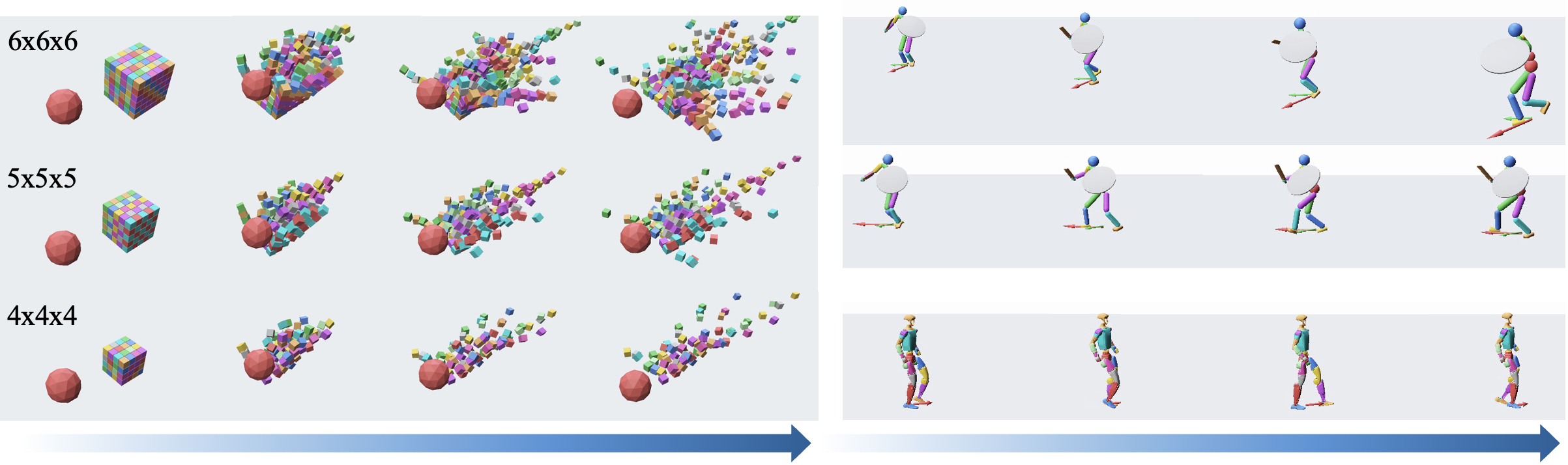
Figure 4: Left: Stable simulation as object count increases to 216. Right: Articulated agent following heading commands; arrows indicate target directions.
Theoretical and Practical Implications
RigidFormer demonstrates that object-centric, anchor-based Transformer architectures can overcome the traditional mesh-dependency and computational inefficiency in point-based rigid-body simulation. The key implications include:
- Inductive Bias: Enforcing SE(3) rigidity via differentiable Kabsch, and structuring interactions at the object level, matches the physics of rigid-body dynamics, yielding sample-efficient, robust, scalable models.
- Geometry Generalization: ARoPE provides permutation- and shape-consistent position encoding, supporting arbitrary, unordered shape collections and variable object numbers.
- Computational Scaling: Quadratic growth in object count (as opposed to vertex count) makes simulation tractable at unprecedented scales, favoring practical deployment in real-time or large-scene domains.
- Versatility: The same model architecture accommodates partial observations and basic articulated body conditioning without any mesh input or per-object tuning.
Potential future developments include extending to scenes with ambiguous perceptual segmentation, handling mixed rigid–deformable objects, and integrating uncertainty quantification for downstream control tasks.
Conclusion
RigidFormer (2605.09196) constitutes a substantive step forward in mesh-free rigid-body dynamics learning. By unifying object-centric perception, anchor-based dynamic summarization, robust geometric attention, and explicit rigidity projection, the method achieves highly efficient, generalizable, and accurate simulation on realistic multi-object scenes. Its scalability, generalization, and mesh-free flexibility set a new standard for learned physical dynamics simulation and open avenues for further research into generalized world modeling, mixed-material systems, and neural-physical hybrid planning.

Figure 5: Strong qualitative results on partial observations, diverse MOVi datasets, and articulated agent scenarios, demonstrating robustness and versatility.
