- The paper demonstrates APWA, a distributed architecture that decomposes complex agentic tasks using distinct manager, worker, and executor roles.
- It employs hierarchical planning, contract-based subtask delegation, and immutable data tables to handle large-scale, heterogeneous data efficiently.
- Experimental results show near-zero failure rates and scalable performance, outperforming traditional LLM agent frameworks in high-volume tasks.
APWA: A Distributed Architecture for Parallelizable Agentic Workflows
Motivation and Problem Statement
The proliferation of autonomous LLM-based multi-agent systems has unlocked diverse application domains; however, as task size and complexity increase, these systems encounter severe bottlenecks in reasoning, coordination, and computational throughput. Traditional LLM agents and multi-agent frameworks struggle with high-volume data processing, hitting limits imposed by finite context windows, lack of distributed reasoning primitives, and inefficient global coordination mechanisms. Prior frameworks are largely restricted to narrowly-scoped workflows, with insufficient abstractions for scalable task decomposition, parallel execution, or handling heterogeneous data patterns. The problem addressed is how to architect an AI agent environment analogous to distributed data processing paradigms (e.g., MapReduce, Spark), enabling automated and efficient parallelizable workflow execution for agentic systems.
APWA System Architecture
APWA introduces a distributed agentic execution model, centered on novel hierarchical abstractions—manager, worker, and executor—specifically designed for massively parallelizable task decomposition and execution.
The manager holds a global view of task execution, decomposing tasks into non-interfering subtasks suitable for parallel dispatch. Subtasks are specified via contract-based templates and enable guided planning, leveraging abstractions for communication of large-scale data. The workers assume the role of solving individual subtasks and are provisioned with agent presets and dynamic toolsets. Workers operate in sandboxed environments and maintain only local state, facilitating autonomous subproblem exploration. The executor manages distributed deployment over a cluster, handling resource allocation, node placement, automatic retries, and failure recovery, abstracting away low-level infrastructure concerns.
APWA is implemented atop Ray, a distributed scheduling substrate supporting task-parallel execution at scale, capable of processing hundreds of thousands of concurrent subtasks and millions per second throughput. The design leverages isolated worker environments, efficient subtask routing (including lightweight LLM-only paths), and a scalable, content-addressed object store for distributed data artifacts.
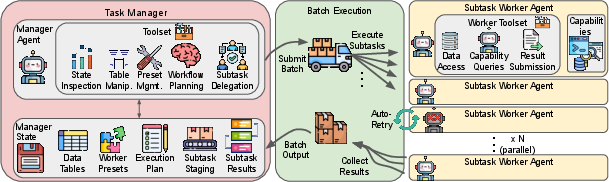
Figure 1: APWA decomposes tasks into parallelizable workflows via agent workers, orchestrating execution in a distributed environment.
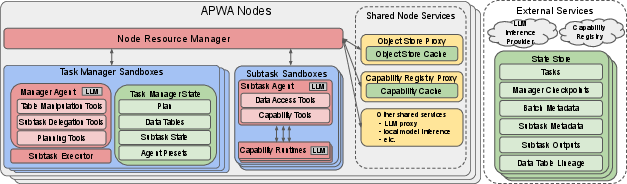
Figure 2: APWA's distributed architecture, detailing manager, worker, executor, and resource abstractions.
Core Abstractions for Distributed Agentic Computation
APWA introduces several abstractions critical for distributed agentic workflows:
- Planning for Parallelization: Managers dynamically generate structured plans encoding partition strategies and procedural steps, explicitly modeling parallel task decomposition. Output contracts, formalized via data table specifications, gate task completion.
- Subtask Delegation: Subtask templates enable efficient batch specification of parallel units of work, decoupling logical specification from data scale. Placeholders are used for scalable parameterization.
- Data Tables: Immutable, lineage-tracked tables support reasoning over large, heterogeneous datasets. Managers interact with data via dedicated tool suites, supporting analytics and manipulation operations, all formatted for context-efficient LLM consumption.
- Dynamic Agent Capabilities: At runtime, managers discover and leverage capabilities through a registry, constructing agent presets tailored to each subtask, facilitating dynamic instantiation and composition of specialized tools.
This architectural paradigm achieves efficient, automated task decomposition, scalable coordination among large agent teams, individualized agentic exploration, flexible handling of data- and task-parallel workflows, and domain-agnostic applicability.
Experimental Evaluation
APWA was evaluated on benchmarks spanning large-scale PII data redaction (PII-300k), structured extraction (SchemaBench), hierarchical summarization (SummaryBench), and agent-powered web report synthesis. Metrics include utility (structural correctness, semantic accuracy), runtime, and failure rates. Baselines included direct LLM invocation, Magentic-One, and MegaAgent.
Results:
- Scalability: APWA maintained 0% failure rate for all tasks and input sizes, scaling to large hierarchies (e.g., 2.5k concurrent workers for summarization) with moderate increases in wall-clock runtime (e.g., 157s for small corpus to 329s for large corpus; sublinear scaling for web surf tasks).
- Output Quality: Structural integrity (>0.9) and semantic scores (up to $0.53$ ROUGE-F1 for summarization) were preserved as task size increased, contrasting sharply with baselines which degraded or failed entirely.
- Baselines: Magentic-One failed on large tasks due to orchestration and context explosion; MegaAgent exhibited high failure rates and format errors. Direct LLM use only solved tasks fitting within the context window.
Highlighted Numerical Results:
- APWA achieved $0.954$ structural and $0.424$ semantic scores on Romeo and Juliet summarization, $0.983$/$0.370$ on the Roman corpus.
- In PII-300k, APWA preserved $0.9$ structural and $0.544$ semantic scores on the largest dataset, with near-perfect scores on smaller inputs.
- Runtime scaling across 100 web surf topics was >0.90 that for 10 topics, indicating amortized execution overhead.
Theoretical and Practical Implications
APWA fundamentally advances agentic workflow execution by bridging distributed system design with LLM-driven agent frameworks. The formalization of planning and data abstractions, along with scalable coordination and execution, addresses longstanding limitations in agentic reasoning over large datasets. The architecture accommodates heterogeneous and dynamic processing patterns, enabling practical deployment in domains requiring high-throughput, parallel processing (e.g., healthcare, scientific research, privacy-sensitive data analysis).
Practically, APWA facilitates robust agent orchestration, reliable execution, and efficient resource utilization, mitigating orchestration bottlenecks and context scaling failures inherent in prior systems. The use of contract-based output gating and immutable, lineage-tracked data models improves output fidelity, recovery, and system robustness.
Theoretically, APWA demonstrates that distributed computation paradigms can be integrated within agentic environments by introducing abstractions that are amenable to both LLM-based reasoning and scalable execution. It decouples the logical control plane from the physical execution layer, enabling broader generalization across domains and data modalities.
Limitations and Future Directions
Limitations include the lack of direct communication between workers, restricting coordination for subtasks requiring inter-agent dialogue, and insufficient generalization to parallelization patterns beyond those evaluated. Security and privacy concerns (e.g., prompt injection, data leakage) remain unaddressed; guardrails and systematic attack surface analysis are necessary.
Future developments may include richer agent communication topologies, more sophisticated planning primitives spanning dynamic role assignment and recursive decomposition, integration with persistent memory, and systematic safety mechanisms. Research into scheduling optimizations, heterogeneous cluster resource allocation, and cross-agent coordination should be prioritized to further enhance scalability and applicability.
Conclusion
APWA establishes a robust, scalable multi-agent architecture for parallelizable agentic workflows, introducing programming and execution abstractions that empower LLM-based agents to reason about and process large volumes of distributed data. Empirical evaluation evidences superior scalability and output fidelity compared to the state-of-the-art, with implications for both theoretical advancement and practical deployment in high-throughput agentic systems. Further exploration of coordination mechanisms, generalization, and security is warranted to maximize utility across emerging domains.