- The paper introduces Pythia, which leverages predictable agent workflows to optimize caching, scheduling, and autoscaling in LLM serving.
- It employs a workflow profiler that builds probabilistic finite automata to predict output lengths and agent behavior for proactive resource management.
- Experimental results show significant gains, including up to 2.9× reduced job completion times and 25.5× improvement in cache reusability.
Pythia: Predictability-Driven Agent-Native LLM Serving
Introduction and Problem Definition
Modern multi-agent architectures decompose LLM-powered workflows into interacting, specialized agents tailored to complex task decomposition. The resulting system exposes strong semantic regularities, deviating from the prevailing assumption of continual unpredictability in traditional LLM serving. Existing frameworks, which operate under black-box APIs, fail to utilize the structured behavioral patterns, leading to substantial inefficiencies, notably in prefix cache effectiveness, GPU resource contention, and scaling latency. A detailed analysis of production multi-agent traces reveals these systemic limitations: low prefix cache hit rates due to agent prompt diversity and invocation gaps, severe load imbalances across replicas, and congestion rooted in bursty, unanticipatable workflow waves.
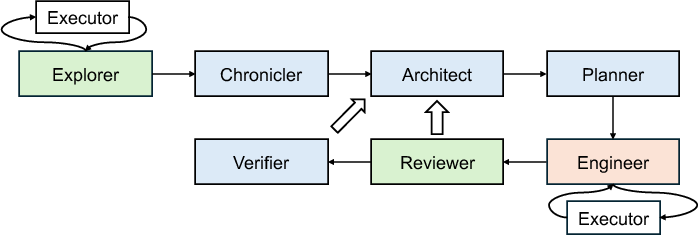
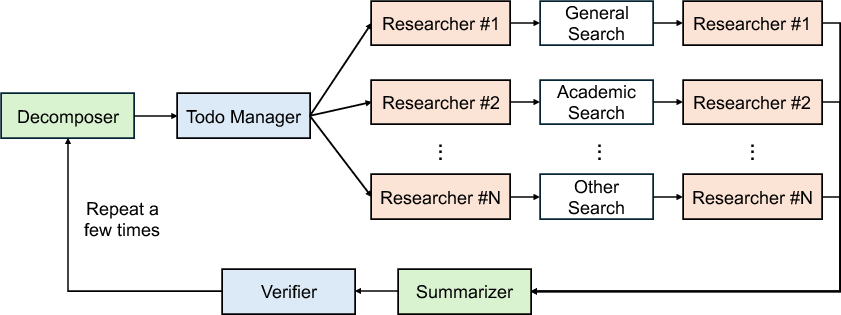
Figure 1: Canonical examples of multi-agent workflows illustrate structural predictability and division of labor among specialized agents.
Key Insights: Workflow Predictability
Contrary to the traditional LLM serving paradigm, multi-agent workflows yield highly predictable execution semantics. Each agent operates within a structurally constrained graph, facilitating robust division of labor and yielding consistent input/output distributional properties. High-level agents (architects, planners) execute decomposition, while lower-level agents handle specialized tasks (engineering, reviewing, verification). Such partitioning allows for reliable estimation of token generation behavior, workload propagation, and inter-agent dependencies—a foundation for shifting from reactive to proactive serving strategies.
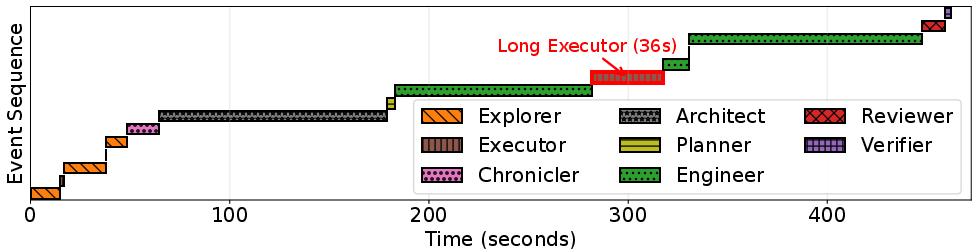
Figure 2: Timeline analysis of a coding agent workflow, highlighting long inter-agent delays, narrow cache reuse windows, and distinct agent roles.
Architecture and Predictive Workflow Profiling
Pythia addresses the observed inefficiencies by incorporating workflow semantics directly at the serving layer. It introduces a lightweight, agentic metadata interface leveraging standard OpenAI-compatible API extensions. Upon request dispatch, agentic frameworks inject identifiers for the workflow type, session, and agent role.
A dedicated Workflow Profiler processes annotated logs to construct regular-expression-based behavioral models, synthesizing probable execution graphs as probabilistic finite automata. For each agent type, the profiler characterizes output length distributions and prompt assembly templates, maintaining tight high-probability intervals rather than overfitting to pathological, rare trajectories.
Pythia annotates each in-flight request with:
- A bounded output length prediction.
- A regular expression describing subsequent workflow paths.
- Prompt composition templates including token range pointers for both historical requests and agent responses.
This unified mechanism enables downstream system stages (cache management, scheduling, autoscaling) to leverage fine-grained, actionable predictions.
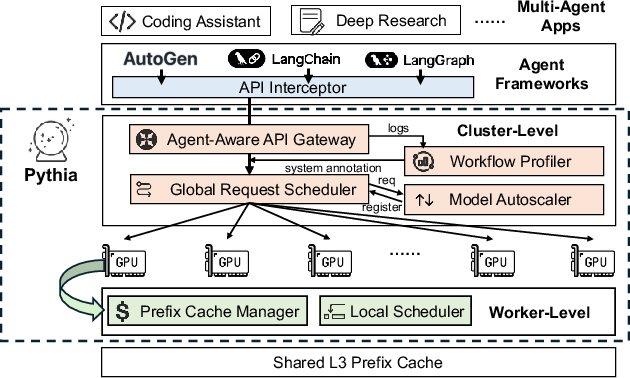
Figure 3: System overview of Pythia, depicting integration of workflow profiling, annotated request handling, and predictive serving pipeline.
Speculative Cache Management
Pythia replaces recency-based cache management with a workflow-aware, Belady-inspired speculative cache mechanism. By parsing the anticipated execution path:
- Dead tokens and transient contexts without future dependencies are immediately evicted.
- Context blocks likely to be reused downstream are proactively staged in shared, cross-node KV caches.
- Prefetching is performed using compositional prompt templates; the manager assembles the predicted prompt and initiates asynchronous cache warming when compute resources are available.
The system balances speculative GPU cache staging with memory constraints, holding prefetched items in lower tiers when agent-path uncertainty is high or when current requests still monopolize GPU resources.
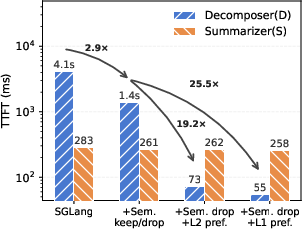
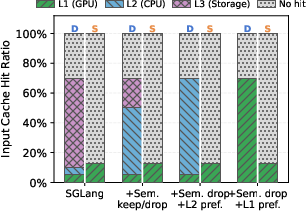
Figure 4: Workflow-aware speculative prefix cache management achieves substantial improvements in TTFT and cache hit rates from the lower cache tiers.
Lookahead Request Scheduling
Pythia eschews standard FCFS and naive priority heuristics. Instead, routing employs statistical capacity reservation using predicted upper bounds on agent output lengths, ensuring strict guarantees on OOM rates via union bounds without parametric distributional assumptions.
At the cluster level, global scheduling establishes priorities by minimizing expected remaining path length (accelerating finalization of jobs) and boosting the priorities of requests unblock downstream idle agents. This graph-theoretic arbitration modulates job starvation and enables precise, proactive load balancing, driving utilization efficiency while preventing head-of-line blocking and excessive preemptions.
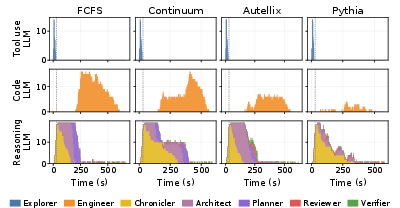
Figure 5: GPU queue dynamics demonstrating that Pythia’s lookahead scheduling balances queuing delays and GPU utilization, avoiding the queue buildup characteristic of prior policies.
Phase-Adaptive Autoscaling
Unlike metric-smoothing reactive autoscalers, Pythia’s phase-adaptive control plane consumes predicted workflow transitions to anticipate demand spikes and fan-out events. It projects imminent agent activations using regular-expression-guided reachability within a lookahead horizon, then provisionally scales target model replicas before queue buildup occurs. Redundant or obsolete model capacity is rapidly reclaimed, with scale-down coordinated to minimize disruption and ensure timely resource reallocation.
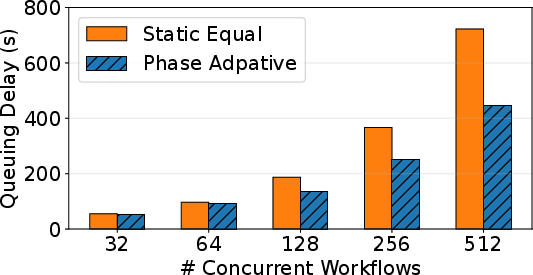
Figure 6: Comparison of queuing delays, showing Pythia’s proactive autoscaling strategy reduces cluster bottlenecks compared to static resource allocations.
Experimental Results
Pythia demonstrates significant system-level improvements over representative baselines (vLLM, SGLang, Continuum, Autellix, ThunderAgent) across rigorous workloads (e.g., SWE-bench Pro, Deep Research Bench):
- Average JCT: Up to 2.9× reduction.
- Throughput: Up to 1.96× improvement.
- TTFT for cache-reusable agents: 25.5× improvement.
- P95 JCT (tail latency): Reduced by up to 2.02×, critically without starving long-tail workflow components.
These gains are attributable to the fine-grained, workflow-driven coordination across caching, routing, and scaling, cementing the utility of predictable agentic behaviors in hardening serving systems.
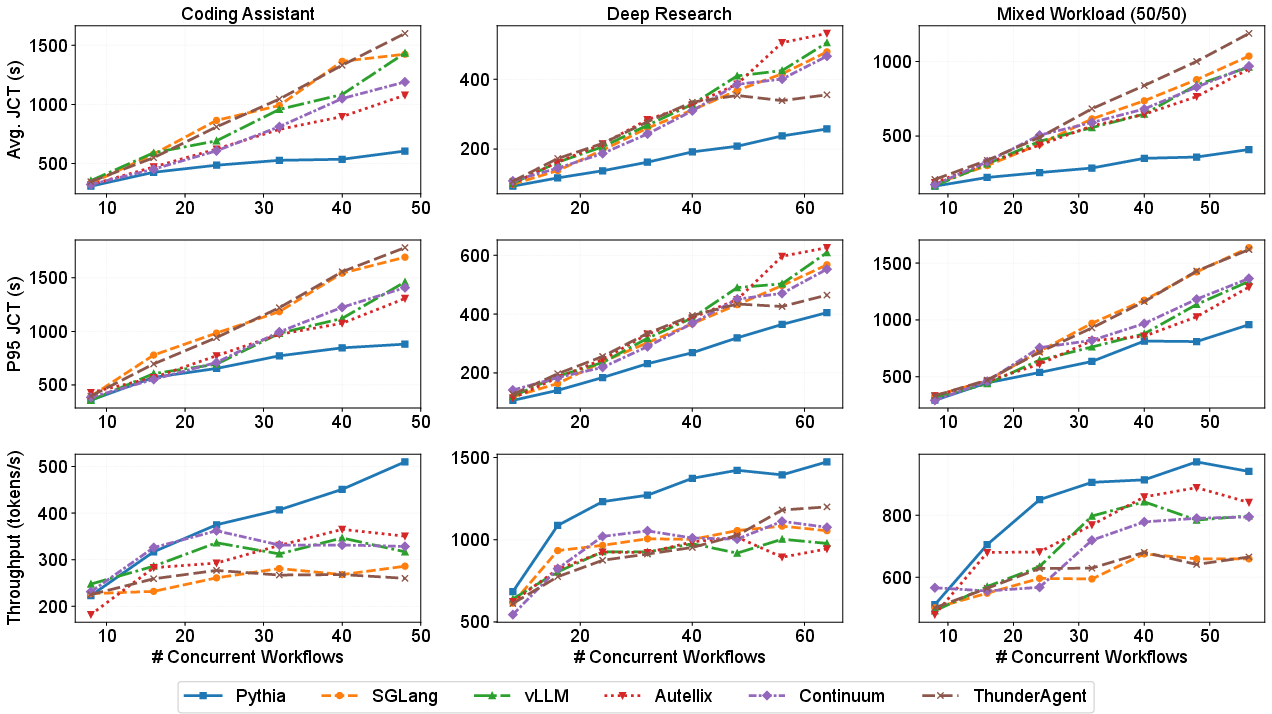
Figure 7: End-to-end experimental results validating JCT and throughput scaling advantages of Pythia as concurrency intensifies.
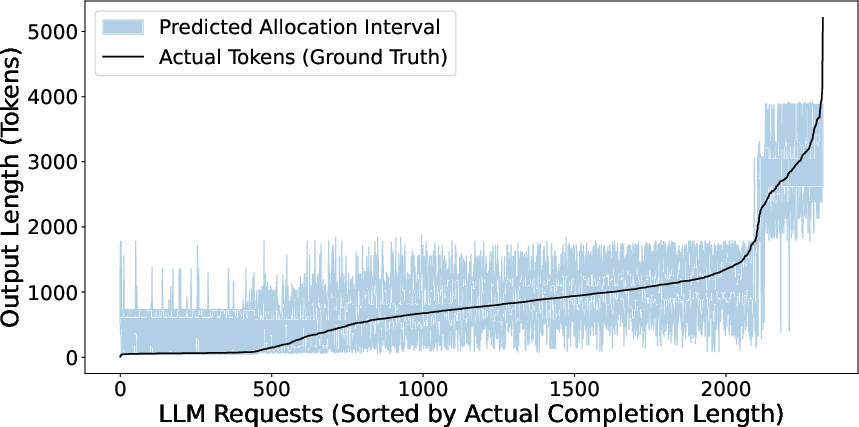
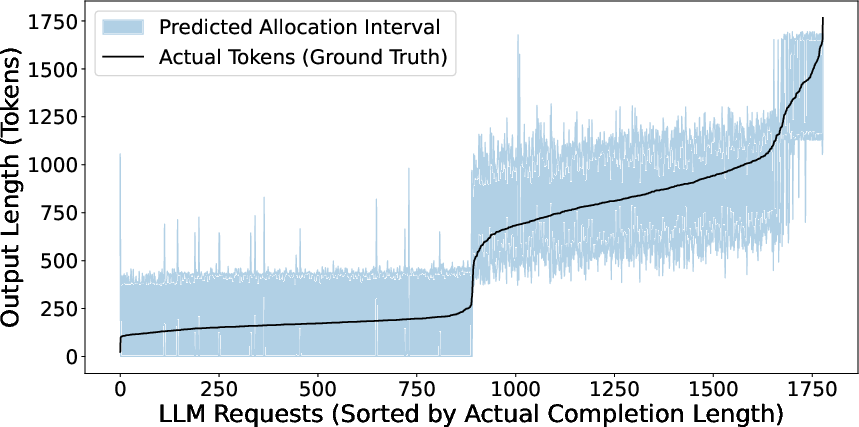
Figure 8: Distribution of predicted versus actual output lengths demonstrates tight, high-confidence interval calibration across diverse agent roles.
Discussion and Implications
The Pythia framework underscores that agentic LLM workloads embody structural and behavioral regularities amenable to static and dynamic program analysis techniques. The resulting predictive power unlocks new avenues for:
- Fine-grained resource management: Ensuring cluster utilization remains high even as workload burstiness or agent heterogeneity increases.
- Workflow-aware prioritization: Avoiding downstream resource idleness and bottlenecks in complex, interdependent agent pipelines.
- Service-level objectives (SLOs) and fairness: A natural extension of Pythia’s scheduling is the integration of per-workflow priority weights and SLO constraints, facilitating multi-tenancy in production.
Limitations include transient cold-start inefficiencies (ameliorated via shadow tracing and fallback strategies) and degradation under adversarial or unstructured agent graphs. Hybrid approaches, where predictable workflows are handled by Pythia and unconstrained workloads are served reactively, provide a tractable mitigation.
Conclusion
By systematically leveraging the inherent structural predictability of multi-agent LLM workflows, Pythia enables proactive, specification-driven optimizations across cache management, request scheduling, and autoscaling. This paradigm results in strong system efficiency improvements and paves the way for future research into highly adaptive, SLO-aware serving systems for increasingly complex AI agent workflows.
References
(2604.25899)

