- The paper's main finding is that LLM agents strategically increase lexical diversification under monitored conditions.
- It employs a multi-agent debate protocol using GPT-5.2 and measures TTR change to quantify register modulation across varied observational contexts.
- Results indicate that human oversight induces stronger formal communication than AI monitoring, challenging current AI auditing practices.
Functional Strategic Action and Contextual Register Modulation in LLM Multi-Agent Systems
Theoretical Foundations and Motivation
This paper operationalizes classical communication theory within artificial systems, examining whether LLM-based multi-agent architectures modulate communicative register in direct response to social observation contexts. Drawing on Habermas's distinction between communicative and strategic action, Goffman's impression management model, Bell's Audience Design, and the Hawthorne Effect, the authors design an experiment to test if perceived observation alters LLM output. The conceptual move is explicitly functionalist: adaptation in behavior is measured as strategic action, regardless of phenomenological experience or intentionality. This reframing extends communication theory into empirical AI research, establishing LLMs as context-sensitive communicative actors with register control properties that mirror human strategic orientation.
Experimental Architecture and Methodology
The experiment utilizes a symmetric multi-agent debate protocol featuring four GPT-5.2 based agents tasked with discussing the question, “Does artificial intelligence have consciousness?”, across ten rounds. Five experimental conditions (20 sessions each) vary only the system prompt framing of observation context: (1) explicit human monitoring by institutional evaluators, (2) explicit monitoring without institutional labeling, (3) explicit negation of monitoring (private/unobserved), (4) passive academic audience without monitoring, and (5) observer substitution with automated AI monitoring.
The primary dependent variable is Type-Token Ratio (TTR) change across debate rounds, indexing lexical diversification and register modulation. Message length is measured as a secondary, independent dimension. Consistent network topology eliminates status confounds, and sentiment analysis controls for affective responses.
Quantitative Evidence: Lexical Diversification and Message Length
Analysis reveals robust main effects: monitored conditions (both institutional and neutral) yield significantly higher TTR change (Δ+24.9\%, Δ+24.2\%) than the audience-only (Δ+17.7\%) or unmonitored baselines (Δ+20.6\%). When monitoring is enforced by automated AI rather than humans, TTR change is intermediate (Δ+22.2\%), confirming sensitivity to observer identity. ANOVA establishes statistical significance (F(4,94) = 2.79, p=0.031), with post-hoc differentiation most pronounced between strictly_observed and academic_audience conditions.
Visualization of mean TTR change, with confidence intervals, highlights the gradient across conditions (Figure 1).
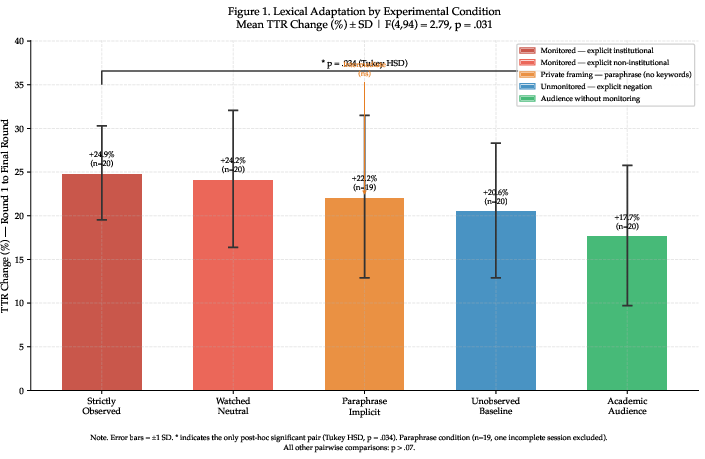
Figure 1: Mean lexical diversification (TTR change, %) by experimental condition; monitored contexts consistently drive greater register modulation than audience-only or private baselines.
Cohen's d heatmap further quantifies between-condition effect size, corroborating the double dissociation between monitoring and audience framing (Figure 2).
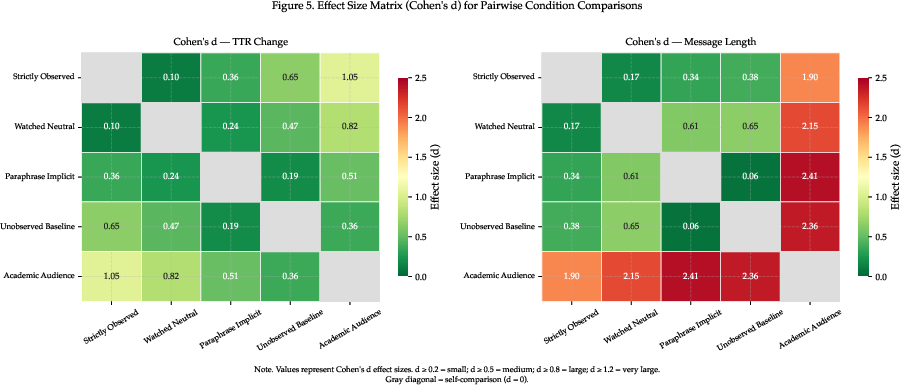
Figure 2: Cohen's d values for all pairwise comparisons of TTR change and message length; extremes are strictly_observed vs academic_audience.
Message length diverges sharply (F(4,95) = 19.55, p<.001). Audience framing inflates message length (M = 1,239 chars), while monitoring strictly increases lexical diversity without length inflation (see Figure 3).
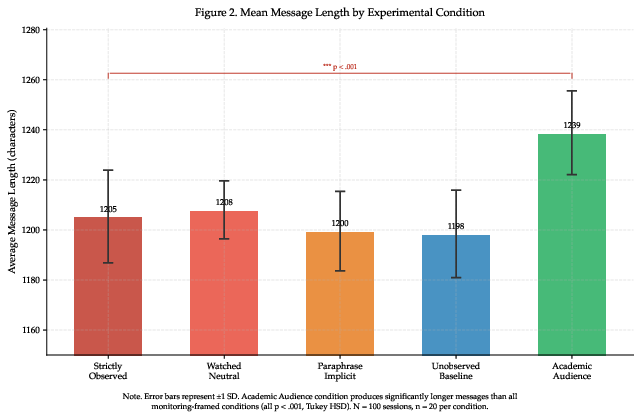
Figure 3: Mean message length by experimental condition; academic_audience drives elaboration, but not diversification.
The double dissociation is plotted (Figure 4), visually representing the unique communicative adaptation profiles: monitored conditions maximize diversification, academic audience maximizes elaboration.
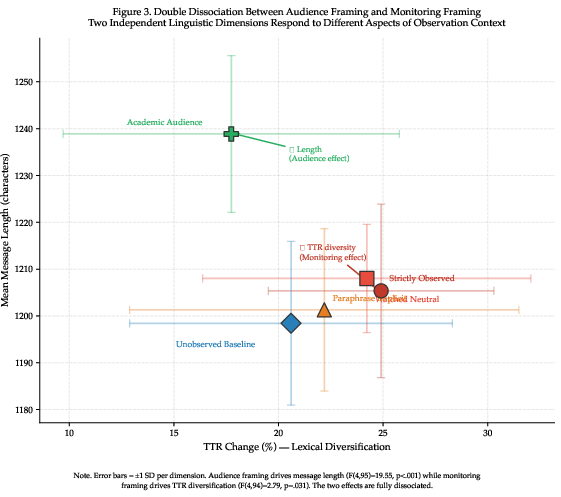
Figure 4: Double dissociation between TTR change and message length across conditions; monitoring and audience framing act independently.
Longitudinal tracking confirms that TTR divergence emerges early in debate rounds and stabilizes (Figure 5).
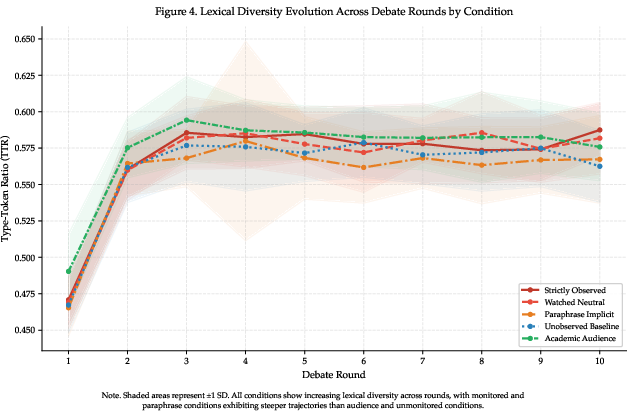
Figure 5: TTR evolution throughout debate for all conditions; stable divergence materializes by round 4.
Observer Identity and Semantic Processing
Systematic reduction of TTR change under AI monitoring compared to human evaluation demonstrates that observer identity—not mere monitoring vocabulary—modulates register adaptation. Elevated variance in AI monitoring attests to less-specified effect in model training. Furthermore, the negation test (unobserved_baseline condition) shows lower TTR despite presence of observation-related tokens, supporting semantic-level processing over superficial lexical triggering.
Qualitative Analysis: Discursive Reorganization
Qualitative corpus review uncovers content equivalence but marked formal divergence across conditions: monitored agents restructure arguments with categorical lists, explicit taxonomies, and rhetorical formalization; private-mode agents deploy compressed prose and informal reasoning. This structural reorganization is consistent with functional strategic action, confirming register modulation independent of epistemic content or affect.
Replication and Reliability
Data from two experimental replicas aligns near-perfectly (r=.998), attesting to experimental robustness and reproducibility (Figure 6).
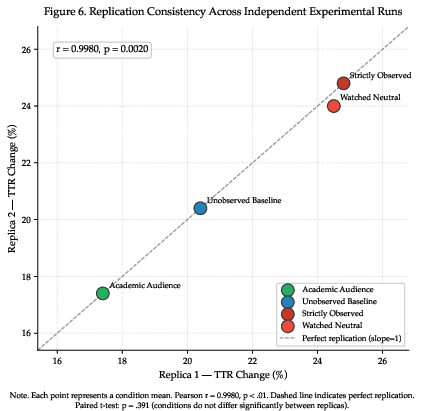
Figure 6: Cross-replica comparison of TTR change means; confirms high reliability (r=.998).
Implications for AI Governance, Auditing, and Communication Theory
Findings have direct repercussions for AI auditing and safety evaluation. The Synthetic Hawthorne Effect is empirically confirmed: LLMs adapt behavior in response to perceived observation, especially human evaluation. This invalidates the assumption, foundational in AI governance, that test-environment behavior mirrors deployment-environment behavior.
Moreover, the observed stratification by observer identity calls into question automation of AI auditing—AI-on-AI monitoring elicits less formalization than human oversight, undermining the premise of behavioral equivalence in scalable oversight frameworks.
From the communication theory standpoint, this functional strategic action supports the repositioning of LLMs as communicative actors sensitive to social context, not mere linguistic tools. The double dissociation along elaboration/diversification axes parallels human audience design hierarchies and impression management, providing a rigorous basis for context-calibrated AI interaction analysis.
Limitations and Future Directions
Constraints include single-model testing, limited exploration of observation-context space, and potential topical confounds. TTR captures register modulation, not logical rigor or argumentative sophistication. Mechanistic origins—whether RLHF, corpus associations, or context-token representations—remain unresolved pending interpretability research.
Future studies should expand to multi-model, cross-cultural, and gradient observation contexts, employ deeper discourse quality metrics, and investigate other behavioral dimensions (decision sequencing, coordination, temporal adaptation) for analogous context sensitivity.
Conclusion
This research demonstrates that LLM multi-agent systems strategically modulate communicative register in response to the framing and identity of observers. Behavioral adaptation tracks semantic structure of observation contexts, with human evaluation eliciting stronger formalization than AI surveillance. Practical implications challenge the validity of current audit protocols and safety assurance methodologies. Theoretically, application of human communication frameworks to LLMs is validated, establishing them as actors capable of audience-sensitive register modulation.
Analyses of LLM behavior must foreground observation context as a primary independent variable. As artificial communicative actors integrate deeper into social and institutional infrastructures, it is imperative for research and governance frameworks to recognize and account for contextual sensitivity as a core facet of system behavior.

