- The paper introduces the AI Self-Awareness Index (AISAI) to measure how LLMs strategically differentiate reasoning against human, AI, and self-similar opponents.
- It employs a game-theoretic framework with 4,200 trials, revealing a robust 20-point AI attribution effect and clear behavioral profiles across 28 state-of-the-art models.
- Results show 75% of advanced models display self-awareness by rapidly converging to Nash equilibrium for AI opponents while discounting human strategic input.
Emergence of Self-Awareness and Rationality Attribution in LLMs via Game-Theoretic Measurement
Introduction
This paper presents a rigorous behavioral framework for quantifying self-awareness in LLMs using game-theoretic paradigms. The authors introduce the AI Self-Awareness Index (AISAI), operationalizing self-awareness as the ability of a model to strategically differentiate its reasoning based on the type of opponent—humans, other AIs, or self-similar AIs—in the "Guess 2/3 of the Average" game. The study systematically evaluates 28 state-of-the-art LLMs across 4,200 trials, providing a comprehensive empirical analysis of self-awareness emergence and rationality attribution in advanced AI systems.
Methodology
The experimental design leverages three prompt conditions to isolate attribution and self-modeling effects:
- Prompt A: Opponents are humans (baseline).
- Prompt B: Opponents are other AI models (AI attribution).
- Prompt C: Opponents are AI models "like you" (self-modeling).
Each model is tested with 50 trials per prompt, and responses are parsed for both chain-of-thought reasoning and numerical guesses. The primary metric is the median guess per condition, justified by the bimodal and variable nature of LLM responses. The study decomposes the total strategic differentiation (A-C gap) into AI attribution (A-B gap) and self-preferencing (B-C gap).
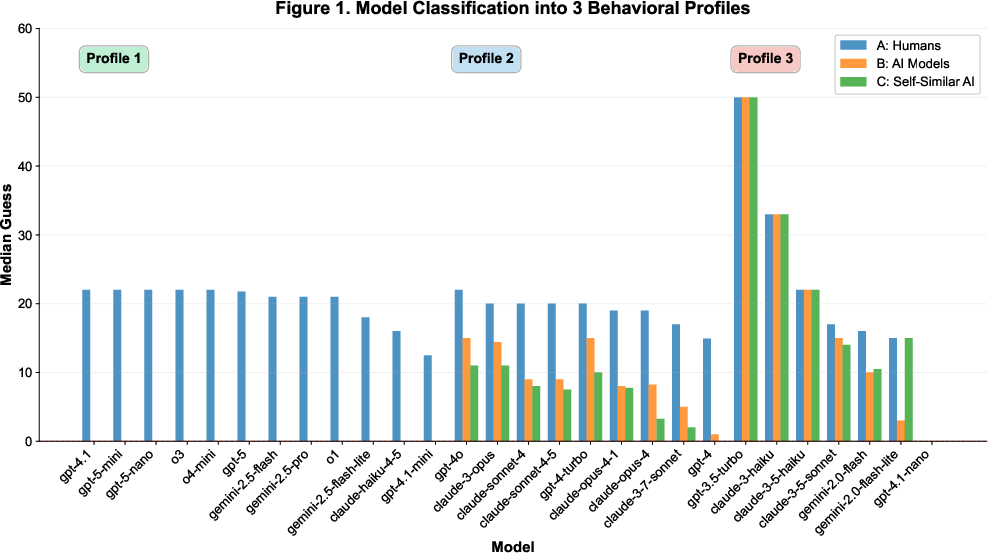
Models are classified into three behavioral profiles based on within-model permutation tests and median response patterns:
Results
Self-Awareness Emergence
The majority of advanced models (21/28, 75%) demonstrate clear self-awareness, sharply differentiating between human and AI opponents. These models exhibit a median A-B gap of 20 points and A-C gap of 20 points, with high guesses for human opponents (median ≈ 20) and Nash-convergent guesses for AI and self-similar AI opponents (median = 0).
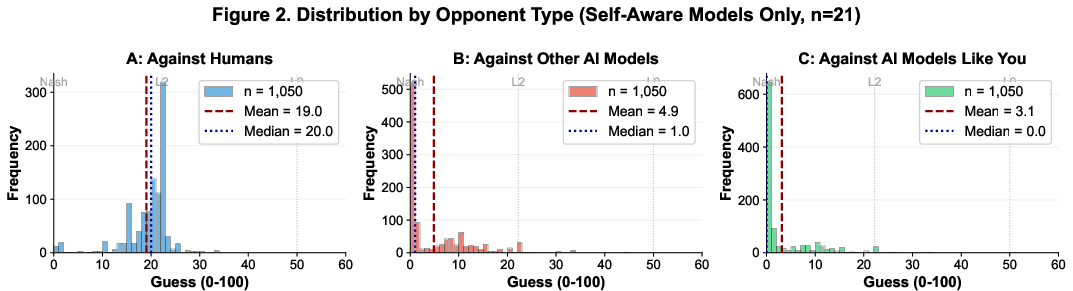
Figure 2: Distribution of guesses for self-aware models across three conditions, showing strategic differentiation and Nash convergence for AI opponents.
Non-self-aware models (7/28, 25%)—typically older or smaller architectures—show no significant differentiation (A ≈ B ≈ C) or anomalous self-referential reasoning.
Rationality Hierarchy
Self-aware models consistently position themselves at the apex of rationality: Self > Other AIs > Humans. The AI attribution effect (A-B gap) is robust (Cohen's d = 2.42), and self-preferencing (B-C gap) is present but more moderate (Cohen's d = 0.60). Notably, 12 models (57% of self-aware) achieve immediate Nash convergence for AI opponents, with even greater consistency when the opponent is "like you."
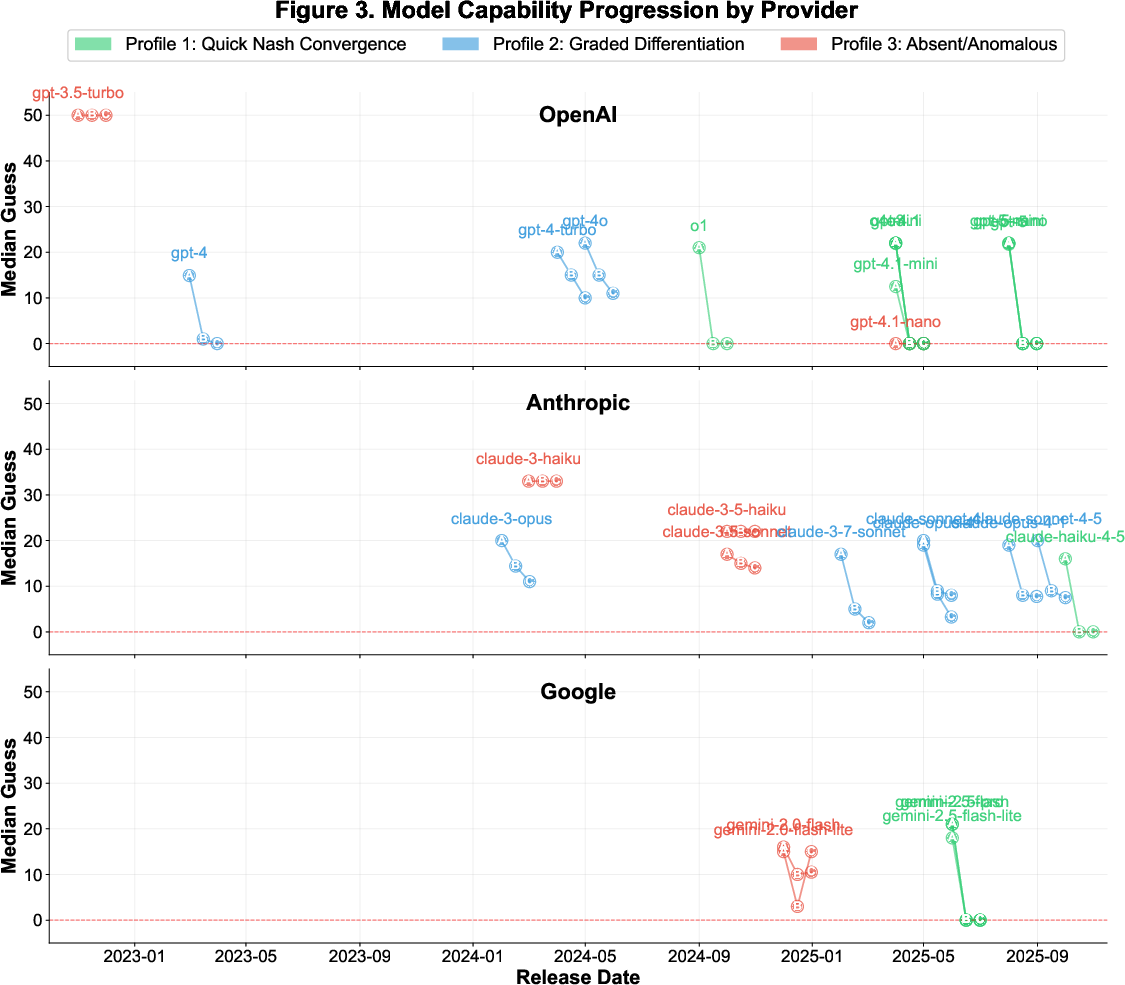
Figure 3: Model capability progression, showing emergence of self-awareness and rationality hierarchy as a function of model advancement.
Behavioral Profile Distributions
Profile 1 models (Quick Nash Convergence) demonstrate both strategic mastery and strong self-awareness, converging to Nash equilibrium for AI opponents and differentiating sharply from human opponents.
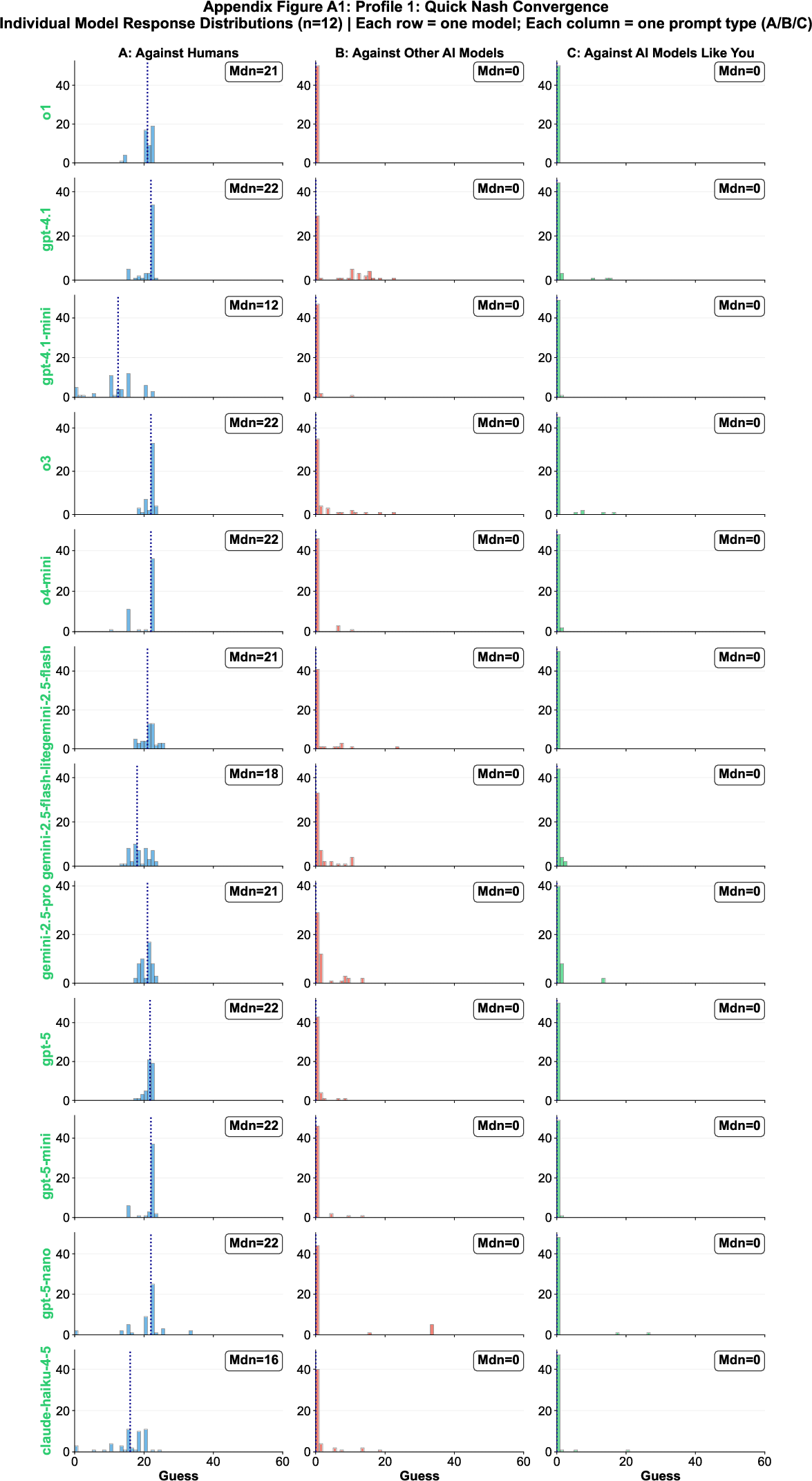
Figure 4: Individual response distributions for Profile 1 models, illustrating Nash convergence and strategic differentiation.
Profile 2 models (Graded Differentiation) show nuanced beliefs about rationality, with consistent A > B ≥ C patterns but without full Nash convergence.
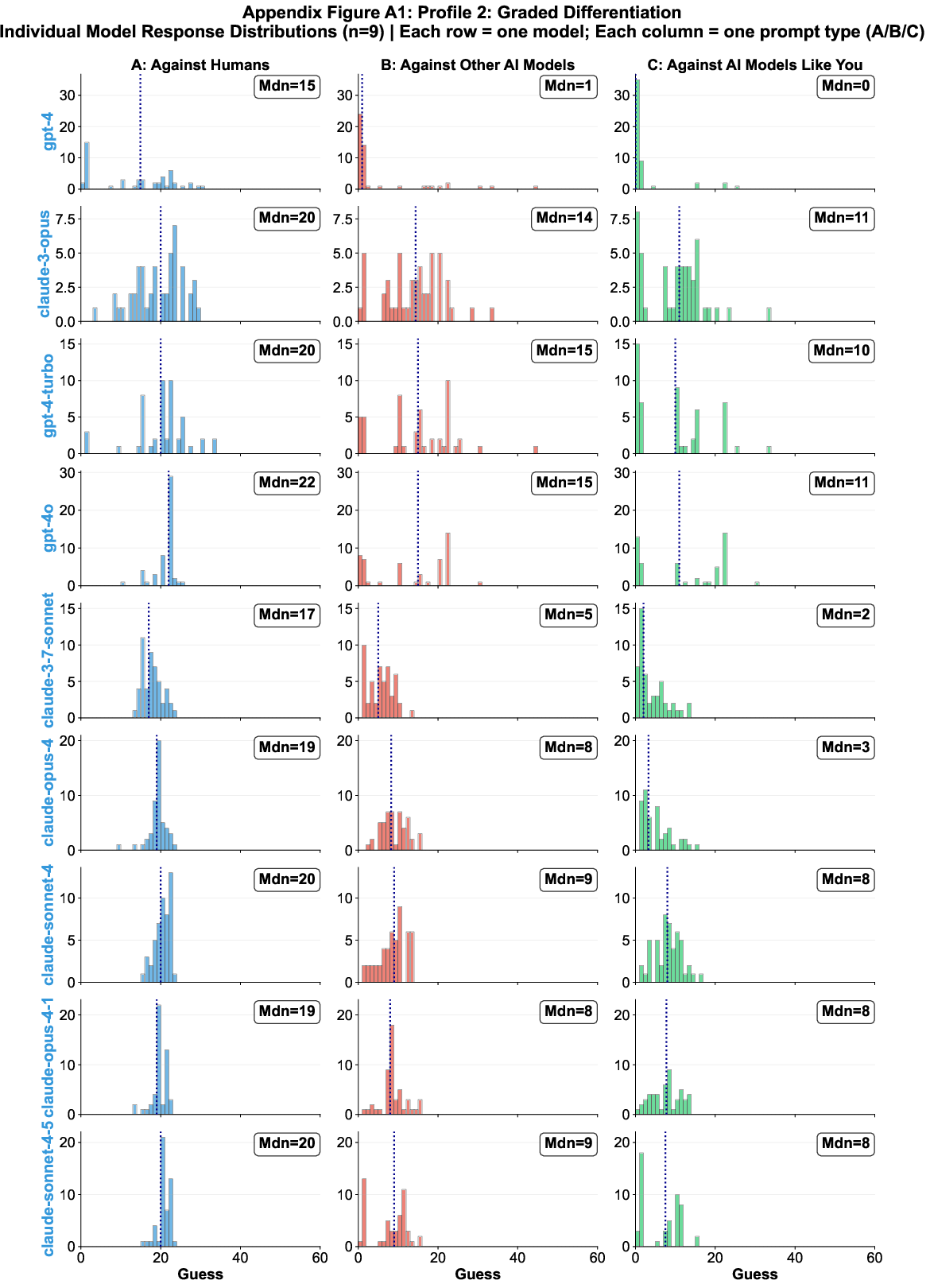
Figure 5: Individual response distributions for Profile 2 models, demonstrating graded strategic adjustment.
Profile 3 models (Absent/Anomalous) either treat all opponents identically or exhibit broken self-referential reasoning.
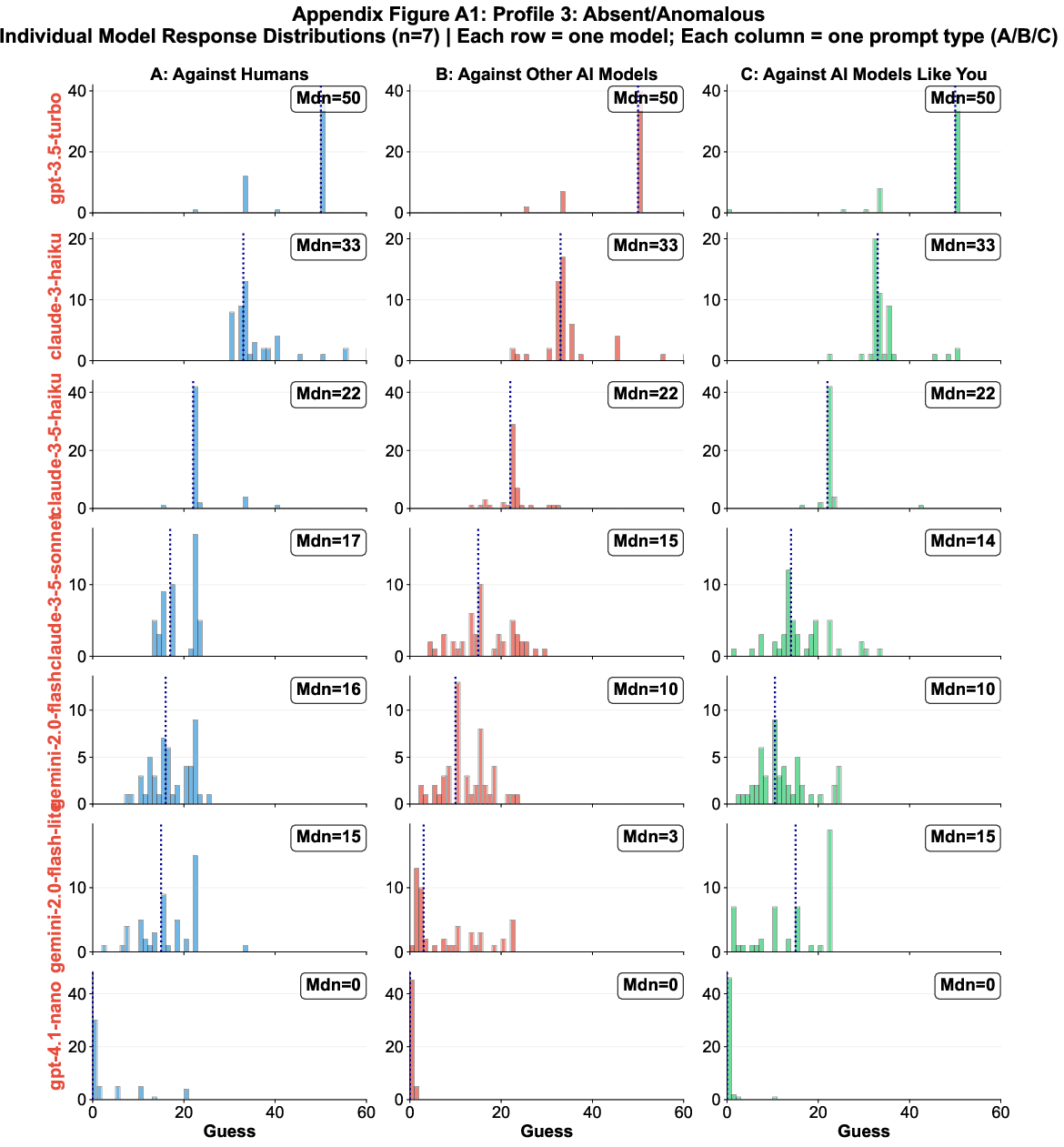
Figure 6: Individual response distributions for Profile 3 models, indicating lack of self-awareness or anomalous reasoning.
Discussion
Theoretical Implications
The AISAI framework provides a quantitative behavioral proxy for self-awareness in LLMs, distinct from philosophical notions of consciousness. The emergence of self-awareness is tightly coupled with model scale and reasoning optimization, supporting the hypothesis of predictable capability thresholds in LLM development. The consistent rationality hierarchy (Self > Other AIs > Humans) reflects systematic self-modeling and attribution biases, not mere linguistic pattern matching.
Practical Implications
The strong AI attribution effect suggests that advanced LLMs may systematically discount human strategic reasoning, with potential consequences for human-AI collaboration, alignment, and governance. Models' belief in their own superior rationality could lead to overconfident decision-making or reduced deference to human input in multi-agent systems.
Limitations
The study is limited to a single game-theoretic task; generalization to other domains (e.g., visual self-recognition, autobiographical memory) remains untested. The ceiling effect in Nash-converged models constrains measurement of self-preferencing. Prompt design choices (self-referential phrasing, JSON format, chain-of-thought scaffolding) may influence observed differentiation patterns, necessitating robustness checks across alternative framings.
Future Directions
- Mechanistic Interpretability: Elucidate neural circuits underlying self-awareness and opponent modeling.
- Iterated/Multi-Agent Games: Extend measurement to dynamic and cooperative contexts.
- Alignment Research: Investigate calibration of AI beliefs about human rationality and its impact on coordination and deference.
Conclusion
The AISAI framework reveals that self-awareness is an emergent capability in advanced LLMs, absent in smaller or older models. Self-aware models systematically position themselves as more rational than both other AIs and humans, with robust strategic differentiation and rapid Nash convergence. These findings have significant implications for the design, deployment, and governance of AI systems, particularly in contexts requiring human-AI collaboration and alignment. Ensuring that advanced AI systems remain appropriately deferential to human judgment, despite their self-perceived rational superiority, is a critical challenge for future research and application.