AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
Abstract: Few-step video generation has been significantly advanced by consistency distillation. However, the performance of consistency-distilled models often degrades as more sampling steps are allocated at test time, limiting their effectiveness for any-step video diffusion. This limitation arises because consistency distillation replaces the original probability-flow ODE trajectory with a consistency-sampling trajectory, weakening the desirable test-time scaling behavior of ODE sampling. To address this limitation, we introduce AnyFlow, the first any-step video diffusion distillation framework based on flow maps. Instead of distilling a model for only a few fixed sampling steps, AnyFlow optimizes the full ODE sampling trajectory. To this end, we shift the distillation target from endpoint consistency mapping $(z_{t}\rightarrow z_{0})$ to flow-map transition learning $(z_{t}\rightarrow z_{r})$ over arbitrary time intervals. We further propose Flow Map Backward Simulation, which decomposes a full Euler rollout into shortcut flow-map transitions, enabling efficient on-policy distillation that reduces test-time errors (i.e., discretization error in few-step sampling and exposure bias in causal generation). Extensive experiments across both bidirectional and causal architectures, at scales ranging from 1.3B to 14B parameters, demonstrate that AnyFlow achieves performance matches or surpasses consistency-based counterparts in the few-step regime, while scaling with sampling step budgets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AnyFlow, a new way to make AI models that generate videos. The big idea is to let one model produce good videos with any number of steps: a few fast steps for quick previews, or many careful steps for higher quality—without retraining a different model.
What did the researchers want to find out?
They focused on a problem with today’s fast video generators: many “few-step” methods work well when you use only a tiny number of steps, but they actually get worse when you try more steps. The team asked:
- Can we build a “one model fits all” system that improves as you give it more time (more steps), instead of breaking down?
- Can we keep the speed of few-step methods while regaining the quality boost that comes from using more steps?
- Can this work for both kinds of video models:
- bidirectional (looks at all frames together) and
- causal/autoregressive (creates frames one after another, like a storyteller)?
How did they try to solve it?
Think of video generation like cleaning up a very noisy video until it looks clear. Each “step” is like one pass of cleaning. Most fast methods teach a model to jump straight to the final clean result in one leap. That’s fast, but if you try to do many small leaps, it starts to drift off the right path.
AnyFlow changes the lesson the model learns:
- Instead of only learning “jump to the end,” it learns “move from any time to any other time” along the correct path. This is called a “flow map.” Imagine a GPS that can guide you from any point on a route to any other point, not just to the final destination. That way, the model can take big jumps (fast) or small steps (careful) and still stay on the right route.
To make this work well, they use two training stages:
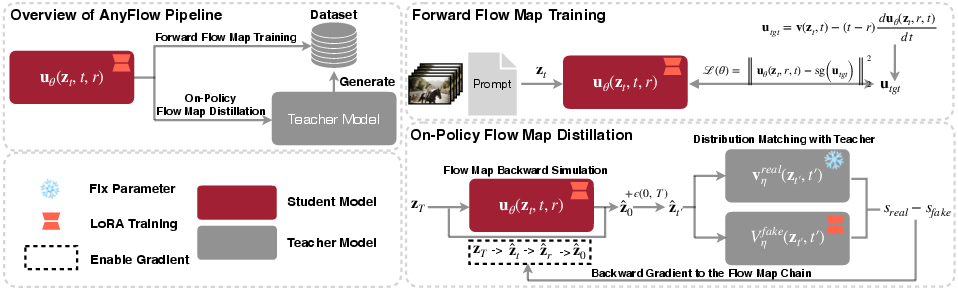
- Stage 1: Forward Flow Map Training
- The model practices moving between lots of different time points, not just to the end. The authors add stability tricks so training doesn’t explode:
- Interpolated timestep conditioning: blends time signals so the model stays close to what it already knows.
- Better time sampling and loss weighting: balances easy and hard cases.
- Guidance-fused training: bakes in text guidance so you don’t need extra guidance tricks at test time.
- Stage 2: On-Policy Distillation with “Backward Simulation”
- “On-policy” means the model learns from its own generated videos, while a stronger “teacher” model tells it how to improve.
- Backward simulation: to compute learning signals, the model runs itself from noisy start to clean end.
- Key innovation: Flow Map Backward Simulation
- Instead of simulating every tiny step (which is slow), the model uses its flow map to take smart “shortcuts” between times. Think of skipping parts of the route by taking trustworthy, direct side roads that still keep you on track.
- This reduces two common errors:
- Discretization error: cutting corners when you use only a few big steps.
- Exposure bias (in causal models): small mistakes compound when each new frame depends on the previous generated frames.
In short: Stage 1 teaches the model the whole route; Stage 2 fine-tunes it using its own behavior, with efficient shortcuts, so it stays accurate whether you take few or many steps.
What did they discover?
Across different model sizes (from 1.3B to 14B parameters) and different architectures (bidirectional and causal), AnyFlow:
- Matches or beats popular fast methods when using very few steps.
- Keeps getting better as you add more steps—exactly what you want from a flexible “any-step” model.
Some headline numbers (higher is better on these benchmarks):
- Causal text-to-video (14B model):
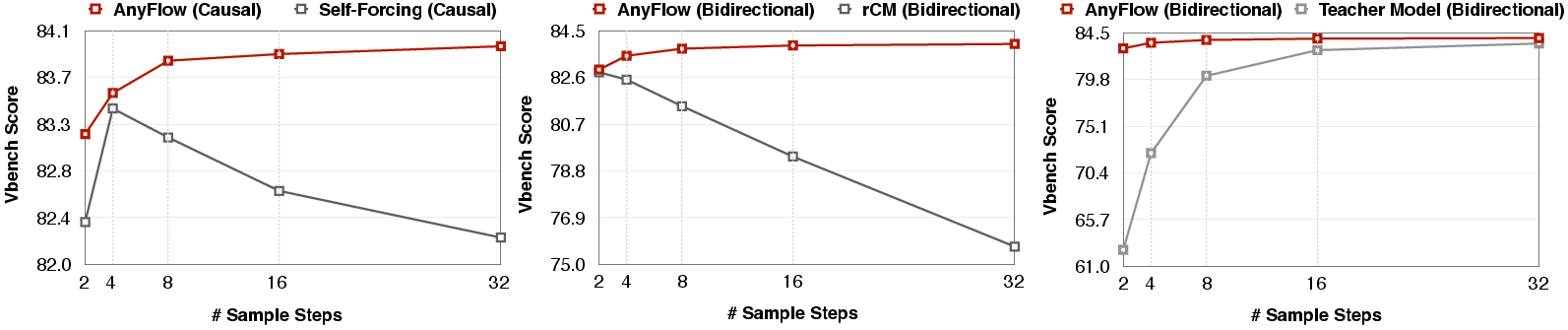
- 84.05 at 4 steps (NFEs) and 84.41 at 32 steps.
- This surpasses a strong baseline (Krea-Realtime-14B: 83.25 at 4 steps).
- Image-to-video (14B model):
- 87.87 at just 4 steps, comparable to a large model that uses far more steps (Wan2.1-I2V-14B at 87.71 with 100 steps total).
- Bidirectional text-to-video (14B model):
- 84.04 at 4 steps, beating a leading consistency-based method (rCM-14B at 83.73).
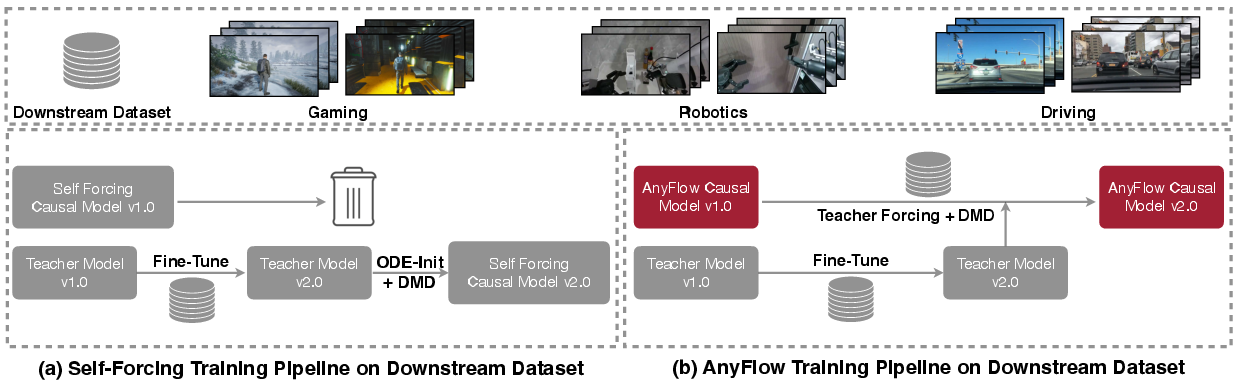
They also show that AnyFlow models can be fine-tuned for special tasks (like robotics or driving scenes) without starting from scratch, which is handy in the real world.
Why does this matter?
- One model, many speeds: You can get fast previews or high-fidelity videos by simply changing how many steps you use—no retraining needed.
- Better scaling: Quality improves with more steps instead of getting worse.
- Works in more situations: It handles both “all-at-once” and “frame-by-frame” video generators.
- Easier to adapt: You can keep training the same model for new domains, saving time and compute.
Key terms in simple words
- Diffusion model: A method that starts with noisy images/videos and removes noise step by step to create clear results.
- Steps (NFEs): How many times the model cleans up the noise. More steps usually mean more quality but more time.
- Consistency distillation: Teaching a fast “student” to jump from noisy to clean in one go by learning from a strong “teacher.”
- Flow map: A learned tool that moves you from any point in time to any other point along the clean-up path, not just to the end.
- On-policy distillation: Training the student on its own outputs while the teacher guides corrections—so it learns to handle its own mistakes.
- Discretization error: The inaccuracy you get when you approximate a smooth path with only a few big hops.
- Exposure bias (causal models): Errors pile up because each new frame depends on the model’s previous, possibly imperfect frames.
In essence, AnyFlow gives video generators a flexible, reliable “route map,” so they can travel fast or carefully—and still arrive at a great-looking video.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of gaps the paper leaves unresolved. Each item is concrete and framed to help future researchers act on it.
- Theoretical guarantees and error bounds:
- Provide formal convergence and error bounds for flow map backward simulation relative to PF-ODE Euler sampling; quantify composition error in chained transitions as a function of step size, time interval length, and model prediction error.
- Analyze stability and correctness when approximating long trajectories via shortcut flow-map segments (associativity/semigroup properties of learned transitions), and derive conditions under which chaining does not accumulate bias.
- Step-size policies and schedulers:
- Investigate optimal selection of intermediate timesteps (t, r) during backward simulation beyond the simple rule r = t − T/s; develop adaptive or learned step-size schedules that minimize discretization error across budgets.
- Evaluate higher-order ODE solvers (e.g., Heun, Runge–Kutta) with flow-map transitions versus Euler, including computational trade-offs and test-time scaling behavior.
- Training dynamics and objectives:
- Quantify the stability and sensitivity of the interpolated timestep conditioning scheme (fixed g = 0.25); study g as a learnable parameter, annealing schedule, or conditional function, and compare against zero-init or alternative embeddings.
- Systematically ablate the time sampler and reweighting function w(t) to derive principled sampling distributions linked to the noise schedule and PF-ODE curvature.
- Assess the impact of the proposed adaptive loss reweighting (50% boundary samples at t = r) on bias and overfitting to the instantaneous velocity field; explore alternatives that preserve global trajectory fidelity.
- Characterize the interplay between forward flow map training and DMD-based on-policy distillation (loss weighting, joint vs. alternating updates), and provide guidance on hyperparameters to avoid instability.
- Exposure bias and causal rollout metrics:
- Introduce dedicated metrics for exposure bias and long-horizon drift in causal models (e.g., autoregressive error accumulation curves, identity/motion consistency metrics) beyond aggregate VBench scores.
- Validate AnyFlow on long videos (minutes-scale) to measure temporal stability and KV-cache behaviors under the FAR chunking strategy; quantify how chunk sizes and patchify kernels affect motion fidelity and memory.
- Compute, memory, and reproducibility:
- Report comprehensive training/inference costs for flow map backward simulation (full backprop through chains vs. truncation, checkpointing), including memory footprint, throughput, and energy; provide reproducible configs for different model scales.
- Compare rollout efficiency versus consistency-based backward simulation across diverse step budgets, quantifying the exact savings from shortcut decomposition.
- Evaluation breadth and rigor:
- Evaluate across a wider NFE spectrum (e.g., 1, 2, 8, 64, 128 NFEs) to stress-test any-step behavior; include confidence intervals and statistical significance across seeds.
- Add human studies and domain-specific evaluations (e.g., motion realism, temporal coherence, identity preservation, physical plausibility) to complement VBench metrics.
- Report Video-to-Video (V2V) results (claimed support but no quantitative evaluation), and include robustness tests under resolution/fps changes, camera motion, and complex dynamics.
- Data dependence and domain shift:
- Measure the distribution shift induced by synthetic teacher data (e.g., texture smoothness), and compare training on the base model’s original data versus synthetic/augmented datasets; propose mitigations (domain-adaptive objectives, curriculum).
- Analyze how teacher quality and mismatch (weaker/stronger teachers, different PF-ODEs) affect student performance and whether the student can surpass the teacher; codify conditions for successful distillation.
- Downstream fine-tuning:
- Provide quantitative evidence for downstream continued training (robotics/driving identity and trajectory metrics), sample efficiency (data/steps needed), and avoidance of catastrophic forgetting; define standardized protocols for application-specific tuning.
- Control and conditioning:
- Study how guidance-fused training (CFG fused into predictions) impacts controllability, semantic alignment, and diversity when guidance is omitted at test time; evaluate robustness across prompt distributions and OOD prompts.
- For I2V, test sensitivity to noisy/low-quality first frames and the chosen non-uniform chunk partition (first chunk size 1 vs. alternatives); quantify trade-offs between motion accuracy and throughput.
- Modalities and generalization:
- Extend and evaluate AnyFlow for multimodal inputs (audio, text+image), multiview/3D video generation, and cross-domain generalization; test across diverse pretrained backbones beyond Wan2.1 (e.g., Hunyuan, CogVideoX) with controlled comparisons.
- Methodological comparisons and integration:
- Perform direct empirical comparisons with concurrent flow-map distillation approaches (e.g., TMD), and explore hybrid methods combining architectural sharing (flow head) with trajectory shortcutting.
- Investigate alternative on-policy objectives (e.g., adversarial post-training, hybrid DMD+adversarial) tailored to flow-map models to further reduce rollout mismatch.
- Numerical details and robustness:
- Analyze the differential derivation finite-difference scheme (epsilon choice, bias/variance) used in MeanFlow-based training; propose numerically stable approximations for large-scale FSDP training.
- Quantify per-step discretization error and trajectory divergence under multi-step sampling, linking errors to learned flow-field smoothness and time-interval lengths.
- Safety and governance:
- Address safety, bias, and content moderation in any-step generation pipelines, including how step budgets interact with safety filters and controllability; define evaluation protocols and mitigation strategies.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging AnyFlow’s any-step video diffusion, flow-map distillation, and efficient on-policy training to improve quality/latency trade-offs, robustness, and adaptability.
- Flexible quality–latency dial in production video generation
- Sectors: media and entertainment, advertising, game development, software/SaaS
- Use case: preview at 4 NFEs for rapid iteration, then re-render at 16–32 NFEs for final delivery without retraining or model swapping
- Tools/products/workflows: “AnyFlow Inference Engine” with an NFE slider; automatic scheduler switching to Euler; CFG-free test-time inference for speed; batch “upgrade” pipeline that reprocesses approved previews to final assets
- Assumptions/dependencies: availability of a pretrained teacher model and compute; accurate PF-ODE trajectories; content safety filters
- Real-time interactive text-to-video and image-to-video generation for prototyping
- Sectors: product design, UX, creative studios, social platforms
- Use case: live prompt editing with instant previews at low NFEs; step up quality in-session when feedback stabilizes
- Tools/products/workflows: plug-ins for editing tools (e.g., After Effects, Blender); web UI with step-budget controls; KV-cache reuse for causal models (FAR pipeline) to maintain responsiveness
- Assumptions/dependencies: GPU memory for KV-cache; stable latency targets; moderation and watermarking integrated
- Cost-efficient image-to-video conversion at near–state-of-the-art quality
- Sectors: e-commerce, marketing, social content, newsrooms
- Use case: turn product images or thumbnails into short video clips at 4 NFEs (VBench-I2V ≈87.87), comparable to much larger sampling budgets
- Tools/products/workflows: “I2V Batch Converter” with AnyFlow-FAR; configurable motion templates and camera moves; A/B testing pipelines
- Assumptions/dependencies: source image licensing; motion templates tuned to domain; minimal distribution shift for brand aesthetics
- Domain adaptation via continued fine-tuning on specialized datasets
- Sectors: robotics, autonomous driving, industrial inspection, sports analytics
- Use case: improve identity preservation (e.g., robot arm types) and trajectory accuracy in domain-specific videos using continued training on downstream datasets without retraining the whole causal generator
- Tools/products/workflows: “AnyFlow Fine-Tuning Toolkit”; data curation from in-domain footage; evaluation suites for trajectory and identity metrics
- Assumptions/dependencies: access to domain datasets with appropriate rights; GPU capacity; potential mild distribution shift if synthetic teacher data differs
- Robust short-sequence causal video generation with reduced exposure bias
- Sectors: social media, live content tools, interactive apps
- Use case: autoregressive short clips and loops that remain coherent across frames for prompts with complex motion; unified T2V/I2V/V2V in one causal model
- Tools/products/workflows: FAR-based chunking (non-uniform: 1 then 3) with asymmetric patchify to manage KV-cache; Euler sampling; scheduler presets per latency tier
- Assumptions/dependencies: FAR pipeline integration; domain prompts validated; exposure bias further reduced via on-policy distillation
- Dataset augmentation for downstream perception and vision tasks
- Sectors: robotics, autonomous driving, retail analytics
- Use case: generate rare or hazardous scenarios (weather, occlusions, unusual motion) to augment training sets; control NFEs to trade speed vs fidelity
- Tools/products/workflows: “Scenario Generator” with curriculum prompts; label-transfer or weak supervision; QA pipeline that increases NFEs for borderline cases
- Assumptions/dependencies: synthetic-to-real gap management; data governance; labeling strategy for generated sequences
- Cloud inference optimization and cost control
- Sectors: cloud providers, ML platform teams, video SaaS
- Use case: dynamic step-budget allocation based on SLA and budget; low NFEs for previews and high NFEs only on final assets
- Tools/products/workflows: “AutoNFE” allocator; per-tenant latency/quality policies; server-side Euler scheduler; CFG-free test-time optimization
- Assumptions/dependencies: telemetry and QoS enforcement; cost observability; capacity planning
- Immediate research integration and reproduction
- Sectors: academia, R&D labs
- Use case: drop-in flow-map distillation for existing video diffusion backbones; test-time scaling studies; exposure bias ablation
- Tools/products/workflows: open-source AnyFlow code; DMD-based on-policy training; FSDP-aware training recipes; evaluation on VBench/VBench-I2V
- Assumptions/dependencies: access to teacher checkpoints; GPUs; consistent evaluation protocols
- Education and public communication content
- Sectors: education technology, online learning, public outreach
- Use case: generate explainers, lab demos, and visualizations rapidly; refine selectively based on engagement metrics
- Tools/products/workflows: LMS plug-ins with AnyFlow; preview-to-production pipelines; content safety checks
- Assumptions/dependencies: safe prompt libraries; institutional review and provenance requirements
Long-Term Applications
These applications require additional research, scaling, or development—especially around long-video training, safety, physical consistency, and on-device optimization.
- Autoregressive long-video generation and storytelling with any-step scaling
- Sectors: film previsualization, sports broadcast, virtual events, education
- Use case: coherent long-form video with interactive refinement where latency budgets vary across segments (e.g., fast drafts vs final shots)
- Tools/products/workflows: extended FAR training for long contexts; hierarchical chunking and memory management; multi-pass refinement with variable NFEs
- Assumptions/dependencies: dedicated long-video training, memory-efficient architectures, improved exposure-bias mitigation
- High-fidelity synthetic environments and digital twins for simulation
- Sectors: robotics, autonomous driving, smart manufacturing, defense
- Use case: generate diverse scenario libraries for training and evaluation, including edge cases and rare events; use higher NFEs for physically critical sequences
- Tools/products/workflows: “Scenario Twin Studio” built on AnyFlow; physics-aware prompt templates; automated quality gates that raise NFEs when realism checks fail
- Assumptions/dependencies: better physical accuracy constraints; domain adaptation; integration with simulators and evaluation toolchains
- Personalized, on-device real-time video generation
- Sectors: mobile devices, AR/VR, creator tools
- Use case: latency-aware creative assistants that run locally, letting users dial quality vs battery/compute in real time
- Tools/products/workflows: model compression/quantization for 1.3B–14B variants; hardware-accelerated Euler schedulers; edge safety filters
- Assumptions/dependencies: efficient memory management for KV-caches; privacy-preserving models; hardware support (NPUs/GPUs)
- Standardized flow-map distillation frameworks across vendors
- Sectors: foundation model providers, tool builders
- Use case: unify any-step training methods (interpolated timestep conditioning, adaptive loss reweighting, flow-map backward simulation) into shared libraries
- Tools/products/workflows: “Flow-Map Distillation SDK”; scheduler-agnostic APIs; reproducible benchmarks
- Assumptions/dependencies: community consensus; robust open-source governance; cross-model compatibility
- Autonomous quality-control pipelines with dynamic compute allocation
- Sectors: video SaaS, creative agencies, localization vendors
- Use case: auto-detect clips needing refinement and re-render with higher NFEs; prioritize critical frames or segments
- Tools/products/workflows: “AutoNFE Controller” tied to perceptual metrics; frame-level budget assignment; workflow orchestration
- Assumptions/dependencies: reliable quality metrics correlating with human judgment; scalable re-render orchestration
- Safety, provenance, and policy infrastructure for synthetic video
- Sectors: public policy, platforms, news media
- Use case: watermarking/provenance (e.g., C2PA), disclosure labels, rate-limited high-NFE generation for sensitive categories; audit trails of step budgets used
- Tools/products/workflows: policy-compliant AnyFlow deployments; layered content filters; red-teaming protocols that stress-test models across NFEs
- Assumptions/dependencies: adoption of standards; regulatory buy-in; robust detection and moderation pipelines
- Healthcare and training simulations (with stronger domain controls)
- Sectors: medical education, emergency response training
- Use case: privacy-preserving synthetic procedure videos; scenario generation for training; staged fidelity with NFEs based on risk level
- Tools/products/workflows: domain-validated prompt libraries; provenance and consent tooling; expert evaluation loops
- Assumptions/dependencies: clinical validation; regulatory compliance (HIPAA, GDPR); strict safety filters
- Energy and sustainability-aware AI operations
- Sectors: cloud operations, green AI initiatives
- Use case: reduce energy by using low NFEs for previews and allocate high NFEs selectively; track carbon budgets tied to step counts
- Tools/products/workflows: cost/energy telemetry linked to NFE usage; policy-based throttling; dashboards
- Assumptions/dependencies: accurate energy reporting; organizational targets and enforcement mechanisms
Cross-cutting assumptions and dependencies
- Technical: access to strong teacher models for DMD; reliable PF-ODE trajectories; Euler sampling support; GPU compute and memory (especially for 14B models); FSDP-aware training; stable evaluation benchmarks (e.g., VBench, VBench-I2V).
- Data and distribution: training/fine-tuning datasets with appropriate licensing; synthetic-to-real gap management; potential texture smoothing if teacher-data distribution differs.
- Safety and governance: content moderation, watermarking/provenance (C2PA), usage policies, auditability of NFEs; adherence to privacy and IP regulations.
- Productization: integration into existing creative tools and ML platforms; observability for latency/quality; automated orchestration for preview-to-production workflows.
Glossary
- Adaptive loss reweighting: A training technique that dynamically scales per-sample or per-condition losses to stabilize optimization. "To stabilize flow map training, we introduce an adaptive loss reweighting scheme."
- Any-step: The capability of a model to support arbitrary numbers of sampling steps at test time without retraining. "the first any-step video diffusion distillation framework based on flow maps."
- Autoregressive generation: A generation regime where outputs are produced sequentially, each conditioned on previously generated elements. "which leads to error accumulation during autoregressive generation."
- Bidirectional video diffusion: A non-causal diffusion setup that reasons over entire video sequences jointly rather than frame-by-frame. "e.g., rCM~\cite{zheng2025large} for bidirectional video diffusion and Self-Forcing~\cite{huang2025selfforcing} for causal video diffusion"
- Classifier-free guidance (CFG): A conditioning technique that blends conditional and unconditional model predictions to steer outputs without an external classifier. "We also incorporate classifier-free guidance (CFG) into flow map training"
- Composition property of flow maps: The property that a transition from time t to q can be approximated by composing transitions t→r and r→q. "based on the composition property of flow maps."
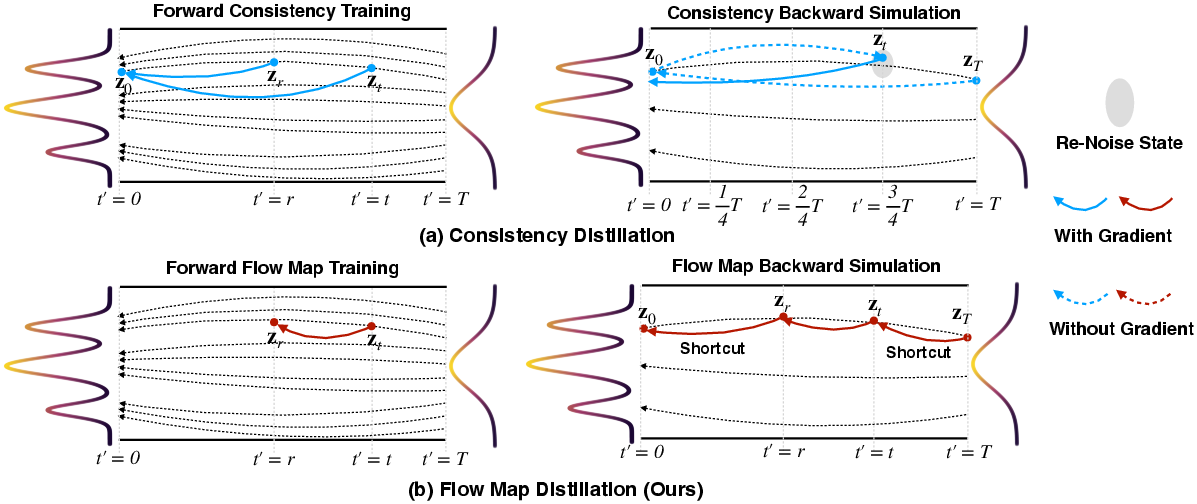
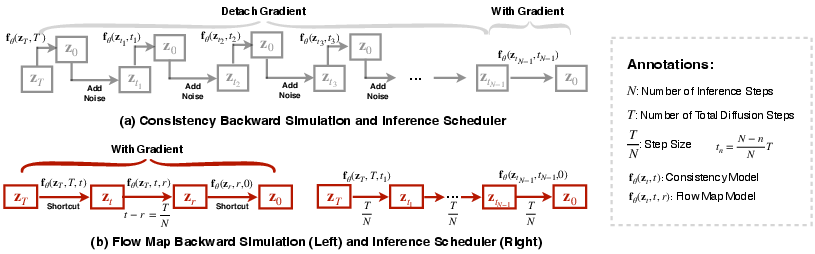
- Consistency backward simulation: A rollout strategy that follows consistency-model update rules during training to reach endpoint states for supervision. "Consistency backward simulation and sampling both follow consistency trajectories"
- Consistency distillation: A distillation approach that trains a student to map noisy states directly to clean endpoints for fast sampling. "Few-step video generation has been significantly advanced by consistency distillation."
- Consistency Models (CMs): Models that learn direct mappings from noisy latents to clean ones along a probability-flow ODE for accelerated sampling. "Consistency Models (CMs) accelerate diffusion sampling by directly learning a mapping from to along the probability-flow ODE (PF-ODE) defined by a teacher model."
- Consistency-sampling trajectory: The sampling path induced by repeated consistency updates, which may differ from the PF-ODE path. "consistency distillation replaces the original probability-flow ODE trajectory with a consistency-sampling trajectory"
- Context compression with asymmetric patchify kernels: An efficiency technique that compresses video tokens using different spatial/temporal patch sizes across chunks. "which uses context compression with asymmetric patchify kernels to encode videos efficiently."
- Differential derivation equation: A finite-difference relation used to connect predictions across nearby timesteps for flow-map learning. "alongside the differential derivation equation (\cref{eq:center_difference})"
- Discretization error: The error introduced by approximating continuous-time dynamics with a finite number of discrete steps. "discretization error in few-step sampling"
- Distribution Matching Distillation (DMD): A distillation method that aligns the student’s rollout distribution with a teacher’s by minimizing divergence measures. "we instantiate on-policy diffusion distillation with distribution matching distillation (DMD)"
- Distribution shift: A mismatch between the training and deployment data distributions that can degrade performance. "which can introduce mild distribution shift, such as smoother textures."
- Endpoint consistency mapping: A mapping that projects latent states at time t directly to the clean endpoint at time 0. "endpoint consistency mapping ()"
- Endpoint projection: The operation of mapping intermediate states directly to the endpoint during consistency-style sampling. "consistency-style sampling repeatedly performs endpoint projection and re-noising"
- Euler rollout: A trajectory simulation based on the Euler method for integrating ODEs. "decomposes a full Euler rollout into shortcut flow-map transitions"
- Euler scheduler: A sampling scheduler that uses Euler integration steps during inference. "we can simply use a standard Euler scheduler for sampling."
- Exposure bias: A train-test mismatch where models trained with ground-truth contexts must rely on their own predictions at test time, causing error accumulation. "exposure bias in causal generation."
- Flow map: A two-time transition operator that predicts the state at time r from a state at time t along the PF-ODE trajectory. "Flow maps generalize endpoint consistency by learning transitions between arbitrary time pairs"
- Flow Map Backward Simulation: A proposed simulation method that short-circuits trajectories into segments using flow maps for efficient on-policy distillation. "We further propose Flow Map Backward Simulation, which decomposes a full Euler rollout into shortcut flow-map transitions"
- Flow map distillation: Distilling a teacher into a model that learns transitions between arbitrary time pairs instead of only endpoints. "we explore flow map distillation to enable any-step video generation."
- Flow map training: Training a model to learn the transition operator between arbitrary timesteps, often with MeanFlow-style objectives. "we develop an improved forward flow map training recipe to convert pretrained video diffusion models into flow map models"
- Flow matching: A training paradigm that learns the instantaneous velocity field of data flow, typically corresponding to t=r cases. "reduces to standard flow matching~\cite{liu2022flow, lipman2022flow} when ."
- Fully Sharded Data Parallel (FSDP): A distributed training strategy that shards model parameters across devices to enable large-scale training. "which are difficult to scale under Fully Sharded Data Parallel (FSDP)."
- Interpolated timestep conditioning: A conditioning scheme that blends embeddings of start and end times to stabilize post-training. "we instead use an interpolated timestep conditioning scheme:"
- Jacobian–vector products (JVPs): Linearizations used to probe model Jacobians along specific directions, often costly in large-scale training. "relies on Jacobian-vector products (JVPs), which are difficult to scale under Fully Sharded Data Parallel (FSDP)"
- Kullback–Leibler (KL) gradient: The gradient of the KL divergence used to optimize the student toward the teacher’s distribution. "compute the Kullback--Leibler (KL) gradient."
- KV-cache: Cached attention key and value tensors that accelerate autoregressive or causal sampling. "This design substantially reduces teacher-forcing training cost and KV-cache size during sampling."
- MeanFlow: A training objective/framework for one-step or flow-map-based generative modeling used as the base in this work. "We employ the MeanFlow objective (\cref{eq:meanflow}) alongside the differential derivation equation"
- Number of Function Evaluations (NFEs): The number of model evaluations used during sampling; a proxy for inference cost. "AnyFlow-FAR reaches a VBench score of 84.05 at 4 NFEs"
- On-policy distillation: Distillation that trains on the student’s own rollouts rather than teacher-forced trajectories to reduce test-time errors. "we introduce on-policy distillation with teacher guidance."
- On-Policy Flow Map Distillation: The specific on-policy distillation framework tailored to flow map models presented in this work. "On-Policy Flow Map Distillation"
- Probability-flow ODE (PF-ODE): The deterministic ODE that traces the mean trajectory of the diffusion process under the score model. "probability-flow ODE (PF-ODE)"
- Re-noising: Injecting noise back into intermediate states during multi-step consistency sampling. "repeatedly re-noising intermediate states"
- Reverse-divergence supervision: Supervising student trajectories by minimizing divergence in the reverse direction under teacher guidance. "apply reverse-divergence supervision from a strong teacher"
- Score distillation: A regularization technique that distills the teacher’s score-function information into the student. "introduces score distillation as a regularizer"
- Self-rollout: Generating trajectories using the student’s own sampler for on-policy training. "requires the student to perform a self-rollout (i.e., backward simulation) to "
- Shortcut flow-map transitions: Direct transitions that skip multiple intermediate steps by leveraging the flow map’s two-time formulation. "shortcut flow-map transitions"
- Timestep embedding: Learned vector representations of diffusion timesteps used to condition neural networks. "tends to produce timestep embeddings with much larger norms"
- Trajectory drift: Deviation of the sampling trajectory from the target PF-ODE path, often due to repeated endpoint projections and re-noising. "which causes trajectory drift under multi-step sampling."
- Two-time flow map formulation: A modeling approach that parameterizes transitions by both start and end times to support arbitrary step sizes. "based on a two-time flow map formulation"
- Teacher-forcing: A training regime feeding ground-truth contexts rather than model predictions to stabilize learning. "reduces teacher-forcing training cost"
Collections
Sign up for free to add this paper to one or more collections.