- The paper introduces an algebraic interval splitting consistency identity that generalizes MeanFlow for efficient few-step generative modeling.
- It presents a hardware-friendly training algorithm that bypasses complex Jacobian-vector product computations, ensuring rapid and stable model updates.
- Empirical results in audio generation show that 1-step generation achieves parity with 10-step methods, confirming both efficiency and high-fidelity outputs.
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Motivation and Context
The computational inefficiency of iterative sampling in diffusion and flow-based generative models has motivated the development of few-step and one-step generative frameworks. While Flow Matching and its variants have achieved strong sample quality, their reliance on modeling instantaneous velocity fields and multi-step ODE integration remains a bottleneck for real-time and resource-constrained applications. MeanFlow advanced the field by proposing to learn the average velocity field, enabling direct mapping from noise to data in a single or few steps. However, MeanFlow's reliance on a differential identity introduces both theoretical and practical limitations, particularly due to the need for Jacobian-vector product (JVP) computations.
Algebraic Interval Splitting Consistency
SplitMeanFlow introduces a principled algebraic approach to learning the average velocity field for generative modeling. The core insight is to leverage the additivity property of definite integrals, leading to the Interval Splitting Consistency identity:
(t−r)u(zt,r,t)=(s−r)u(zs,r,s)+(t−s)u(zt,s,t)
where u(zt,r,t) is the average velocity field over [r,t], and zt is the flow path at time t. This identity holds for any r≤s≤t and is derived directly from the integral definition of average velocity, bypassing the need for differential operators.
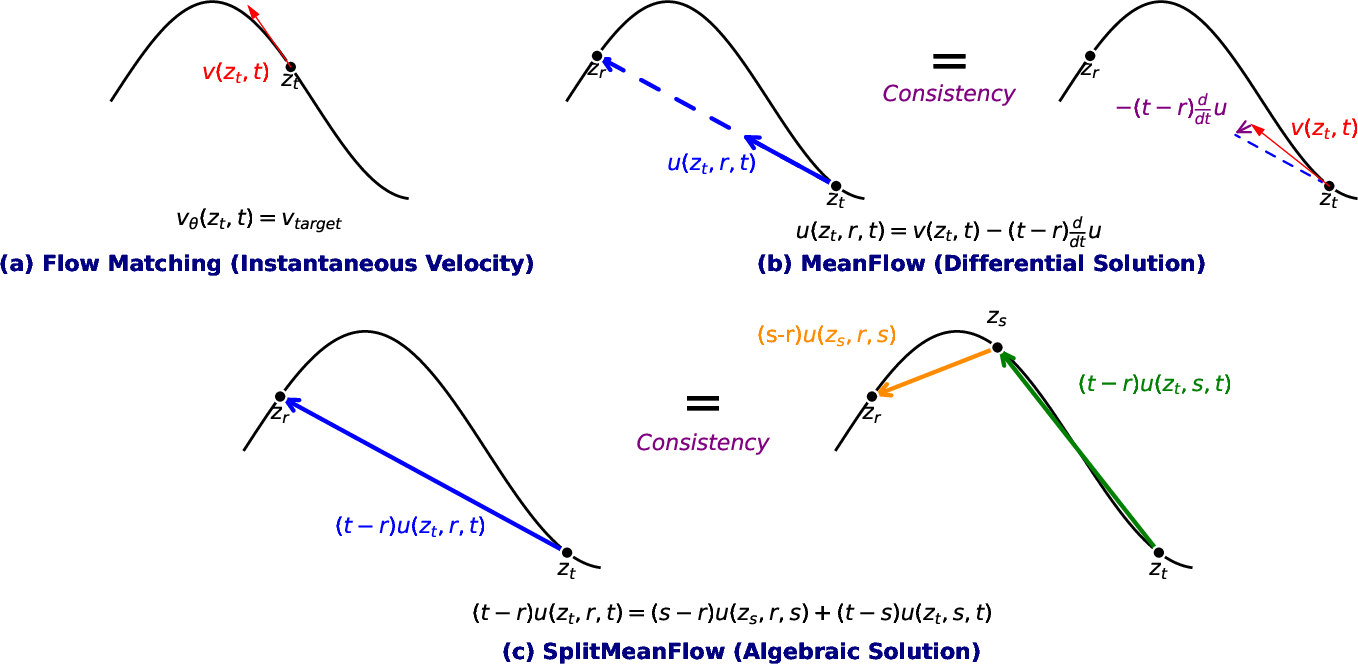
Figure 1: Conceptual comparison of generative flow methods, highlighting the transition from instantaneous velocity (Flow Matching) to average velocity (MeanFlow, SplitMeanFlow) and the algebraic self-consistency of SplitMeanFlow.
This algebraic formulation generalizes the MeanFlow differential identity, which is recovered as a limiting case when s→t. The approach is thus both more fundamental and more flexible, providing a self-referential constraint that can be enforced at arbitrary interval splits.
Training Algorithm and Implementation
The SplitMeanFlow training procedure enforces the Interval Splitting Consistency as a self-supervised objective. The key steps are:
- Sample time points r,t with 0≤r<t≤1, and a random λ∼U(0,1); set s=(1−λ)t+λr.
- Sample prior ϵ∼N(0,I).
- Construct flow path zt=(1−t)x+tϵ.
- Compute u2=uθ(zt,s,t).
- Compute intermediate point zs=zt−(t−s)u2.
- Compute u1=uθ(zs,r,s).
- Form target target=(1−λ)u1+λu2.
- Loss: L=∥uθ(zt,r,t)−sg(target)∥ (where sg is stop-gradient).
This procedure requires only standard forward and backward passes, with no JVPs or higher-order derivatives, resulting in a simple and hardware-friendly implementation.
Pseudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def splitmeanflow_step(u_theta, x_batch, optimizer):
r, t = sample_time_points()
lambda_ = np.random.uniform(0, 1)
s = (1 - lambda_) * t + lambda_ * r
epsilon = np.random.normal(size=x_batch.shape)
z_t = (1 - t) * x_batch + t * epsilon
u2 = u_theta(z_t, s, t)
z_s = z_t - (t - s) * u2
u1 = u_theta(z_s, r, s)
target = (1 - lambda_) * u1 + lambda_ * u2
loss = ((u_theta(z_t, r, t) - target.detach()) ** 2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step() |
Boundary Conditions and Distillation
To avoid degenerate solutions, the model is anchored by enforcing u(zt,t,t)=v(zt,t) at the boundary, where v is the instantaneous velocity from a pretrained teacher model. In practice, a two-stage training regime is used: first, a standard flow matching model is trained as the teacher; then, SplitMeanFlow is distilled from this teacher, mixing the boundary condition and interval splitting losses.
Theoretical and Practical Advantages
Theoretical Generality
The algebraic identity of SplitMeanFlow subsumes the MeanFlow differential identity as a special case. In the limit s→t, the difference quotient on the left-hand side becomes a derivative, and the right-hand side converges to the instantaneous velocity, exactly recovering the MeanFlow update. This demonstrates that SplitMeanFlow is a strict generalization, providing a more robust and theoretically grounded framework for learning average velocity fields.
Computational Efficiency
SplitMeanFlow eliminates the need for JVPs, which are required in MeanFlow to compute dtdu. This results in:
- Simpler implementation: Only standard forward and backward passes are needed.
- Improved stability: Avoids numerical issues associated with higher-order derivatives.
- Broader hardware compatibility: No reliance on JVP support in accelerators or frameworks.
- Faster training: Reduced computational overhead per iteration.
Empirical Results
SplitMeanFlow was evaluated on large-scale audio generation tasks using the Seed-TTS framework. Key findings include:
- 2-step SplitMeanFlow matches or slightly exceeds the 10-step Flow Matching baseline in speaker similarity (SIM: 0.789 vs. 0.787) and achieves nearly identical word error rate (WER: 0.0561 vs. 0.0551) and subjective CMOS scores.
- 1-step SplitMeanFlow achieves parity with 10-step Flow Matching in in-context learning tasks, with identical WER (0.0286) and negligible difference in SIM (0.685 vs. 0.686), and a neutral CMOS score, indicating no perceptual degradation.
- No need for Classifier-Free Guidance (CFG), further reducing inference complexity.
These results demonstrate that SplitMeanFlow enables high-fidelity, few-step, and even one-step generation with minimal quality loss and substantial computational savings.
Implications and Future Directions
SplitMeanFlow's algebraic approach to learning average velocity fields provides a new foundation for efficient generative modeling. Its theoretical generality and practical simplicity make it well-suited for deployment in latency-sensitive and resource-constrained environments, as evidenced by its industrial adoption.
Potential future directions include:
- Extension to other modalities: Application to image, video, and multimodal generative tasks.
- Integration with advanced architectures: Combining with transformer-based or hierarchical models for further gains.
- Exploration of alternative self-supervised consistency objectives: Generalizing the algebraic approach to other forms of generative modeling and distillation.
- Theoretical analysis of convergence and expressivity: Formal study of the conditions under which algebraic self-consistency leads to optimal generative performance.
Conclusion
SplitMeanFlow establishes a principled, algebraic framework for few-step generative modeling by enforcing interval splitting consistency. It generalizes and improves upon prior differential approaches, offering both theoretical robustness and practical efficiency. The method achieves state-of-the-art performance in one-step and few-step generation tasks, with strong empirical results and demonstrated industrial impact. This work opens new avenues for efficient, high-quality generative modeling across domains.