- The paper introduces a benchmark for one-step-ahead neural spike-count forecasting using strict autoregressive and causal constraints.
- It decomposes performance across population rate, spatial patterns, and cosine similarity to reveal region-specific predictability and biophysical noise floors.
- Deep sequence models show significant gains over linear baselines, though challenges remain with sub-Poisson neurons and knowledge distillation for SNNs.
SpikeProphecy: Establishing the Benchmark for Autoregressive Neural Population Forecasting
Introduction
The paper "SpikeProphecy: A Large-Scale Benchmark for Autoregressive Neural Population Forecasting" (2605.12992) addresses a fundamental gap in computational neuroscience and neuroengineering: the lack of standardized, large-scale, and reproducible benchmarks for forecasting future neural population activity from past dynamics in high-density electrophysiological datasets. While neural population models have seen rapid advances via architectures derived from language and time-series modeling, evaluation practices remain limited—often relying on a single scalar metric that obscures both population-level and feature-specific modeling challenges. This work establishes the first benchmark and evaluation protocol specifically for autoregressive spike-count forecasting, leveraging two large Neuropixels datasets to systematically compare a range of modern sequence models and introduce a decomposed suite of evaluation metrics tailored to neural population activity.
Benchmark Construction and Evaluation Protocol
SpikeProphecy operationalizes the task of one-step-ahead forecasting of binned spike counts across thousands of simultaneously recorded neurons using recent spike history as the only input, enforcing both strict autoregressivity and causality. The primary datasets derive from Steinmetz et al. 2019 and the International Brain Laboratory (IBL) Repeated Site initiative, collectively comprising over 89,000 neurons and 105 recording sessions—spanning multiple brain regions, labs, and experimental setups.
The evaluation protocol forms the core methodological advance: performance is decomposed into three axes—
- Population Rate r (rpop): Captures fidelity in modeling the overall temporal envelope of population activity.
- Spatial Pattern r (rspatial): Quantifies cross-neuron pattern fidelity at each timepoint.
- Cosine Similarity: Assesses magnitude-invariant alignment of predicted and true responses.
This decomposition is empirically demonstrated to uncover critical structure—such as region-specific predictability hierarchies and biophysical noise floors—that are completely masked by aggregate Pearson correlation metrics frequently used in prior work.
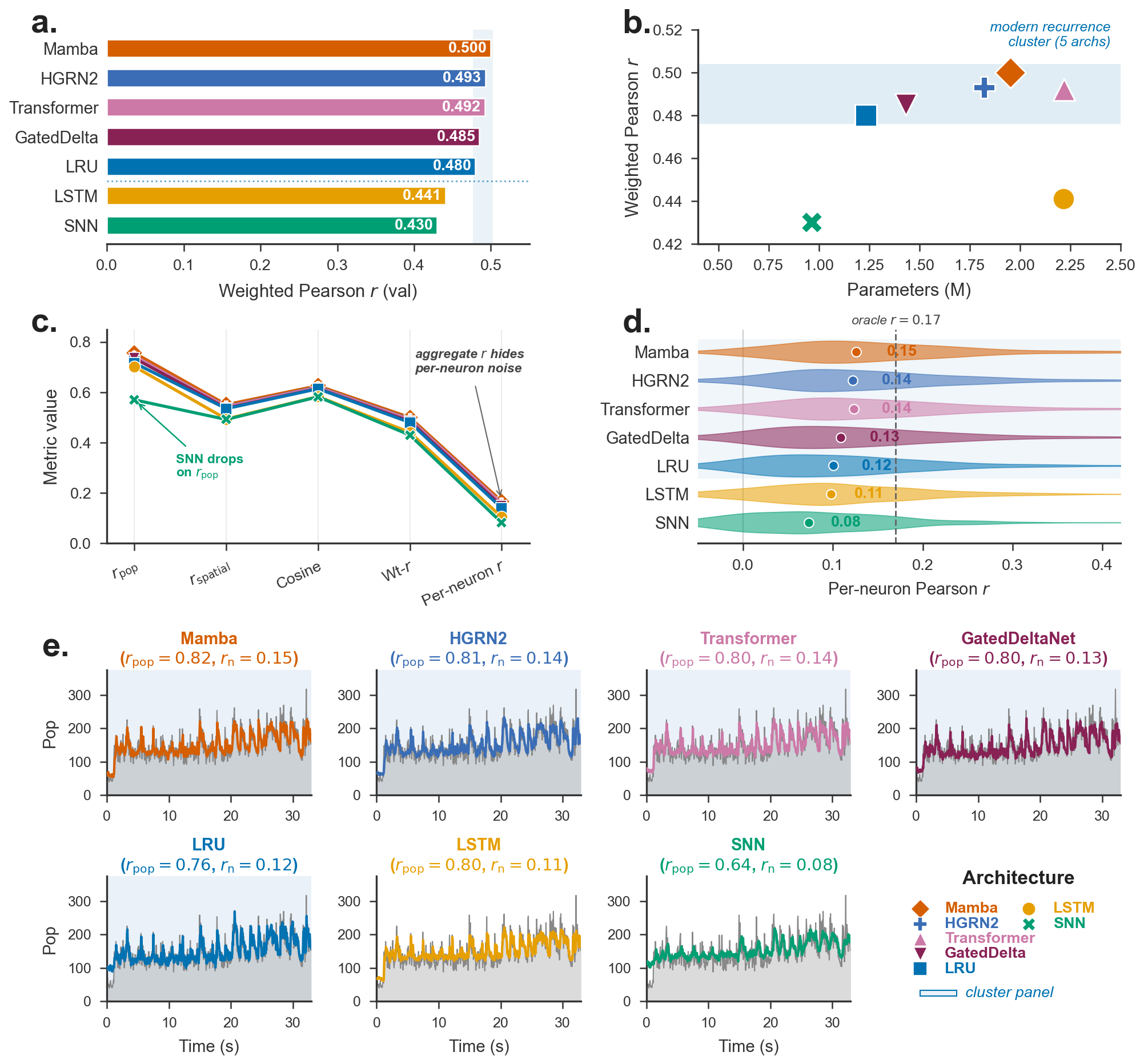
Figure 1: Overview of the SpikeProphecy benchmark—showing per-architecture results, parameter/accuracy Pareto front, metric decompositions, per-neuron score spread, and session-level rate traces.
Model Suite and Baseline Analysis
Seven primary architectures are compared using this protocol, all with harmonized optimization and training schedules:
- Diagonal SSMs: Mamba, HGRN2, LRU.
- Non-diagonal SSM: GatedDeltaNet.
- Transformer (causal attention).
- LSTM (classical baseline).
- RSynaptic SNN (event-driven, neuromorphic).
Comprehensive linear controls (autoregressive GLM, population GLM with ridge regularization) calibrate the difficulty of the task and sensitivity to information leakage or overfitting.
Key Empirical Findings
Decomposition Surfaces Brain Region Predictability Hierarchy
Applying the decomposed metrics across 8 Allen CCF functional brain regions reveals a significant, reproducible hierarchy in forecastability. ANCOVA analysis controlling for firing statistics (log rate and Fano factor) finds that region assignment explains a nontrivial, reproducible increment in explainable variance (ΔR2=0.018 above covariates, total R2=0.275, p<10−77). This ranking is stable across all architectures; motor cortex and midbrain exhibit the most predictable short-timescale activity, while hippocampal and limbic regions are substantially harder to forecast within the provided context window.
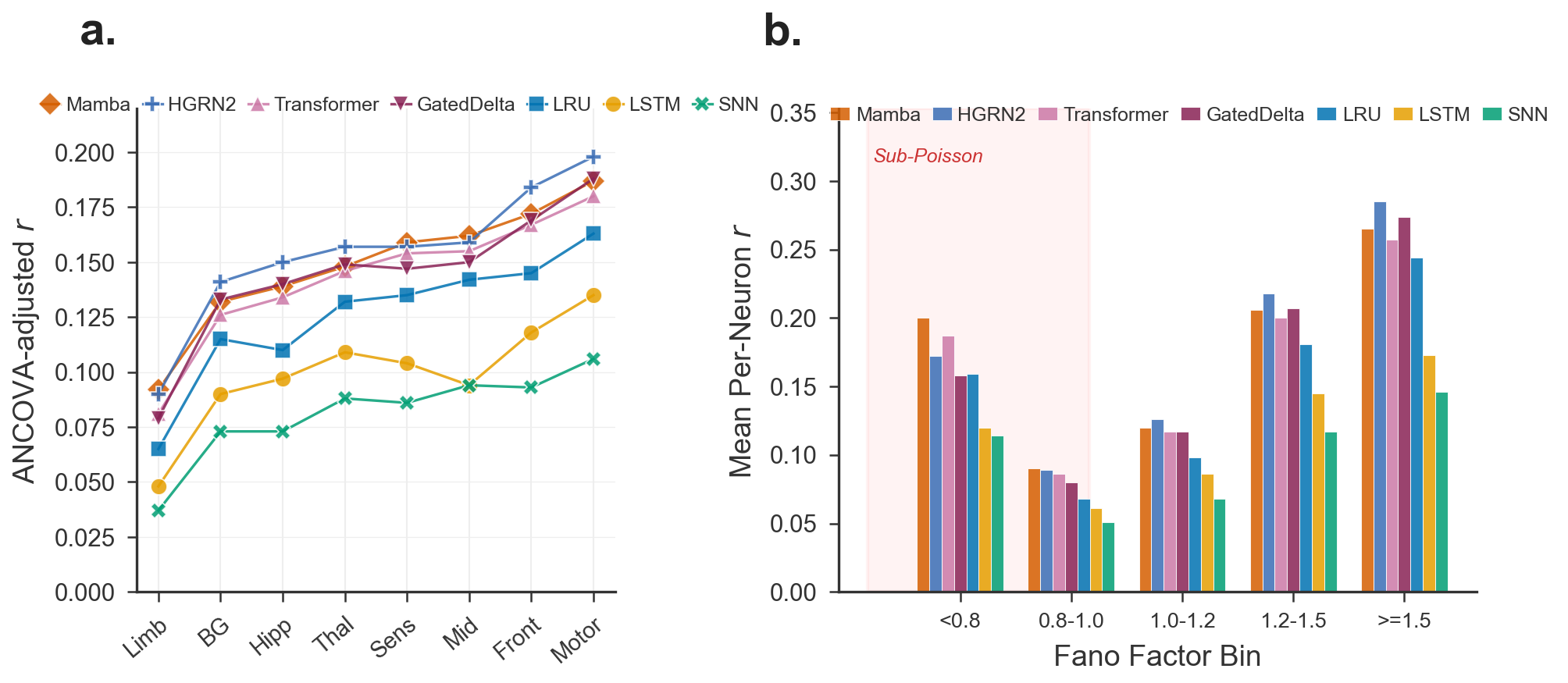
Figure 2: ANCOVA-adjusted per-neuron r across eight functional brain regions, highlighting reproducible hierarchy and sub-Poisson floor.
Sub-Poisson Evaluation Floor and Metric Limitation
A substantial fraction (28%) of recorded neurons are sub-Poisson (FF<1), exhibiting highly regular, oscillator-like firing. These neurons define a hard lower limit for model performance: mean r values are rpop0, independent of architecture. This limitation is entangled between irreducible biophysical variability and the mathematical harshness of Pearson correlation in low-variance regimes—motivating the necessity of Fano-stratified metric reporting.
Linear versus Deep Modeling Regimes
Linear baselines (GLMs) either fail to generalize due to within-session nonstationarity (autoregressive GLM, rpop1) or overfit catastrophically under high-dimensional input regimes (population GLM, rpop2 on validation unless aggressively regularized). Deep sequence models (Mamba, HGRN2, GatedDeltaNet, Transformer, LRU), in contrast, form a statistically indistinguishable cluster (rpop3–rpop4), exhibiting rpop5–rpop6 performance gains over linear models on valid splits, with SNNs and LSTM trailing consistently.
Negative Result for Output KL Distillation
Contrary to established practice in ANN-to-SNN knowledge transfer for classification tasks, output KL-divergence-based distillation does not improve SNN forecasting performance. Standalone SNNs are maximally efficient at smaller depths; soft-label teacher rates introduce no “dark knowledge” benefit in real-valued Poisson regression, and deeper network architectures degrade sharply.
Ceiling and Rollout Behavior
Empirical oracle ceiling analysis indicates that current models capture rpop774% of the achievable signal, with the remainder attributable to irreducible noise. Deeper rollout of predictions reveals rapid degradation in per-neuron rpop8 for all ANN architectures, while SNNs decline more slowly at long horizons, consistent with architectural differences in error propagation mechanisms.
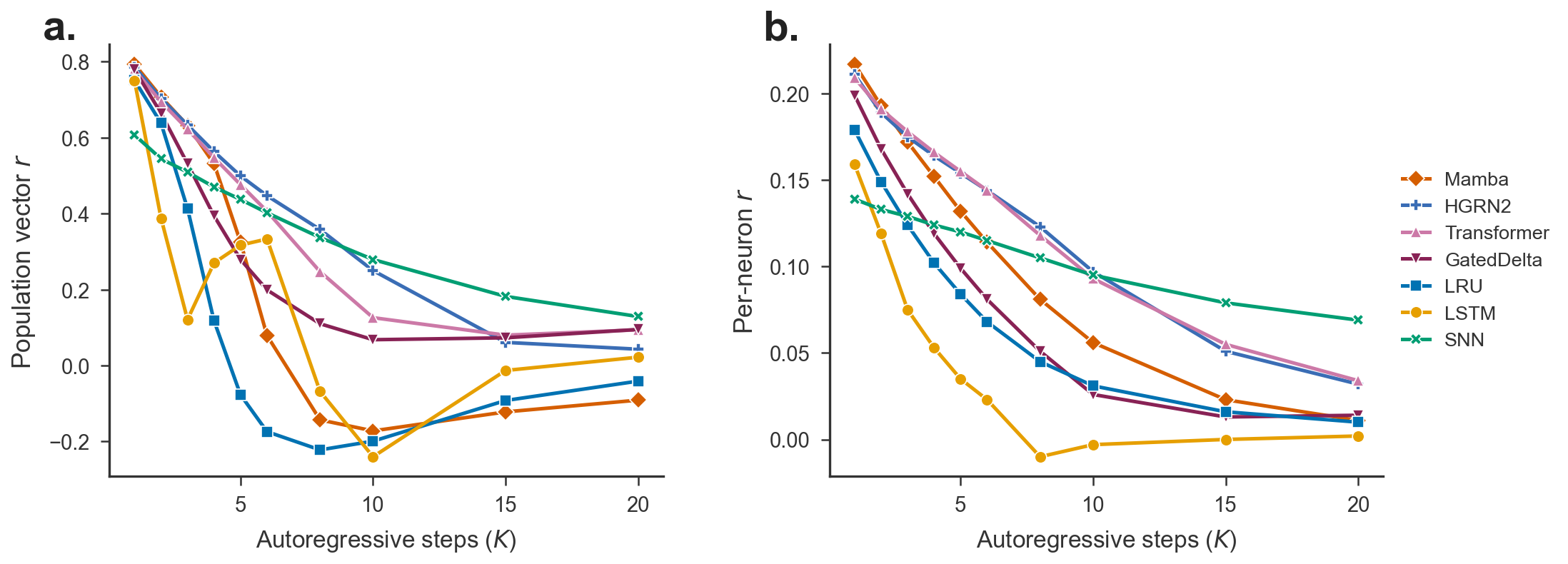
Figure 3: Degradation of autoregressive rollout across all baselines, highlighting per-neuron instability at longer horizons and increased SNN robustness.
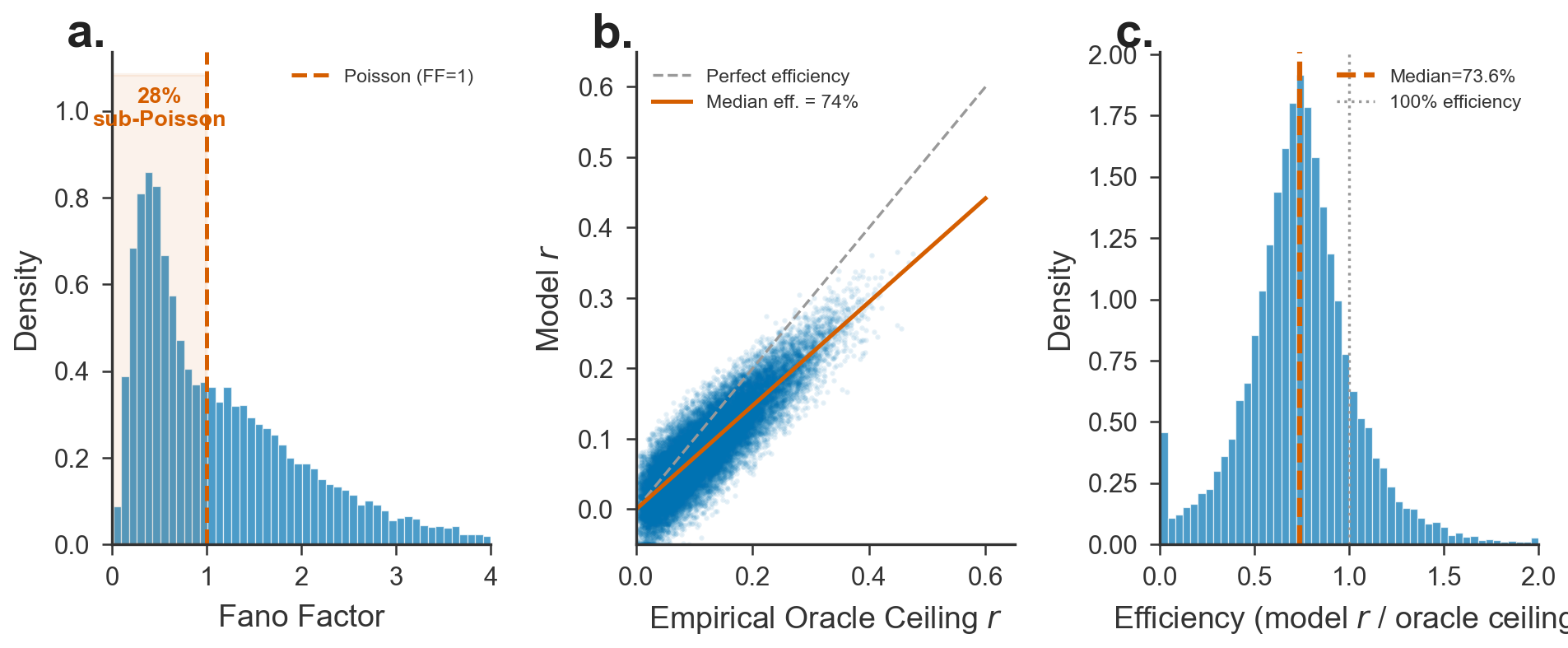
Figure 4: Oracle ceiling analysis demonstrating sub-Poisson neuron floor, neuronal rpop9 versus achievable ceiling, and model efficiency distribution.
Practical and Theoretical Implications
The protocol demonstrates that effective deployment of neural forecasting models—e.g., in closed-loop BCIs—requires moving beyond aggregate metrics. Application domains differ in sensitivity to population-level versus neuron-specific dynamics; decomposed metrics enable appropriate model selection for use cases such as brain-state classification, BCI gating, or targeted stimulation. The substantial gap between the predictability of motor versus non-motor regions highlights critical challenges for modeling complex, internally generated activity (e.g., hippocampus) at physiologically realistic timescales. Observations of distinctly nonlinear gains in deep models, the persistence of biophysical evaluation floors, and the ineffectiveness of standard ANN-to-SNN distillation methods collectively chart a nuanced path for future method development—including latent-state modeling, dispersion-aware loss formulations (e.g., Conway–Maxwell–Poisson), and architecture design tailored to the spatiotemporal structure of neural data.
Release and Reproducibility
All code, processed data (with links to underlying raw repositories), and trained model checkpoints have been released for reproducibility, including a pip-installable evaluation toolkit and a comprehensive leakage-audit suite. This facilitates both robust cross-laboratory comparison and extension to new modeling approaches, including foundation-model pretraining for strictly causal forecasting.
Conclusion
SpikeProphecy defines a rigorous, accessible, and auditable standard for autoregressive neural population forecasting on large-scale, real electrophysiological data. Its decomposed metrics and stratified reporting capture performance axes critically relevant for both scientific understanding and neurotechnology deployment, substantively advancing the benchmark-driven development paradigm in computational neuroscience and AI modeling of biological populations. The released dataset and toolkit lower entry barriers and establish a reproducibility baseline, signaling a practical shift in evaluation methodologies for large-scale neural sequence modeling.