SpikySpace: A Spiking State Space Model for Energy-Efficient Time Series Forecasting
Abstract: Time-series forecasting often operates under tight power and latency budgets in fields like traffic management, industrial condition monitoring, and on-device sensing. These applications frequently require near real-time responses and low energy consumption on edge devices. Spiking neural networks (SNNs) offer event-driven computation and ultra-low power by exploiting temporal sparsity and multiplication-free computation. Yet existing SNN-based time-series forecasters often inherit complex transformer blocks, thereby losing much of the efficiency benefit. To solve the problem, we propose SpikySpace, a spiking state-space model (SSM) that reduces the quadratic cost in the attention block to linear time via selective scanning. Further, we replace dense SSM updates with sparse spike trains and execute selective scans only on spike events, thereby avoiding dense multiplications while preserving the SSM's structured memory. Because complex operations such as exponentials and divisions are costly on neuromorphic chips, we introduce simplified approximations of SiLU and Softplus to enable a neuromorphic-friendly model architecture. In matched settings, SpikySpace reduces estimated energy consumption by 98.73% and 96.24% compared to two state-of-the-art transformer based approaches, namely iTransformer and iSpikformer, respectively. In standard time series forecasting datasets, SpikySpace delivers competitive accuracy while substantially reducing energy cost and memory traffic. As the first full spiking state-space model, SpikySpace bridges neuromorphic efficiency with modern sequence modeling, marking a practical and scalable path toward efficient time series forecasting systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SpikySpace, a new kind of AI model that predicts future values in time-based data (like traffic flow, power usage, or sensor readings) while using very little energy. It does this by combining two ideas:
- Spiking neural networks (SNNs), which “wake up” and do work only when something changes.
- State space models (SSMs), which keep a compact memory of the past to understand long-term patterns.
The big goal is to bring accurate, real-time forecasting to small, low-power devices (like sensors or edge hardware) without relying on power-hungry cloud computing.
What questions were the authors trying to answer?
The authors aimed to answer simple but important questions:
- Can we predict time series accurately on tiny, energy-limited devices?
- Can we replace heavy, expensive parts of popular models (like transformers) with something faster and lighter?
- Can we make a fully “spiking” version of a state space model so the whole system is event-driven and energy efficient?
- Can we avoid expensive math operations (like exponentials and divisions) and still keep the model accurate?
How did they do it?
The authors built SpikySpace by blending spiking neurons with a state space model and carefully simplifying tricky math so it works well on energy-saving chips.
Spiking neurons in simple terms
Think of a spiking neuron like a bucket that collects drops of water. When the water level passes a line (the threshold), it “spikes” (sends a signal) and then resets. In SNNs:
- The model only computes when spikes happen (events), not at every time step.
- This saves energy because it skips over boring parts where nothing changes.
SpikySpace uses an efficient version of this called “Average Integrate-and-Fire,” which reduces memory reads and keeps computation light.
State Space Models (SSMs) in simple terms
Imagine keeping a small notebook that summarizes everything important you’ve seen so far, instead of storing every detail. An SSM is like that notebook:
- It keeps a compact “state” that updates over time.
- It can remember long-term patterns using fast, stable rules.
- It processes sequences in linear time (grows with length L), unlike transformers’ attention, which grows with L squared (much slower and heavier).
The SpikySpace design
Here are the key design ideas, explained simply:
- Event-driven updates (only on spikes): Instead of calculating at every time step, SpikySpace updates its state only when spikes occur. This means:
- Less work,
- Less memory traffic,
- Less energy.
- Selective scan (fast memory updates): Transformers compare every time step with every other one (quadratic cost). SpikySpace uses a “scan” that passes through the sequence once (linear cost) and only does real work when events (spikes) happen.
- Multiplication-free approximations: Many models use functions like Softplus and SiLU that need expensive math (exponentials, divisions). SpikySpace replaces them with look-alike, piecewise formulas using powers of two:
- PTSoftplus (for Softplus)
- PTSiLU (for SiLU)
- These can be computed using additions and bit shifts, which are fast and energy-friendly on neuromorphic hardware.
- ANN-to-SNN conversion with quantization: The model is first trained in a standard setting (ANN) with low-precision “quantized” activations (few bits). Then it’s converted into a spiking version that behaves similarly but runs much more efficiently. This strategy keeps accuracy while enabling spikes.
- Structured memory that’s spiking: Unlike earlier attempts, SpikySpace makes both the memory updates and the nonlinear parts spiking and sparse. That means the whole model benefits from event-driven efficiency.
What did they find?
On standard time-series forecasting benchmarks (like METR-LA for traffic and Electricity for power usage), SpikySpace:
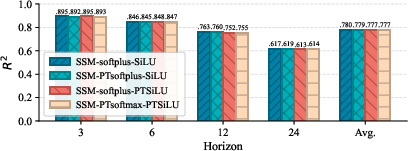
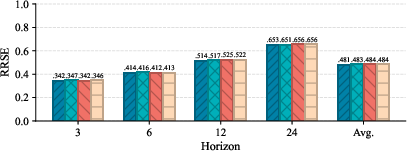
- Reached strong accuracy, with average R2 scores of about 0.778 (METR-LA) and 0.992 (Electricity).
- R2 is a “goodness of fit” score; closer to 1 means better predictions.
- Beat a prior spiking model (SpikeSTAG) in accuracy by 3.3% (METR-LA) and 0.7% (Electricity), while using only about 2.7% of its energy.
- Used far less energy than transformer-style baselines:
- Up to about 26.6× less than iSpikformer,
- Up to about 78.9× less than iTransformer,
- Or, in another matched setting, about 96–99% lower estimated energy use.
- Also reduced memory traffic and model size, which is important for small devices.
In short, it kept accuracy competitive while dramatically cutting energy costs.
Why does it matter?
This work shows a practical path to real-time forecasting on edge and neuromorphic hardware:
- Longer battery life and lower heat for wearables, sensors, and robots.
- Faster reactions for on-device systems (like traffic control or industrial monitoring) without sending data to the cloud.
- A blueprint for future models that combine modern sequence modeling (SSMs) with event-driven spikes for big efficiency gains.
If developed further, models like SpikySpace could help bring powerful, privacy-preserving prediction to lots of everyday devices—accurate, fast, and frugal.
Key takeaways
- Purpose: Make time-series forecasting both accurate and ultra–energy-efficient on small devices.
- Approach: Fully spiking state space model with event-driven updates, linear-time scanning, and multiplication-free activations.
- Results: Similar or better accuracy than strong baselines, while using dramatically less energy (often tens of times less).
- Impact: A step toward practical, scalable, on-device forecasting that doesn’t need the cloud or lots of power.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Real hardware validation is missing: energy and latency are estimated via synaptic operations (SOPs) and off-chip memory proxies, but there are no end-to-end measurements on neuromorphic devices (e.g., Loihi 2, TrueNorth) or low-power edge hardware under streaming workloads and varying firing rates.
- Event-driven execution is asserted but not substantiated: the selective scan algorithm still iterates over all timesteps 1…L; there is no explicit mechanism, schedule, or empirical analysis showing how updates are actually skipped when no spikes occur, nor the control overhead when spikes are sparse versus dense.
- Output head may not be multiplication-free: the final linear projection appears to require dense multiply-accumulate unless weights are structured (e.g., power-of-two) or ternary; the paper does not specify quantization/constraints for the output head to ensure bit-shift or accumulation-only computation.
- C and D matrices in the readout path are not guaranteed to be hardware-friendly: unlike A_t, there is no requirement or analysis ensuring C or D are quantized to power-of-two or sparse forms; the cost of C_t h_t and D s_t may dominate if left dense.
- Stability and expressivity of the spike-driven SSM are not analyzed: replacing exp(ΔA) with 2{⌊ΔA⌉} changes the system’s spectral properties; there is no bound on state evolution error, no conditions guaranteeing contraction/stability, and no guarantees on long-horizon behavior versus the continuous formulation.
- Approximation gap for exp(⋅) is unquantified: there is no formal error bound or calibration linking exp(x) to 2{⌊x⌉} (or more accurate 2{x}/ln 2 scaling), nor analysis of the impact of rounding on system dynamics and forecasting accuracy.
- PTSoftplus and PTSiLU proofs do not quantify task-level impact: while smoothness and function/derivative deviation bounds are provided, there is no analysis of how these approximations affect gating behavior, gradient flow, convergence, and final accuracy under different quantization bit-widths.
- PTSiLU closeness proof relies on computer-aided bounds over a finite interval: the [-10, 10] analysis is not complemented by a rigorous global bound or worst-case guarantees across all real inputs.
- Quantization scope is unclear: activations are quantized with LSQ, but treatment of weights (especially in convolution, B, C, D, and the final head) is not specified; without weight quantization or power-of-two constraints, multiplications may persist.
- RMSNorm implementation is not detailed for SNNs: normalization typically involves division/square-root and dense operations; the paper does not explain how RMSNorm is implemented or approximated in a multiplication- and exponentiation-free manner on neuromorphic hardware.
- Conversion versus direct SNN training remains unexplored: only ANN-to-SNN conversion (Average IF) is used; a comparison with direct SNN training via surrogate gradients (accuracy, energy, stability) is missing.
- Spike thresholding and rate control are under-specified: there is no systematic study of learned versus fixed thresholds, per-layer/per-channel threshold adaptation, or techniques to maintain desired sparsity/accuracy across datasets.
- No analysis of worst-case complexity: the claimed linear-time scan and energy savings depend on spike sparsity; there is no characterization of the worst case (dense spikes), the distribution of spikes per layer, and how this affects latency and memory traffic.
- Dataset coverage and generality are limited: evaluation is on four standard multivariate forecasting datasets; there is no assessment on irregular sampling, missing values, exogenous variables, regime shifts, or graph-structured time series where spatial dependencies are critical.
- Lack of standardized baselines and fairness checks: comparisons with iTransformer, iSpikformer, and SpikeSTAG do not clearly document parity in window sizes, horizons, parameter counts, training budgets, and hyperparameters; standardized evaluation protocols are needed.
- No comparison to non-spiking SSMs under comparable efficiency constraints: the paper does not benchmark against Mamba/S4 variants with quantization/pruning to contextualize the trade-off between accuracy and energy beyond transformers/SNN baselines.
- Scaling laws and capacity constraints are unexamined: the impact of d_hidden, number of states n, and model depth on the accuracy–energy Pareto front is not studied; guidelines for choosing these hyperparameters under tight budgets are absent.
- Robustness and reliability are not tested: there is no evaluation under noise, missing data, outliers, adversarial perturbations, or distribution shift, which are common in edge sensing applications.
- Streaming and online operation are not validated: despite targeting edge deployments, the paper does not show continuous, online inference latencies, memory footprints, or performance under varying stream rates and bursty event patterns.
- Memory subsystem behavior lacks empirical validation: off-chip traffic is estimated but not measured; there is no breakdown across layers/paths, nor sensitivity analysis to batch size, sequence length, and firing rate on actual hardware.
- Autoregressive versus direct multi-horizon forecasting is not contrasted: the head maps L_in to L_out directly; the paper does not compare iterative/autoregressive strategies, hybrid approaches, or error accumulation behavior over long horizons.
- Spatial modeling is not addressed: METR-LA and similar datasets benefit from graph-based spatial correlations; SpikySpace uses depthwise 1D convs without explicit graph modeling; the gains or losses relative to graph SNNs/SSMs remain unclear.
- Practical deployment details are missing: there is no end-to-end implementation plan (kernel libraries, scheduling, memory layout) for neuromorphic chips, nor mapping details for the selective scan and bit-shift approximations on specific hardware toolchains.
- Energy–accuracy trade-off knobs are not exposed: the paper does not provide actionable tuning guidelines (bit-widths, thresholds, Δ parameterization, firing rate targets) to navigate different deployment budgets and accuracy requirements.
Practical Applications
Immediate Applications
Below are practical, deployable applications that can leverage the paper’s findings and methods today, given existing edge hardware, neuromorphic toolchains, and standard time-series datasets.
- Edge traffic forecasting and control (sector: transportation)
- Use SpikySpace to predict short-horizon traffic flows on intersection controllers and roadside units, enabling signal timing optimization and congestion alerts without cloud dependence.
- Tools/products/workflows: A “SpikySpace Edge Forecaster” compiled for ARM Cortex-M/ESP32-class microcontrollers with a training-to-conversion pipeline (quantized ANN → SNN). Integrate with existing ITS workflows for 5–60 minute rolling forecasts.
- Assumptions/dependencies: Availability of traffic sensor feeds; deployable SNN runtimes (e.g., Lava/Nengo/snnTorch ports); stable performance under domain shift beyond METR-LA-like datasets.
- Smart meter and building load forecasting (sector: energy)
- Deploy on smart meters, gateways, or BMS controllers to predict short-term electricity demand and enact demand-response or preemptive HVAC setpoints.
- Tools/products/workflows: A TinyML-compatible SpikySpace model with
PTSoftplus/PTSiLULUTs and bit-shift kernels; pipeline for continuous model updates on back-office servers and periodic on-device refresh. - Assumptions/dependencies: Consistent metering cadence; compatibility with device memory/compute budgets; accuracy on diverse load profiles similar to the “Electricity” dataset.
- Industrial condition monitoring and predictive maintenance (sector: manufacturing)
- On-device forecasting of vibration, temperature, or pressure time series to flag anomalies and predict equipment degradation with ultra-low energy budgets.
- Tools/products/workflows: Embedded SNN firmware with “Selective Scan” kernels; SOP- and memory-traffic profiling to meet battery-powered sensor constraints; integration with OPC-UA/SCADA.
- Assumptions/dependencies: Reliable sensor calibration; event-driven data streams; threshold and time-window tuning (spiking timestep T, quantization bits n) for each asset class.
- Wearable and mobile health time-series analytics (sector: healthcare)
- On-device prediction of heart-rate trends, activity states, or sleep phase transitions to deliver responsive coaching or alerts while preserving privacy.
- Tools/products/workflows: Smartphone/SoC inference libraries that replace dense multiplications with additions/bit-shifts; pipeline for quantized training with
PTSoftplusandPTSiLU. - Assumptions/dependencies: Battery constraints and inference latencies compatible with device UX; domain adaptation from benchmark multivariate datasets to physiological signals.
- Smart home/IoT device forecasting (sector: consumer electronics)
- Local forecasting of environmental sensors (temperature, humidity, CO2) to optimize HVAC, air purifiers, and energy scheduling without cloud calls.
- Tools/products/workflows: “Neuromorphic Time-Series SDK” for MCU deployment; auto-calibrated thresholds for Average Integrate-and-Fire neurons; rolling model updates (daily/weekly).
- Assumptions/dependencies: Stable sensor sampling and noise filtering; device SDK support for integer arithmetic and bit-shifts; user privacy policies allowing on-device learning.
- Network edge analytics (sector: software/infrastructure)
- Lightweight anomaly prediction in IoT gateways or base stations to prioritize telemetry and reduce backhaul bandwidth.
- Tools/products/workflows: SpikySpace packaged as a containerized microservice for edge nodes; SOP-based energy monitoring and admission control.
- Assumptions/dependencies: Sufficient memory to hold constant-size latent state; compatibility with heterogeneous edge platforms.
- Academic benchmarking and teaching modules (sector: education/research)
- Use SpikySpace as a reference model for courses on energy-efficient ML, neuromorphic computing, and time-series SSMs; reproduce reported energy savings and accuracy.
- Tools/products/workflows: Teaching labs with the ANN→SNN conversion workflow; experiments on electricity and traffic datasets to demonstrate sparsity-vs-accuracy trade-offs.
- Assumptions/dependencies: Access to open datasets and SNN toolchains; student-friendly docs and code examples.
- Privacy-preserving, on-device analytics (sector: policy/IT governance)
- Immediate policy-aligned deployment where data leaves the device only as aggregated forecasts; reduces exposure and compliance overhead (e.g., GDPR).
- Tools/products/workflows: Edge-first analytics policies paired with SpikySpace models; audit trails of energy use and data movement.
- Assumptions/dependencies: Organizational acceptance of edge inference; governance frameworks that recognize energy and privacy benefits.
Long-Term Applications
These applications require further research, scaling, hardware co-design, or broader ecosystem maturation (neuromorphic chips, standardized toolchains, domain validations).
- Co-designed neuromorphic accelerators for state-space forecasting (sector: semiconductors/robotics/energy)
- Dedicated “Selective Scan” and spike-driven SSM accelerators that natively implement 2k transitions, spike gating, and SOP counters for predictable energy.
- Tools/products/workflows: ASIC/FPGA IP blocks for
PTSoftplus/PTSiLULUTs; compiler passes for spiking SSM kernels; integration with Loihi-like platforms. - Assumptions/dependencies: Hardware vendor adoption; standardization of spike-driven SSM primitives; verified gains over DSPs/GPUs.
- City-scale smart infrastructure forecasting (sector: smart cities/transportation/energy)
- Distributed deployment across thousands of sensors for traffic, power, water, and air quality; hierarchical edge aggregation with minimal data movement.
- Tools/products/workflows: MLOps for federated, on-device training and conversion; policy frameworks for energy-aware AI procurement and maintenance.
- Assumptions/dependencies: Robustness to non-stationarity and extreme events; interoperable data standards; large-scale evaluation beyond four benchmark datasets.
- Medical-grade neuromorphic analytics (sector: healthcare)
- Certified low-power forecasting for implantables or clinical monitors (e.g., early deterioration alarms) with strong explainability and reliability.
- Tools/products/workflows: Clinical validation studies; safety-certified firmware; continuous calibration protocols for spiking thresholds and quantization scales.
- Assumptions/dependencies: Regulatory approvals (FDA/CE); rigorous generalization tests across patients and devices; standardized datasets and evaluation metrics.
- Autonomous systems and robotics predictive control (sector: robotics/mobility)
- Onboard forecasting of sensor streams (IMU/LiDAR/time-of-flight) to anticipate dynamics for high-frequency control loops under strict power budgets.
- Tools/products/workflows: Real-time spiking SSM controllers with bounded latency; co-integration with model predictive control; hardware-in-the-loop testing.
- Assumptions/dependencies: Stable performance on irregular sampling and multimodal streams; safety guarantees; domain-specific tuning of SSM parameters and spiking timesteps.
- Microgrid and storage management (sector: energy)
- Fine-grained forecasting for microgrids, storage SOC/health, and renewable ramps running locally at edge controllers; support for islanded operation.
- Tools/products/workflows: Forecast-to-actuation pipelines; event-driven scheduling policies; energy market interfaces for prosumers.
- Assumptions/dependencies: Validation on diverse renewable regimes; resilience to missing data and sensor drift; standards for decentralized energy control.
- Finance and retail edge analytics (sector: finance/retail)
- Low-power demand forecasting at POS or branch devices; tactics like inventory pre-positioning or dynamic staffing aligned to on-device forecasts.
- Tools/products/workflows: Retail IoT firmware; edge dashboards; hybrid cloud-edge training with quantization-aware updates.
- Assumptions/dependencies: Suitability of SpikySpace for highly volatile, regime-shifting signals; explainability requirements; data governance constraints.
- Standardized energy-aware AI procurement and compliance (sector: policy)
- Institutional policies that set energy budgets for edge models, require SOP/memory-traffic reporting, and incentivize spiking SSM approaches for public deployments.
- Tools/products/workflows: Compliance checklists and model cards documenting energy metrics and privacy posture; lifecycle management standards.
- Assumptions/dependencies: Consensus on metrics (SOPs, off-chip traffic) as proxies for energy; public-sector capability to audit and enforce.
- Generalization to irregular/event-driven and multimodal streams (sector: software/AI research)
- Extending SpikySpace to handle asynchronous sampling, missingness, and cross-modal fusion (audio, vision, text) while retaining spiking sparsity.
- Tools/products/workflows: Advanced training schemes (surrogate gradients + conversion); adaptive
Δestimation under non-uniform timesteps; multimodal spiking encoders. - Assumptions/dependencies: Algorithmic advances beyond current selective scanning; broader benchmarks; stability of
PTSoftplus/PTSiLUin multimodal regimes.
Notes on feasibility across applications:
- Reported energy savings are estimated via synaptic operations (SOPs) and memory traffic proxies; real-world gains depend on hardware, toolchain efficiency, and workload characteristics.
- Accuracy was demonstrated on four standard multivariate datasets (e.g., METR-LA, Electricity); domain transfer may require additional calibration and data augmentation.
- The ANN-to-SNN conversion pipeline and quantization hyperparameters (bit width, thresholds, timestep T) materially impact both accuracy and sparsity; deployment should include calibration and validation phases.
- Current neuromorphic hardware availability is limited; in the interim, integer/bit-shift kernels can target MCUs, DSPs, or FPGAs with careful optimization.
Glossary
- ANN-to-SNN conversion: A training strategy that maps a pre-trained artificial neural network’s continuous activations to spiking dynamics to obtain a functionally equivalent spiking model. "The second, ANN-to-SNN conversion \cite{ANN-SNN-conversion}, leverages a pre-trained artificial neural network (ANN) and maps its continuous neuron activations to spiking dynamics, producing a functionally similar SNN."
- Average Integrate-and-Fire (IF): An optimized spiking neuron variant that reduces memory access by accumulating inputs and updating membrane potential in a single step per timestep. "We adopt an optimized version called Average Integrate-and-Fire~\cite{yan2025low}, which reduces memory access by accumulating inputs and updating the potential in a single step, requiring only one read of the synaptic weights per time step."
- Bit-shifting operations: Low-cost hardware operations that implement power-of-two scalings efficiently by shifting bits rather than performing multiplications or divisions. "This design allows the activation to be implemented through efficient bit-shifting operations, removing costly divisions and exponentials while preserving smooth gating behavior."
- Convolutional kernel: The impulse response used to express the system output as a convolution over inputs, enabling efficient long-range sequence modeling in SSMs. "Compared with generic recurrent architectures, SSMs admit exact continuous-to-discrete conversions and an analytic convolutional kernel, which together enable numerically stable long-horizon reasoning and efficient implementations."
- Continuous-to-discrete conversions: Exact transformations that map continuous-time SSMs to discrete-time forms for stable and efficient computation. "Compared with generic recurrent architectures, SSMs admit exact continuous-to-discrete conversions and an analytic convolutional kernel, which together enable numerically stable long-horizon reasoning and efficient implementations."
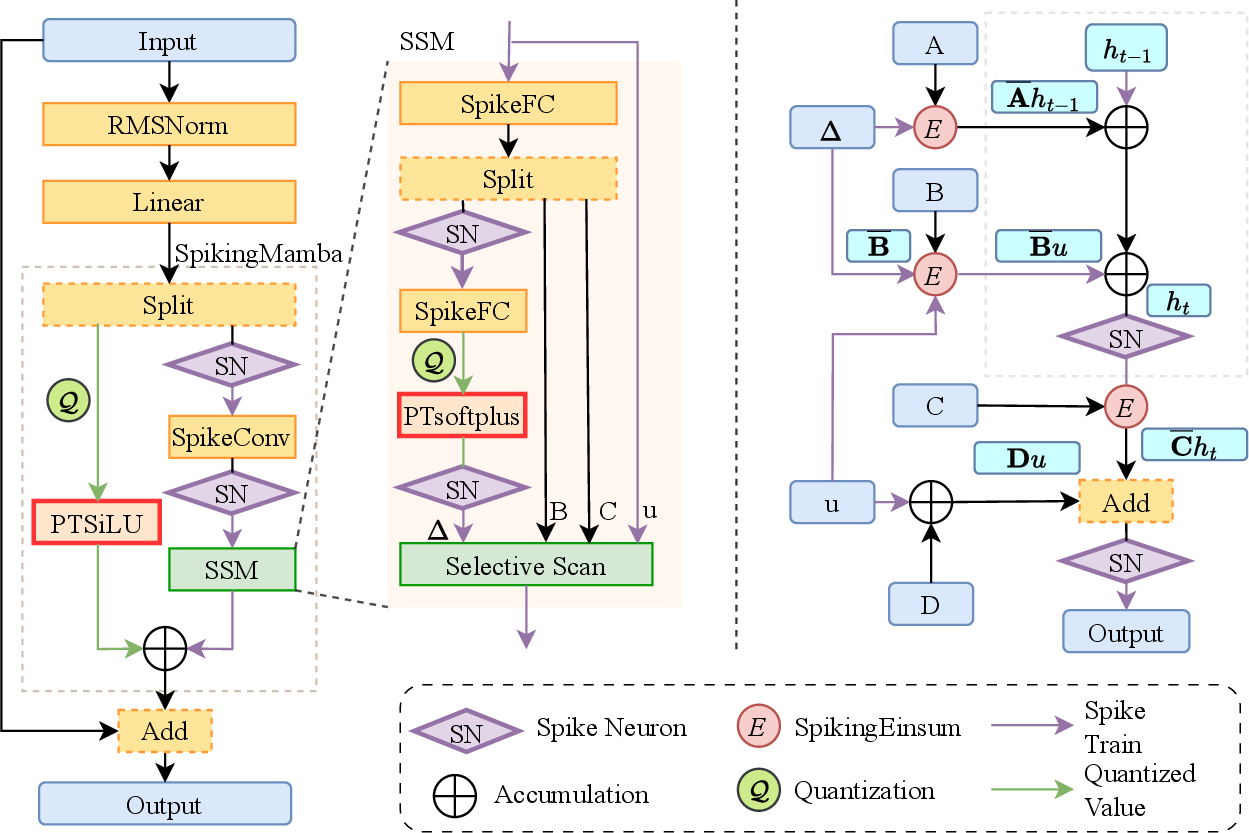
- Depth-wise separable 1D convolution: A lightweight convolution that applies per-channel temporal filtering, reducing parameters and computation while capturing local features. "Before entering the SSM block, the data path \mathbf{x}_{\text{in} undergoes depth-wise separable 1D convolution to capture the local temporal feature."
- Diagonalizable dynamics: A parameterization of SSM state-transition matrices that simplifies computation and stability by using diagonal or diagonalizable forms. "Meanwhile, the SSMâs diagonalizable dynamics parameters are learned as"
- Dilation: A technique in temporal convolutions that spaces kernel elements to enlarge the receptive field without increasing kernel size. "Temporal convolutional networks (TCNs) enlarge receptive fields through dilation and allow parallel training, but require deep stacks or large kernels to capture long-range contexts."
- Event-driven computation: A processing paradigm where operations occur only on discrete input events (spikes), reducing energy and latency. "Spiking neural networks (SNNs) offer event-driven computation and ultra-low power by exploiting temporal sparsity and multiplication-free computation."
- Integrate-and-Fire (IF) neuron: A spiking neuron model that integrates synaptic inputs into a membrane potential and emits spikes when a threshold is exceeded. "Among spiking neuron models, the Integrate-and-Fire (IF) neuron is widely used for its simplicity and efficiency \cite{SNN-Review}."
- Key–value caches: Memory structures in transformers that store past keys and values to enable attention over long contexts, often creating memory bottlenecks. "However, these models remain memory-bound due to keyâvalue caches and dense step-wise updates."
- Latent state: A compact internal memory vector in SSMs that evolves over time to capture long-range dependencies. "Mechanistically, SpikySpace retains information over long horizons through its explicit latent state, while event-driven spikes naturally skip redundant updates."
- Learned Step-size Quantization (LSQ): A quantization method that learns the quantization step size and optionally the offset to improve low-bit performance. "The quantization is in a Learned Step-size Quantization(LSQ) manner."
- Linear-time recurrences: State updates in sequence models whose computational complexity scales linearly with sequence length. "SSMs represent temporal dynamics through compact latent states updated via linear-time recurrences."
- Mamba: A modern state-space modeling framework that replaces attention with efficient scanning to achieve linear-time sequence modeling. "In the original Mamba formulation, the transition matrix is obtained through an exponential operation:"
- Membrane potential: The internal voltage-like state of a spiking neuron that integrates inputs and triggers spikes upon reaching a threshold. "A spiking neuron integrates incoming signals over time and emits a spike once its “membrane potential” exceeds a threshold, mimicking the behavior of biological neurons."
- Neuromorphic hardware: Specialized computing platforms designed to emulate neural spiking and synaptic behavior for energy-efficient event-driven computation. "This makes it exceptionally energy-efficient and inherently compatible with neuromorphic hardware."
- Power-of-two representation: An approximation technique that replaces exponentials or multiplications with powers of two for efficient hardware implementation. "To facilitate hardware efficiency, we approximate the exponential with a power-of-two representation and round the input to integers, which allows efficient bit-shifting implementation:"
- Pre-normalization structure: A design pattern where normalization is applied before the main block to stabilize training and improve performance. "it employs a pre-normalization structure, utilizing RMSNorm before the Spiking Mamba unit designed for time series forecasting to stabilize the training dynamics."
- PTSoftplus: A power-of-two-based, piecewise approximation to Softplus designed for neuromorphic efficiency while preserving smoothness. "We first develop SNN-compatible approximations for Softplus and SiLU with power-of-two components and linear transformations, namely PTsoftplus and PTSiLU."
- PTSiLU: A power-of-two-based, piecewise approximation to the SiLU activation that avoids expensive exponentials and divisions. "We first develop SNN-compatible approximations for Softplus and SiLU with power-of-two components and linear transformations, namely PTsoftplus and PTSiLU."
- Residual gating module: A component that modulates residual signals via learned gates to enhance nonlinearity and stability, especially under quantization. "After obtaining the output \mathbf{y} from the SSM, we further apply a lightweight residual gating module to enhance nonlinearity and stabilize quantized representations."
- RMSNorm: A normalization technique that scales activations based on their root-mean-square, often used to stabilize transformer-like architectures. "it employs a pre-normalization structure, utilizing RMSNorm before the Spiking Mamba unit designed for time series forecasting to stabilize the training dynamics."
- Selective scan: An SSM execution strategy that scans sequences with adaptive, spike-driven updates to achieve linear-time complexity and efficiency. "With the learned parameters and step size, the SSM then performs a spike-driven selective scan to iteratively update the latent state."
- SiLU: An activation function defined as x multiplied by its sigmoid, used for smooth gating and improved optimization properties. "The SiLU activation is defined as:"
- Softplus: A smooth, differentiable approximation to ReLU that maintains non-negativity and stable gradients, commonly used in SSMs. "The Softplus function is widely used in SSMs such as Mamba, where the non-negativity of state parameters and stable gradient flow are crucial for modeling long-range temporal dynamics."
- Spike timing: The temporal pattern of spike occurrences, which carries information and enables temporal coding in SNNs. "Furthermore, SNNs possess an intrinsic ability to model temporal dynamics through membrane potentials and spike timing, making it well-suited for streaming time-series forecasting..."
- Spike train: A sequence of discrete binary spike events over time representing neural activity in SNNs. "which transforms the continuous feature \mathbf{x}_{\text{in} into a sparse, binary spike train \mathbf{s} \in \{0, 1\} over T timesteps:"
- Spiking neural networks (SNNs): Neural models that compute with discrete spikes and event-driven dynamics to achieve energy-efficient processing. "Spiking neural networks (SNNs) consist of interconnected spiking neurons that communicate through discrete spike events, enabling energy-efficient and event-driven computation \cite{taherkhani2020review, zhou2024direct}."
- State Space Model (SSM): A sequence model that evolves a low-dimensional hidden state via linear recurrences to capture long-range dependencies efficiently. "State Space Models (SSMs) provide a compact, physics-inspired way to model sequence dynamics by evolving a low-dimensional latent state and mapping it to observable outputs."
- Straight-through estimator (STE): A gradient approximation technique that passes gradients through non-differentiable quantization operations during backpropagation. "Straight-through estimator (STE) is employed as commonly used in previous works to back-propagate the gradients to ."
- Structured memory: Organized, model-based state retention (e.g., via SSMs) that preserves long-range information with efficient updates. "Further, we replace dense SSM updates with sparse spike trains and execute selective scans only on spike events, thereby avoiding dense multiplications while preserving the SSMâs structured memory."
- Surrogate gradients: Approximate gradients used to enable training of non-differentiable spiking functions via gradient-based methods. "The first relies on surrogate gradients \cite{surrogat_egradient}, which approximate the gradients of spike events to allow backpropagation."
- Temporal sparsity: A property where computation is triggered only by informative temporal changes, reducing operations compared to dense updates. "Spiking neural networks (SNNs) offer event-driven computation and ultra-low power by exploiting temporal sparsity and multiplication-free computation."
- Threshold: The membrane potential level at which a spiking neuron fires a spike and resets. "A spiking neuron integrates incoming signals over time and emits a spike once its “membrane potential” exceeds a threshold, mimicking the behavior of biological neurons."
Collections
Sign up for free to add this paper to one or more collections.