HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Abstract: State-of-the-art text-to-video models excel at generating isolated clips but fall short of creating the coherent, multi-shot narratives, which are the essence of storytelling. We bridge this "narrative gap" with HoloCine, a model that generates entire scenes holistically to ensure global consistency from the first shot to the last. Our architecture achieves precise directorial control through a Window Cross-Attention mechanism that localizes text prompts to specific shots, while a Sparse Inter-Shot Self-Attention pattern (dense within shots but sparse between them) ensures the efficiency required for minute-scale generation. Beyond setting a new state-of-the-art in narrative coherence, HoloCine develops remarkable emergent abilities: a persistent memory for characters and scenes, and an intuitive grasp of cinematic techniques. Our work marks a pivotal shift from clip synthesis towards automated filmmaking, making end-to-end cinematic creation a tangible future. Our code is available at: https://holo-cine.github.io/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching an AI to make short “movie scenes” with several different shots, not just one continuous clip. The system, called HoloCine, takes a text prompt and creates a multi-shot video that looks and feels like a real scene: it keeps the same characters and setting across shots, follows the script, and switches shots at the right times.
Goals and Questions
The authors want to solve the “narrative gap” in AI video: current models can make single, nice-looking clips, but real storytelling uses many shots edited together. They focus on three simple questions:
- How can an AI keep characters and places consistent across multiple shots?
- How can it follow detailed instructions for each shot (like “zoom in” or “switch to a close-up”)?
- How can it do all this quickly enough to make longer videos?
How HoloCine Works
Think of making a scene like running a school play:
- You have a script for the whole scene.
- You also have specific directions for each shot (“Shot 1: wide view of the beach”, “Shot 2: close-up of the hero’s face”, etc.).
- The cast should look the same from start to finish, and the camera should move as the director says.
HoloCine uses two core ideas to make this happen:
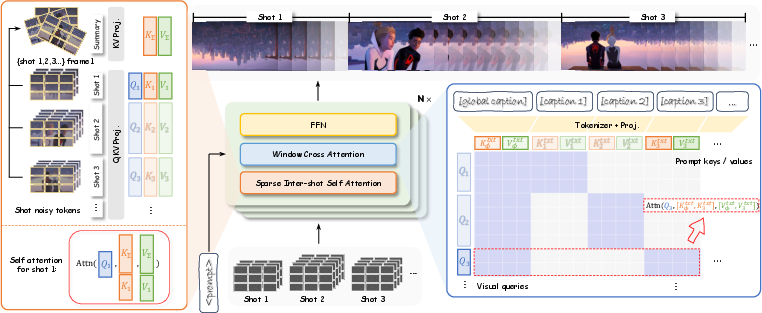
- Window Cross-Attention (like focused director notes)
- Analogy: Each shot’s crew only reads the part of the script that applies to their shot, plus the overall scene summary.
- In AI terms: The model “pays attention” only to the text relevant to the current shot and the global context. This helps it switch shots cleanly and follow per-shot instructions exactly.
- Sparse Inter-Shot Self-Attention (like sharing quick summaries)
- Analogy: People within the same shot talk a lot to coordinate their actions (dense communication). Between different shots, they don’t share everything; they exchange brief highlights so everyone remembers important details (like who the hero is and what the setting looks like).
- In AI terms: Inside a shot, the model connects frames very tightly to keep motion smooth. Between shots, it passes around small “summary tokens” (like a compact snapshot) so characters and style stay consistent without the heavy cost of making every frame talk to every other frame. This makes longer videos practical.
To train HoloCine, the team built a big dataset from movies and TV:
- They split videos into shots.
- They grouped shots into scenes with different lengths (5, 15, and 60 seconds).
- They wrote “hierarchical prompts”: one global description of the scene plus detailed instructions for each shot, separated by a [shot cut] marker. Think of it as a full script plus shot-by-shot directions.
Main Findings
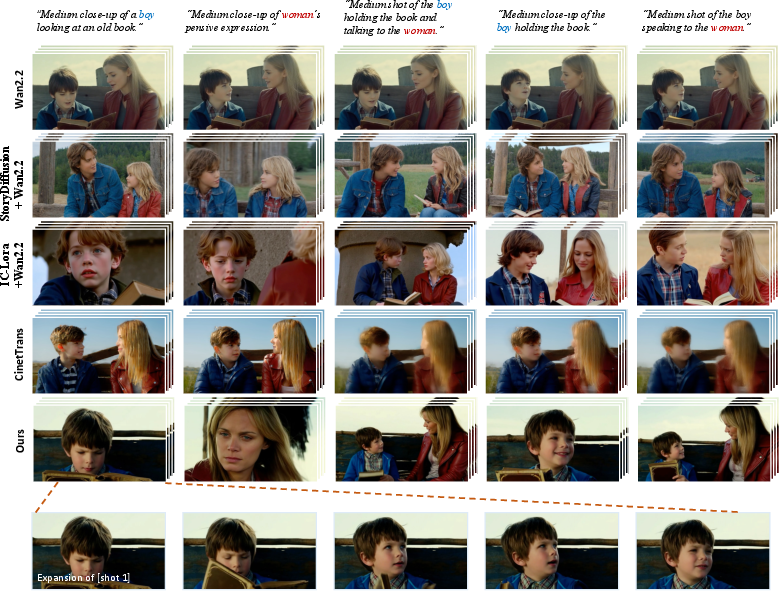
The authors tested HoloCine against strong baselines, including:
- Big single-shot video models
- Two-stage pipelines that first make images (keyframes) and then animate them
- Other “holistic” models that try to make multi-shot videos in one go
What they found:
- Better shot control: HoloCine places shot cuts at the right times and follows per-shot instructions more accurately.
- Strong consistency: Characters and settings stay the same across shots (inter-shot consistency), and motion stays smooth within each shot (intra-shot consistency).
- Good script following: The videos match the text prompts well.
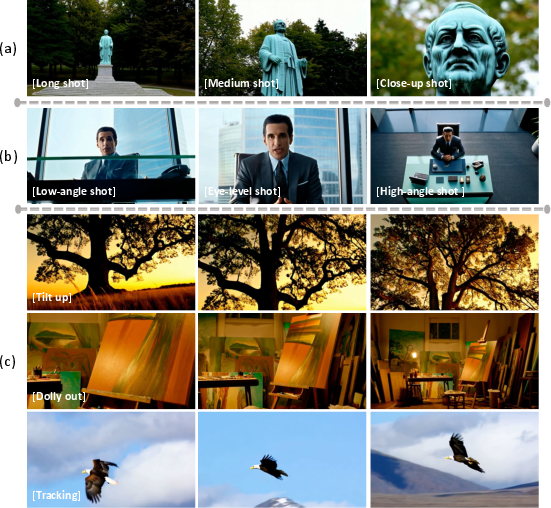
- Emergent “movie sense”: Surprisingly, the model remembers characters and even small background details across shots, and it understands common film language—like long shots vs. close-ups, camera angles (low, eye-level, high), and camera moves (tilt, dolly, tracking).
They also show that HoloCine can make minute-long scenes efficiently, something that’s very hard for standard methods.
Why This Matters
HoloCine moves AI video closer to real filmmaking:
- Creators could type a scene description and get a whole edited sequence—not just isolated clips.
- Pre-visualization for movies, shows, ads, and classrooms could be faster and more accessible.
- It hints at future tools where writing a script could generate a fully directed video, end-to-end.
A simple limitation to note:
- The model sometimes struggles with cause-and-effect. For example, if water is poured into an empty glass, it might not update the glass to be full in the next shot. This shows AI still needs better “physical logic” for certain scenarios.
In Short
HoloCine is an AI that makes multi-shot video scenes from text in one pass. It keeps characters and settings consistent, follows precise shot instructions, and runs efficiently by focusing on the right parts of the script and sharing compact summaries across shots. It sets a new bar for narrative coherence in AI video and points toward a future of automated, end-to-end filmmaking.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each point is concrete to help future researchers act on it.
- Dataset release and licensing: The curated multi-shot dataset built from films/TV “public sources” is not described in terms of licensing, consent, or release plans, hindering reproducibility and raising potential legal/ethical questions.
- Caption quality assurance: Hierarchical prompts are auto-generated by an LLM (Gemini 2.5); the paper does not quantify caption accuracy, coverage, or noise rates, nor the impact of caption errors on training and inference.
- Human validation: No human evaluation is reported for narrative coherence, character consistency, or cinematographic control; reliance on automatic metrics may not capture perceptual and storytelling quality.
- Benchmarking gaps: The 100-prompt test set is synthetic (LLM-generated) and not publicly standardized; a community benchmark with ground-truth shot boundaries, duration targets, and transition types is missing.
- Metric validity and calibration: The proposed Shot Cut Accuracy (SCA) depends on TransNet V2 shot detection without validating its accuracy for AI-generated content (e.g., stylized scenes, soft transitions); no human calibration or inter-rater reliability is provided.
- Duration control: The framework and metrics focus on cut timing but do not provide mechanisms or evaluation for precise per-shot duration control and pacing—critical for editing rhythm.
- Transition types beyond hard cuts: Support and evaluation for cinematic transitions (dissolves, fades, wipes, match cuts) are absent; the attention design and SCA do not cover non-cut transitions.
- Audio and audiovisual coherence: The method does not address audio generation, lip-sync, dialogue continuity, or soundtrack transitions—key elements of cinematic narratives.
- Cross-shot textual dependencies: Window Cross-Attention restricts tokens to global + per-shot prompts; handling co-reference or callbacks across shots (“He replies,” “She returns”) is not explored.
- Robustness to free-form prompts: The system assumes hierarchical (global + per-shot) prompts with explicit [shot cut] markers; robustness to user prompts lacking explicit shot structure or with vague instructions is untested.
- Identity persistence measurement: Inter-shot consistency is assessed via ViCLIP similarity within character groups from prompts; there is no identity-tracking metric (e.g., face/person re-ID) to quantify identity drift under occlusion, pose change, or reappearance after many shots.
- Emergent memory quantification: Memory claims (A–B–A recall, background detail persistence) are qualitative; no controlled experiments measure memory horizon, failure rates, or sensitivity to distractors and time gaps.
- Causal reasoning: The paper identifies failures in cause–effect (object state changes) but lacks a systematic benchmark and training strategies (e.g., physics priors, state-tracking losses, causal supervision) to address this.
- 3D scene and camera realism: There is no evaluation of geometric consistency (parallax, depth coherence) or physically plausible camera motion (acceleration limits, rig constraints); metrics for 3D continuity are missing.
- Cinematographic grammar: Adherence to film grammar (180-degree rule, eyeline matches, match cuts, continuity editing) is not evaluated; control over lens parameters (focal length, aperture), lighting continuity, and exposure is not supported or measured.
- Scaling beyond 60s/13 shots: The model is trained/evaluated up to 60 seconds and 13 shots; empirical scaling curves (quality, runtime, memory) for longer sequences and higher shot counts are not reported.
- Inference efficiency and accessibility: Generation time, GPU memory footprint, and performance on modest hardware are not reported; practicality for typical users (without 128 H800s) remains unclear.
- Sparse Inter-Shot Self-Attention design: Summary token selection is only lightly ablated; dynamic, learned summaries, routing, or adaptive sparsity (e.g., MoE-style routers) are not explored or benchmarked.
- Error recovery and editability: The reliance on first-frame summary tokens suggests early errors may propagate; mechanisms for mid-sequence correction, iterative editing, or region-level refinements are not provided.
- Generalization across languages: It is unclear if the model supports multi-lingual prompts and how performance varies across languages or cultural domains; captioning was likely English-centric.
- Domain breadth and bias: Dataset composition (genres, lighting conditions, demographics) and potential biases are not quantified; performance variation across genres (e.g., sports, animation, documentary) is unexplored.
- Personalization via references: The framework does not support conditioning on user-supplied character/scene references (images/video) for reliable identity continuity in holistic generation.
- Multi-threaded narratives: Handling cross-cutting (interleaving parallel actions across locations) and maintaining coherence across multiple storylines is not studied.
- Shot-length variability and control: While training uses fixed target durations (5s/15s/60s), the system’s ability to honor user-specified per-shot length distributions or variable pacing within a scene is not evaluated.
- Safety and ethics: The paper does not analyze content safety (e.g., violence, sensitive portrayals), representational biases, or misuse risks when generating cinematic narratives from text.
- Reproducibility details: Key training choices (data splits, caption quality filters, prompt templates, ablation configurations) and whether code for varlen FlashAttention packing + masking will be fully released are not specified.
- Comparative fairness: Many baselines are unavailable; quantitative comparison with strong closed models (e.g., Sora) is absent; a plan to enable standardized, reproducible cross-model evaluation is needed.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s holistic multi-shot generation, Window Cross-Attention (shot-level control), Sparse Inter-Shot Self-Attention (efficient scaling), hierarchical prompting, and evaluation metrics (e.g., Shot Cut Accuracy).
- Previsualization and storyboarding for film/TV and streaming (entertainment/media)
- Use text-to-multi-shot generation to produce minute-scale scene drafts with consistent characters, controllable shot cuts, and camera language.
- Tools/products/workflows: “Shot Prompt Editor” UI for per-shot prompts; HoloCine plug-ins for Adobe Premiere/After Effects/DaVinci Resolve; a “Previz Studio” SaaS with WCA-enabled shot mapping; export shot lists with cut timestamps.
- Assumptions/dependencies: Access to high-GPU inference; legal rights for model and training data; human director supervision for creative alignment; sound design and color grading still external.
- Rapid iteration of digital ad campaigns and social content (advertising/marketing, creator economy)
- Generate multiple coherent multi-shot versions for A/B testing, maintaining brand assets and character consistency.
- Tools/products/workflows: Brand-aware prompt libraries; batch generation pipeline with per-shot editing; SCA-based QA for cut accuracy before delivery.
- Assumptions/dependencies: Prompt engineering expertise; asset licensing and brand safety checks; compute costs; content moderation.
- Game cutscene prototyping and in-engine cinematic planning (gaming/software)
- Produce consistent multi-shot drafts of narrative sequences with accurate shot scales, angles, and movements for previsualization before in-engine implementation.
- Tools/products/workflows: Unreal/Unity plug-ins to convert shot prompts to camera rigs; “Cinematic Previz API” exposing WCA to design shot-by-shot requirements.
- Assumptions/dependencies: Integration with engine pipelines; art style alignment; IP constraints; human review for gameplay coherence.
- Cinematography, directing, and media literacy education (education)
- Demonstrate shot scales, angles, and camera movements via controllable prompts; create assignments that require students to specify per-shot prompts and compare outcomes.
- Tools/products/workflows: Classroom toolkit using hierarchical prompts; auto-assessment via SCA for shot control and VBench metrics for prompt adherence.
- Assumptions/dependencies: Institutional licensing; instructor oversight; caution about causal reasoning limitations in procedure demonstrations.
- Automated continuity and shot-control QA for post-production (media tech/software)
- Use SCA to verify deliveries match specified cut counts and timing; check inter-shot consistency with ViCLIP-based scores for character identity continuity.
- Tools/products/workflows: “Continuity Checker” service that ingests video and script; dashboard showing SCA, inter-/intra-shot metrics; alerts for drift.
- Assumptions/dependencies: Reliable detectors (TransNet V2); production adoption of shot-level specs; threshold calibration with human QA.
- Synthetic data generation for computer vision tasks (academia/AI research)
- Create labeled multi-shot sequences to train/evaluate shot boundary detection, camera motion recognition, and long-range identity tracking with consistent characters.
- Tools/products/workflows: Dataset generator using per-shot prompts plus auto-labels (cut positions, camera moves); public benchmarks incorporating SCA, VBench, ViCLIP metrics.
- Assumptions/dependencies: Dataset governance; domain gap vs. real footage; transparent documentation of generation process.
- Internal corporate training and product demos (enterprise communications)
- Rapidly produce coherent stepwise explainer videos with consistent scenes and personas (e.g., onboarding, product walkthroughs).
- Tools/products/workflows: Template libraries for common scenarios; review loop with per-shot prompt editing; SCA to validate structure.
- Assumptions/dependencies: Accuracy requirements; limitations in causal/physical state changes; compliance with internal policies.
- Localization and accessibility versions of narratives (media localization)
- Generate region-specific multi-shot edits with consistent characters while modifying environments, props, or language overlays per shot.
- Tools/products/workflows: Prompt variants tied to locale; subtitle/voice-over pipelines; version management via cut timestamps.
- Assumptions/dependencies: Cultural sensitivity; rights for likeness and brand elements; translation quality; compute for batch generation.
- Research adoption of metrics and pipelines (academia)
- Use Shot Cut Accuracy (SCA), VBench extensions, and hierarchical captioning protocols to evaluate multi-shot models and establish shared benchmarks.
- Tools/products/workflows: Reproducible evaluation harness; open-sourced shot boundary and prompt alignment workflows.
- Assumptions/dependencies: Agreement on metric standards; access to code/models; consistent hierarchical prompt formatting.
Long-Term Applications
These applications require further research, scaling, integration, and/or policy development, especially around causal reasoning, legal provenance, cost reduction, and production-grade workflows.
- End-to-end automated filmmaking with “AI director” capabilities (entertainment/media)
- From script to final cut: multi-shot generation with automated casting of digital doubles, shot planning, camera blocking, and iterative revisions with human-in-the-loop direction.
- Tools/products/workflows: Narrative DSL for shot-level specification; “Director Agent” combining LLM planning with WCA control and sparse long-context memory; pipeline integrations for sound, VFX, grading.
- Assumptions/dependencies: Robust causal reasoning; scalable, cost-efficient inference (hardware/software); provenance tracking; union and labor considerations; IP licensing.
- Interactive, personalized, and branching narrative experiences (streaming/gaming/XR)
- Real-time generation of multi-shot scenes that adapt to viewer choices while preserving character continuity across branches and episodes.
- Tools/products/workflows: Story graph orchestrators; stateful memory modules to preserve identity across branches; low-latency sparse attention inference engines.
- Assumptions/dependencies: Strong narrative state management; edge or cloud compute; content safety; user privacy.
- Virtual actors and long-horizon continuity across series and franchises (media/entertainment)
- Maintain persistent identities of digital characters across seasons, regions, and spin-offs, with robust control of camera language and style.
- Tools/products/workflows: Identity preservation training modules; continuity databases; rights management for digital likenesses.
- Assumptions/dependencies: Legal frameworks for digital personas; audience acceptance; ethical guidelines; resilient memory across very long timelines.
- Procedure-accurate instructional and medical videos (education/healthcare)
- Multi-step demonstrations (e.g., clinical procedures, lab protocols) that correctly enact state changes over time, integrating physics and cause-effect models.
- Tools/products/workflows: Causality-aware generation modules; validation via domain simulators; clinical review pipelines; regulatory compliance checks.
- Assumptions/dependencies: Address current limitation in causal reasoning; domain validation; strict safety and regulatory approvals (e.g., medical claims).
- Robotics and autonomy simulation for long-horizon tasks (robotics)
- Generate multi-shot environments with stable identities and consistent layouts for training perception and planning over extended narratives (e.g., household tasks, inspections).
- Tools/products/workflows: Physics-consistent world models; sim-to-real bridges; scenario orchestration with per-shot constraints; integration with robot learning stacks.
- Assumptions/dependencies: Accurate physics and interaction modeling; metrics for long-range consistency; scalability; domain adaptation.
- Policy, standards, and infrastructure for provenance and responsible media (public policy/media governance)
- Establish norms for watermarking, disclosure, dataset governance, and style/likeness rights in multi-shot generative media; auditability of shot-level intent and cuts.
- Tools/products/workflows: Open standards for provenance metadata (shot prompts, cut maps, model versions); auditing tools using SCA and consistency metrics.
- Assumptions/dependencies: Multi-stakeholder collaboration; enforceable regulations; adoption by platforms and studios; international harmonization.
- Cost-efficient hardware/software stacks for long video generation (semiconductors/cloud)
- Specialized accelerators and libraries for sparse inter-shot attention, varlen packing, and memory-aware diffusion to reduce quadratic costs and enable consumer-grade generation.
- Tools/products/workflows: “Sparse Attention Accelerator” hardware IP; FlashAttention-style kernels optimized for multi-shot masks; model compression/distillation for on-device generation.
- Assumptions/dependencies: Hardware R&D cycles; ecosystem support; performance/quality parity with dense attention; broad developer adoption.
- Enterprise-grade narrative automation for marketing and training (enterprise software)
- End-to-end platforms that ingest briefs and produce multi-shot campaigns, product explainers, and training content with governance, approvals, and analytics.
- Tools/products/workflows: Workflow orchestration with version control; compliance checks; SCA-based delivery SLAs; asset libraries integrated with per-shot prompts.
- Assumptions/dependencies: Integration with enterprise systems; content risk management; data privacy compliance; organizational change management.
- Localization at scale with cultural adaptation and dynamic narrative (global media)
- Automatically adapt narratives to local norms (props, scenes, idioms) while keeping character and brand continuity intact across markets.
- Tools/products/workflows: Cultural adaptation engines; locale-specific prompt libraries; QA teams using consistency and adherence metrics.
- Assumptions/dependencies: Deep cultural modeling; editorial oversight; rights management per region; efficient batch generation.
- Formalized academic benchmarks and shared datasets for multi-shot storytelling (academia)
- Large-scale, open datasets with hierarchical annotations, cut maps, and camera labels; standardized metrics (SCA, inter-/intra-shot consistency, prompt adherence).
- Tools/products/workflows: Community-maintained evaluation suites; reproducible curation pipelines (shot detection + hierarchical captioning); leaderboards.
- Assumptions/dependencies: Data licensing and ethics; funding and stewardship; participation from both open and closed-source model developers.
Glossary
- 3D U-Net: A convolutional neural network architecture extended to three dimensions for spatio-temporal generation tasks. "3D U-Net architectures"
- Aesthetic Quality: A metric reflecting human-perceived visual appeal such as composition and realism in generated frames. "Aesthetic Quality"
- autoregressive generation: A strategy that synthesizes video sequentially in overlapping chunks, conditioning each part on prior outputs. "The predominant strategy to circumvent this is autoregressive generation"
- cascaded diffusion: A multi-stage diffusion approach that progressively generates higher-quality outputs at increasing resolutions. "the potential of cascaded diffusion"
- cinematographic language: The set of film techniques (e.g., shot scale, camera movement) used to convey narrative and style. "Controllability of Cinematographic Language"
- CLIP: A vision-LLM used to measure semantic similarity between text and images or video frames. "compute CLIP feature similarities"
- Context Parallelism (CP): A parallelization method that splits long token sequences across devices to manage memory and speed up training. "Context Parallelism (CP)"
- Diffusion Forcing: A training strategy that injects controlled noise into historical context to reduce error accumulation in long generation. "Diffusion Forcing"
- Diffusion Transformer (DiT): A transformer-based diffusion architecture operating on tokenized latents instead of convolutional U-Nets. "Diffusion Transformers (DiTs)"
- DINO: A self-supervised vision model whose features are used to assess subject consistency across frames. "We extract DINO features"
- Dolly out: A camera movement where the camera physically moves backward to reveal broader context. "A [Dolly out] command results in the camera physically moving backward"
- FlashAttention-3: An optimized attention kernel supporting variable-length sequences for efficient transformer computation. "FlashAttention-3"
- Fully Sharded Data Parallelism (FSDP): A training scheme that shards model parameters across devices to fit large models in memory. "Fully Sharded Data Parallelism (FSDP)"
- global key-value cache: A compact set of summary tokens from all shots used to enable efficient inter-shot attention. "to form a global key-value cache"
- hierarchical prompt structure: A two-tier text format with a global scene description and per-shot instructions. "a hierarchical prompt structure"
- holistic generation: Jointly modeling all shots in a single process to maintain global narrative consistency. "holistic generation of multi-shot videos"
- Image-to-Video (I2V): A model that animates still images or keyframes into video sequences. "I2V model"
- in-context learning: Guiding a model to perform a task by providing examples within the prompt rather than updating weights. "in-context learning."
- interleaved positional embeddings: A positional encoding scheme that mixes shot and token positions to jointly model multi-shot sequences. "interleaved positional embeddings"
- Inter-shot Consistency: The preservation of identities, environments, and style across different shots. "Inter-shot Consistency"
- Intra-shot Consistency: The stability of subjects and backgrounds within a single continuous shot. "Intra-shot Consistency"
- keyframe-based generation: A pipeline that first produces consistent keyframes and then infills motion between them. "keyframe-based generation"
- LAION aesthetic predictor: A model used to estimate the aesthetic quality of images or frames. "the LAION aesthetic predictor"
- latent patches: Tokenized latent representations of video that transformers process instead of raw pixels. "operating on latent patches"
- LLM: A LLM used to decompose stories into sequential shot prompts. "where an LLM first decomposes a story into sequential prompts"
- Mixture of Contexts: An approach that partitions tokens into chunks and routes attention to relevant contexts for long sequences. "Mixture of Contexts"
- MMDiT: A multi-modal diffusion transformer architecture supporting joint modeling of different modalities or shots. "MMDiT architectures"
- Normalized Shot Discrepancy (NSD): An error measure of cut placement differences normalized by video length, used to compute SCA. "Normalized Shot Discrepancy"
- Radial Attention: An attention masking scheme with O(n log n) complexity based on spatio-temporal energy decay. "Radial Attention"
- SageAttention: An efficient attention mechanism combining token compression with selective computation. "SageAttention"
- Shot Cut Accuracy (SCA): A metric that evaluates both the correctness and timing precision of predicted shot cuts. "Shot Cut Accuracy (SCA)"
- Sparse Inter-Shot Self-Attention: An attention pattern that is dense within each shot but uses sparse summary connections across shots. "Sparse Inter-Shot Self-Attention"
- STA: A transformer design that processes localized 3D windows for efficient video attention. "STA utilizes localized 3D windows"
- summary tokens: A small selection of representative tokens (e.g., from a shot’s first frame) used to communicate across shots. "These summary tokens from all shots are concatenated"
- Tilt up: A vertical camera rotation upward to reveal more of the subject or scene. "a [Tilt up] command generates a smooth vertical camera motion"
- Tracking shot: A camera movement that follows a subject to keep it framed during motion. "a [Tracking] shot correctly follows the motion of a subject"
- TransNet V2: A model for detecting shot boundaries used in evaluation and data processing. "TransNet V2"
- varlen (variable-length) sequence: A representation enabling efficient attention over concatenated sequences of differing lengths. "varlen (variable-length) sequence functionality"
- VBench: A benchmark suite for evaluating video generation across multiple dimensions. "VBench"
- ViCLIP: A video-LLM used to compute semantic alignment between prompts and generated clips. "ViCLIP"
- Wan2.2: A DiT-based video diffusion model serving as the base architecture and baseline. "Wan2.2"
- Window Cross-Attention: A mechanism that restricts text-video attention to the relevant global and per-shot prompts for each shot. "Window Cross-Attention"
Collections
Sign up for free to add this paper to one or more collections.

