OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Abstract: Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces OneStory, a new AI system that can create long, multi-shot videos that tell a clear, consistent story. Instead of making just one continuous clip, OneStory makes a sequence of shorter clips (called “shots”) that feel connected—keeping the same characters, settings, and storyline even when the camera angle or scene changes.
Key Questions the Paper Tries to Answer
- How can we make multi-shot videos that stay consistent across different scenes and camera angles?
- How can an AI remember important details (like a character’s face or the room’s layout) across many shots without forgetting them?
- How can we make this video-making process efficient and work with existing powerful video models?
How OneStory Works (Methods in Simple Terms)
Think of making a video like writing a story one chapter at a time. Each “shot” is a chapter. To keep the story consistent, the AI needs good memory and a smart way to use it.
Here are the main ideas, explained with everyday examples:
- Autoregressive next-shot generation: The model creates one shot at a time, using everything it knows from earlier shots. It’s like continuing a story—each new chapter looks back at previous chapters to keep the plot and characters consistent.
- Memory bank of frames: As it goes, the model stores important frames (images from past shots) in a “memory bank.” This is like keeping a photo album of key moments to remember who’s who and where things are.
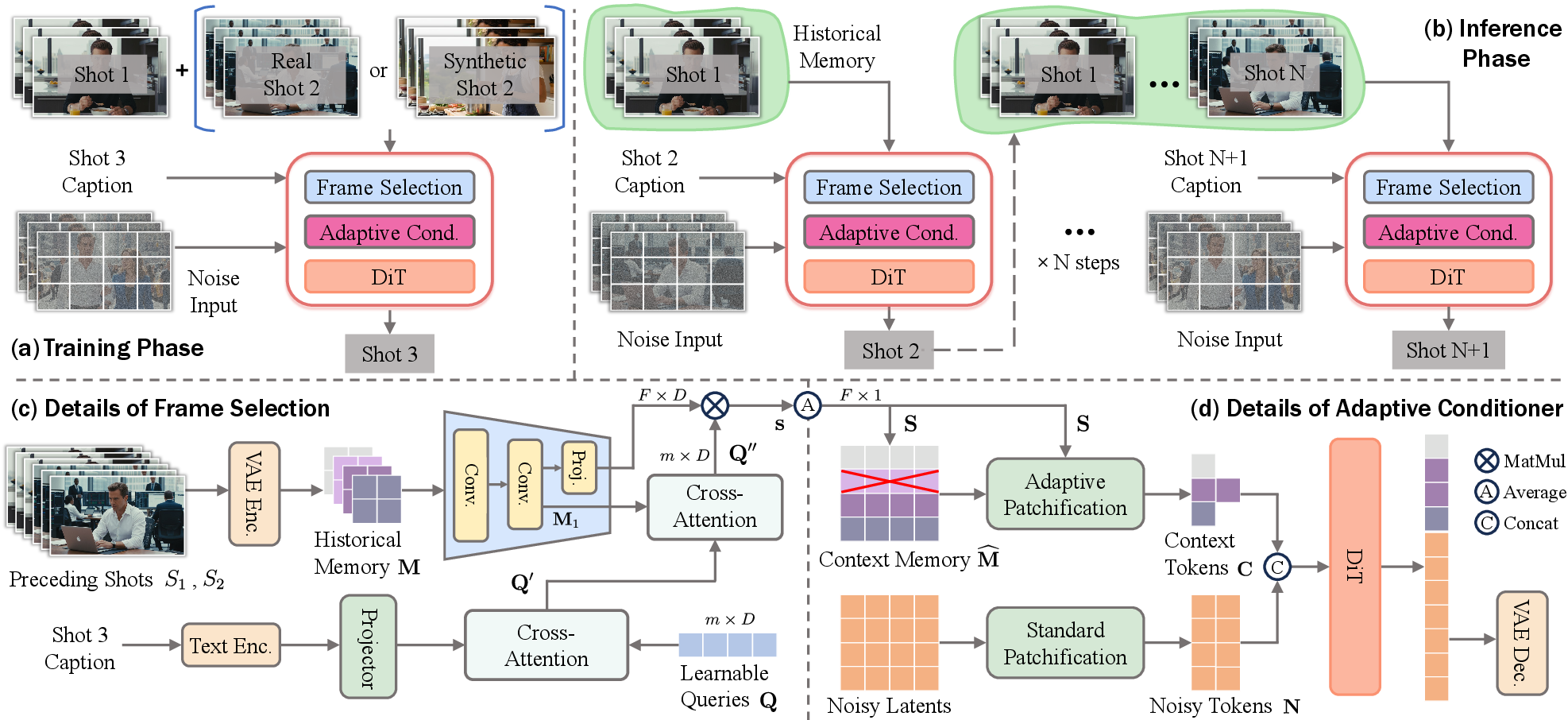
- Frame Selection (picking the right photos): Not all past frames are equally useful. OneStory has a module that looks at the current shot’s caption (description) and picks the most relevant frames from the memory bank. For example, if the next shot returns to the main character, it will pull frames where that character is clearly visible.
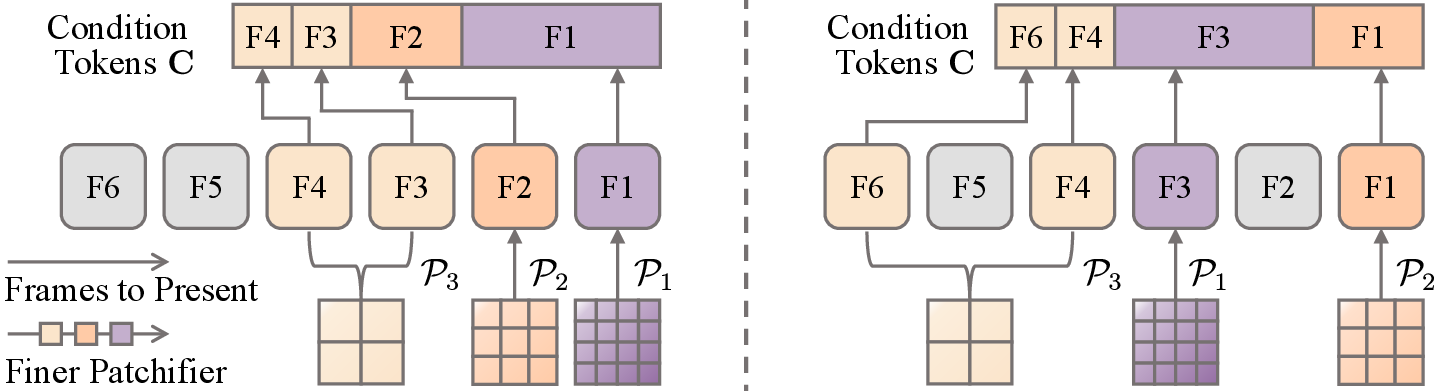
- Adaptive Conditioner (compressing the memory smartly): Even after picking good frames, feeding them all into the model would be slow. So OneStory “patchifies” them—breaks frames into small pieces and compresses them smartly. More important frames get finer, detailed patches; less important ones get coarser patches. Imagine shrinking photos into stickers: important photos stay high-quality; less important ones get smaller stickers.
- Direct conditioning: The compressed “context” (those patches) is directly mixed into the video generator’s input. This lets the model pay attention to both the noisy video it’s creating and the helpful memory at the same time—like having notes right next to your draft while writing.
- Using strong existing models: OneStory is fine-tuned on top of a powerful image-to-video (I2V) model. That means it benefits from high-quality visuals while learning to handle multi-shot storytelling.
- A new dataset that feels like real stories: The authors built a dataset of about 60,000 multi-shot videos. Each shot has captions that reference previous shots (for example, “the same man now stands by the window”), which helps the model learn realistic storytelling patterns without needing one huge global script.
- Training strategies (like using training wheels):
- Shot inflation: Many videos had only two shots, which makes training uneven. So they “inflate” some into three shots by inserting a related or augmented shot. This balances training and makes the model more stable.
- Decoupled conditioning: Early on, the frame selector might pick bad frames. So the model first trains using simple, uniformly sampled frames as “training wheels” and later switches to the smart selector.
Main Findings and Why They Matter
- Better consistency across shots: OneStory keeps characters and environments consistent even when they reappear after being off-screen or when scenes change. It beats several strong baselines on metrics like:
- Character consistency (same people look the same across shots)
- Environment consistency (backgrounds and rooms stay consistent)
- Semantic alignment (shots match their captions well)
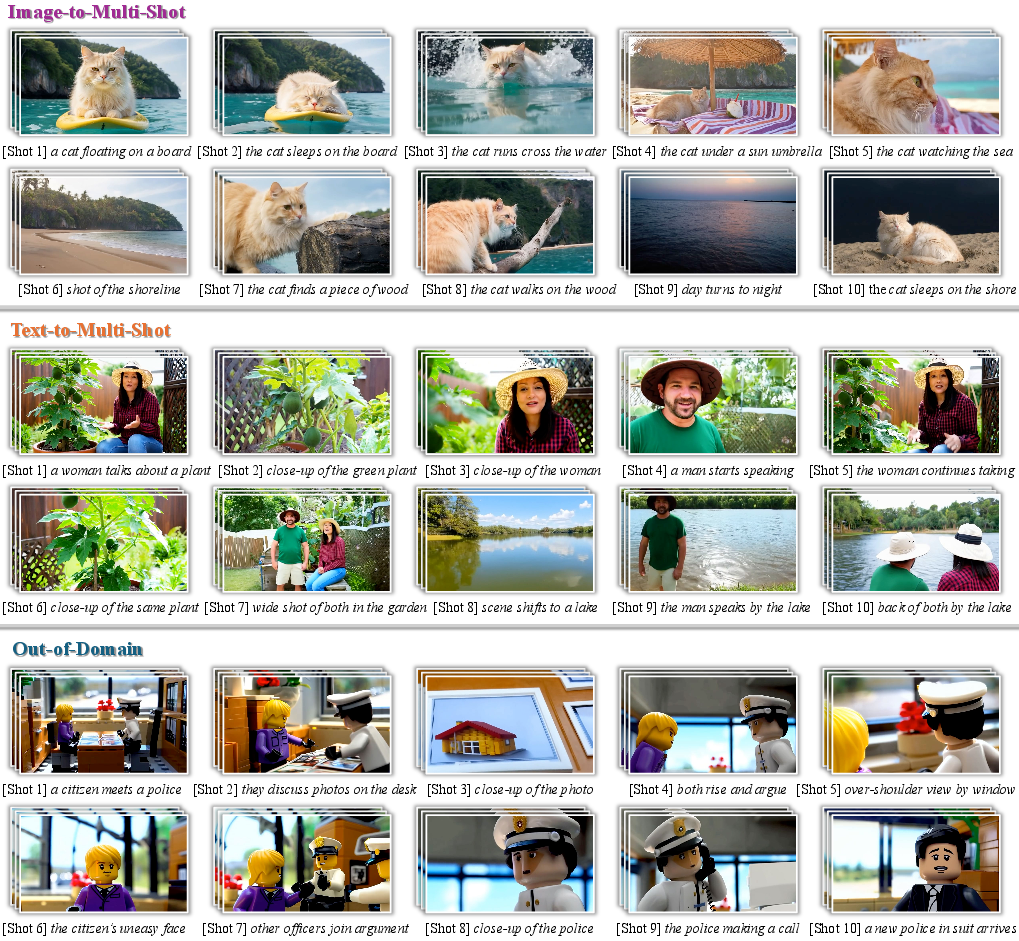
- Works for both text and image starting points:
- Text-to-multi-shot: Start with a description and get a coherent video made of multiple shots.
- Image-to-multi-shot: Start with an image (like your main character) and generate the following shots consistently.
- Handles complex storytelling:
- Reappearing characters without mixing identities
- Zooming in on small details while keeping them accurate
- Human–object interactions (like someone folding a tent or interacting with a car) that continue logically in the next shot
- Efficient and scalable: By compressing memory smartly, OneStory keeps computational costs reasonable while still using global context (not just the most recent shots).
In short, OneStory makes minute-long, 10-shot videos with strong visual quality and narrative coherence and sets a new standard among existing methods.
Implications and Potential Impact
- Creative tools: Filmmakers, animators, and content creators could use OneStory to quickly prototype scenes, create storyboards, or generate long-form videos from scripts and images.
- Education and training: It could help make consistent instructional videos that show step-by-step processes across multiple scenes.
- Entertainment and advertising: Brands and studios could produce more coherent narrative ads or short films automatically.
- Research direction: The idea of “adaptive memory” for long sequences could inspire better AI systems in other areas, like long conversations, comics generation, or interactive storytelling.
Note: As with any powerful generative tool, it’s important to consider ethical use—like preventing misuse for deepfakes or misinformation—by adding safeguards and clear provenance.
Overall, OneStory shows that combining smart memory selection with efficient conditioning can make AI much better at telling consistent, engaging multi-shot video stories.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing or unresolved in the paper and suggest concrete directions for future work:
- Dataset scope and bias: The curated ~60K dataset is predominantly human-centric and contains mostly two-shot sequences (50K) with far fewer three-shot sequences (10K). It remains unclear how the model performs on non-human, animation, multi-object, or scene-centric narratives, or on more complex shot structures (e.g., 4–20 shots with varied durations and transitions).
- Long-horizon scaling: The method demonstrates 10-shot generation qualitatively but provides no quantitative analysis of coherence and failure rates beyond three-shot training. Systematic evaluation of error accumulation, identity drift, and environment persistence for 10–50+ shots is missing.
- Context memory capacity limits: Frame Selection selects top-K frames from an unbounded history, but scalability and performance as the number of prior shots grows are not characterized. How K_sel, memory size, and memory pruning strategies affect long-range recall and consistency over very long narratives is underexplored.
- Selector training and differentiability: The paper uses pseudo-labels (CLIP/DINOv2) to supervise frame relevance and a TopK selection, but the training stability and differentiability of the selection (e.g., use of straight-through, soft selection via Gumbel-Softmax, or attention pooling) are not described or analyzed.
- Pseudo-label reliability and bias: The relevance supervision derived from CLIP/DINOv2 may be noisy or biased (e.g., towards salient entities). There is no validation of pseudo-label accuracy against human annotations, nor analysis of how errors propagate to selection quality and generation consistency.
- Sensitivity to hyperparameters: The effects of key design hyperparameters (number of queries m, number of selected frames K_sel, number and kernel sizes of patchifiers L_p, token budgets N_c) on performance, compute, and stability are not comprehensively studied beyond a small context-token ablation.
- Importance-guided patchification trade-offs: The Adaptive Conditioner compresses context tokens via relevance-based patchifiers, but the trade-off curves between token budget, inference speed, and narrative coherence (especially for fine-grained identity and small-object details) are not quantified.
- Conditioning interference and gating: Condition injection concatenates context tokens with noise tokens, but potential interference with text tokens (and with each other) is not analyzed. The need for gating, cross-attention routing, or modulation (e.g., FiLM-like conditioning) is an open question.
- Robustness to noisy or contradictory captions: The method relies on referential shot-level captions, but robustness to inaccurate, contradictory, or underspecified narratives is not assessed. Stress tests with caption noise or conflicting references would clarify practical reliability.
- Handling multiple similar identities: Scenarios with multiple visually similar characters and subtle identity cues (e.g., twins, uniform attire) may challenge Frame Selection and coherence. There is no targeted evaluation or mitigation (e.g., identity embedding tracking or face recognition cues).
- Off-screen persistence over long gaps: The paper highlights reappearance but does not measure identity/environment persistence when an entity remains off-screen across many intervening shots. Quantifying “off-screen memory” retention and retrieval is needed.
- Shot boundary and transition diversity: The dataset uses hard shot boundaries detected by TransNetV2. Performance on softer transitions (e.g., cross-dissolves, L-cuts/J-cuts, match cuts), montage, and variable shot lengths/durations is not explored.
- Camera and action controllability: Beyond captions, the method does not provide explicit control signals for camera motion, lens effects, blocking, or precise action timing. Mechanisms for structured control (e.g., shot types, camera paths, beat timing) are left open.
- Planner integration: The approach eschews a global script, but integration with high-level story planners, beat/scene graphs, or hierarchical outline-to-shot generation (and their benefits/limitations vs. purely referential captions) is unexplored.
- Generalization to out-of-domain content: Claims of out-of-domain generalization are qualitative; there is no quantitative evaluation on non-human, wildlife, vehicles, indoor/outdoor diversity, animation, or stylized domains.
- Fairness and breadth of baseline comparisons: Baselines include Mask2DiT, keyframe+I2V, and edit-and-extend, but do not cover other recent long-context paradigms (e.g., LCT, MoGA, HoloCine). A broader, standardized benchmark comparison is needed.
- Metric validity for narrative coherence: The use of DINOv2 similarities and ViCLIP alignment may not fully capture narrative coherence (e.g., continuity of plot, causal progression). Human evaluation protocols or dedicated benchmarks (e.g., ShotBench/CineTechBench) are not reported.
- Safety and identity considerations: Persistence and realistic synthesis can amplify risks (e.g., deepfakes, unintentional identity replication). The paper’s keyword filtering does not address generation-time safeguards, identity consent, or content integrity checks.
- Computation and efficiency characterization: The paper does not report training/inference throughput, memory footprint, or latency impacts of the Adaptive Conditioner at different token budgets. Practical deployment constraints (e.g., for minute-scale or higher-resolution videos) remain unclear.
- Resolution and aspect ratio scaling: All videos are center-cropped to 480×832. Behavior at higher resolutions (e.g., 1080p/4K), variable aspect ratios, and detailed texture preservation with adaptive memory is not evaluated.
- Error propagation and recovery: As an autoregressive next-shot model, errors can compound. Strategies for recovery (e.g., memory re-weighting, corrective edits, or reconditioning from user-supplied frames) are not discussed.
- Editability and interactive workflows: Post-generation editing of earlier shots, interactive refinement of memory (e.g., pinning key frames), or user-in-the-loop frame selection/patchification are not supported or explored.
- Reproducibility and data release: The paper does not state whether the curated dataset, frame relevance labels, or code/model checkpoints will be released. Without this, reproducibility and adoption are limited.
- Formalizing invariants vs. evolutions: The method implicitly handles what should remain invariant (identity, layout) vs. what should change (camera, actions), but does not formalize or enforce these constraints (e.g., via explicit consistency losses or disentangled representations).
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be built on top of OneStory’s next-shot generation, Frame Selection, and Adaptive Conditioner modules, leveraging existing pretrained I2V models and current creative toolchains.
- Bold: Film/TV previsualization and storyboarding
- Sectors: media and entertainment, software
- What it does: Rapidly generates multi-shot previz sequences from shot-by-shot prompts or a starter image; preserves character/environment continuity across discontinuous shots.
- Tools/products/workflows: “OneStory Studio” plugin for Premiere/DaVinci/Blender; shot-by-shot caption editor; memory bank manager for identity continuity; export to EDL/XML for editors.
- Assumptions/dependencies: Access to a high-fidelity I2V backbone (e.g., Wan-class models), GPU inference, rights to reference material, human-in-the-loop for creative control.
- Bold: Marketing concept videos and A/B testing
- Sectors: advertising, commerce
- What it does: Produces multiple minute-scale narrative variants for the same product brief (different angles, reappearances, compositions), enabling fast A/B concept testing.
- Tools/products/workflows: “Multi-shot Ad Generator” SaaS; prompt template library; brand asset memory banks (logos, mascots).
- Assumptions/dependencies: Brand safety filters, watermarking, QA review; reliable identity persistence (mascots/actors); licensing for model and assets.
- Bold: Social media storytelling assistant
- Sectors: consumer apps, creator economy
- What it does: Converts short scripts or reference photos into coherent multi-shot stories (travel recaps, event highlights) with consistent identities across shots.
- Tools/products/workflows: Mobile app with shot-level captions; auto-caption rewrites to referential form; quick publishing workflows (vertical aspect ratios, music sync).
- Assumptions/dependencies: Cloud inference or on-device acceleration; content moderation; user-friendly shot captioning UX.
- Bold: E-learning micro-lessons and procedural demos
- Sectors: education, enterprise software
- What it does: Generates multi-step tutorials (e.g., “zoom into part X,” “show the next interaction”), maintaining object continuity and scene layout across steps.
- Tools/products/workflows: LMS integration; “Narrative Consistency Checker” derived from OneStory’s metrics; template-based lesson generator.
- Assumptions/dependencies: Accurate prompts and subject grounding; instructor review for correctness; legal clarity on generated instructional content.
- Bold: Game cutscene prototyping
- Sectors: gaming, creative tools
- What it does: Produces narrative drafts of cutscenes from shot-level briefs without full 3D pipelines; preserves character identities across camera and setting changes.
- Tools/products/workflows: Engine-agnostic previz generator; import to Unreal/Unity as storyboard videos; shot continuity memory curated per character.
- Assumptions/dependencies: Reference concept art; IP rights management; integration for iteration loops with designers.
- Bold: Corporate training and safety walkthroughs
- Sectors: industrials, energy, manufacturing
- What it does: Creates consistent, stepwise scenario videos (e.g., safety procedures, equipment operation) with zoom-ins on relevant parts, ensuring environment continuity.
- Tools/products/workflows: Shot script templates for standard operating procedures; review dashboard; localization pipeline for captions.
- Assumptions/dependencies: Domain review for accuracy; safety/regulatory compliance; controlled deployment in internal LMS.
- Bold: Product onboarding and UI walkthroughs
- Sectors: software, fintech
- What it does: Multi-shot explainers that maintain UI element continuity across steps, zooming into specific controls while keeping background context stable.
- Tools/products/workflows: “UI-to-video” generator from screenshots; referential caption rewrites; versioning for product updates.
- Assumptions/dependencies: Up-to-date UI assets; privacy-safe mock data; legal review for claims.
- Bold: Academic benchmarks and tooling for MSV research
- Sectors: academia, open-source
- What it does: Uses OneStory’s curated 60K dataset and narrative metrics (character/environment consistency, semantic alignment) to evaluate MSV systems and train new variants.
- Tools/products/workflows: Shot-level caption datasets; evaluation suite; ablation-ready training scripts (shot inflation, decoupled conditioning curricula).
- Assumptions/dependencies: Dataset licensing for research use; reproducible baselines; compute availability.
- Bold: Synthetic video data for multi-shot understanding tasks
- Sectors: academia, robotics
- What it does: Generates controlled sequences for studying reappearance, human–object interactions, zoom-in localization; augments training for video understanding benchmarks.
- Tools/products/workflows: Scenario generator with controllable identities and scene variations; annotation via existing detectors/segmenters (YOLO, DINOv2).
- Assumptions/dependencies: Careful domain-gap analysis; synthetic-to-real transfer validation; ethical data use.
- Bold: Editor-integrated “next-shot” video co-pilot
- Sectors: software, creator tools
- What it does: Suggests and renders the next shot based on prior timeline clips and a text prompt; maintains continuity via memory bank conditioning.
- Tools/products/workflows: NLE extension panels; timeline-aware memory ingestion; quick iteration loop (render, review, revise).
- Assumptions/dependencies: Stable APIs for NLEs; compute budgeting per shot; user governance and undo/redo support.
Long-Term Applications
The following applications need further research, scaling, integration, or validation (e.g., broader domain generalization, audio/dialog support, provenance, cost/latency improvements).
- Bold: End-to-end virtual production (script-to-scene-to-cut)
- Sectors: media and entertainment, software
- What it could do: Automatic camera planning, shot composition, and continuity management across entire scenes; integrate with asset libraries and motion capture.
- Tools/products/workflows: “AI Director” that turns scripts into coherent multi-shot sequences with blocking and camera moves; tight integration with DCC tools and game engines.
- Assumptions/dependencies: High-fidelity controllability (camera grammar, blocking), cross-modal audio/dialog generation, production-grade QC pipelines.
- Bold: Interactive narrative engines for personalized stories
- Sectors: consumer apps, education, gaming
- What it could do: Real-time next-shot generation that adapts to user input, assessment scores, or gameplay states; maintains identity and environment continuity at runtime.
- Tools/products/workflows: Low-latency streaming inference; stateful memory across sessions; adaptive captioning and content safety gates.
- Assumptions/dependencies: Fast inference on edge/cloud; robust controllability; safety and personalization policies.
- Bold: Knowledge-grounded journalism and explainer videos
- Sectors: media, policy
- What it could do: Script-to-multi-shot videos grounded in verified sources, with automated continuity, zoom-in to relevant facts, and narrative adherence.
- Tools/products/workflows: Retrieval-augmented captioning; fact-checking and citation overlays; provenance and watermarking by default.
- Assumptions/dependencies: Trusted knowledge bases; strong fact-checking; regulatory compliance and clear labeling of AI-generated segments.
- Bold: Healthcare education and therapeutic storytelling
- Sectors: healthcare, education
- What it could do: Patient-specific explainer videos (procedures, rehab steps) and therapy narratives with controlled identity persistence and environment transitions.
- Tools/products/workflows: Clinician-in-the-loop templates; accessibility and localization; secure data handling.
- Assumptions/dependencies: Clinical validation, HIPAA/GDPR compliance, measurable learning outcomes, bias and sensitivity reviews.
- Bold: Robotics and embodied AI simulation curricula
- Sectors: robotics, autonomy
- What it could do: Generate long-horizon, multi-shot synthetic scenarios for planning and human–object interaction learning; bridge to sim2real with narrative continuity.
- Tools/products/workflows: Scenario libraries with controllable object states; cross-modality links to physics simulators; evaluation on planning tasks.
- Assumptions/dependencies: Physics fidelity, actionable labels, sim2real transfer, safety validation.
- Bold: Enterprise continuity editing and compliance automation
- Sectors: enterprise software, legal/compliance
- What it could do: Automatic continuity checks (identity, environment) across training or marketing videos; propose compliant next shots to fix inconsistencies.
- Tools/products/workflows: Continuity validators using OneStory-style metrics; revision assistant that regenerates next shots with constraints.
- Assumptions/dependencies: Policy definitions per enterprise; audit trails and provenance; human approval loops.
- Bold: Multi-episode IP generation with rights and identity banks
- Sectors: media, licensing
- What it could do: Maintain consistent characters across seasons/episodes; control appearance changes while preserving core identity.
- Tools/products/workflows: Identity memory banks; rights management (contracts, likeness approvals); episode-scale narrative planners.
- Assumptions/dependencies: Legal/IP frameworks, scalability to long-form content, robust identity persistence across diverse scenes.
- Bold: Real-time broadcast augmentation
- Sectors: live media, sports/entertainment
- What it could do: On-the-fly next-shot explainer inserts (e.g., zoom-ins, replays) with coherent visual context during live programming.
- Tools/products/workflows: Hardware acceleration; stream-aware memory conditioning; operator control surfaces.
- Assumptions/dependencies: Sub-second latency targets, reliability under load, broadcast compliance rules.
- Bold: Consumer-grade “storycam” devices and apps
- Sectors: consumer hardware/software
- What it could do: Capture a few frames and auto-generate multi-shot stories tailored to a user’s narrative intent (events, trips), handling reappearances and zooms.
- Tools/products/workflows: On-device inference chips; shot-caption UX; family-friendly content controls.
- Assumptions/dependencies: Efficient local models, battery/thermal limits, privacy-safe operation.
- Bold: Standardized provenance and watermarking for multi-shot AI video
- Sectors: policy, standards
- What it could do: End-to-end content provenance (C2PA-like) with shot-level metadata; detection tools in platforms; reporting dashboards for regulators.
- Tools/products/workflows: Watermark insertion APIs; “Synthetic Media Registry”; platform enforcement hooks.
- Assumptions/dependencies: Cross-industry standards adoption; model-level watermark robustness; interoperability with platforms and regulators.
Cross-cutting assumptions and dependencies
- Access to high-fidelity pretrained I2V backbones and compatible licenses; potential dependence on large-scale compute for fine-tuning/inference.
- Shot-level caption quality and referential flow are crucial; weak or ambiguous prompts reduce narrative adherence.
- Safety, fairness, and rights management: human-centric training may encode biases; identity/likeness persistence requires legal approvals and clear labeling of AI-generated content.
- Provenance and watermarking for policy compliance and platform trust; content moderation integrated into generation pipelines.
- Operational constraints: inference latency/costs, storage and memory management for global context, integration with existing creative/software stacks.
- Generalization limits: current training is primarily human-centric; out-of-domain scenes may require further fine-tuning, data curation, or domain adapters.
Glossary
- 3D VAE encoder: A variational autoencoder operating on spatio-temporal volumes to compress video frames into latent features. "where is a 3D VAE encoder~\citep{polyak2024movie,wan2025wan} that maps each shot into latent features"
- AdamW: An optimizer that decouples weight decay from gradient-based updates, improving training stability. "We optimize using AdamW with a learning rate of 0.0005 and weight decay of 0.01."
- Adaptive Conditioner: A module that dynamically compresses selected context frames and injects them into the generator for efficient conditioning. "an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning."
- Aesthetic quality: A metric assessing visual appeal and style of generated shots. "Shot-level quality follows single-shot metrics..., including subject consistency, background consistency, aesthetic quality, and dynamic degree."
- Attention masks: Structured masks guiding transformer attention to align modalities or time steps. "MaskDiT modifies attention masks to enforce caption–shot alignment"
- Autoregressive: A generation approach that produces outputs sequentially, conditioning each step on previous results. "enabling autoregressive shot synthesis"
- Caption-to-shot attention masks: Attention constraints linking specific caption segments to corresponding shots. "by applying caption-to-shot attention masks"
- Center-cropped: A preprocessing step that crops frames around the center to a fixed resolution. "All videos are center-cropped to while preserving aspect ratio."
- Character Consistency: A metric measuring identity persistence of characters across shots. "Character Consistency computes DINOv2 similarity between YOLO segmented persons across shots"
- CLIP: A vision-LLM used for cross-modal similarity and filtering. "i.e, CLIP~\citep{radford2021learning}"
- Condition injection: The process of inserting context tokens into the model’s token stream for joint attention with noise tokens. "Condition injection."
- Context tokens: Compressed representations of selected frames used to condition the generator. "We concatenate the context tokens with along the token dimension to form the DiT input"
- Cross-shot context: Visual and semantic information carried across discontinuous shots to maintain coherence. "restrict the cross-shot context to a single image"
- Decoupled conditioning: A training strategy that temporarily separates frame selection from conditioning to stabilize learning. "Decoupled conditioning."
- DiT: Diffusion Transformers; transformer-based diffusion models for unified spatial-temporal generation. "to form the DiT~\citep{peebles2023scalable} input"
- DINOv2: A self-supervised vision model used for feature similarity and pseudo-labeling. "DINOv2~\citep{oquab2023dinov2}"
- Diffusion process: The iterative denoising procedure underpinning diffusion models. "in the diffusion process~\citep{ho2020denoising}"
- Diffusion Transformers: Transformer architectures tailored for diffusion-based generation. "Recent advances in diffusion transformers~\citep{peebles2023scalable} have greatly advanced video generation"
- Dynamic degree: A metric quantifying the amount and quality of motion in generated clips. "including subject consistency, background consistency, aesthetic quality, and dynamic degree."
- Edit-and-extend: A baseline approach that edits the last frame and extends it into a shot via I2V synthesis. "Edit-and-extend treats MSV as next-shot generation"
- Environment Consistency: A metric measuring persistence of environment and background across shots. "Environment Consistency measures DINOv2 similarity between segmented background regions"
- Feature-based filters: Automated quality filters leveraging pretrained feature extractors to remove poor or irrelevant samples. "Then, we use feature-based filters, i.e, CLIP and SigLIP2, to eliminate videos with completely irrelevant transitions"
- Fixed-window attention: Attention computed over a bounded temporal window of shots, leading to context truncation. "Fixed-window attention extends attention to multiple shots within a fixed temporal window."
- Frame Selection module: A component that scores and selects semantically relevant frames from prior shots. "We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory"
- I2I model: Image-to-image model used to transfer and edit frames before video synthesis. "We use FLUX~\citep{flux} as the I2I model"
- Image-to-multi-shot (I2MSV): Generating multi-shot videos conditioned on an initial image plus per-shot captions. "Image-to-multi-shot (I2MSV)"
- Image-to-video (I2V): Models that animate a static image into a video sequence. "pretrained image-to-video (I2V) models"
- Latent features: Compressed representations of video frames in the model’s latent space. "that maps each shot into latent features"
- Latent frame: A single time step represented in the latent space of the video encoder. "one latent frame as the unit of context token amount"
- Learnable query tokens: Trainable tokens used to attend to text and memory to compute relevance scores. "we introduce learnable query tokens "
- Long context tuning: Techniques to extend a model’s effective context length for long-range dependencies. "or direct long context tuning"
- MaskDiT: A baseline method using masked alignment between captions and shots within DiT. "MaskDiT"
- Memory bank: A storage of past shot frames/features maintained during autoregressive generation. "it maintains a memory bank of past shots and generates multi-shot videos autoregressively."
- MMDiT: A DiT variant supporting multimodal inputs and multi-shot encoding. "LCT augments MMDiT~\citep{esser2024scaling} to encode multi-shot structure."
- Multi-shot video generation (MSV): Generating sequences of multiple shots that form a coherent narrative. "multi-shot video generation (MSV)"
- Next-shot generation: Reformulating MSV to predict the upcoming shot conditioned on prior shots and current caption. "we reformulate MSV as a next-shot generation task"
- Noise tokens: Tokens representing noisy inputs at each diffusion step for the current shot. "denote the noise tokens of the current shot in the diffusion process"
- Patchification: Converting frame features into patch tokens via kernels to control context compression. "performs importance-guided patchification to generate compact context"
- Patchifiers: Operators with different kernel sizes that produce context tokens at varying compression levels. "We define a set of patchifiers "
- Progressive coupling scheme: A staged training approach that gradually couples selector-driven conditioning to stabilize optimization. "including unified three-shot training and a progressive coupling scheme"
- Referential captions: Shot-level captions that explicitly reference prior shots to preserve narrative continuity. "a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns"
- Semantic Alignment: A metric measuring how well generated shots match their captions. "Semantic Alignment quantifies the alignment between each generated shot and its caption using ViCLIP"
- Shot detection: Identifying shot boundaries in raw videos as part of data curation. "(i) Shot detection"
- Shot inflation: Augmenting two-shot sequences into three-shot ones to enable uniform training. "Shot inflation."
- SigLIP2: A vision-LLM used for filtering and relevance scoring. "SigLIP2~\citep{tschannen2025siglip}"
- Spatio-temporal reasoning: Understanding spatial and temporal relationships across discontinuous scenes. "spatio-temporal reasoning across discontinuous scenes"
- Text-to-multi-shot (T2MSV): Generating multi-shot videos from text prompts with per-shot captions. "Text-to-multi-shot (T2MSV)"
- Text-to-video (T2V): Models that synthesize videos directly from text prompts. "text-to-video (T2V) models"
- Top-K (top-): Selecting the K highest-scoring frames/features for conditioning. "the top- frames are selected from based on "
- TransNetV2: A deep model for fast and accurate shot transition detection. "We first apply TransNetV2~\citep{soucek2024transnet} to detect shot boundaries"
- Vision-LLM: Models that jointly process visual and textual inputs for tasks like captioning. "we use a vision-LLM~\citep{llama4,bai2025qwen2,yuan2025tarsier2} for shot-level captioning"
- ViCLIP: A video–text model used to compute semantic alignment between shots and captions. "using ViCLIP~\citep{wanginternvid}"
- YOLO: A real-time object detector used for person segmentation in consistency metrics. "YOLO~\citep{ultralytics2021yolov5} segmented persons"
- Zoom-in effects: Shot transitions that require localizing fine details when moving from wide to close-up views. "Zoom-in effects."
- Weight decay: Regularization technique applied during optimization to prevent overfitting. "weight decay of 0.01."
Collections
Sign up for free to add this paper to one or more collections.

