- The paper demonstrates that instruction embeddings effectively filter out hallucinated visual elements by assigning lower confidence to non-existent objects compared to traditional image embeddings.
- The InsLen score fuses calibrated local scores with context consistency, achieving notable AUROC and AUPR improvements across benchmarks like MSCOCO, Objects365, POPE, and CLEVR.
- The approach provides a plug-and-play, resource-efficient solution that generalizes across various MLLM architectures to enhance generative reliability and safety in practical applications.
Instruction Lens Score: Plug-and-Play Object Hallucination Detection for MLLMs
Object Hallucination in Multimodal LLMs
Object hallucination (OH) persists as a major reliability obstacle in multimodal LLMs (MLLMs), which exhibit spurious responses incorporating nonexistent objects. This phenomenon is prevalent even in advanced architectures like LLaVA, Qwen3-VL, and mPLUG-Owl3, severely restricting deployment in safety-critical or industrial contexts. Prior OH detection schemes have largely focused on vision-derived signals—such as patch-based embeddings or attention—often requiring auxiliary models, leading to computational inefficiency and suboptimal separation between real and hallucinated objects.
Instruction Embeddings as Robust Visual Filters
The paper "Instruction Lens Score: Your Instruction Contributes a Powerful Object Hallucination Detector for Multimodal LLMs" (2605.12258) establishes a novel perspective: instruction embeddings within MLLMs inherently encode visual semantics and systematically suppress misleading information propagated by erroneous visual embeddings. Leveraging the Logit Lens technique to probe the intermediate embeddings, the study demonstrates that instruction embeddings consistently yield higher confidence for image-grounded concepts, while reducing confidence in hallucinated objects.
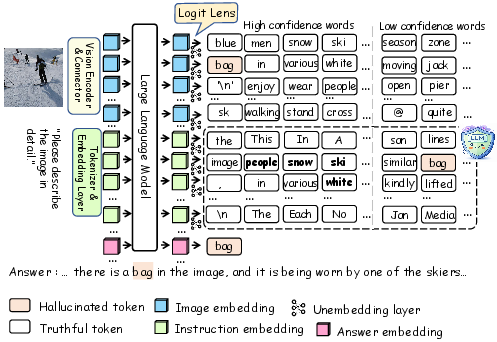
Figure 1: Instruction embeddings filter misleading visual signals, assigning confidence to image-grounded concepts and suppressing hallucinated objects.
Methodology: The Instruction Lens Score (InsLen)
Building on the filtering capacity of instruction embeddings, the authors propose the Instruction Lens Score (InsLen), a compositional plug-and-play detector requiring no auxiliary models or training. InsLen combines two complementary components:
- Calibrated Local Score: This calibrates vision-based scores (e.g., Local Similarity Score) using the 'Calibration Confidence' derived from instruction embeddings, suppressing spuriously high vision-based confidence for hallucinated tokens.
- Context Consistency Score: Aggregates top instruction embeddings that assign high confidence to an object token, measuring global semantic alignment between generated object embedding and instruction embedding aggregates.
The overall InsLen score fuses both aspects, facilitating robust discrimination of hallucinated tokens that overlap with visual patterns of real objects.
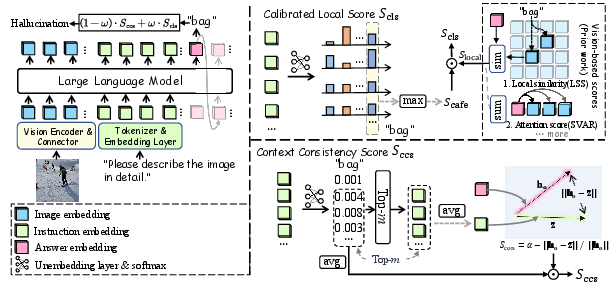
Figure 2: Overview of InsLen, fusing Calibrated Local Score and Context Consistency Score for object hallucination detection.
Empirical Evaluation
Extensive quantitative studies are provided across MSCOCO, Objects365, POPE, and CLEVR benchmarks with a range of MLLM architectures. InsLen consistently outperforms baselines—GLSIM, SVAR, Internal Confidence, NLL, Entropy, and EAZY—in AUROC and AUPR metrics:
- On Qwen3-VL, InsLen surpasses GLSIM on MSCOCO by 7.7% AUROC and 3.29% AUPR.
- On Objects365, InsLen outperforms SVAR by 6.6% AUROC and 1.49% AUPR.
- On POPE (object-probing binary classification), InsLen leads by up to 13.81% AUROC for LLaVA-1.5.
- On CLEVR (attribute and relational hallucinations), InsLen maintains superior results, achieving AUROC of 77.72% versus SVAR’s 73.01% on Qwen3-VL.
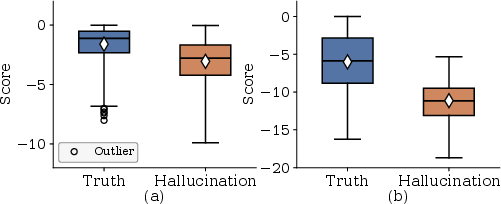
Figure 3: Confidence score distributions for hallucinated and real objects are more separable when derived from instruction embeddings.
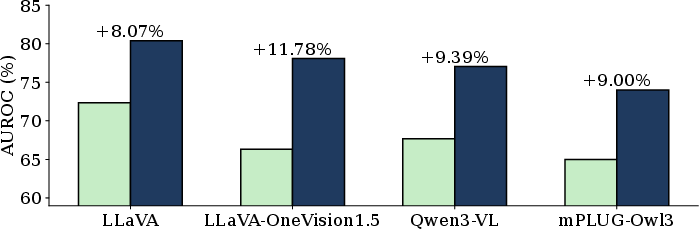
Figure 4: Internal confidence from instruction embeddings (blue) exceeds that from image embeddings (green) across MLLMs on MSCOCO.
Ablation studies reveal the necessity of both InsLen components and emphasize the efficacy of Calibration Confidence in correcting overconfident vision-based scores.
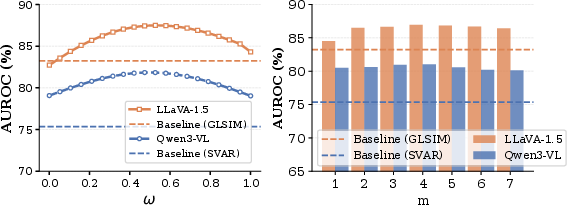
Figure 5: InsLen’s AUROC stability across hyperparameter omega and number m of instruction embeddings, maintaining performance above best baselines.
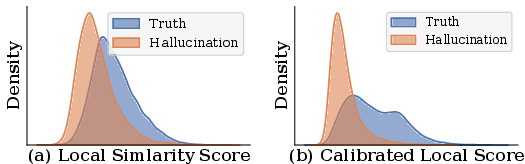
Figure 6: Calibration shifts the distribution of Local Similarity Score (LSS), increasing separation between real and hallucinated objects.
Instruction Embeddings Visualization and Model Generalization
Visualizations of instruction embeddings corroborate their semantic alignment with image content. Aggregated instruction embeddings from LLaVA-OneVision1.5 and Qwen3-VL show explicit mapping to visual concepts, validating their utility in object hallucination detection.

Figure 7: Top-vocabulary tokens projected from instruction embeddings reveal semantic alignment with visual concepts.

Figure 8: Instruction embeddings in LLaVA-1.5 reflect global image-related semantics.
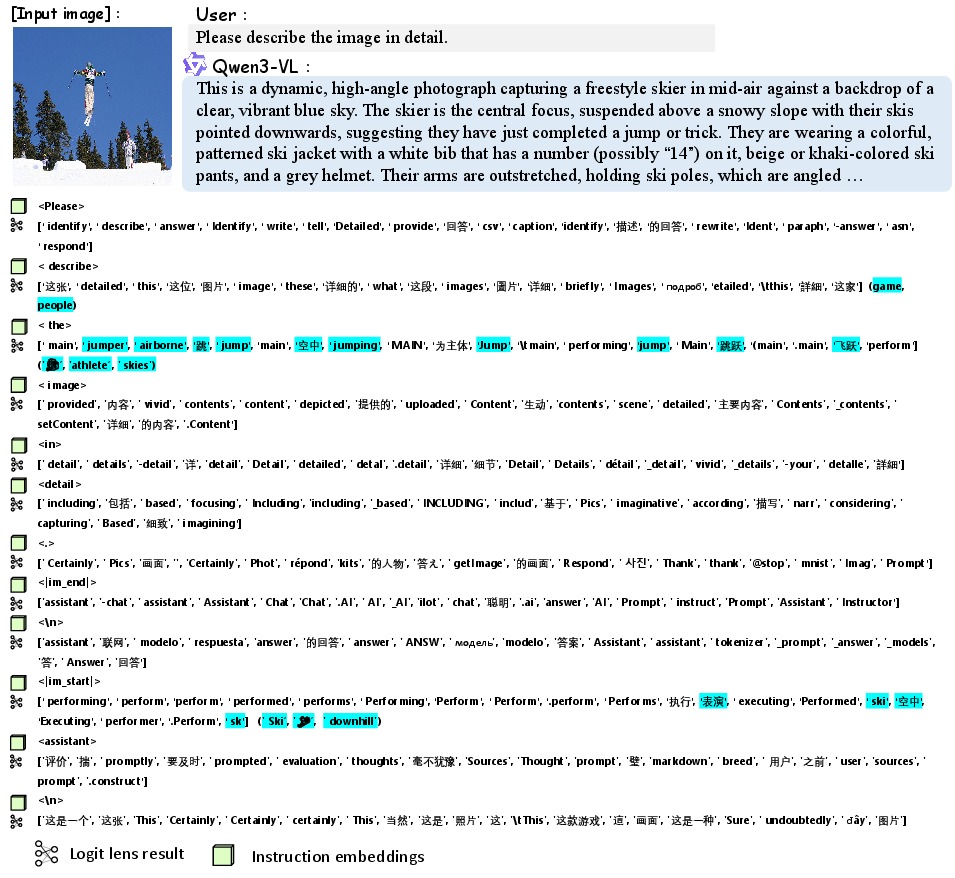
Figure 9: Qwen3-VL instruction embeddings encode visual object information directly relevant to input content.
Sensitivity analyses indicate robust performance across model sizes, decoder layers for embedding extraction, temperature parameters, prompt length, and aggregation strategies. InsLen exhibits minimal additional latency relative to answer generation and remains effective on post-trained MLLMs (RLHF, RLAIF-V).
Practical and Theoretical Implications
By demonstrating that instruction embeddings act as effective visual signal filters, the paper introduces a resource-efficient method for hallucination detection. The approach is applicable in inference-time contexts, does not require costly external resources, and generalizes across variants, architectures, and tasks. This insight addresses the weakness of vision-centric detectors and opens avenues for employing instruction-contextual embedding signals for control, evaluation, and mitigation in generative MLLMs.
Theoretically, the findings suggest that instruction tokens, through cross-modal attention, are unexpectedly informative for semantics grounding. Further research can be directed toward leveraging instruction embeddings for decoding interventions, preference alignment, and improving generative reliability.
Conclusion
The study systematically analyzes instruction token embeddings in MLLMs and illustrates their utility in suppressing misleading visual information—a critical factor in object hallucination detection. The plug-and-play InsLen score, integrating calibrated vision-based evidence and instruction-context consistency, exhibits robust and generalizable detection capabilities, consistently surpassing established baselines across benchmarks and architectures. This work highlights instruction embeddings as a valuable, underutilized signal for enhancing reliability in multimodal language generation, with implications for future interpretability, decoding control, and safety mechanisms in AI systems (2605.12258).

