- The paper proposes a closed-form joint scale optimization (CJSO) and decoupled scale search (DSS) method to significantly reduce NVFP4 quantization error in LLMs.
- It demonstrates that iterative alternation between analytical updates and discrete scale refinement enhances zero-shot and reasoning accuracy.
- The approach minimizes hardware-induced precision loss with no extra memory cost and generalizes across various microscaling regimes and model sizes.
SOAR: Scale Optimization for Accurate Reconstruction in NVFP4 Quantization
Introduction and Motivation
The proliferation of LLMs has intensified the demand for efficient quantization strategies that minimize memory and computation without degrading model fidelity. Traditional integer quantization (e.g., INT8/INT4) methods, while effective in reducing memory footprints, often fail to adequately preserve accuracy in the presence of the highly non-uniform, heavy-tailed weight distributions typical of LLMs. Recent advancements in microscaling floating-point formats, such as MXFP4 and NVFP4, address this limitation by providing block-wise floating-point scaling, offering superior adaptation to diverse tensor statistics and native hardware support on platforms like NVIDIA Blackwell.
However, even state-of-the-art NVFP4 quantization methods exhibit systematic deficiencies: their scaling factor selection mechanisms are typically rigid or restricted to shallow discrete search spaces, leading to suboptimal fits for the underlying weight statistics. This inflexibility, compounded by the coupling of quantization and dequantization scales due to hardware constraints, results in residual quantization errors that limit model performance (see the inadequacy of traditional scaling approaches in representing actual weight distributions).
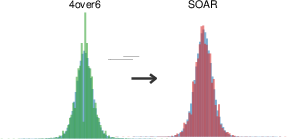
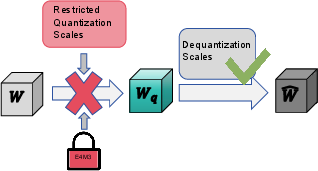
Figure 1: Comparison of weight distributions between conventional and SOAR-adapted scaling strategies, highlighting SOAR's superior adaptability to the true distribution.
The "SOAR: Scale Optimization for Accurate Reconstruction in NVFP4 Quantization" (2605.12245) work systematically addresses these deficiencies, introducing a rigorous optimization framework that jointly adapts global and block-wise scaling and further decouples the quantization and dequantization processes to minimize both quantization error and hardware-induced precision loss.
Methodological Framework
CJSO constitutes the analytical core of SOAR, formulating the determination of global (α) and block-wise (Δi) scaling factors as a joint optimization problem. Instead of relying on heuristic max-based scaling or coarse search, CJSO minimizes the reconstruction error ∥W−W^∥2 analytically, leveraging the fact that, under fixed FP4 assignments, the error becomes a quadratic function of scaling factors. This yields closed-form updates for α and each Δi by satisfying first-order optimality conditions, and allows iterative alternated optimization: FP4 assignments are recomputed after each scale update, driving the solution toward a local error minimum.
Decoupled Scale Search (DSS)
NVFP4 hardware mandates that block-wise dequantization scales (Δid) be E4M3-quantized, introducing non-negligible quantization error. Traditional approaches use identical scales for both quantization (weight-to-FP4 assignment) and dequantization (weight recovery), thereby propagating scale quantization inaccuracies throughout the entire process.
SOAR's DSS explicitly disentangles these two roles: the quantization-side scale (Δiq) is allowed to be high-precision, enabling optimal assignment of weights to FP4 levels; the dequantization-side scale (Δid) is hardware-constrained to nearby FP8-representable values. DSS then performs a joint discrete search over (Δiq,Δid) pairs for each block, selecting pairs that minimize local reconstruction error, thus mitigating both representation and scale-induced errors.
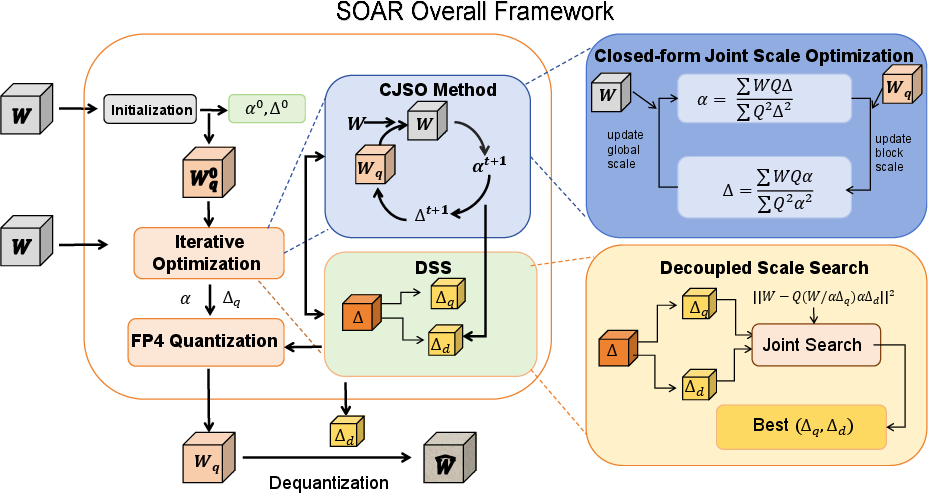
Figure 2: The SOAR framework, illustrating its iterative optimization process, the analytical update (CJSO), and the discrete search decoupling (DSS) that refines quantization and dequantization scales independently.
Iterative SOAR Framework
SOAR is built as an iterative alternation of CJSO and DSS stages. Each cycle comprises: (1) a closed-form update of global and block-wise scales under fixed weight assignments and (2) local search refinement of scale pairs, where DSS optimizes the assignment and quantization/dequantization scales for each block. These steps are repeated either for a fixed number of iterations or until convergence, efficiently driving the quantization solution into a high-fidelity regime.
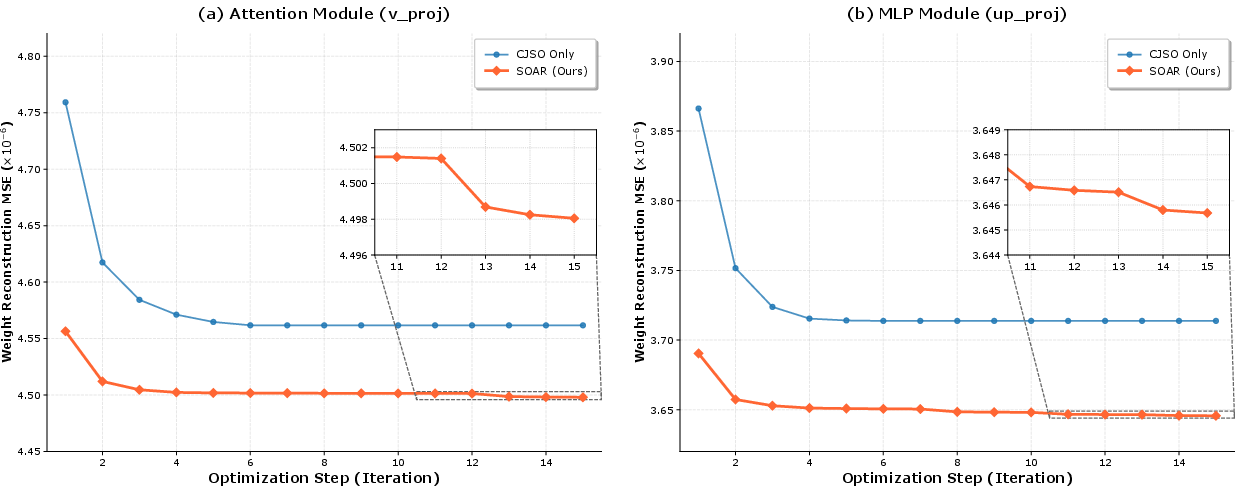
Figure 3: SOAR's convergence characteristics, demonstrating that the integration of both CJSO and DSS consistently achieves lower reconstruction MSE compared to CJSO in isolation.
Experimental Analysis
Zero-Shot and Reasoning Accuracy
SOAR demonstrates robust accuracy improvements over previous NVFP4 quantization baselines such as 4over6 and RaZeR on diverse LLM model sizes and architectures (LLaMA, Qwen, etc.). For example, on Qwen3-8B, SOAR yields an average zero-shot accuracy of 70.68, a +1.93 point improvement over the plain NVFP4 baseline and +0.56 over RaZeR. Similar gains are observed on reasoning benchmarks such as MMLU and GSM8K, indicating SOAR's effectiveness in preserving knowledge and logical competence under low-precision constraints.
Ablation and Generalization
Ablation results highlight the distinct and complementary contributions of CJSO and DSS. While CJSO alone provides substantial improvements by analytically adapting scales to block statistics, incorporating DSS yields further error reduction by precisely controlling quantization noise attributed to hardware constraints. Notably, when DSS is ported to other microscaling regimes (e.g., MXFP4), consistent accuracy improvements are observed, supporting the generality of SOAR's approach.
SOAR's improvements incur no increase in storage or inference-time costs: the Δq scales are used purely in the optimization phase and not required at runtime. The stored quantized format (FP4 weights + FP8 dequantization scale + FP32 global scale) remains identical to prior NVFP4 methods. Quantization time is competitive, with execution for modern billion-parameter models measured in minutes.
Implications and Future Directions
SOAR's analytical and architectural contributions provide several practical and theoretical implications:
- Enhanced Quantization Fidelity: By systematically minimizing both representation and hardware-induced scale errors, SOAR achieves high-accuracy quantization at 4-bit precision with no extra memory consumption or latency overhead, making it well-suited for efficient deployment on edge or data center hardware supporting NVFP4.
- Generalization Potential: The decoupled scale search mechanism is broadly applicable to other microscaling quantization formats or quantization-aware training scenarios, positioning SOAR as a foundation for further algorithm-hardware co-design.
- Synergy with Calibration-Aware Methods: Although calibration-free by design, SOAR is compatible with data-driven quantization frameworks (e.g., GPTQ), suggesting future research directions combining analytical scale optimization with calibration-data-induced channel weighting.
- Extension to Activation-Aware Objectives: Future developments may further integrate layerwise output distortion minimization using calibration activations as auxiliary objectives, enabling activation-aware scale optimization for even higher downstream task fidelity.
Conclusion
SOAR provides a mathematically principled and practically efficient framework for NVFP4 quantization, integrating closed-form analytical scaling and hardware-constrained scale search to systematically reduce quantization errors. The demonstrated generality across LLM architectures and compatibility with established PTQ frameworks underscores SOAR's utility both as a drop-in post-training solution and as a platform for future innovation in precision-efficient model deployment.