- The paper introduces MedTPE, a novel token-pair encoding technique that achieves lossless compression for clinical EHR data.
- It employs dependency-aware vocabulary replacement and self-supervised fine-tuning to reduce token lengths by 22.8%-32.4% without retraining core LLMs.
- Empirical evaluations demonstrate up to 62.5% reduction in inference latency while maintaining or improving prediction performance.
MedTPE: Tokenisation-Driven Lossless Compression for Clinical LLM Prediction
Context and Motivation
The growth of EHR-based clinical prediction using LLMs is hindered by prohibitively long token sequences resulting from serialisation of longitudinal, fine-grained medical records. Standard tokenisation algorithms (BPE, WordPiece, SentencePiece) excessively fragment specialized medical terms, yielding inefficient and context-window–saturating sequences that drive up compute costs and inference latency. Prior approaches, such as domain-specific vocabulary retraining, removal-based prompt compression, and inference-time merge methods, fundamentally trade off compatibility, reliability, or losslessness. There is an unsolved requirement for an efficient, lossless compression strategy for clinical EHR text that integrates with pre-trained LLMs without imposing additional architectural or computational overhead.
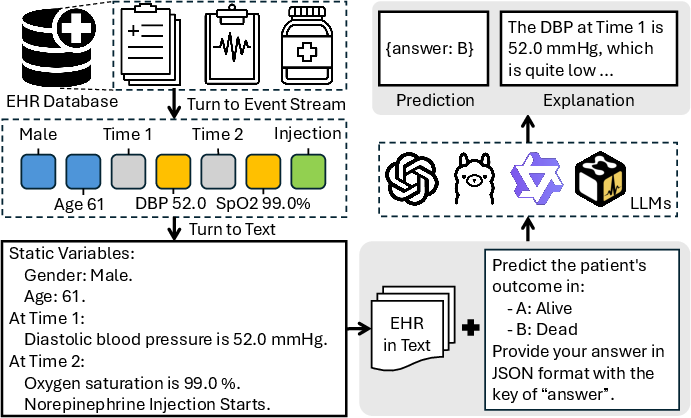
Figure 1: Illustration of the LLM-based clinical prediction pipeline, highlighting the transformation of event streams into natural language sequences for LLM input.
MedTPE: Methodology Overview
MedTPE (Medical Token-Pair Encoding) presents an integrated, three-stage pipeline for targeted, lossless token-sequence compression tailored to the clinical domain:
- Medical Token-Pair Discovery: Frequent contiguous token pairs (n-grams, primarily bigrams) are mined from a large-scale EHR corpus, identifying semantically coherent and computationally redundant patterns.
- Dependency-Aware Replacement: Approximately the M most frequent composite tokens (typically 3% of vocab) are injected into the LLM vocabulary by evicting the least frequent, dependence-free general language tokens. Crucially, all dependent sub-tokens required for lossless detokenisation are preserved, ensuring no disruption to the reversible encoding pathway.
- Self-Supervised Fine-Tuning (SSFT): Only the embeddings for new TPE tokens are fine-tuned via self-supervision (pseudo-labelled by the frozen pre-trained LLM); the bulk of the LLM remains untouched, enabling rapid, parameter-efficient adaptation.
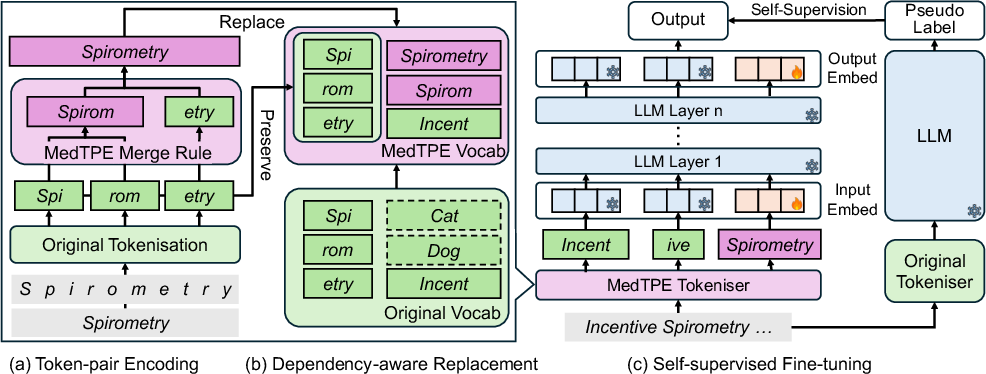
Figure 2: MedTPE workflow: (a) corpus-driven discovery of high-value token pairs, (b) vocabulary injection with call-graph–aware replacement, (c) embedding alignment via SSFT while freezing core LLM parameters.
This architecture maintains the original tokenisation complexity (O(n)), preserves the model/vocabulary size, and introduces negligible parameter count increases (0.5–1.0%). The compositional structure guarantees reversible, lossless compression.
Experimental Evaluation
Comprehensive empirical analysis is performed on canonical ICU and longitudinal EHR datasets (MIMIC-IV, EHRSHOT), across multiple backbone LLMs (Llama3, Qwen2.5/3, Gemma2, Meditron3) and both binary and multilabel classification tasks, including ICU mortality, phenotyping, and long-range readmission prediction.
In MIMIC-IV and EHRSHOT experiments, MedTPE attains:
- Token length reduction: 22.8%–32.4%
- Inference latency reduction: 33.9%–62.5%
- Maintained or increased predictive performance (F1 scores), with improved format compliance (FCR)
- Robustness across context length scaling and test-time inference strategies
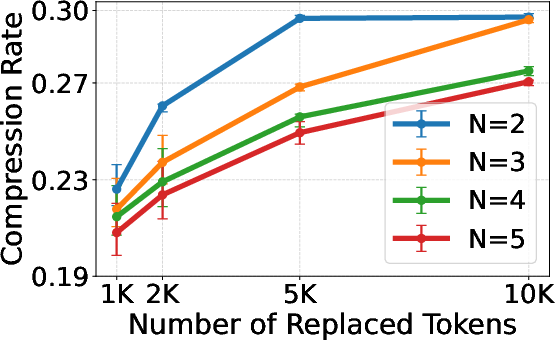
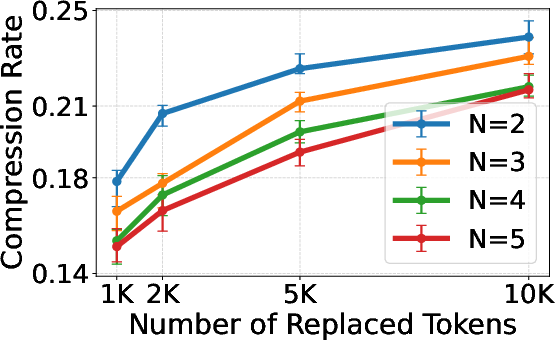
Figure 3: Distribution of token sequence lengths in raw MIMIC-IV EHRs, highlighting the need for compression.
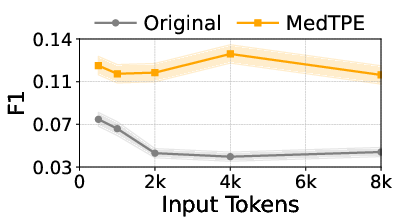
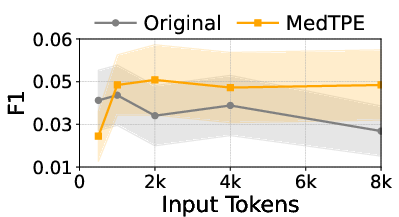
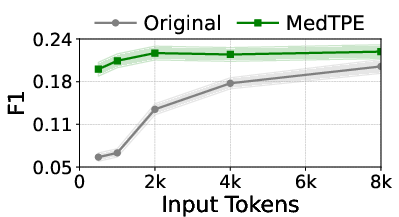
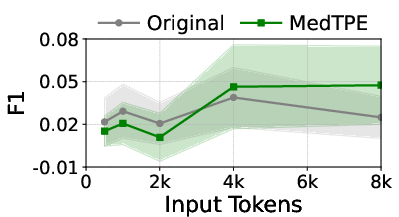
Figure 4: The impact of MedTPE on token sequence length and prediction F1 for Llama3-1B on MIMIC-IV.
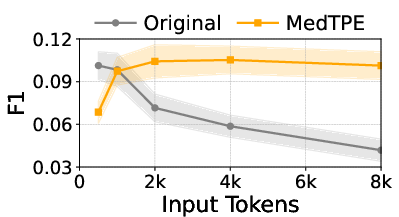
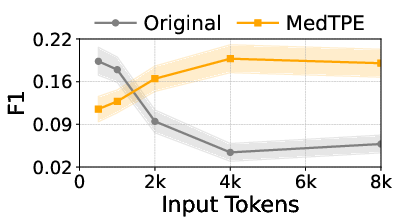
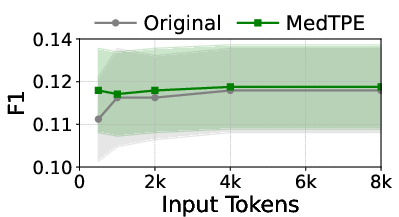
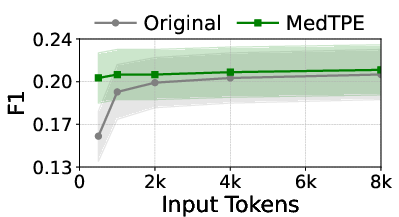
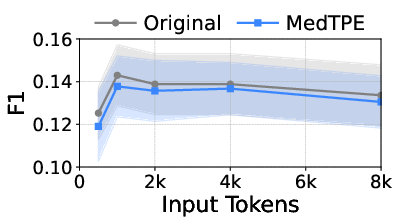
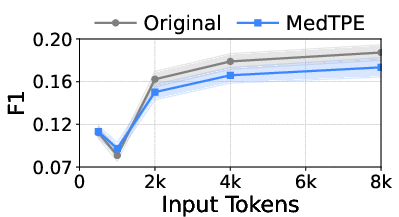
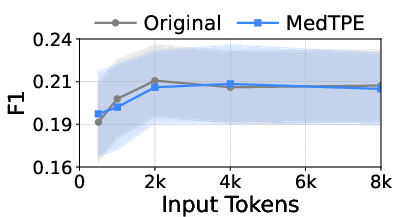
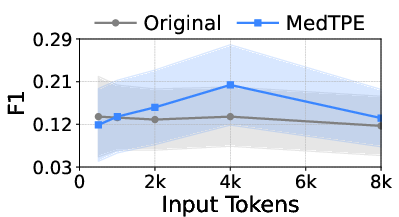
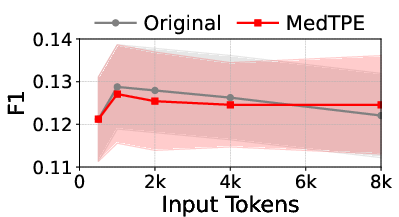
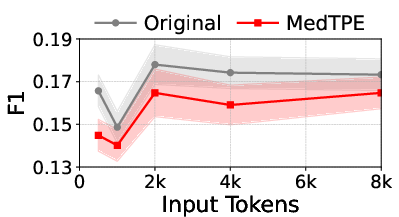
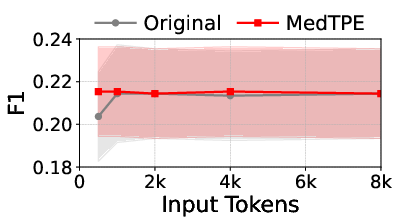
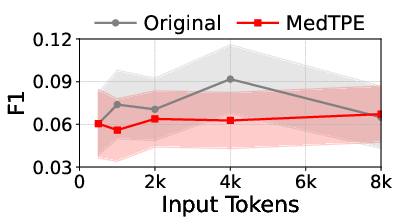
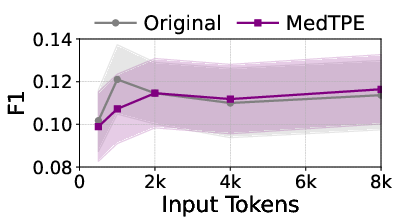
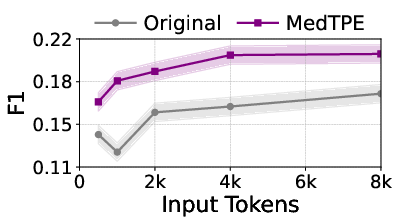
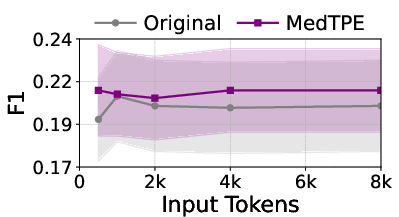
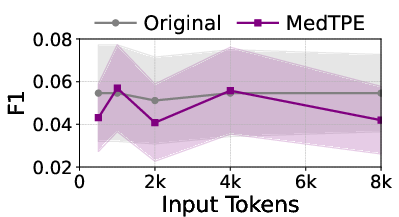
Figure 5: Inference latency reduction and F1 improvement for Llama3-1B on ICU Mortality, demonstrating the computational impact of MedTPE.
MedTPE outperforms removal-based (LLMLingua2) and merge-based (ZeTT) compression baselines, both in efficiency and reliability. Aggressive summarisation-based approaches yield lower latencies at the cost of significant predictive degradation—MedTPE circumvents this trade-off.
Architectural Analysis and Ablation
- Ablation studies confirm both the dependency-aware vocabulary replacement and SSFT steps are necessary. Omitting SSFT causes TPE embeddings to act as representation noise, breaking downstream model coherence.
- The empirical upper bound on compression (≈30%) aligns with the information-theoretic entropy bound for the corpora, as dictated by Shannon’s theorem.
Domain Generalisation and Robustness
MedTPE demonstrates strong cross-domain and cross-lingual generalisability when vocabularies are re-mined and aligned in the target domain (e.g., scientific, financial, and Chinese medical QA data). However, naive transfer of token-pair inventories across substantially diverged clinical corpora produces mismatches in token usage statistics and reduces downstream performance, underscoring the importance of localised vocabulary adaptation and re-validation.
Theoretical Implications
MedTPE introduces a scalable approach to semantically-driven, token-level efficiency for LLMs operating on specialised corpora with skewed substring frequency distributions. By maximising information content per token under computational constraints, MedTPE operationalises Shannon-optimal, lossless compression directly at the tokenisation layer—without retraining or adverse interference with the core LLM knowledge representation. This framework demonstrates that frozen-backbone, embedding-only adaptation can yield clinically significant efficiency improvements.
Limitations and Future Directions
MedTPE requires access to the base tokeniser and the embedding matrix, which may not be feasible in closed-source or restricted model deployments. Instruction-following LLMs with heavy domain-specific continual pretraining (e.g., Meditron3) may show degraded format compliance and reasoning robustness under certain prompting strategies when token distributions shift, particularly with CoT (Chain-of-Thought) prompts. Integration with reasoning-intensive prompting frameworks and exploration of instruction-aware TPE selection offer open research avenues.
Conclusion
MedTPE empirically establishes tokenisation-driven, lossless compression as a highly effective method for real-world deployment of LLMs in clinical prediction on EHRs. The approach achieves substantial reductions in input sequence length and inference latency—without sacrificing predictive fidelity or requiring model retraining—thereby facilitating tractable, plug-and-play acceleration of LLMs in high-throughput, long-horizon healthcare workloads.
Practical and Theoretical Implications
For practical deployment, MedTPE delivers robust, interpretable, and efficiency-optimised LLM-based clinical prediction with negligible architectural modifications and obviates retraining on expensive, domain-limited corpora. Theoretically, MedTPE’s approach supports scalable, entropy-bounded vocabulary engineering aligned to domain-specific redundancy patterns, and operationalises lossless compression as an architectural primitive for domain-adapted LLM integration.
References
For in-depth experimental details, methodology, and code, refer to "From Token to Token Pair: Efficient Prompt Compression for LLMs in Clinical Prediction" (2605.11774).