- The paper demonstrates that prompt compression can achieve up to an 18% end-to-end speedup while sustaining output quality for lengthy LLM inputs.
- Methodologically, it compares LLMLingua and LLMLingua-2, revealing linear compression latency scaling across diverse hardware platforms.
- The study highlights that compression benefits are situational, offering significant memory savings on commodity hardware but risking quality degradation on structured tasks.
Prompt Compression for LLM Inference: Latency, Rate Adherence, and Quality in Practice
Introduction
The increasing integration of LLMs into information retrieval (IR) workflows and retrieval-augmented generation (RAG) pipelines has underscored inference latency as a bottleneck, particularly as prompt sizes expand due to concatenation of multiple context passages. Prompt compression, aiming to reduce the input prompt length while maintaining downstream performance, has become a candidate for alleviating both latency and memory constraints, with methods such as LLMLingua and LLMLingua-2 showing compelling preliminary results. However, comprehensive large-scale empirical analysis quantifying real-world trade-offs—across latency, memory, hardware, and output quality—remains scarce. This work fills that gap through an extensive set of 30,000 experimental runs, dissecting where prompt compression delivers significant practical benefit and where it does not.
Methodological Overview
The study examines both LLMLingua and LLMLingua-2 compression paradigms—representing sequential token-pruning and encoder-based approaches, respectively—each in two model sizes (standard and small). Compression performance is assessed across three major hardware platforms (Nvidia A100, GTX 1080 Ti, Apple M1 Pro) and a spectrum of open-source and proprietary LLMs. The evaluation meticulously separates compression latency from model inference, quantifies end-to-end latency gains (with particular focus on the Time to First Token, TTFT), tracks output quality across a diverse task suite, and investigates adherence to target compression rates.
Latency and Hardware Dependence
The empirical results decisively demonstrate that compression overhead—rather than model inference speedup—dominates as the principal factor constraining the practical benefit of prompt compression, especially as hardware tier decreases or serving frameworks become more optimized. For LLMLingua-2, compression latency remains independent of compression ratio, scaling linearly with prompt size and staying within approximately 3 seconds for maximal (48K-token) prompts on high-end hardware.
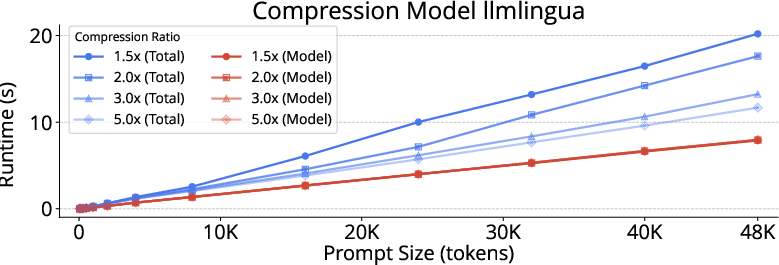
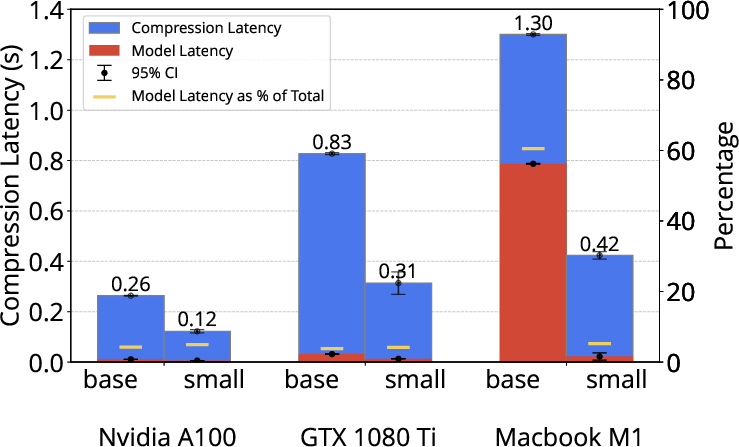
Figure 1: LLMLingua-2 exhibits prompt size-dependent but compression ratio-invariant latency, with notably reduced wall-clock times on advanced GPUs compared to other variants.
When prompt length, compression ratio, and hardware throughput are optimally matched, LLMLingua-2 achieves up to 18% end-to-end speedup with preservation of output quality. Outside this operational window, however, the compression stage itself eliminates or reverses any latency gains.
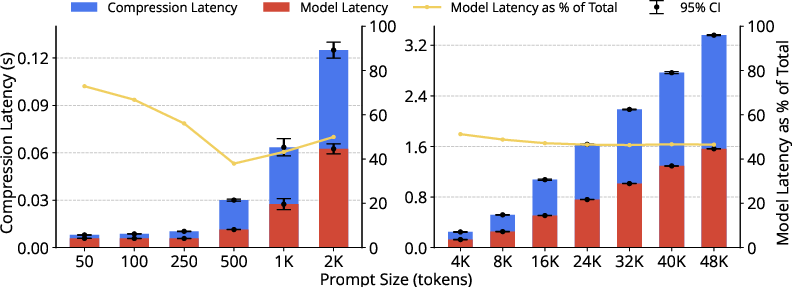
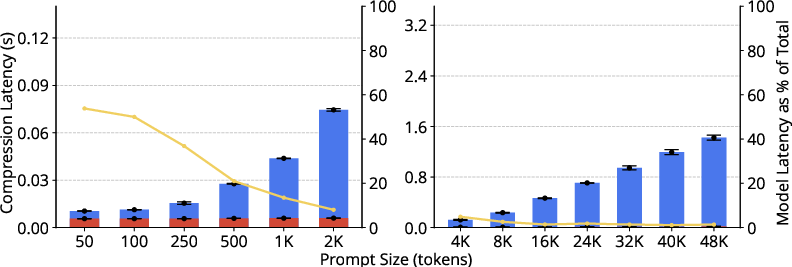
Figure 2: Compression latency profiles for small LLMLingua variants reveal linear scaling with increasing prompt size and highlight the proportion of time spent in model versus post-processing inference.
Time-to-First-Token (TTFT) acceleration is highly contingent on serving context. Substantial speedup (up to 4× for 7B models on non-optimized Hugging Face Transformers) is evident for very long prompts and aggressive compression. However, inference under optimized serving frameworks (vLLM, commercial APIs) nullifies these gains due to already highly optimized prefill and prompt processing routines.
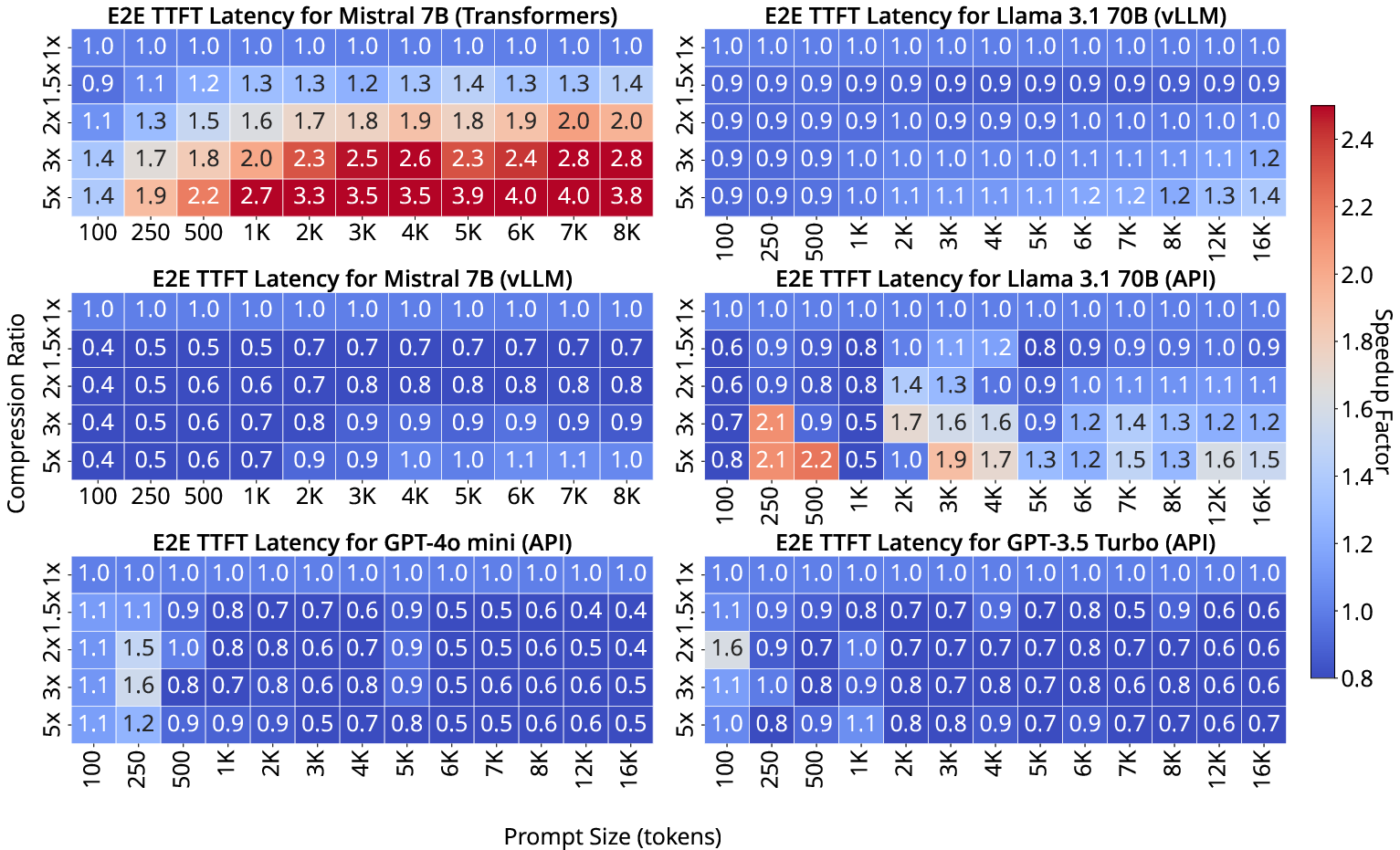
Figure 3: TTFT speed-up varies sharply across target model, hardware, and serving framework, with significant gains observed primarily in non-optimized frameworks and high-compression regimes.
Quality Retention and Task Sensitivity
LLMLingua-2 maintains statistically equivalent performance on summarization, question answering, and some code generation tasks for longer prompts, provided the compression enables inclusion of otherwise context-truncated content. Performance is highly variable, however, for structured synthetic tasks, passage retrieval, and few-shot learning scenarios. In some cases, such as passage counting and retrieval, compression artifacts induce a loss of critical labeling structure, leading to sharp accuracy declines. For classification via few-shot, removal of key class indicators during compression causes substantial degradation, especially when zero-shot baselines are competitive.
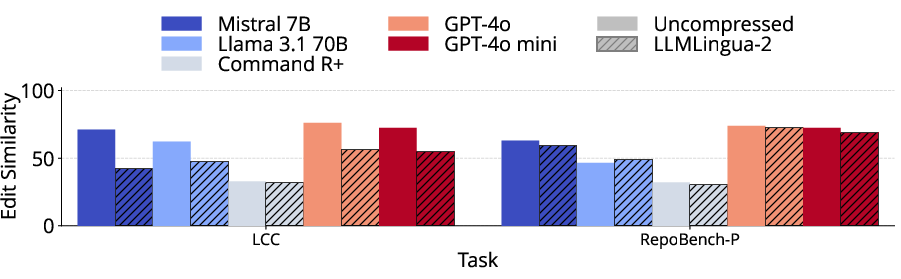
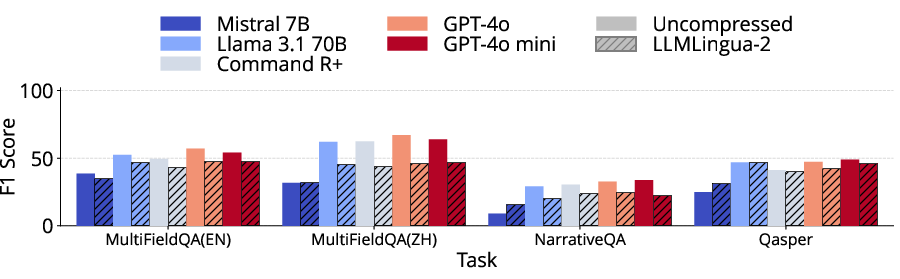
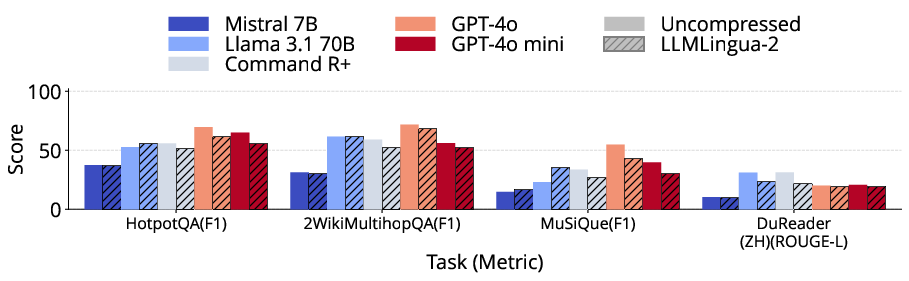
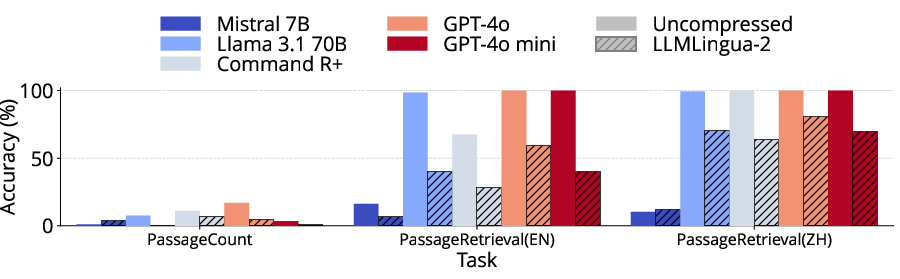
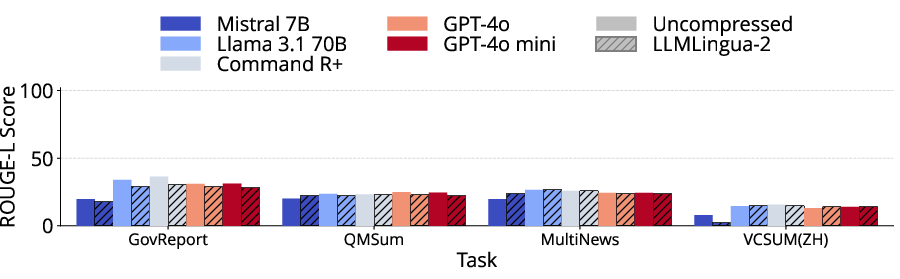
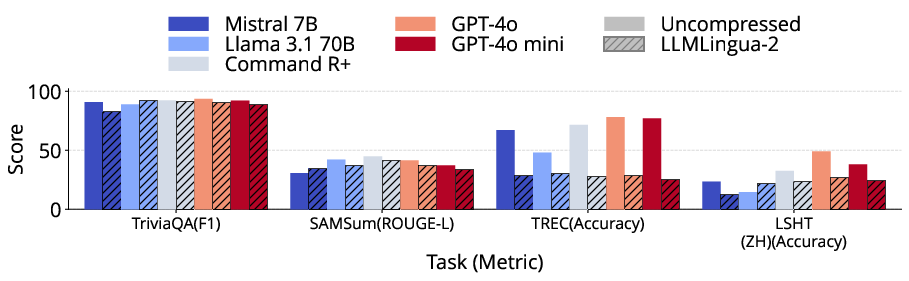
Figure 4: Across LongBench tasks, LLMLingua-2-compressed prompts retain quality for QA and summarization but degrade sharply for synthetic and few-shot tasks.
Rate Adherence and Predictability
Adherence to target compression rates is essential for predictable latency and API cost control. LLMLingua-2 exhibits robust rate adherence across prompt sizes, in contrast to LLMLingua's variable compression, which introduces unpredictability in downstream latency, cost, and output quality.
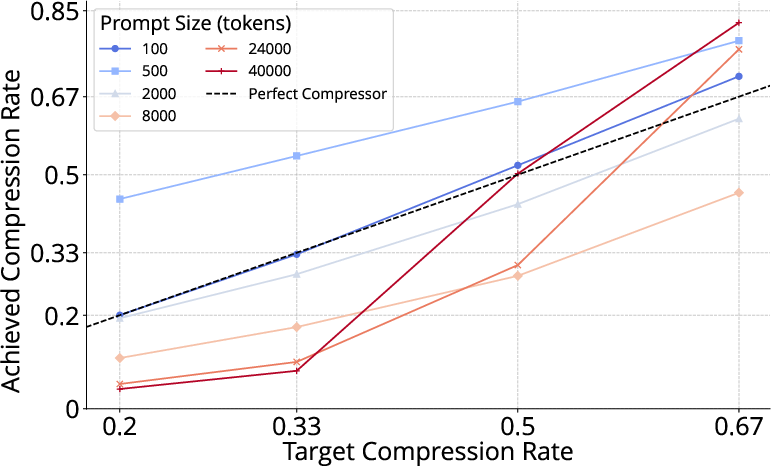
Figure 5: LLMLingua-2 aligns closely with device-specified compression rates, ensuring predictable resource usage, unlike its predecessor.
Memory and System Implications
Memory reduction through prompt compression can be substantive—up to 75% in certain configurations—enabling long-context LLM inference on consumer-grade GPUs otherwise incapable of accommodating large prompt lengths. Model size is a critical determinant; small encoder-based compressors (LLMLingua-2-small) operate comfortably within 1.5 GB VRAM ceilings, making them practical even on commodity hardware for moderate prompt lengths.
Implications, Limitations, and Future Directions
The comprehensive results point to several nuanced conclusions:
- Prompt compression is beneficial only under specific operational conditions, namely for very long inputs, on hardware not leveraging optimized inference pipelines, or when memory constraints are paramount.
- The window of practical acceleration is tightly constrained: for short or moderate input lengths, or on already optimized serving architectures, compression introduces net overhead.
- Task selection is critical: tasks reliant on finely structured or position-dependent input, as well as those where zero-shot baselines are strong, are unlikely to benefit and may suffer from compression artifacts.
- For commodity hardware, compression allows workload offloading, opening avenues for scalable, low-cost deployment in edge and on-premise scenarios where memory is the dominant concern.
Looking forward, future work should address integration of compression-aware methods more deeply within LLM serving pipelines, explore hybrid approaches that dynamically select compression strategy based on prompt/task profile, and refine task-specific pruning criteria. Transparent metrics for end-to-end cost—including API costs, latency, and energy—would augment practical utility. Additionally, comprehensive benchmarks on multilingual and knowledge-intensive tasks remain outstanding.
Conclusion
End-to-end prompt compression for LLM inference, as instantiated in LLMLingua-2, provides a measured, situationally dependent benefit—delivering up to 18% speedup and substantial memory savings for long prompt contexts, but incurring measurable overhead outside these bounds. Task choice, model size, serving framework, and hardware dictate the extent to which compression is advantageous. Rate-adherent, lightweight compressors extend feasibility to commodity hardware, though care must be taken to avoid output degradation on structurally sensitive applications. The open-source profiler released alongside this work operationalizes these findings for practitioners, formalizing when and where prompt compression will yield real-world acceleration.

