- The paper introduces W-Flow, a one-step generative framework that compresses multi-step transport dynamics into a single, efficient inference map.
- It leverages Sinkhorn divergence with a two-batch debiased estimator to derive optimal velocity fields, ensuring robust mode coverage and convergence.
- Empirical results on ImageNet show 100× faster sampling with superior FID scores and enhanced control via classifier-free guidance.
One-Step Generative Modeling via Wasserstein Gradient Flows
Motivation and Conceptual Framework
The paper "One-Step Generative Modeling via Wasserstein Gradient Flows" (2605.11755) proposes W-Flow, a novel generative modeling framework engineered for high-fidelity, efficient image generation in a single network evaluation. The motivation arises from the computational latency of traditional diffusion and flow-based models, which require numerous sequential steps to transition a sample from a reference distribution to the target data distribution. W-Flow circumvents this bottleneck by compressing the entire evolution into a static generator, mapping the reference distribution to the target in just one step.
This is achieved by prescribing the evolution of the generator distribution via Wasserstein gradient flows (WGF), instantiated with the Sinkhorn divergence as the energy functional. The evolution is defined in continuous distribution space and discretized via explicit Euler steps, each driven by a batch-level optimal transport plan computed through Sinkhorn iterations. The generator is then trained to simulate these transport updates, ultimately compressing the dynamics into a single inference map.
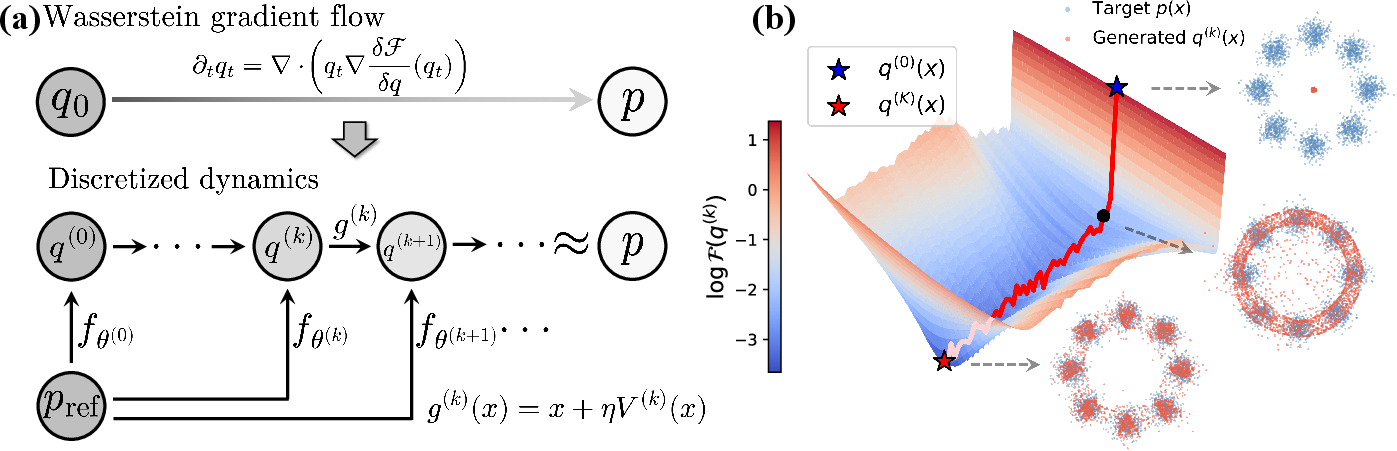
Figure 1: (a) Diagram of W-Flow showing the incremental pushforward structure; (b) Visualization of training dynamics projected onto the Sinkhorn divergence landscape for multimodal Gaussian mixtures.
W-Flow decomposes global transport into sequential local updates, training a neural generator to match the trajectory specified by batch-level velocity fields. The velocity field is derived from the steepest descent direction of the Sinkhorn divergence, yielding Vq,pε(x)=Tq,pε(x)−Tq,qε(x), where Tq,pε(x) and Tq,qε(x) are barycentric projections from optimal transport couplings between the model distribution and dataset (and itself). Empirical velocity estimation employs a principled two-batch approach, which avoids self-matching artifacts endemic to naive one-batch estimators.
This approach ensures that the only stationary point of the dynamics is the target distribution, eliminating spurious equilibria and enhancing mode coverage. The discrete-time particle dynamics admit theoretical guarantees: under regularity and large-sample assumptions, the empirical distribution of evolved particles converges to the solution of the WGF continuity equation.
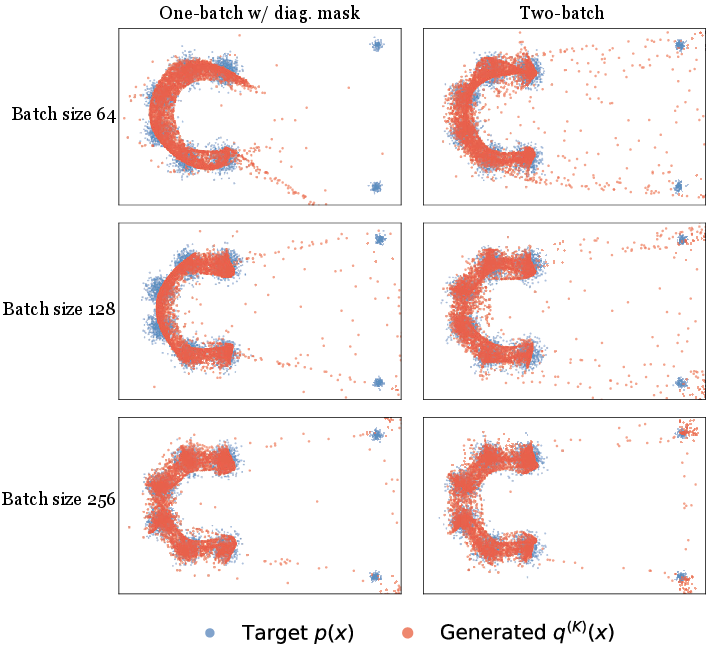
Figure 2: Evaluation of self-transport estimators; the two-batch debiased estimator yields faithful coverage of Gaussian tails, unlike one-batch or masked heuristics.
Implementation, Classifier-Free Guidance, and Feature-Based Transport
The generator is instantiated in latent space and trained with regression loss aligning the generator output to the updated particle position under the Sinkhorn velocity—importantly with stop-gradient targets to avoid unstable differentiation through the transport plan.
Classifier-free guidance (CFG) is incorporated directly into the velocity field, enabling controlled amplification of class-conditional features and resolving conceptual mismatches in alternative distribution-guidance strategies. Experiments demonstrate that velocity guidance yields improved FID and IS tradeoffs relative to distribution guidance.

Figure 3: FID and Inception Score curves across CFG scales, with image samples exhibiting controlled enhancement of class-specific details as guidance increases.
Empirical Results: ImageNet Generation, Throughput, Domain Transfer, and Mode Coverage
W-Flow sets new performance benchmarks for one-step generators on ImageNet 256×256, achieving FID 1.29 (XL scale), 1.35 (L scale), and 1.52 (B/2 scale), surpassing both Drifting Model [deng2026generative] and previous consistency or mean flow variants in terms of sample quality and mode coverage. The throughput analysis confirms approximately 100× faster sampling compared to state-of-the-art multi-step diffusion models at comparable FID scores.
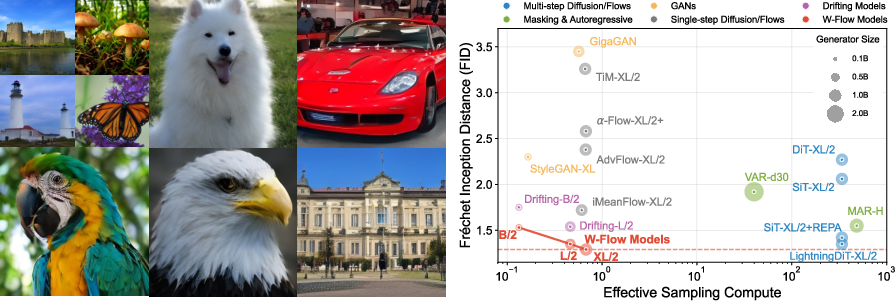
Figure 4: (Left) Representative 1-NFE samples from W-Flow-L/2 on ImageNet 256×256; (Right) Sample quality (FID) vs. effective compute, illustrating the efficiency advantage.
Practically, W-Flow’s globally coordinated OT dynamics confer robust mode coverage even in highly imbalanced settings. In toy multimodal and real-world latent space tasks (FFHQ age translation), the method achieves better coverage of minority modes, mitigating mode collapse—a persistent issue in non-OT-driven dynamics.
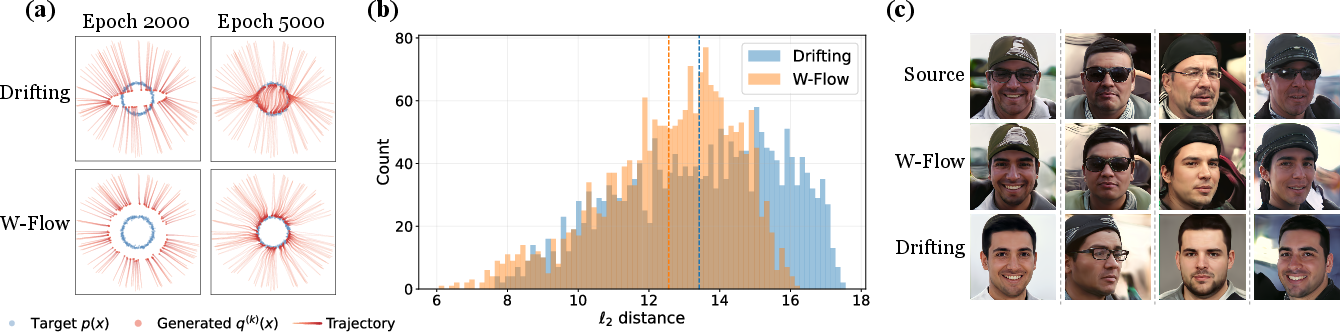
Figure 5: (a) Oval-to-circle domain transfer map; (c) One-step facial age translation on FFHQ, with histogram of transport distances and qualitative comparisons revealing preservation of source identities.
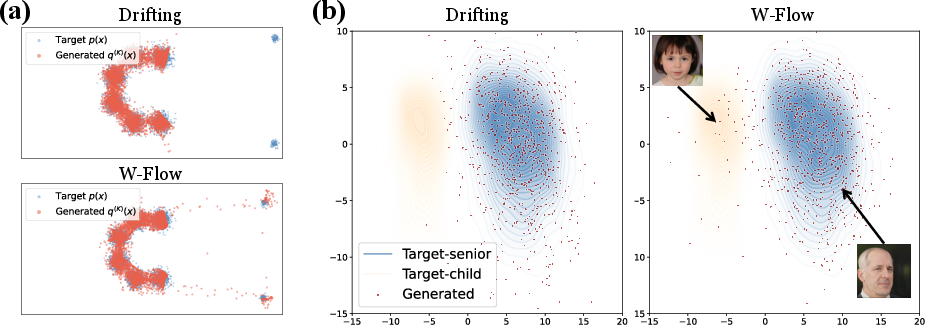
Figure 6: (a) Mode coverage evaluation in imbalanced mixtures; (b) PCA scatter plot of generated latent codes for FFHQ, demonstrating successful preservation of minority child faces.
Theoretical and Practical Implications
W-Flow demonstrates that WGFs instantiated with Sinkhorn divergence yield principled, globally consistent dynamics for compressing training-time evolution into static one-step generators. The method is resilient to tuning choices, converges faster during training, and supports scalable implementations that avoid adversarial or inner-loop optimization.
From a theoretical standpoint, the work clarifies the correspondence between particle-level transport and population-level gradient flows, establishes the absence of spurious equilibrium, and motivates broader exploration of transport-based energy functionals. The empirical superiority of the quadratic OT cost and two-batch estimation scheme underscore the importance of principled divergence selection and estimator design in efficient generative modeling.

Figure 7: Uncurated samples generated by W-Flow, L/2 with CFG w=0.15, evidencing high-fidelity, diverse one-step ImageNet generation.

Figure 8: Uncurated samples from W-Flow, XL/2 (Top) and B/2 (Bottom), with consistent sample quality across scales.
Future Directions
Extending W-Flow to text-to-image, video, and multimodal generative tasks appears promising, given its robustness and scalability. Moreover, the general framework of specifying distributional evolution via gradient flows and compressing them into static maps could inspire novel architectures in domains where inference compute or latency is a premium constraint. Further research may focus on integrating richer energy functionals, deploying in higher-dimensional or semantic spaces, and exploring adversarial robustness and fairness in mode coverage.
Conclusion
W-Flow inaugurates a principled, globally-coordinated framework for one-step generative modeling, offering demonstrable improvements in sample quality, training and inference efficiency, and distributional coverage. Through explicit WGF dynamics, optimal transport-based velocity fields, and efficient learning schemes, the approach provides a scalable foundation for fast, high-fidelity generation in complex domains (2605.11755).

