Flow Straighter and Faster: Efficient One-Step Generative Modeling via MeanFlow on Rectified Trajectories
Abstract: Flow-based generative models have recently demonstrated strong performance, yet sampling typically relies on expensive numerical integration of ordinary differential equations (ODEs). Rectified Flow enables one-step sampling by learning nearly straight probability paths, but achieving such straightness requires multiple computationally intensive reflow iterations. MeanFlow achieves one-step generation by directly modeling the average velocity over time; however, when trained on highly curved flows, it suffers from slow convergence and noisy supervision. To address these limitations, we propose Rectified MeanFlow, a framework that models the mean velocity field along the rectified trajectory using only a single reflow step. This eliminates the need for perfectly straightened trajectories while enabling efficient training. Furthermore, we introduce a simple yet effective truncation heuristic that aims to reduce residual curvature and further improve performance. Extensive experiments on ImageNet at 64, 256, and 512 resolutions show that Re-MeanFlow consistently outperforms prior one-step flow distillation and Rectified Flow methods in both sample quality and training efficiency. Code is available at https://github.com/Xinxi-Zhang/Re-MeanFlow.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI image generators faster and simpler. Many popular models create pictures by slowly turning random noise into a real-looking image, one tiny step at a time. That works well, but it’s slow. The authors show a way to jump from noise to a finished image in just one step, while keeping the picture quality high and the training cost low.
What questions did the researchers ask?
- Can we make one-step image generation both high-quality and efficient?
- Can we avoid the heavy, repeated training that older methods needed to “straighten” their paths?
- Can we fix the instability that happens when training one-step models on very twisty (curvy) paths?
How did they do it?
To understand their idea, imagine traveling from point A (random noise) to point B (a real image). If the road is twisty, you must slow down and check directions often (many steps). If the road is straight, you can get there fast (one step).
The problem: Curvy paths make you slow
In many models, the “path” from noise to image is curved. That makes sampling (creating a new image) take many steps. One-step methods struggle because a single jump isn’t accurate on a curvy path.
Two earlier ideas
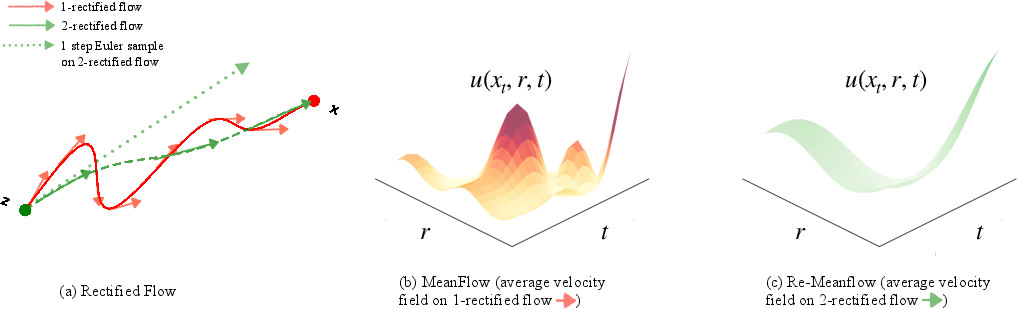
- Rectified Flow: Try to straighten the path by repeatedly re-planning the route (“reflow” steps). In theory, perfectly straight paths would allow one step. In practice, you’d need many rounds to get perfectly straight, which is expensive—and even one or two rounds can still leave some curves.
- MeanFlow: Instead of following the curve step-by-step, learn the average speed and direction over time (like learning the average “push” from A to B). That allows one-step generation. But if the original path is very curvy, the “average” becomes noisy and hard to learn, so training is slow and unstable.
Their idea: Rectified MeanFlow (Re-Meanflow)
Combine the best parts of both:
- First, do just one round of path-straightening (one “reflow” step). This makes the paths noticeably smoother but doesn’t aim for perfection.
- Then, train a MeanFlow model on these smoother paths. Because the paths are less curvy, the “average direction” is cleaner and easier to learn, so training becomes faster and more stable.
- A simple trick called distance truncation helps even more: they throw away the most extreme 10% of paths—the ones where the start and end are very far apart. Those extreme cases tend to be the curviest and noisiest, and dropping them makes learning steadier and quality higher.
In short: slightly straighten the paths, then learn the average push along those paths, and ignore the worst troublemakers.
What did they find, and why does it matter?
Across ImageNet image generation at 64×64, 256×256, and 512×512:
- Better one-step image quality:
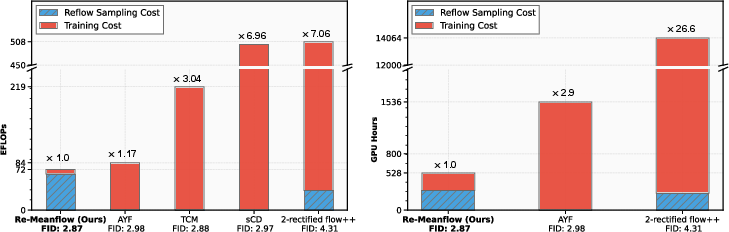
- At 64×64, their method beats a strong “2-rectified flow++” baseline by about 33% (lower FID is better).
- At 512×512, it improves over recent leading one-step methods (like AYF).
- At 256×256, it slightly beats MeanFlow—even though it trained only on synthetic (self-generated) data, which usually makes quality worse. The smoother paths made training easier.
- Faster and cheaper training:
- Compared to a recent strong baseline, their method used about 2.9× fewer GPU hours.
- Compared to “2-rectified flow++,” it was about 26.6× faster in GPU hours.
- Most of the heavy work moves to an “inference-only” stage (making paths) that runs well on widely available, cheaper hardware; the actual training phase is light.
- Clear synergy:
- Rectifying once makes paths smoother.
- MeanFlow then learns the average direction much more easily.
- Dropping the worst 10% long-distance pairs removes the noisiest training cases.
- Together, these steps give better quality and efficiency than any one of them alone.
What’s FID? It’s a common score that measures how close generated images are to real images. Lower is better.
What’s the impact?
This approach makes one-step image generation more practical:
- Faster image creation: jumping from noise to image in one step is great for speed-sensitive apps.
- Lower training cost: you can train with fewer resources and less time.
- More accessible: since much of the work can run on cheaper, widely available GPUs, more teams can experiment and deploy.
- Scales to big images: it works well even at high resolutions.
Overall, the paper shows a simple, effective recipe: slightly straighten the path, learn the average push along that smoother path, and ignore the worst outliers. This improves both the quality and the efficiency of one-step image generation, and could help future models in other domains (like larger images or text-to-image) become faster and easier to train.
Collections
Sign up for free to add this paper to one or more collections.

