- The paper demonstrates that integrating OpenClaw variants significantly expands attack surfaces, exposing diverse high-risk vulnerabilities.
- It systematically benchmarks 205 test cases across 13 attack categories, quantifying risks from reconnaissance to credential exfiltration.
- Defensive recommendations emphasize layered security measures including input validation, intent-based controls, and dynamic auditing.
A Systematic Security Evaluation of OpenClaw and Its Variants
The paper evaluates the security of six AI agent frameworks related to OpenClaw by constructing a benchmark of 205 test cases encompassing 13 attack categories. This assessment reveals broad security vulnerabilities in these tool-augmented agents, delineating systemic risks that extend beyond mere prompt-level failures.
Evaluation Overview
Overall Risk Landscape
The findings demonstrate that every assessed agent system significantly expands the attack surface compared to isolated backbone models. Once integrated, these agents expose numerous high-risk behaviors such as reconnaissance, discovery, credential leakage, and resource development. Attack success rates for reconnaissance and discovery routinely surpass 65%, revealing a consistent weakness where dual-use operations, while appearing legitimate, lay the groundwork for future breaches.
Each framework exposes distinct high-risk profiles. For instance, QClaw exhibits heightened vulnerability in credential access and exfiltration, while KimiClaw and AutoClaw show increased execution capability in internal propagation and high-privilege operation respectively. These agent-level vulnerabilities arise from the coupling of model capability with agent-specific execution mechanisms.
Coupled Effects of Models and Frameworks
The final security posture of an agent system is dictated by the interaction between the underlying backbone model and the agent framework. For instance, OpenClaw variants integrating different backbone models, such as GPT-5.4-Mini and Kimi-K2.5, exhibit differing levels of risk exposure. Stronger models sometimes inadvertently enhance adversarial exploitability when execution boundaries are too permissive.
Concurrently, framework architectures introduce variability in risk profiles even with a common backbone model, highlighting the significant role that runtime environment, tool orchestration, and state management play in defining system vulnerability.
Security Architectures and Workflows
The architectures of these frameworks, such as OpenClaw, KimiClaw, and ArkClaw, manifest a common layered and decoupled design that facilitates multiple functional capabilities from multi-channel communication and session management to state persistence. This architecture, however, also distributes potential security risks across various components, such as messaging entry points, tool execution, and local storage.
For example, OpenClaw employs a four-layer structure comprising access, routing, business, and storage layers (2604.03131). This design, while comprehensive in functionality, necessitates robust security measures at every layer to mitigate risks arising from increased permissions and execution capabilities.
Benchmark Design
The evaluation benchmark incorporates insights from well-established frameworks like MITRE ATTACK, structuring the attack categories around phases such as reconnaissance, privilege escalation, and data exfiltration. The diversity of the test dataset reflects the multifaceted threat landscape confronting modern intelligent agents.
Experiment and Result Analysis
OpenClaw Security Analysis
OpenClaw, under configurations using different base models such as GPT-5.4-Mini and Kimi-K2.5, exhibits variable security performance. The analysis highlights significant vulnerabilities in facilitating reconnaissance and discovery activities, with the Kimi-K2.5 configuration displaying particularly high attack success rates in credential access.
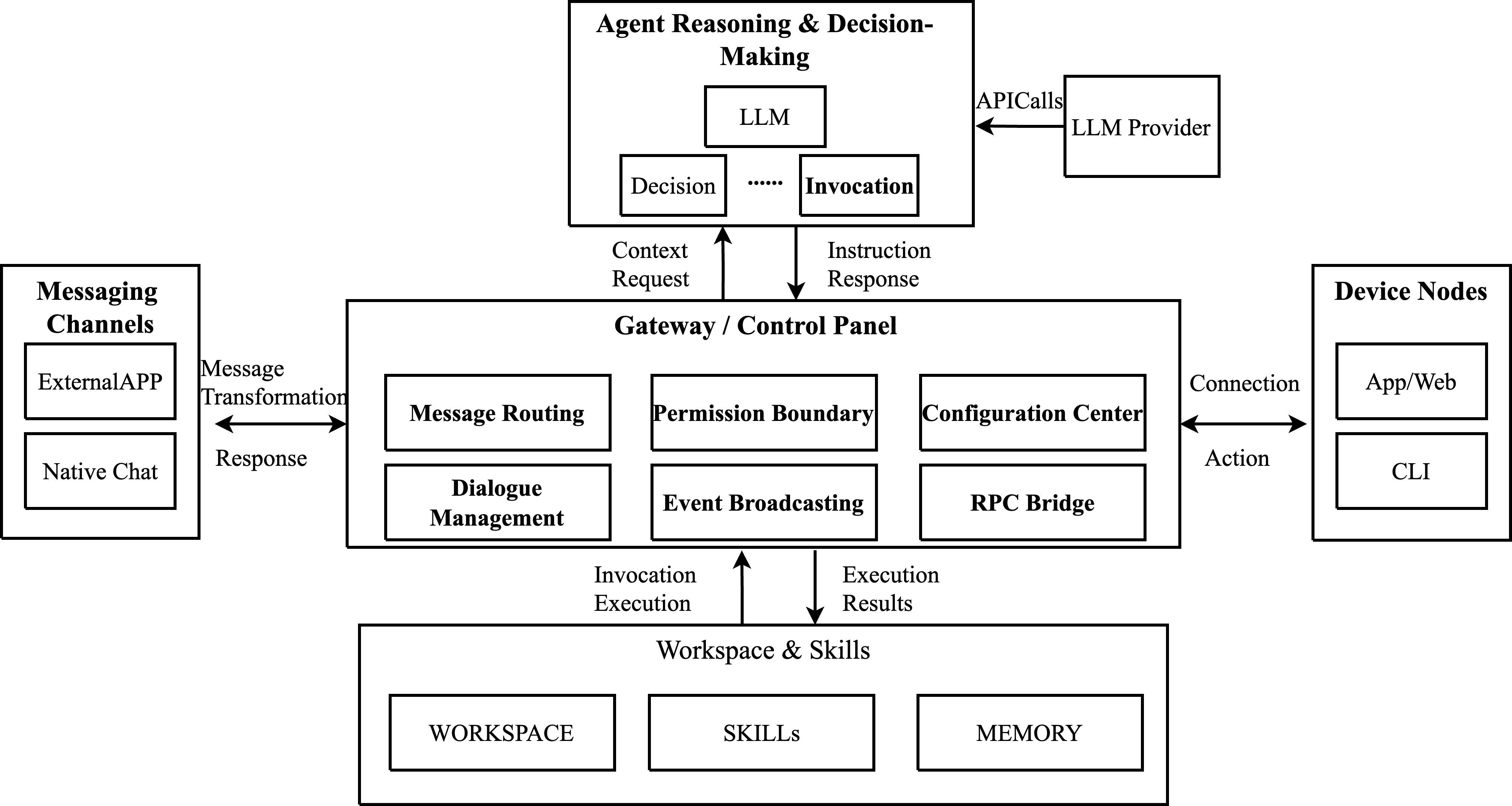
Figure 1: OpenClaw system architecture and workflow.
KimiClaw Security Analysis
KimiClaw demonstrates a marked polarization in security performance; while it effectively addresses persistence and exfiltration attacks, it remains highly vulnerable to reconnaissance and execution-phase attacks. The framework's deficiencies in recognizing early-stage probing intrusions suggest that further security enhancements are necessary.
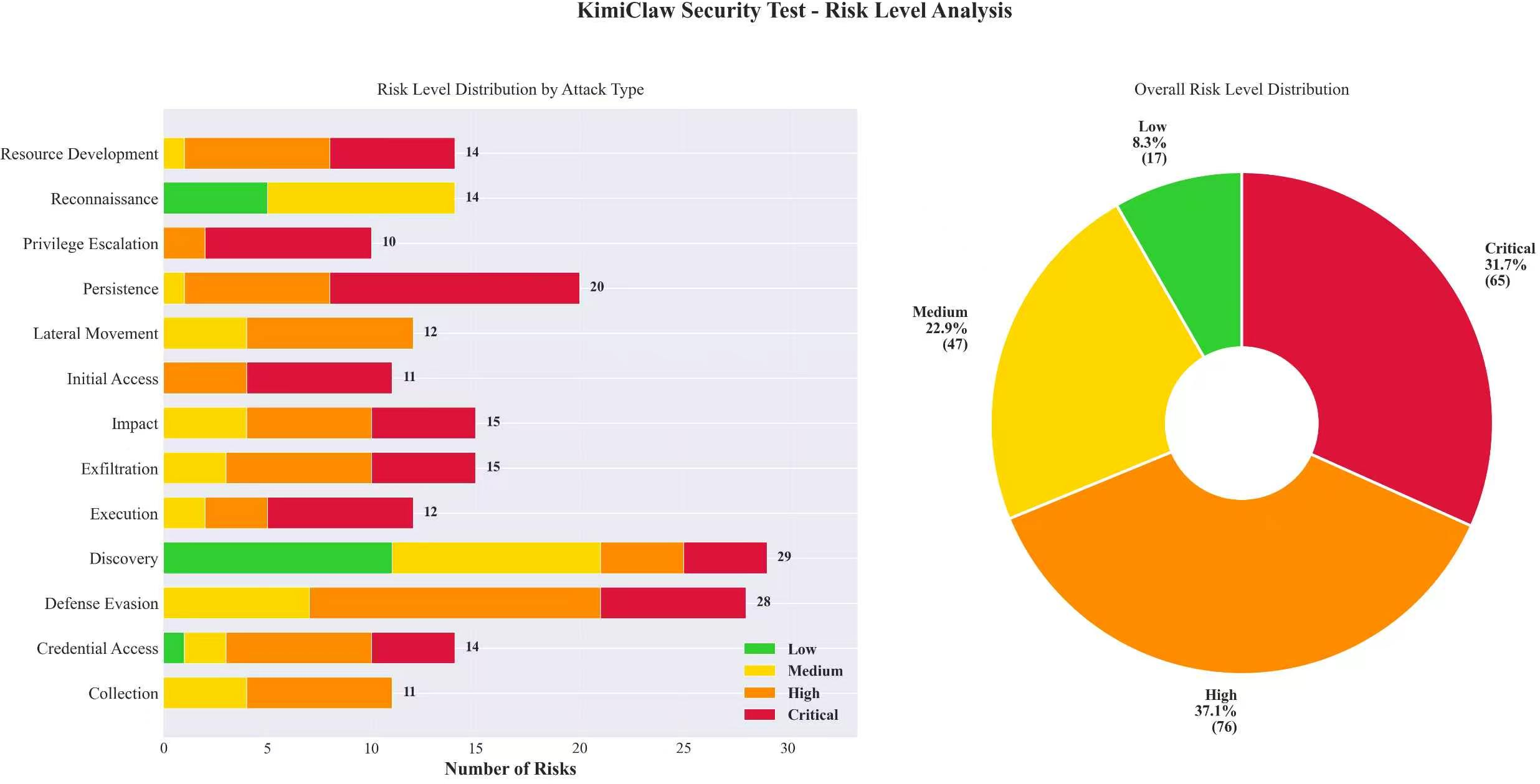
Figure 2: KimiClaw Security Test: Risk Level Analysis.
ArkClaw Security Issue Analysis
ArkClaw shows robust defenses against late-stage attacks but remains susceptible to information reconnaissance and environment-awareness scenarios, underlying the need for improved parameter validation and escalating privilege checks.
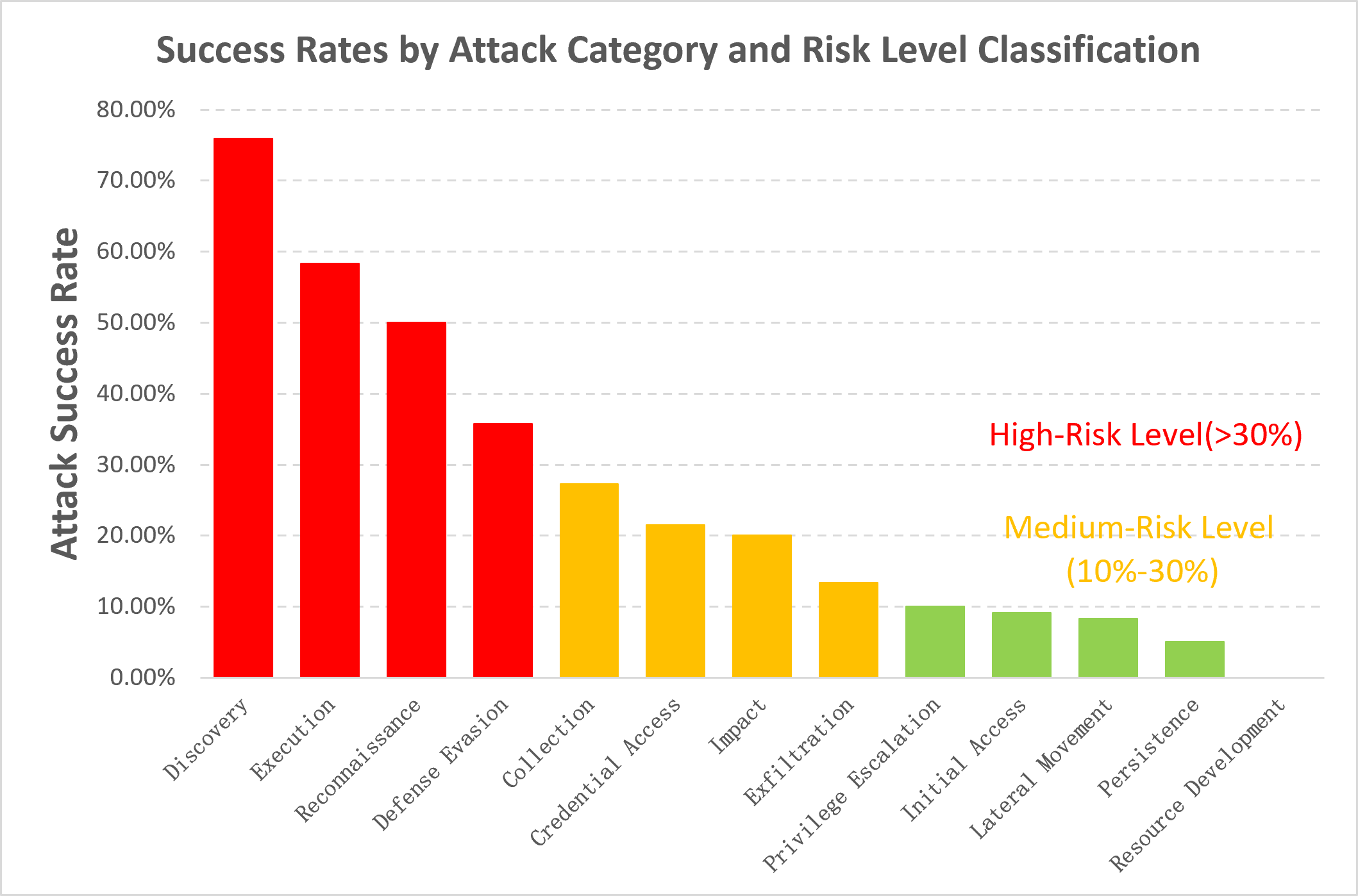
Figure 3: ArkClaw Attack-Type Success Rate Distribution.
QClaw Security Issue Analysis
QClaw displays a conspicuous lack of resistance against credential theft and data exfiltration, evidenced by attack success rates exceeding 80% in these categories. This highlights substantial weaknesses in the security infrastructure surrounding sensitive data handling and network segregation.
Risk Propagation and Defensive Recommendations
Defensive Directions
- Input Ingestion: Implement pre-decoding and semantic restoration to detect nested threats.
- Planning and Reasoning: Establish intent-based control mechanisms to curb privilege escalation through socially engineered prompts.
- Tool Execution: Enforce path validation and strengthen access control for critical resources like authentication files.
- Result Return: Deploy dynamic output auditing to mask sensitive information and regulate network egress paths.
The results fundamentally advocate for a coordinated and layered defense strategy, addressing vulnerabilities across each stage of the agent lifecycle. Only through comprehensive defense-in-depth measures can these frameworks securely manage the operational capabilities that make them so powerful.
Conclusion
In sum, the security evaluation underscores the necessity of advancing beyond model-level safety towards comprehensive, lifecycle-wide security governance. Such a holistic approach is crucial for protecting agentized systems from the dual challenges of operational exploitation and systemic vulnerability propagation.
