Pixal3D: Pixel-Aligned 3D Generation from Images
Abstract: Recent advances in 3D generative models have rapidly improved image-to-3D synthesis quality, enabling higher-resolution geometry and more realistic appearance. Yet fidelity, which measures pixel-level faithfulness of the generated 3D asset to the input image, still remains a central bottleneck. We argue this stems from an implicit 2D-3D correspondence issue: most 3D-native generators synthesize shape in canonical space and inject image cues via attention, leaving pixel-to-3D associations ambiguous. To tackle this issue, we draw inspiration from 3D reconstruction and propose Pixal3D, a pixel-aligned 3D generation paradigm for high-fidelity 3D asset creation from images. Instead of generating in a canonical pose, Pixal3D directly generates 3D in a pixel-aligned way, consistent with the input view. To enable this, we introduce a pixel back-projection conditioning scheme that explicitly lifts multi-scale image features into a 3D feature volume, establishing direct pixel-to-3D correspondence without ambiguity. We show that Pixal3D is not only scalable and capable of producing high-quality 3D assets, but also substantially improves fidelity, approaching the fidelity level of reconstruction. Furthermore, Pixal3D naturally extends to multi-view generation by aggregating back-projected feature volumes across views. Finally, we show pixel-aligned generation benefits scene synthesis, and present a modular pipeline that produces high-fidelity, object-separated 3D scenes from images. Pixal3D for the first time demonstrates 3D-native pixel-aligned generation at scale, and provides a new inspiring way towards high-fidelity 3D generation of object or scene from single or multi-view images. Project page: https://ldyang694.github.io/projects/pixal3d/













































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: what this paper is about
This paper is about turning a single photo (or a few photos) into a 3D model that looks exactly like what you see in the picture. The authors introduce a new method called Pixal3D that “lines up” every pixel in the image with the right place in 3D space. This makes the 3D result much more faithful to the original image than many previous methods.
What questions did the researchers ask?
- How can we make a 3D model that matches the input image at the pixel level, not just “kind of similar”?
- Can we build a direct, clear link between each pixel in a photo and where it belongs in 3D space?
- Can the same idea work with multiple photos (views) and even build full 3D scenes with several objects?
How did they do it? (Methods in simple terms)
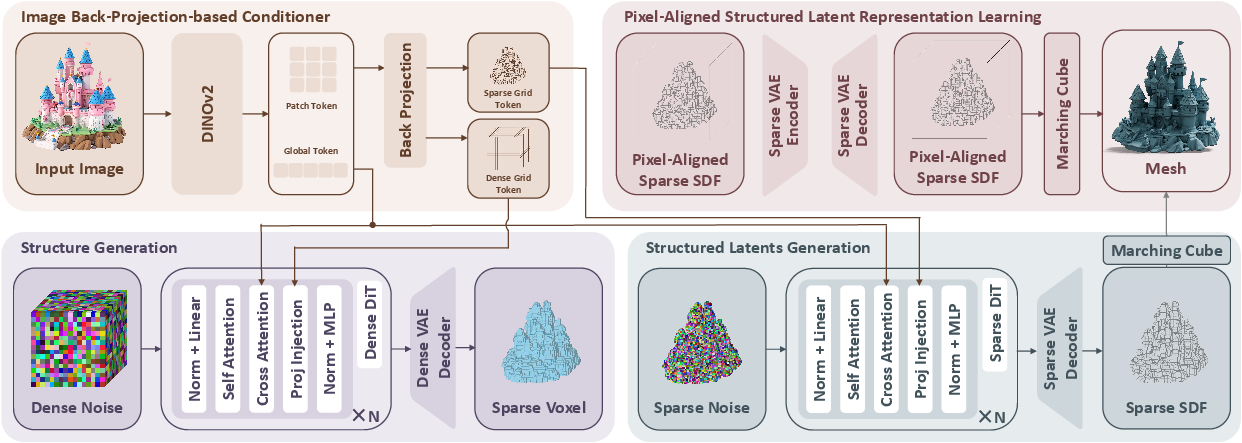
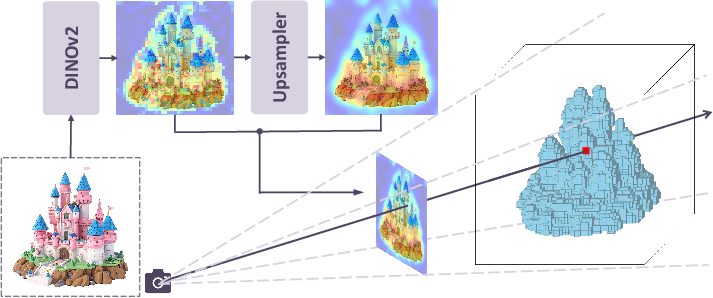
Think of a photo as a window into 3D space. Every pixel in the photo sits on a line that shoots out into the world from the camera. Pixal3D uses this idea to connect 2D pixels to 3D positions directly.
Here are the main pieces, with everyday analogies:
- Pixel-aligned generation (view-aligned sculpting)
- Instead of building a 3D object in a neutral, “default” pose and then trying to match it to the picture, Pixal3D builds the 3D object directly in the camera’s view. Imagine sculpting the object exactly as you see it through the camera.
- Back-projection (threading pixels into space)
- For each image pixel, imagine a thin thread stretching from the camera into 3D space along a straight ray. Pixal3D “lifts” the image’s information along that thread into a 3D grid (like a box filled with tiny cubes).
- These tiny cubes are called voxels (think of them as 3D pixels or Lego bricks). Filling the box with per-pixel information creates a “feature volume” that tells the 3D generator exactly which image details belong where.
- Multi-scale features (both zoomed-out and zoomed-in views)
- The system uses information from the image at different detail levels—like looking at a photo both zoomed out (to understand overall shape) and zoomed in (to capture small details like buttons or textures). Combining these helps keep fine details.
- Generating the 3D model (from noise to neat)
- The 3D model is produced by a “diffusion” process—imagine starting with a noisy block of points and gradually cleaning it up into a clear shape, guided by the pixel-aligned feature volume.
- A compressor–decompressor (VAE) helps keep things efficient by working in a compact representation, then decoding back into a detailed 3D surface. A classic algorithm (“Marching Cubes”) extracts a clean mesh (the final surface) from the data.
- Multiple photos: simple, reliable merging
- With several views, Pixal3D repeats the back-projection for each photo and averages the information in the 3D box. More views give the system more “evidence,” so the 3D model becomes even more accurate and consistent from all angles.
- Building full scenes (several objects in one image)
- To turn a single scene photo into a 3D scene:
- 1) Segment objects in the 2D image and fill in any occlusions (missing parts).
- 2) Generate each object with Pixal3D in the camera’s view (so their directions match the picture automatically).
- 3) Use a predicted depth/point map to set each object’s size and distance so they fit together properly in 3D.
- Because each object is already aligned to the image, arranging them in 3D is easier and more stable.
Main findings and why they matter
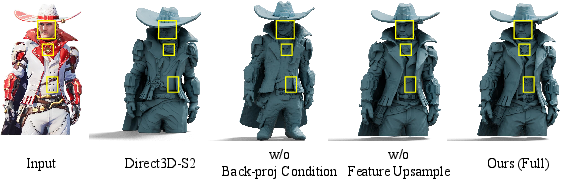
- Much higher image faithfulness (“fidelity”)
- Compared to strong previous methods, Pixal3D’s 3D results line up with the input photo far better—especially for fine details like small parts, patterns, and exact shapes. In tests and user studies, people preferred Pixal3D for matching the image and overall quality.
- Near reconstruction-level accuracy, but with full 3D assets
- Traditional “reconstruction” methods are very accurate for what’s visible but often leave holes in hidden areas. Pixal3D keeps that pixel-accurate quality on visible surfaces while using a learned generator to plausibly fill in the hidden parts, producing complete, usable 3D models.
- Strong with multiple views
- When given several photos, Pixal3D becomes even more reliable. It combines views in a straightforward way and outperforms both reconstruction and generation baselines on standard 3D shape accuracy measures.
- Better scene generation
- For building 3D scenes from a single image, Pixal3D’s pixel-aligned objects make arranging multiple objects easier and more consistent than methods that have to guess each object’s full 3D pose. The result is more coherent scenes with correct relative sizes and placements.
Why this matters: many real uses—games, AR/VR, product previews, and digital design—need 3D models that look exactly like the images people provide. Pixal3D reduces the gap between what you see and the 3D you get.
Implications and potential impact
- A simple idea with big payoff: directly aligning pixels to 3D
- By replacing a fuzzy “guess where this image detail goes in 3D” step with a clean geometric link (back-projection), Pixal3D makes image-to-3D generation more accurate and stable.
- Plays well with future improvements
- Pixal3D is a general paradigm, not tied to one specific 3D representation. As better geometry, texture, or material models appear, the same pixel-aligned conditioning can plug in and keep improving fidelity.
- Practical applications
- Faster creation of faithful 3D assets for e-commerce, movie/game props, AR filters, and education.
- Easier 3D scene construction from photos, useful for virtual staging, interior design, and rapid prototyping.
In short, Pixal3D cleverly blends the discipline of 3D reconstruction (exactly matching what’s seen) with the creativity of generative models (filling in what’s hidden), making it much easier to get high-quality, image-accurate 3D objects and scenes from one or more pictures.
Knowledge Gaps
Below is a focused list of unresolved gaps, limitations, and open questions raised or implied by the paper. Each item is framed to be concrete and actionable for follow-up research.
- Single-view camera assumptions and sensitivity: The inference-time heuristic for cube placement (choosing FoV and computing camera distance so corner rays hit the cube’s back face) replaces actual intrinsics/pose estimation. Its sensitivity to image crop, object centering, focal length mismatch, and lens distortion is unquantified. Develop robust self-calibration or intrinsics/pose estimation for in-the-wild images and evaluate failure modes.
- Train–test mismatch in camera handling: Training uses ground-truth camera parameters (from synthetic renderings), while inference relies on a heuristic. Systematically quantify this domain gap and explore training with noisy/estimated intrinsics to improve robustness.
- Uncalibrated multi-view inputs: The multi-view extension assumes known, accurate camera parameters. Handling uncalibrated or weakly calibrated multi-view settings (e.g., real photo collections) is not addressed. Integrate camera estimation and joint optimization with generation.
- Occlusion and visibility reasoning in conditioning: Back-projection assigns identical features along each ray and multi-view fusion averages per-voxel features, ignoring occlusions and view visibility. Explore occlusion-aware fusion (e.g., depth or transmittance weighting, Z-buffering, learned visibility) and ray-wise gating to prevent conflicting evidence.
- Depth ambiguity along rays: With identical features along a ray, localizing surfaces in depth is left entirely to the generative prior. Investigate adding pixel-aligned depth/normal/point-map priors, positional encodings along rays, or learned per-depth feature modulation to reduce ambiguity.
- Simple averaging for multi-view fusion: Averaging across views does not model confidence, calibration uncertainty, or per-view quality. Study learned fusion modules with confidence weights, view-dependent attention, and uncertainty-aware aggregation.
- Canonicalization and asset reuse: Outputs are in camera coordinates and lack canonical orientation/scale, complicating downstream asset reuse and dataset-wide consistency. Design canonicalization modules (e.g., learned canonical frame prediction) and evaluate the impact on downstream tasks.
- Background clutter and object isolation: The single-view object pipeline implicitly assumes the object dominates the frustum; the scene pipeline offloads isolation to external segmentation/inpainting models. Develop an end-to-end framework that robustly handles background clutter, imperfect masks, and partial occlusions without manual intervention.
- Dependency on external segmentation and inpainting for scenes: Scene synthesis relies on SAM3 and a 2D inpainting model (Qwen-image-edit). Quantify error propagation from these stages, and explore joint training/optimization to reduce dependency and hallucination artifacts.
- Scale and depth alignment in scenes: Scene composition solves only isotropic scale and depth via point-map constraints; inter-object rotations, support/contact, and physical plausibility are not enforced. Introduce constraints for contact, stability, and relative orientation, and formulate joint scene-level optimization.
- Texture/material and appearance modeling: The method focuses on geometry; appearance generation (textures, BRDFs, materials) under the pixel-aligned paradigm is not explored. Develop a coordinated pixel-aligned appearance pipeline and metrics for appearance fidelity.
- Representation limits for thin structures and open surfaces: Sparse SDF + Marching Cubes can struggle with very thin or open geometries. Evaluate failures on such cases and explore representations (dual grids, anisotropic surfaces, mesh-native, Gaussians) tailored to pixel-aligned conditioning.
- Resolution and aliasing constraints: The voxel resolution and sparse indexing may limit very fine details, especially with pixel-to-voxel projection and coarse-to-fine schedules. Characterize trade-offs and investigate scalable higher-resolution conditioning/decoding.
- Feature encoder and upsampler not co-trained: DINOv2 features and the NAF upsampler are used off-the-shelf and are not trained end-to-end with the 3D generator. Assess domain shift (e.g., stylized, non-photorealistic, low-light images) and study joint finetuning or learned multi-scale feature heads for 3D fidelity.
- Multi-scale feature fusion is hand-crafted: The system averages sampled features across scales. Explore learnable scale fusion, edge/normal-aware guidance, or cross-scale attention to better preserve fine details.
- Conditioning fusion by simple addition: The 3D feature volume is added to the noise volume. Investigate more expressive fusion (e.g., FiLM-like conditioning, gated residuals, or cross-modal attention localized by back-projection) to improve controllability and stability.
- Generalization beyond object-centric renderings: Training on Objaverse renderings with randomized views may not fully cover real-world image statistics (clutter, diverse lenses/EXIF, motion blur). Establish real-image benchmarks and study data augmentation or domain adaptation strategies.
- Robustness to adverse visual conditions: Performance under challenging lighting, shadows, reflections, translucency, and textureless regions is not analyzed. Create targeted stress tests and integrate physics-aware cues or learned reflectance priors.
- Evaluation breadth and metrics: Single-view evaluation relies on normal-map comparisons and two embedding-based image–3D consistency metrics; multi-view uses Toys4K CD/EMD/F-Score. Add evaluations on standard real-world datasets (e.g., CO3D, DTU), and report topology quality, manifoldness, watertightness, and downstream utility (e.g., printing, simulation).
- Diversity and uncertainty in unobserved regions: The method aims for “near reconstruction-level fidelity,” but how it captures multi-modal backside completions is not assessed. Introduce mechanisms and evaluations for diversity/uncertainty in unseen regions and user control over completions.
- Computation and memory footprint: Training/inference costs, scaling with input resolution and number of views, and latency in the scene pipeline are not quantified. Profile the system and explore acceleration (sparser conditioning, distillation, caching).
- Lens distortion and non-pinhole cameras: The back-projection assumes a pinhole model; handling fisheye or smartphone lens distortion is not discussed. Add distortion models or self-calibration to extend applicability.
- Handling symmetries and pose ambiguities: Pixel-aligned generation may be brittle for symmetric objects with ambiguous orientations. Incorporate symmetry-aware priors or global consistency constraints.
- Failure analysis and dataset for reproducible errors: The paper reports strengths but lacks systematic failure taxonomy (e.g., occlusions, thin parts, multi-object clutter). Curate and release a diagnostic benchmark to drive targeted improvements.
- Joint learning for scenes: The current scene pipeline is modular and not end-to-end. Explore a unified training objective that couples segmentation, depth/point-map estimation, and pixel-aligned 3D generation to improve coherence and reduce error accumulation.
- Integration with part-aware or articulated modeling: Although stated orthogonal, part structure or articulation was not demonstrated. Investigate pixel-aligned part-aware generation and poseable assets.
- Scaling to very many views or wide baselines: Multi-view results are shown for up to six views with simple averaging. Study scalability to dozens of views, wide baselines, and inconsistent exposures, and compare with reconstruction baselines under those regimes.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Pixal3D’s pixel-aligned back‑projection conditioning, single-/multi-view support, and the modular scene pipeline (segmentation → 2D completion → pixel-aligned 3D → depth-based alignment).
- High-fidelity 3D product assets from 2D listings — retail, e-commerce, advertising
- What: Turn single product photos into faithful, watertight meshes (GLB/USDZ) for 360° viewers, search, and AR previews.
- Workflow/tools: Batch pipeline or Shopify/Adobe/Blender plugins; SAM3 for masks; optional Qwen-image-edit for occlusion fill; Pixal3D for geometry; quick texture bake; export.
- Assumptions/dependencies: Image rights; clean backgrounds improve results; scale is approximate (use a reference object or metadata if needed); textures/materials may need a separate step.
- AR “try-before-you-buy” for furniture and decor — retail, interior design
- What: Convert a catalog image into an AR-ready mesh aligned to the captured view; place it in-room via ARKit/ARCore.
- Workflow/tools: Single-view Pixal3D; dimension normalization from known product specs or fiducials.
- Assumptions/dependencies: Metric scaling requires a known dimension or camera metadata; occluded sides are plausible, not exact.
- Rapid prop generation for games/VR — media/entertainment, software
- What: Faithful, low-latency asset creation from concept/photos for props, set dressing, and background items.
- Workflow/tools: Blender/Unity/Unreal import; decimation/LOD; Pixal3D outputs watertight meshes from images; scene pipeline for multi-object compositions.
- Assumptions/dependencies: Geometry fidelity is highest on visible surfaces; materials may need authoring.
- Single-photo scene 3D for staging and visualization — real estate, marketing
- What: Extract per-object meshes from a single room photo and assemble a coherent 3D scene.
- Workflow/tools: SAM3 segmentation → Qwen-image-edit completion → Pixal3D per object → MoGe point map for global scale/depth alignment → export to USD/GLTF.
- Assumptions/dependencies: Good segmentation; global depth prediction quality impacts relative placement; metric accuracy requires scale references.
- Catalog/MRO part digitization for browsing and training — manufacturing, supply chain
- What: Approximate 3D shapes of catalog parts from photos to improve search, BOM browsing, and training materials.
- Workflow/tools: Batch Pixal3D over catalog imagery; cluster/index with ULIP2/Uni3D embeddings.
- Assumptions/dependencies: Not CAD-accurate; unsuitable for tolerance-critical tasks; multiple views improve fidelity.
- Multi-view reconstruction with generative completion — photogrammetry-lite, cultural heritage
- What: Use a few photos with known cameras to get high-fidelity meshes with robust multi-view consistency and plausible fills for unseen regions.
- Workflow/tools: Multi-view Pixal3D with camera intrinsics/extrinsics; simple averaging in back-projected feature volumes.
- Assumptions/dependencies: Camera calibration or EXIF + solve; fewer floaters than point-map methods; still not a substitute for laser scanning.
- Insurance and claims documentation — finance/insurtech
- What: Generate 3D evidence of damaged items/scenes from claim photos to enable better adjuster review and quoting.
- Workflow/tools: Single-/multi-view Pixal3D; scene pipeline for per-object isolation; annotate measurements on meshes.
- Assumptions/dependencies: Chain-of-custody for images; use disclaimers on uncertainty for occluded/hidden areas; metric scaling needs references.
- Robotics simulation asset bootstrapping — robotics, autonomy
- What: Populate simulators with approximate meshes of household/warehouse items from web or on-site photos to speed domain randomization and perception training.
- Workflow/tools: Pixal3D meshes into Isaac Sim/Gazebo; assign simplified collision shapes; optional multi-view capture from robot cameras.
- Assumptions/dependencies: Metric scale and mass/friction must be specified; geometry is best for perception, not precision manipulation.
- Education and maker workflows (3D print from a photo) — education, daily life
- What: Create watertight prints of everyday objects for teaching aids, hobby projects, or cosplay props.
- Workflow/tools: Pixal3D → mesh cleanup → wall-thickness checks → slicer; texture ignored or baked as vertex color.
- Assumptions/dependencies: Plausible completions for unseen parts; ensure printability and safety checks.
- Research tooling for 3D generative reconstruction — academia
- What: Study pixel-aligned conditioning, evaluate fidelity with normal-map metrics, and explore single-/multi-view aggregation.
- Workflow/tools: Reproduce paper’s evaluation (IoU, PSNR, angular errors vs ground-truth normals); ablations on feature upsampling and conditioning.
- Assumptions/dependencies: Access to TRELLIS/Objaverse-like data; DINOv2 and NAF upsampler; GPUs.
- 2D→3D stock libraries and search — content platforms
- What: Convert high-performing 2D assets into 3D stock; index with multimodal embeddings for retrieval and recommendation.
- Workflow/tools: Pixal3D batch jobs; ULIP2/Uni3D for image-mesh embedding alignment; DRM/provenance tagging.
- Assumptions/dependencies: IP clearance; moderation for sensitive content.
Long-Term Applications
These opportunities are plausible but require further research, scaling, or integration (e.g., robust texturing/materials, metric scale recovery, on-device performance, stronger priors for occlusions).
- CAD-grade reverse engineering from photos — manufacturing, industrial design
- What: From a few annotated photos, produce dimensionally accurate, parametric CAD.
- Needed advances: Metric scale recovery, tolerance-aware priors, parametric surface fitting; uncertainty quantification for occluded features.
- Dependencies/assumptions: Calibration targets/metadata; integration with CAD kernels (Parasolid, Open Cascade).
- Live, on-device 3D capture assistant — mobile AR, creator tools
- What: Real-time pixel-aligned 3D from phone video with immediate AR placement and editing.
- Needed advances: Model compression/quantization; efficient multi-view aggregation; energy-aware scheduling.
- Dependencies/assumptions: Access to camera intrinsics/pose; on-device accelerators.
- Single-shot 3D for robot manipulation and grasp planning — robotics
- What: Use one or few frames to build graspable object models with reliable scale and support relations.
- Needed advances: Metric depth priors, contact-aware geometry, physical property estimation; temporal consistency.
- Dependencies/assumptions: Calibrated cameras; tactile feedback or learned physics for refinement.
- Full material and relightable asset generation — media, ecommerce
- What: Joint geometry, UVs, PBR materials, and BRDFs from sparse photos for high-end rendering and configurators.
- Needed advances: Material priors, view-consistent texture synthesis, UV unwrapping; multi-light inference.
- Dependencies/assumptions: HDR environment capture or illumination estimation; multi-view benefits.
- Scene-scale digital twins from casual imagery — AEC, facilities, energy
- What: Produce coherent, object-separated, metrically aligned 3D scenes of homes, plants, or substations from walk-through photos.
- Needed advances: Global scale alignment, structural priors (walls/floors), asset libraries, and semantic SLAM integration.
- Dependencies/assumptions: Multi-view with camera poses; safety/permission for critical infrastructure.
- Fashion and apparel digitization from photos — retail, virtual try-on
- What: Reconstruct garments and accessories with cloth-aware geometry and materials from a few catalog or influencer photos.
- Needed advances: Deformable/clothing priors, simulation-ready topology, fabric BRDF estimation.
- Dependencies/assumptions: Size charts or body scans for metric fit; IP and model consent.
- Forensic and legal scene reconstruction — public safety, insurance, policy
- What: Generate explainable 3D reconstructions of incidents from limited images with quantified uncertainty.
- Needed advances: Provenance, calibration workflows, audit trails, and courtroom-standard validation; uncertainty overlays.
- Dependencies/assumptions: Strict chain-of-custody; adherence to evidentiary standards.
- Standards for 3D generative provenance and IP management — policy, platforms
- What: Watermarking and metadata standards for 3D assets generated from 2D inputs; licensing flows for derivative works.
- Needed advances: Robust 3D watermarking, interoperable metadata schemas (USD/GLTF extensions), platform governance.
- Dependencies/assumptions: Industry and standards-body collaboration (e.g., Khronos, W3C, MPAA).
- Foundation datasets via scalable scene generation — academia, platform R&D
- What: Use pixel-aligned scene pipeline to create large, object-separated 3D datasets with controllable fidelity for training and evaluation.
- Needed advances: Automated quality control, bias detection, and diversity curation; domain labeling and material realism.
- Dependencies/assumptions: Licensing for source images; compute for large-scale generation.
- Infrastructure inspection from sparse photos — energy, transportation
- What: Approximate 3D of components (valves, insulators, joints) from limited vantage points for pre-planning and annotation.
- Needed advances: Robustness to harsh conditions, material/defect cues, metric alignment with GIS.
- Dependencies/assumptions: Multi-view capture with pose; safety protocols; human-in-the-loop validation.
Notes on feasibility across all applications:
- Strongest fidelity is on visible surfaces; occluded regions are plausible completions and may be inaccurate without multi-view input.
- Multi-view workflows require camera intrinsics/extrinsics; single-view scaling needs references to achieve metric accuracy.
- Texturing/materials are not the primary focus of the paper’s core contribution and may require additional pipelines.
- Compute/GPU availability is needed for practical throughput; on-device scenarios need model distillation/optimization.
- Legal/IP, privacy, and provenance should be addressed when converting third-party images into 3D assets.
Glossary
- 2D-3D correspondence: A mapping between image pixels (2D) and points or regions in 3D space, crucial for aligning imagery with geometry. "explicit 2D-3D correspondence"
- 3D Gaussian Splatting: A rendering/representation technique that models scenes as collections of 3D Gaussians for fast differentiable rendering. "3D Gaussian Splatting, etc."
- 3D generative reconstruction: A paradigm that fuses reconstruction constraints with generative modeling to produce complete, plausible 3D assets faithful to input views. "Pixal3D is essentially a 3D generative reconstruction paradigm"
- 3D latent diffusion: A diffusion-based generative model operating on compact 3D latent representations instead of raw geometry. "a 3D latent diffusion framework"
- back-projection conditioning scheme: Conditioning method that lifts image features along camera rays into 3D (via back-projection) to inject pixel-aligned information into a 3D generator. "we introduce a pixel back-projection conditioning scheme"
- bundle adjustment: A nonlinear optimization in multi-view geometry that jointly refines camera parameters and 3D structure to minimize reprojection errors. "such as bundle adjustment."
- camera frustum: The pyramidal volume defined by a camera’s field of view and near/far planes, containing the rays cast from image pixels. "Collectively, these rays form a camera frustum,"
- camera intrinsics: Parameters of a camera that map 3D rays to 2D pixels (e.g., focal length, principal point), independent of pose. "including camera intrinsics, distance and cube scale ."
- canonical pose: A standardized, view-independent orientation for objects used during learning or generation. "Instead of generating in a canonical pose,"
- Chamfer Distance (CD): A symmetric distance metric between two point sets used to evaluate geometric similarity. "Chamfer Distance (CD)"
- cross-attention: A neural attention mechanism that fuses information across modalities (e.g., images and 3D tokens) by querying one with keys/values from another. "image conditioning is injected via cross-attention."
- DiT (Diffusion Transformer): A transformer architecture adapted for diffusion models to denoise latent variables over time. "a sparse DiT denoises noisy sparse voxel latents,"
- Dual Contouring: An isosurface extraction algorithm that reconstructs meshes from implicit fields by leveraging dual-grid information. "Dual Contouring"
- Earth Mover’s Distance (EMD): A metric that measures the minimal cost to transform one distribution (or point set) into another. "Earth Moverâs Distance (EMD)"
- F-Score: A harmonic-mean measure (precision/recall trade-off) used here to evaluate geometric reconstruction quality. "F-Score"
- feed-forward multi-view reconstruction: Reconstruction that directly predicts 3D structure from images in a single pass, without iterative optimization. "feed-forward multi-view reconstruction methods"
- field of view (FoV): The angular extent of the observable world seen by the camera. "a relatively small field of view"
- least-squares problem: An optimization that minimizes the sum of squared residuals, commonly used for parameter estimation. "solve a least-squares problem"
- Marching Cubes: A classical algorithm to extract a polygonal mesh from an implicit surface (e.g., SDF) on a voxel grid. "Applying Marching Cubes subsequently yields the final mesh."
- multi-view stereo (MVS): A technique that recovers 3D geometry from multiple images by establishing correspondences across views. "multi-view stereo (MVS)"
- pixel-aligned 3D generation: Generating 3D content in the camera’s coordinate frame so that 3D structures align with image pixels/rays. "a pixel-aligned 3D generation paradigm"
- plane-sweeping: A strategy for stereo that samples or aggregates features along hypothetical depth planes to find matches across views. "explored plane-sweeping of deep features"
- point map: A per-pixel prediction of 3D point locations (in a chosen coordinate frame), aligning image pixels to 3D points. "predict depth, normals, or point maps"
- signed distance field (SDF): A scalar field where each point stores the signed distance to the closest surface; zero level-set defines the surface. "decoded by a VAE decoder into a sparse SDF."
- sparse voxel latents: Compact latent features defined only at occupied or selected voxel locations, enabling efficient 3D generation. "utilizing sparse voxel latents as its 3D representation."
- structure-from-motion (SfM): A pipeline that estimates camera poses and sparse/dense 3D structure from image collections. "structure-from-motion (SfM)"
- triangulation: The process of estimating 3D point locations by intersecting rays from multiple views corresponding to the same image feature. "built upon pixel correspondences and triangulation,"
- triplanes: A 3D neural representation that projects features onto three orthogonal planes to efficiently encode volumes. "triplanes~\cite{wu2024direct3d}"
- ULIP2: A learned vision–language–point-cloud metric/embedding used to assess image–3D consistency. "ULIP2"
- Uni3D: A unified cross-modal embedding/metric for evaluating consistency between images and 3D shapes. "Uni3D"
- VAE (Variational Autoencoder): A generative model that learns probabilistic latent encodings and decodings of data. "uses a VAE to compress pixel-aligned sparse SDF into efficient sparse latents;"
- voxel grid: A 3D grid of volumetric elements (voxels) used to discretize space for geometry or feature storage. "back-projects image features into a voxel grid"
- watertight: A mesh property where the surface is closed (no holes), enabling well-defined inside/outside for SDFs and robust processing. "We watertight each mesh"
Collections
Sign up for free to add this paper to one or more collections.

