- The paper presents a thorough evaluation of RISC-V vector processors by establishing hardware performance ceilings through dedicated assembly microbenchmarks.
- The study compares GCC 15 and LLVM 21 auto-vectorization across domain-specific applications, exposing compiler strengths and performance bottlenecks.
- It analyzes LMUL tuning and tail handling overhead, highlighting the need for hardware and compiler co-design improvements to optimize vector performance.
Introduction and Motivation
The RISC-V Vector Extension (RVV) introduces Vector-Length-Agnostic (VLA) programming, offering hardware-agnostic portability of binaries, in sharp contrast to VLS (Vector-Length-Specific) ISAs such as x86 AVX and ARM NEON. This model, which sets active vector length at runtime, poses unique challenges for compiler auto-vectorization, particularly regarding vsetvl sequence generation, LMUL selection, tail/mask handling, and accurate cost modeling. With RVV hardware and compilers evolving actively, updated quantification of auto-vectorization and perf measurement is required, especially for high-performance computing (HPC) and ML workloads.
The paper designs assembly microbenchmarks to establish architectural performance ceilings for all key RVV instructions, systematically calibrates performance counters, and presents the first rigorous evaluation of GCC 15 and LLVM 21 auto-vectorization across diverse domain-relevant proxy and production applications on real RVV 1.0 hardware. The empirical analysis exposes optimizations and deficiencies in both compilers, yielding prescriptive insights into vectorization bottlenecks and practical performance tuning.
Assembly Microbenchmarks and Architectural Analysis
To quantify hardware- and compiler-independent ceilings, dedicated microbenchmarks were devised for memory accesses (unit-stride, non-unit/strided, and tailing/masked loads) and for arithmetic (FP16/32/64, INT8/16/32/64 via add, mul, fma, div), written in strict RVV 1.0 assembly with operand prestaging and dependency breaking.
Peak unit-stride load throughput approaches the theoretical maximum: 28.4 Gops/s for vle8 on Jupiter, with linear decrements for higher precisions. For strided access (stride=2), classic vlse and scalar access are bottlenecked at 1.78 Gops/s, while masked-vle achieves up to 9.2 Gops/s at 8-bit but loses efficacy at higher widths.
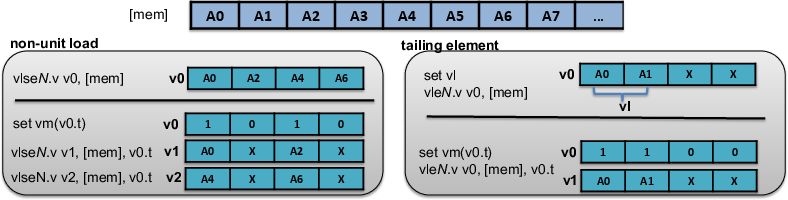
Figure 1: Diagrammatic decomposition of non-unit and tailing vector load addressing in RVV, inclusive of masking and vsetvl options.
The explicit evaluation of tail-handling mechanisms indicates that using predication masks for tail elements induces a 35.1% performance overhead compared to dynamic vector length adjustment, with negligible mask setup cost—this is attributed to inefficiencies in vector unit hardware execution for masked instructions.
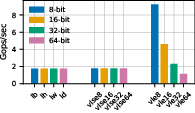
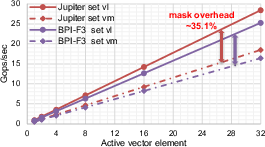
Figure 2: Throughput comparison for non-uniform load instructions on Jupiter, showcasing the efficiency gap across stride, masked, and unit-stride approaches.
Arithmetic benchmarks reveal that FMA on FP16 reaches 57.5 Gops/s, scaling linearly with precision, with FMA achieving near parity with add/mul, indicating hardware issue width sufficiency for fused operations. Scalar throughput is consistently 16× lower for FP16, denoting the wide advantage of vector units. Vector integer arithmetic throughput is similarly high except for INT64, while division (scalar/vector) saturates at <2 Gops/s, validating well-known vector divider latency.
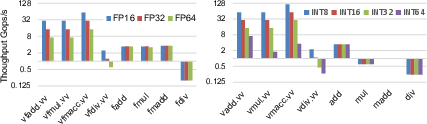
Figure 3: Peak throughput comparison for vector/scalar arithmetic across FP16/32/64 and INT8/16/32/64, highlighting FMA and integer multiplier efficiency.
Compiler Auto-vectorization: GCC 15 vs. LLVM 21
Comprehensive auto-vectorization analysis was performed on six applications (Stream, SpMV, SGEMM/DGEMM, YOLOv3, AlexNet), on both GCC 15 and Clang 21. Non-vectorized, autovectorized, and LMUL-tuned binaries were benchmarked, with all speedups normalized to GCC 15 scalar code.
GCC 15 dominates LLVM 21 in four out of six kernels; Clang 21 outpaces GCC 15 only in GEMM variants due to more aggressive instruction reduction and X60-specific instruction scheduling. For instance, sgemm achieves 2.4× speedup over baseline with Clang 21, 1.85× with GCC 15. For memory-bound and irregular apps (Stream, SpMV), neither achieves significant speedup; Clang 21 even regresses in Stream, exposing deficiencies in loop scheduling and bandwidth sensitivity.
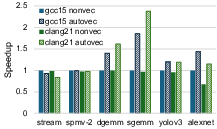
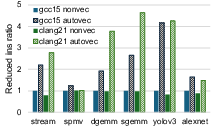
Figure 4: Application-level runtime speedup for GCC 15 and Clang 21, highlighting application-specific vectorization efficacy.
Instruction reduction under vectorization (Figure 4, right) frequently tracks speedup in compute-intensive workloads but not in bandwidth-bound ones, underscoring the complexity of microarchitectural bottlenecks not directly addressable by the compiler.
Detailed profiling using calibrated perf counters confirms that aggressive vectorization reduces scalar FP ld/st instructions (particularly in GEMM), but performance gains are modulated by the memory hierarchy. In SpMV, instruction reduction is negligible due to the inability of Clang and, to a lesser degree, GCC, to vectorize indirect accesses—contrary to better outcomes on ARM SVE platforms.
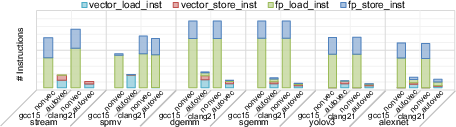
Figure 5: Breakdown of load/store instruction types in BPI-F3, illuminating vector/scalar transition under auto-vectorization.
LMUL Parameter Analysis
LMUL modulates register grouping, trading-off register count for throughput per instruction. Systematic LMUL sweeping in proxies demonstrates optimal settings are app- and compiler-dependent: Clang 21 achieves maximum speedup at LMUL=2 for GEMM, yet performance crashes for LMUL=8 due to register spilling. GCC 15 tolerates larger LMUL for some workloads. For bandwidth-bound kernels (Stream, SpMV), widening LMUL is detrimental. Across workloads, default compiler LMUL selection is usually close to optimal, rendering manual tuning rarely necessary.
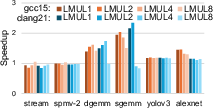
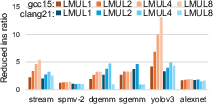
Figure 6: LMUL sensitivity of runtime speedup, exemplifying application-dependent optimal vector register grouping.
YOLOv3's speedup stagnation across LMUL settings, despite instruction reduction, is traced to vector pipeline contention: store-pipeline occupancy rises sharply with increased LMUL, causing pipeline stalls and nullifying expected gains.
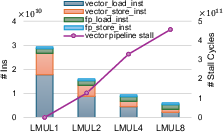
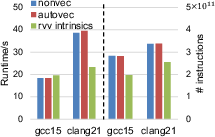
Figure 7: YOLOv3 profiling, highlighting vector pipeline utilization and stalling as LMUL increases.
Production Application: State Vector Quantum Simulation (Qsim)
Google’s Qsim, with interleaved complex data layout, represents a worst-case scenario for memory access complexity. Both GCC 15 and Clang 21 fail to auto-vectorize Qsim, resulting in comparable runtimes to non-vectorized baselines. Manually ported RVV intrinsics, with VLEN-adaptive layout and explicit masking, reduce dynamic instruction count, but only Clang 21 realizes speedup (1.6× relative), and absolute performance is still inferior to GCC 15. This demonstrates the pressing need for enhanced compiler path analysis, masking support, and layout awareness in RVV vectorizing front-ends.
Implications and Future Directions
The study provides authoritative ceilings and exposes tangible gaps in current compiler approaches:
- Masking and predication inefficiency: Hardware vector units suffer significant penalty for masked operations and tail management, suggesting hardware and compiler co-design opportunities.
- Aggressive instruction reduction is a necessary, but not sufficient, condition for speedup: Memory system limitations and vector pipeline contention dominate ultimate performance realities.
- Manual intrinsics required for irregular access: For complex workloads with non-contiguous memory layouts, current auto-vectorization in both GCC and LLVM remains insufficient; this bottleneck will persist until advanced dataflow analysis and alias tracking mature for VLA.
- Limited impact of LMUL tuning: Default choices are robust in most practical scenarios, but exceptional workloads (e.g., GEMM variants) can benefit from moderate manual tuning.
- Hardware perf counter calibration remains necessary: RVV’s current perf ecosystem requires rigorous validation prior to microarchitectural profiling, hampering large-scale toolchain development.
These results motivate several clear avenues for future research: compiler passes targeting non-trivial data access patterns, smart LMUL selection heuristics, hardware support for efficient tail and mask processing, and the development of domain-specific NVRAM-aware prefetching or transformation strategies.
Conclusion
Systematic peak-microbenchmarking and application-level quantification on real RVV hardware establishes the practical state of portable vector performance on RISC-V. GCC 15 currently offers more robust and stable vectorization with a performance lead in several complex domains, but LLVM 21’s aggressive approach can deliver superior results in regular compute-bound codes, especially for structured matrix operations. Both toolchains currently underperform on irregular, memory-complex kernels, underscoring the immaturity of RVV vectorization infrastructure. Manual RVV intrinsics remain, for now, indispensable for state-of-the-art performance on such workloads. Broadly, the paper pinpoints actionable targets for hardware and compiler enhancement in pursuit of full performance portability for VLA architectures.