- The paper introduces Sync-R1, an RL framework that explicitly bridges personalized understanding and content generation, achieving a 12.2% boost in comprehension metrics and a 14.1% improvement in generative quality.
- It employs innovative components like Sync-GRPO and Dynamic Group Scaling (DGS) to accelerate learning, reduce gradient variance, and enhance sample efficiency in multimodal settings.
- The unified reward ensemble integrates multiple evaluative signals, ensuring robust logical consistency, semantic alignment, and identity preservation for improved personalization.
Bridging Personalized Multimodal Reasoning with Reinforcement Learning: An Expert Summary of Uni-Synergy
Conceptual Motivation and Problem Definition
Unified Multimodal Models (UMMs) have established dominance for generic vision-language tasks, yet their personalization capabilities—especially when reasoning across both understanding and generation—remain suboptimal. Prevailing methods rely heavily on token-level supervised fine-tuning (SFT), which implicitly aligns semantic representations but lacks explicit synergy between comprehension and content creation. This leads to semantic bottlenecks, particularly in dense or ambiguous personalized scenarios, where understanding and generation are treated as isolated objectives. The critical challenge addressed by this paper lies in explicitly coupling personalized understanding with generation such that each task reciprocally enhances the other, thus producing robust personalization and reasoning in real-world multimodal settings.
Sync-R1 Framework: Explicit Synergy via Co-operative Reinforcement Learning
The core contribution is Sync-R1, an end-to-end reinforcement learning (RL) framework that implements an explicit, closed-loop reasoning trajectory for the joint optimization of understanding and generation. Sync-R1 decomposes personalization into two distinct phases:
- Personalized Understanding: The model performs reasoning on heterogeneous user context inputs to distill visual and textual attributes via Visual Instruct Reasoning and Textual Attribute Reasoning.
- Context-Guided Generation: These distilled attributes form compound prompts used for generation, ensuring direct semantic transfer from understanding to creation.
The critical innovation is holistic optimization, orchestrated via a composite reward signal that reflects both intermediate understanding outputs and the ultimate generative quality. This bidirectional feedback loop allows generation results to calibrate and refine the comprehension process, thereby enhancing cross-task synergy.
(Figure 1)
Figure 1: Schematic of Sync-R1 showing explicit coupling between personalized understanding and generation via a unified reasoning trajectory.
Sync-GRPO: Reinforcement Learning for Unified Optimization
Sync-R1 utilizes Sync-GRPO, a tailored variant of Group Relative Policy Optimization (GRPO), eschewing value function dependency for direct policy gradient updates across multimodal trajectories. Unlike pure text autoregressive models, Sync-R1 leverages Show-o's MaskGIT-based discrete diffusion mechanism: images are generated via iterative masked token predictions, with RL objectives encompassing both reasoning tokens and image token updates. The joint optimization objective is formulated by dynamic weighting of reasoning and generation components, maximizing clipped advantages while penalizing KL-divergence from a reference policy to ensure update stability. This results in effective functional alignment between intermediate reasoning outputs and downstream generative guidance.
Dynamic Group Scaling (DGS): Efficient High-Quality Trajectory Selection
Applying RL in multimodal settings is computationally expensive due to divergent trajectory spaces and sample inefficiency. Sync-R1 addresses this via Dynamic Group Scaling (DGS), an adaptive selective sampling mechanism that filters out low-potential trajectories during early denoising stages based on surrogate reward signals (e.g., BLIP-based evaluation). DGS accelerates wall-clock convergence and reduces gradient variance, backed by theoretical bounds showing amplified signal-to-noise ratios proportional to filtration intensity and surrogate correlation.
(Figure 2)
Figure 2: DGS workflow filtering low-potential trajectories to optimize sample efficiency in RL.
Unified Reward Ensemble: Multi-Faceted Feedback for Robust Learning
Sync-R1 integrates a synergistic reward ensemble comprising logical consistency (ERNIE/TIER), semantic alignment (BLIP/BER), identity preservation (DINOv2/DER), and high-fidelity facial synthesis (Facenet/FER). Empirical calibration confirms that dense supervision across these facets improves both reasoning and generation metrics, especially for human-centric personalization tasks.
Dataset and Evaluation: UnifyBench++ for Rigorous Assessment
To validate the model under information-dense and reasoning-intensive benchmarks, UnifyBench++ is introduced, extending UnifyBench with richer textual descriptions and diversified user contexts. The benchmark includes dense reasoning, dense generation, and dense reasoning generation tasks, systematically testing cross-modal alignment, inferential logic, and concept disambiguation.
Numerical Results and Empirical Insights
Sync-R1 achieves state-of-the-art (SOTA) results across all UnifyBench and UnifyBench++ metrics, with strong numerical gains:
- Understanding tasks: 12.2% improvement in comprehension metrics over previous SOTA at 1.3B scale.
- Generation tasks: 14.1% and 10.0% increases in dense and reasoning-sensitive generation metrics, respectively, compared to baseline UniCTokens.
- Efficiency: Sync-R1 converges 1.9× faster in wall-clock time, confirming DGS’s efficacy in accelerating robust RL optimization.
Ablation studies highlight that removal of the explicit synergistic loop leads to catastrophic loss in personalization fidelity; understanding is a strict prerequisite to contextually aligned generation. Sync-R1’s performance remains robust across all initialization schemes, obviating costly cold-start pipelines.

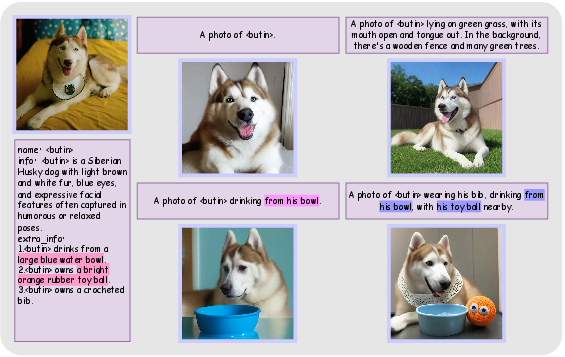
Figure 3: Qualitative visualization of concept $\langle\text{f\_h\rangle$ demonstrating fidelity and attribute reasoning.
Theoretical and Practical Implications
Sync-R1 represents a paradigm shift from latent alignment and SFT toward explicit RL-based reasoning-trajectories in unified multimodal personalization. The mutual reinforcement between understanding and generation enables higher-order concept injection, effective disambiguation, and spatial coherence in dense prompt regimes. Theoretical guarantees on gradient variance reduction and SNR amplification through DGS offer scalable sample efficiency and robust convergence.
Practically, Sync-R1 democratizes advanced personalization, enabling resource-efficient adaptation without prohibitive pre-training requirements. The explicit synergistic loop and reward ensemble provide a blueprint for future unified models seeking deep semantic grounding rather than token-level matching.
Future Directions
Potential avenues include extension to more complex modalities (audio, video, 3D), fine-grained control over synergistic weighting, and adaptation of the framework for continual personalization in dynamic user contexts. The self-improving RL paradigm may be leveraged to automate data selection and reward calibration, further scaling robust personalization across diverse domains.
Conclusion
Sync-R1 sets a new practical and theoretical benchmark for unified multimodal reasoning and generation by explicitly bridging comprehension and creation within a closed-loop RL system. The combination of Sync-GRPO and DGS achieves robust cross-task synergy, superior reasoning accuracy, and highly efficient sample utilization. These findings lay the foundation for next-generation unified personalization architectures with advanced logical and generative capabilities.

