- The paper presents MMEB-V3, a benchmark that systematically evaluates multimodal embedding models under instruction constraints across text, image, video, and audio.
- It introduces OmniSET to generate semantic equivalence tuples, diagnosing modality failures and revealing directional biases in cross-modal retrieval.
- The study highlights that current models struggle with explicit modality instructions, underscoring the need for new training strategies for robust agentic tasks.
MMEB-V3: Systematic Evaluation and Diagnostic Analysis for Omni-Modality Embedding Models
Introduction and Motivation
Multimodal embedding models are fundamental components enabling unified semantic representations across disparate modalities—such as text, images, videos, and audio—that drive information retrieval, RAG pipelines, and agentic decision-making. While prior benchmarks have focused on partial modality pairs (e.g., text–image), they do not systematically measure instruction-constrained behavior or agent-centric task requirements, a gap that MMEB-V3 aims to address. The benchmark introduces a large-scale, highly diverse suite spanning text, image, video, audio, visual documents, and structured agent tasks, enabling rigorous evaluation of embedding models under explicit modality and instruction constraints.
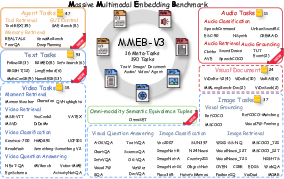
Figure 1: MMEB-V3 overview, visualizing the integration of agent tasks, complex text retrieval, audio, and semantic equivalence tuples built atop previous modality coverage.
Benchmark Design: Modalities, Task Diversity, and Diagnostic Analysis
MMEB-V3 comprises 190 tasks organized across four primary modalities—text, image, video, audio—with additional agentic and diagnostic tasks. Benchmark design emphasizes both modality coverage and diversity of retrieval operations (classification, retrieval, grounding, QA, tool, memory, and GUI retrieval). Crucially, MMEB-V3 introduces OmniSET (Omni-modality Semantic Equivalence Tuples), organizing semantically equivalent content across all modalities for controlled analysis.
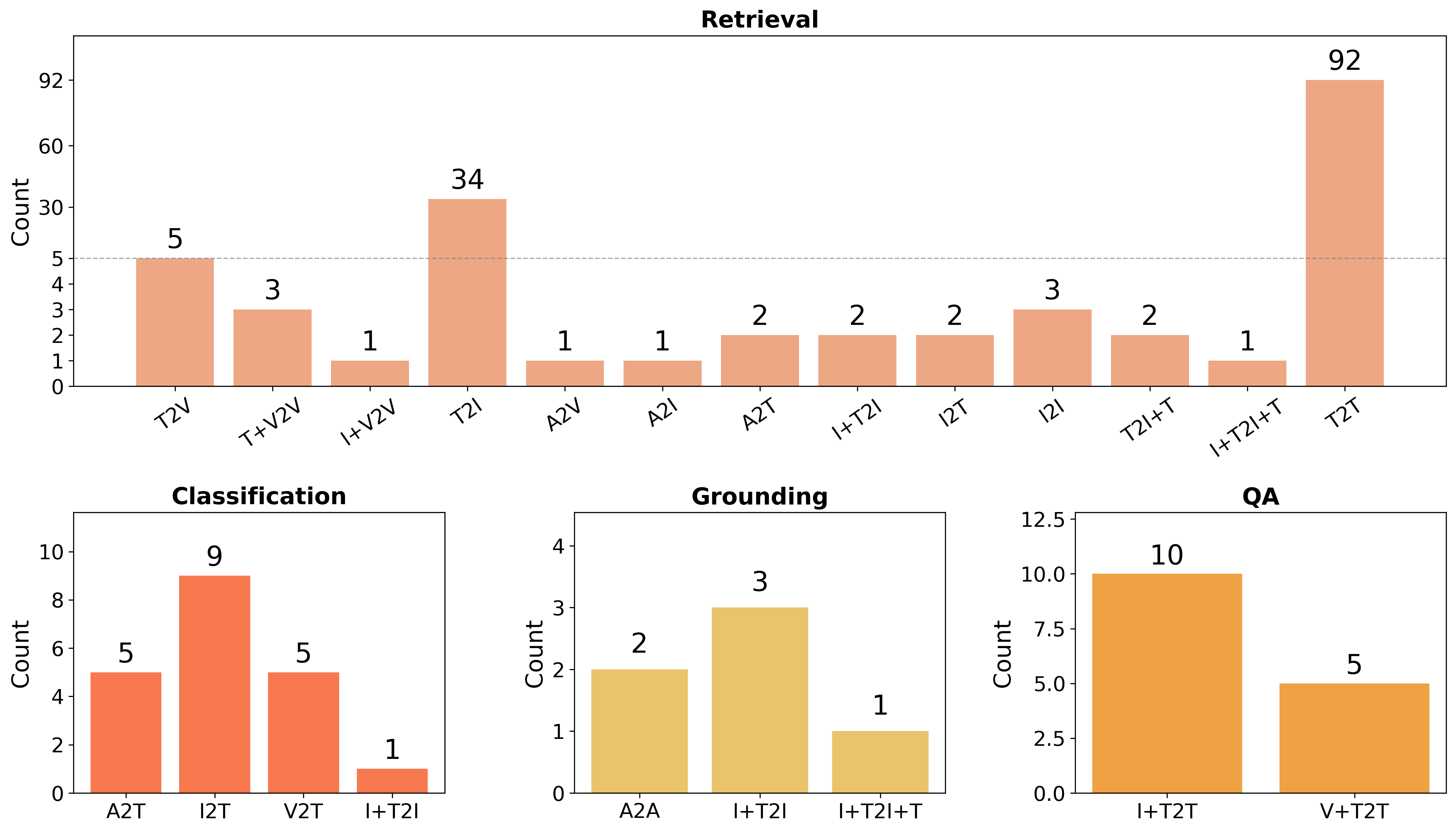

Figure 2: Distribution of modality combinations and task types in MMEB-V3, illustrating the diversity of cross-modal interactions.
The diagnostic utility of OmniSET lies in its construction of hard negatives and cross-modal tuples {xT,xI,xV,xA}, letting researchers disentangle semantic similarity from modality effects during retrieval evaluation.
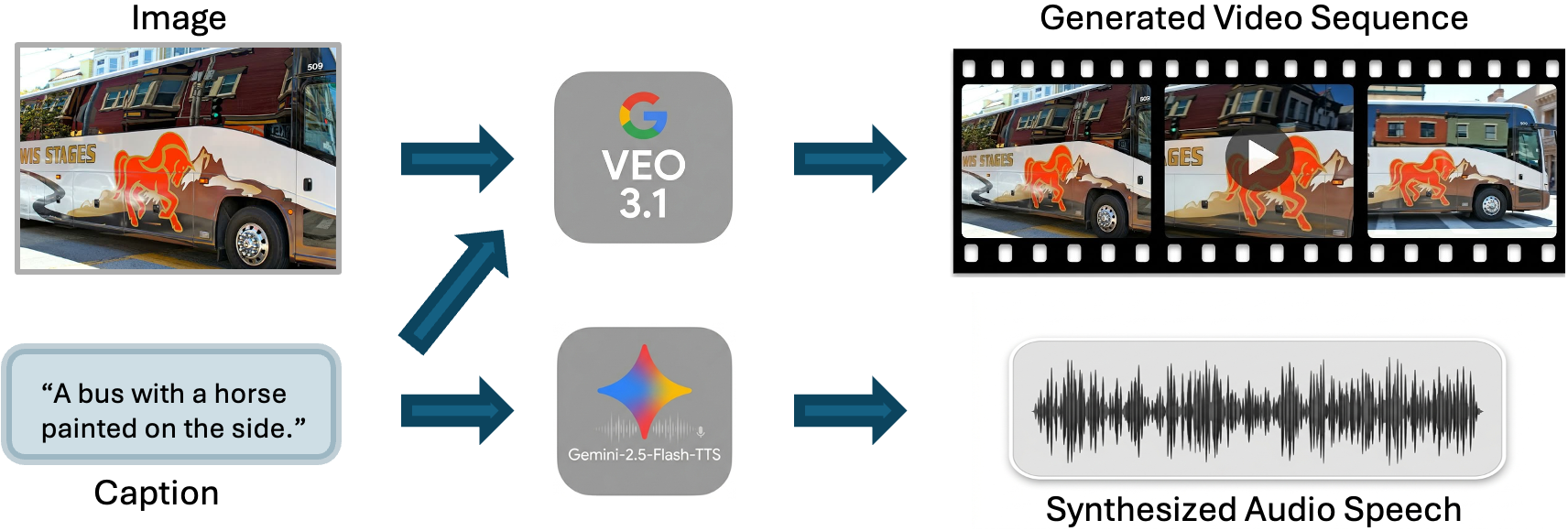
Figure 3: Construction pipeline for OmniSET illustrating generation and verification procedures for semantic equivalence across modalities.
Empirical Findings: Limitations in Instruction-Conditioned Retrieval
Systematic comparison of current embedding models—including omni-modal (Omni-Embed-Nemotron, WAVE) and vision-language (Qwen3-VL-Embedding, VLM2Vec, GME)—reveals consistent gaps:
- Modality-Aware Retrieval Failures: Models frequently fail to retrieve the intended target modality when explicit modality constraints are specified. Instead, retrieval is biased toward the query modality, leading to incorrect modality matches.
- Asymmetry and Modality Bias: Cross-modal retrieval is highly directional, with significant variance in performance across modalities (e.g., I→V is strong but V→I is weak). The dominant modality among top-10 retrieved results correlates strongly with the query modality, rather than the instructed target.
- Instruction-Induced Embedding Shifts: Models vary substantially in sensitivity to modality-constrained instructions. Some (Omni-Embed-Nemotron) exhibit large embedding shifts, while others (WAVE) are nearly invariant. However, even when shifts are substantial, they do not reliably move queries closer to the intended target modality, often increasing semantic distance instead.
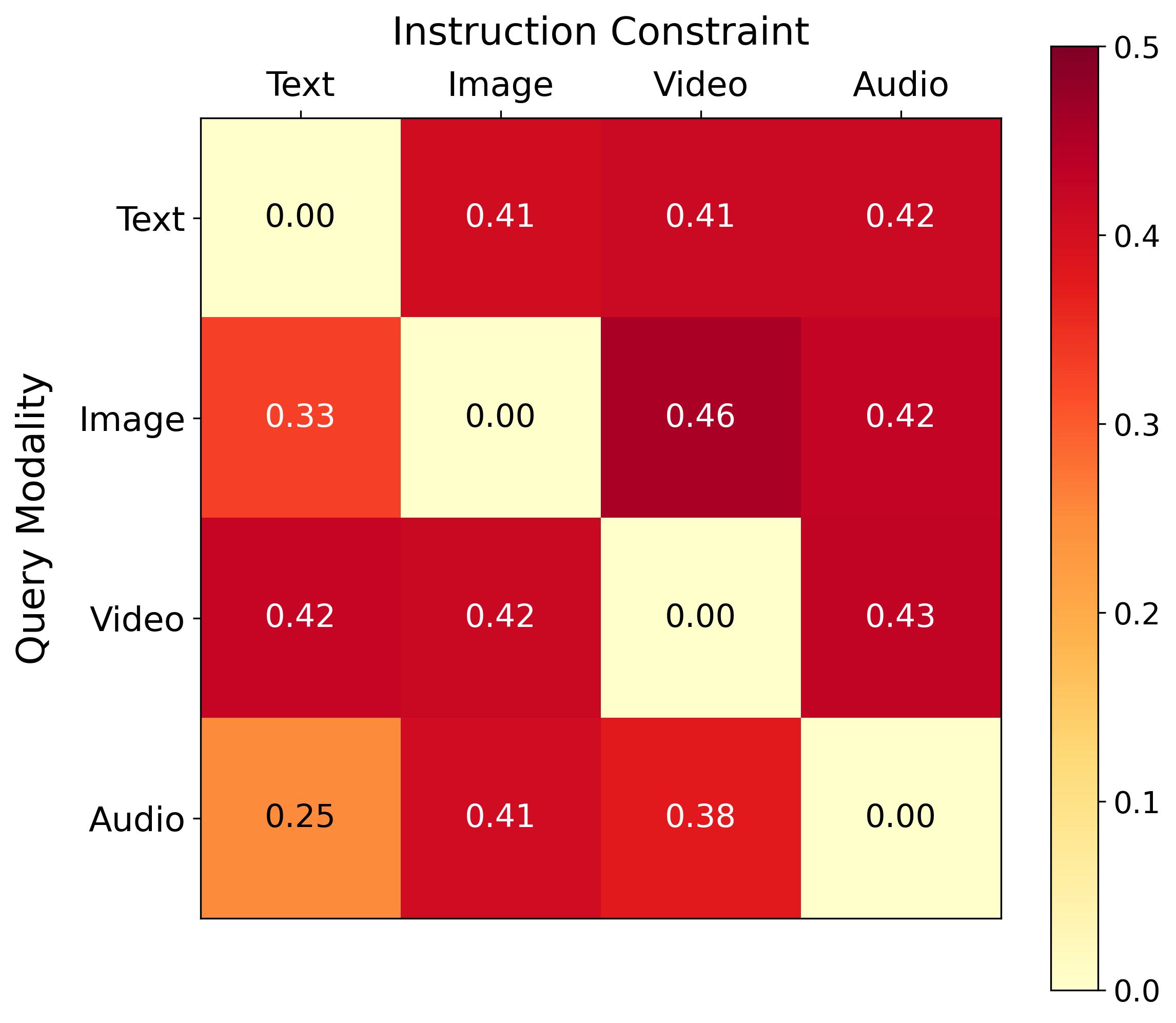
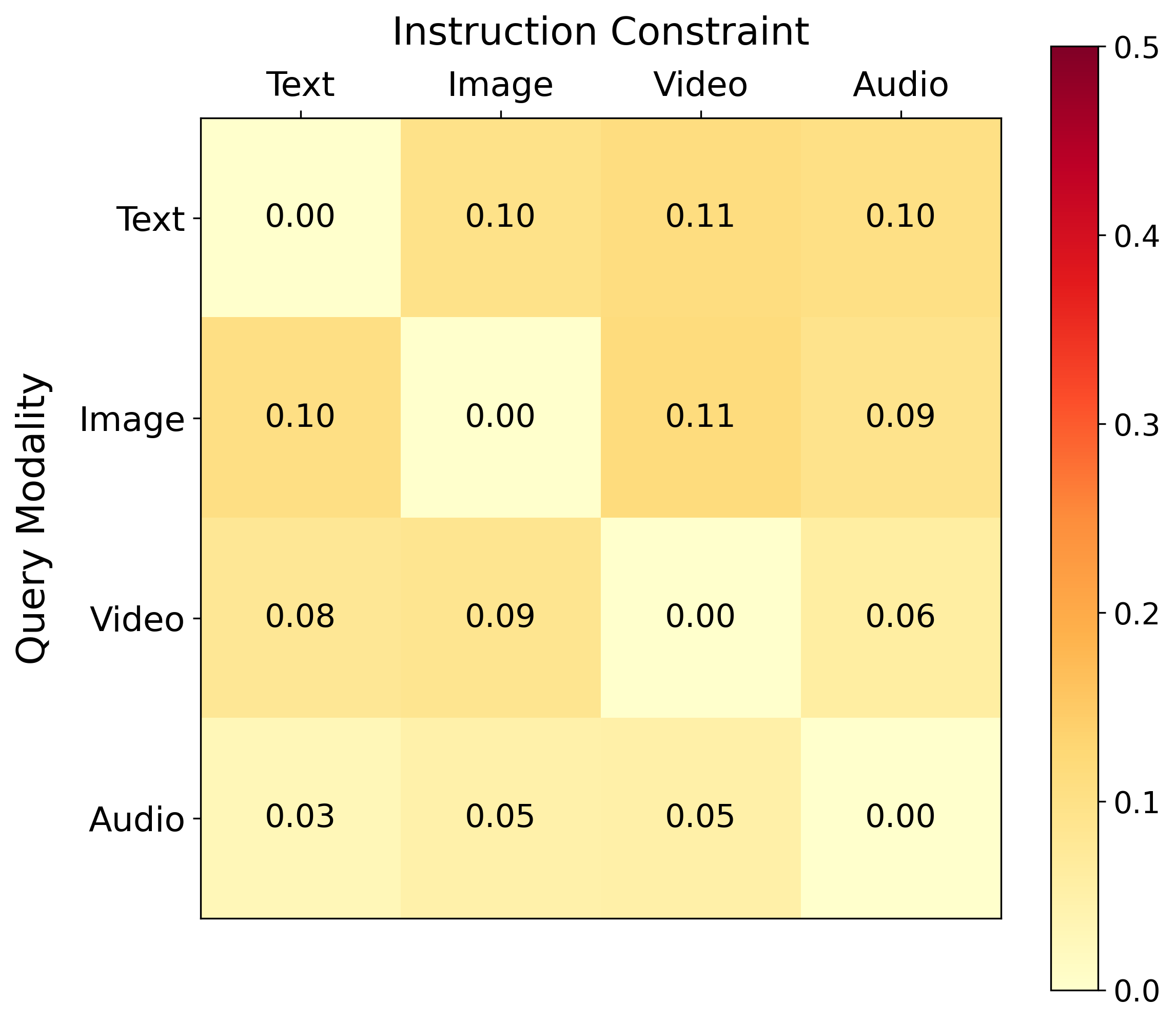
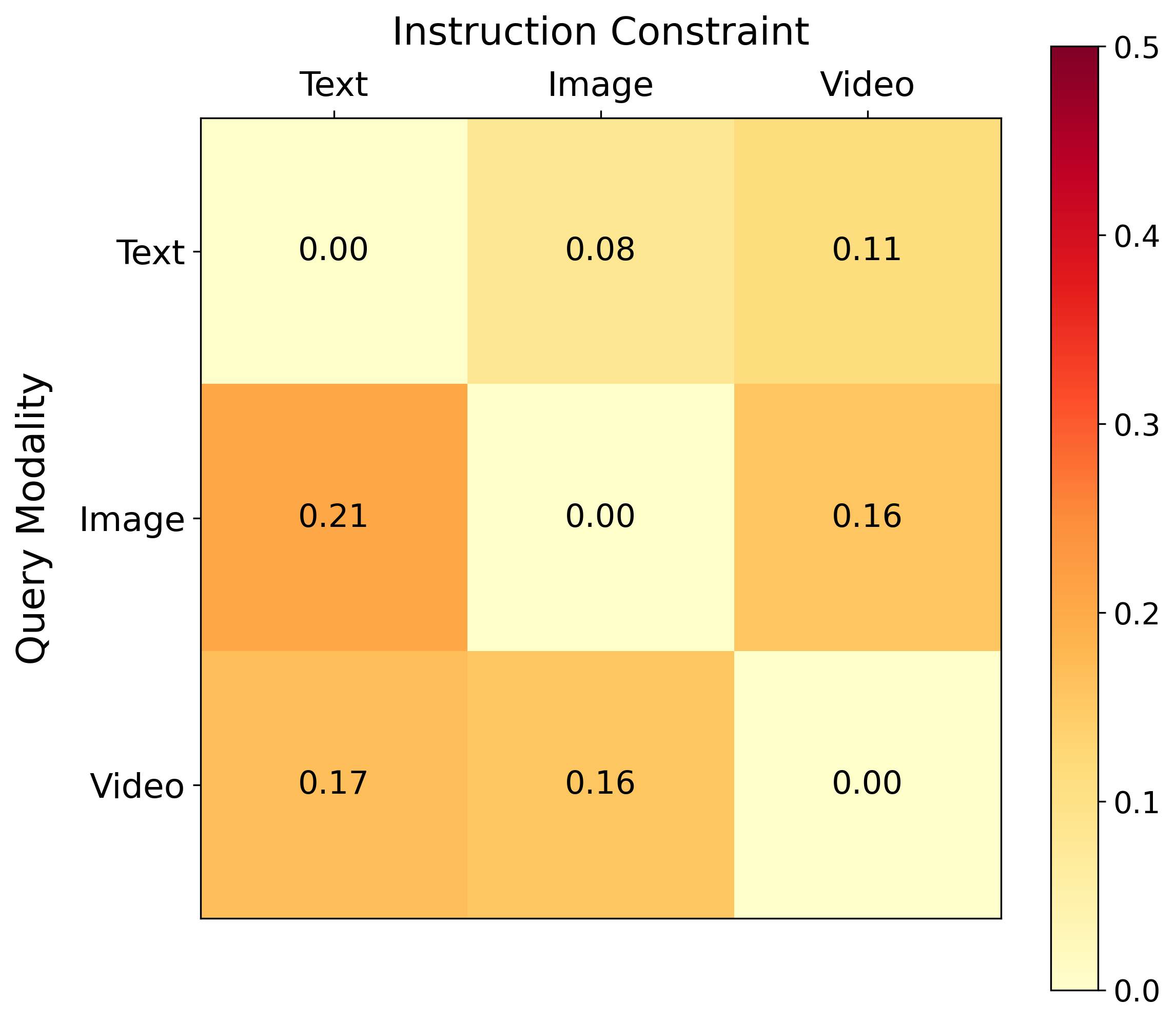
Figure 4: Visualization of the Omni-Embed-Nemotron embedding model architecture.
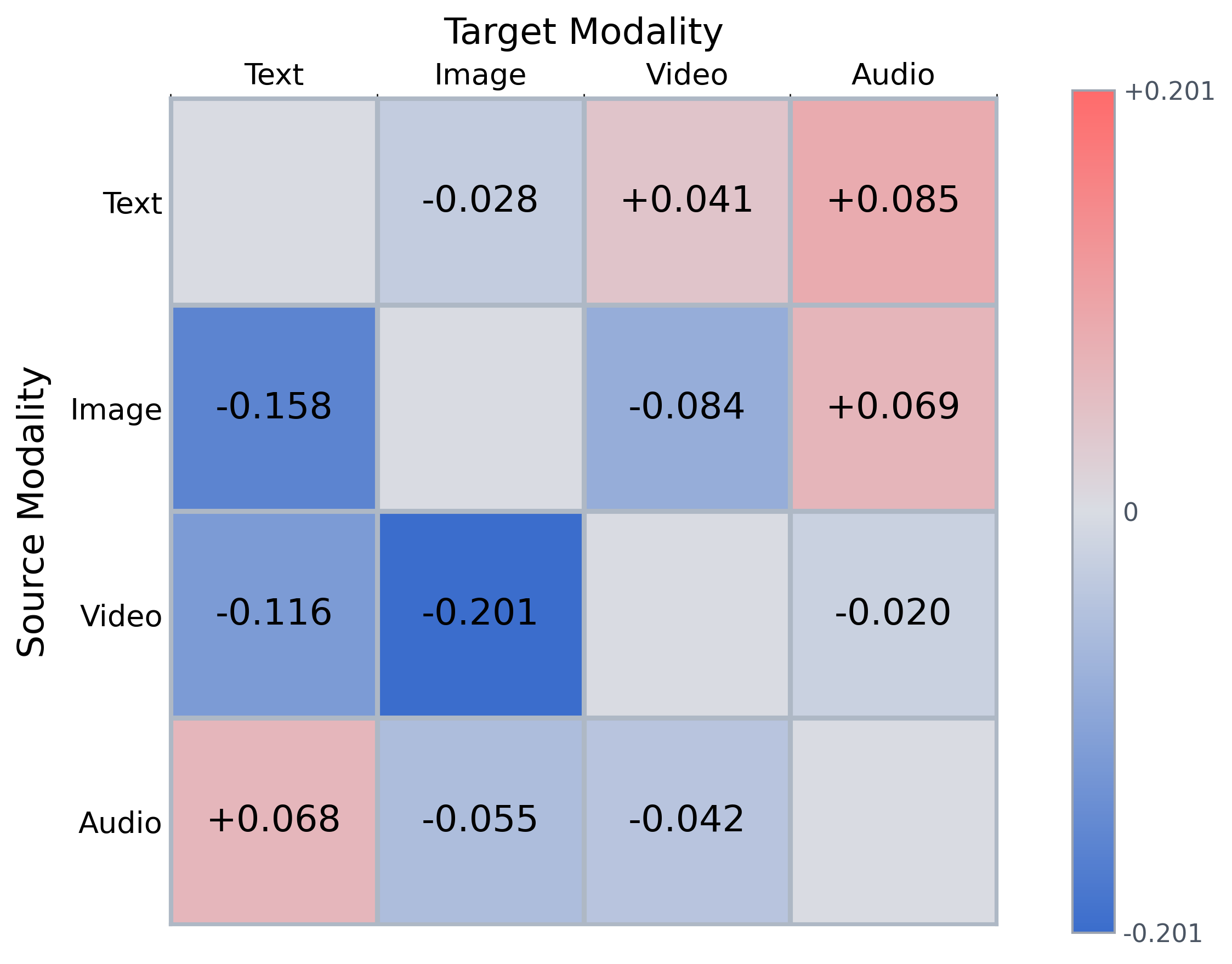
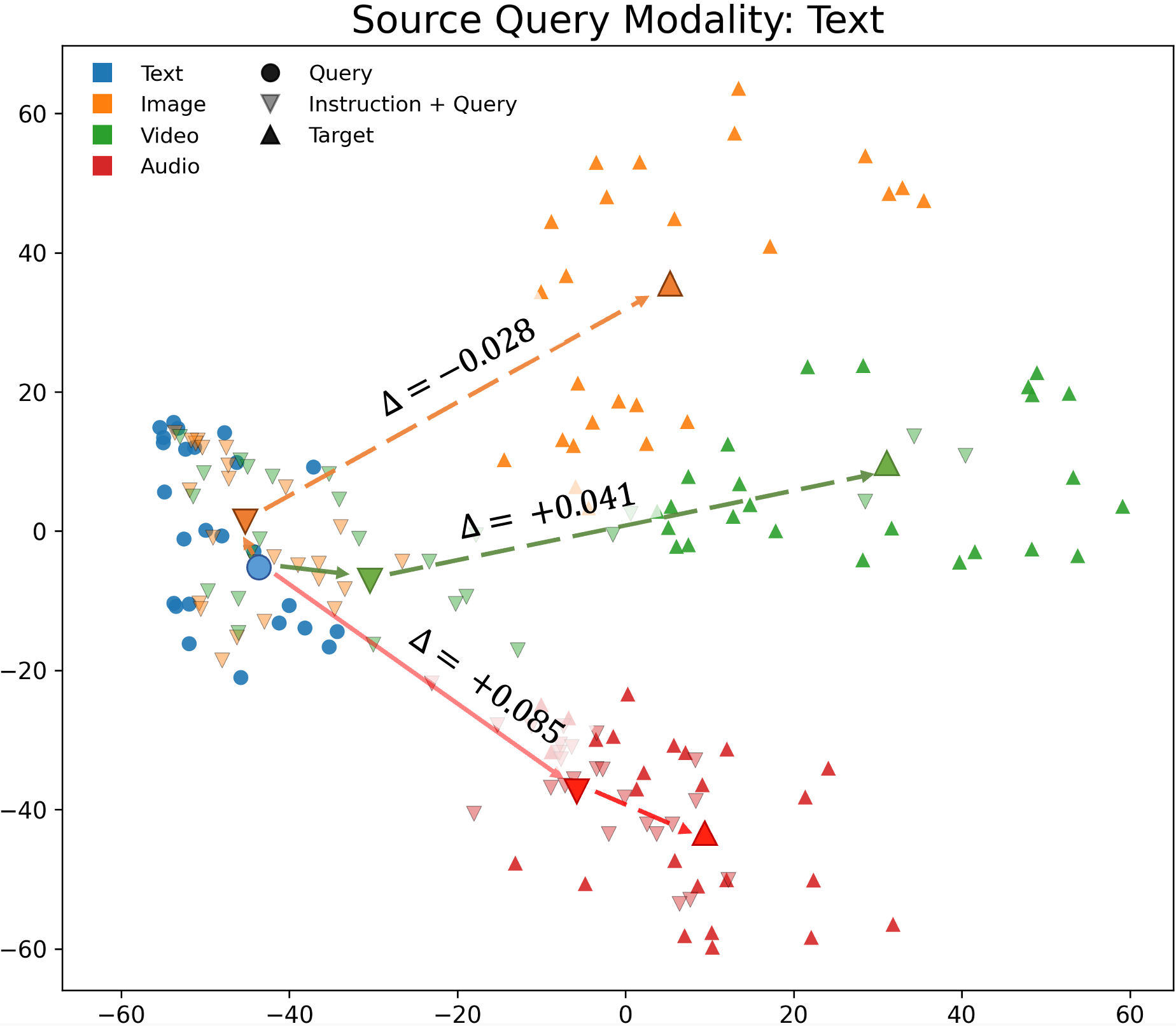
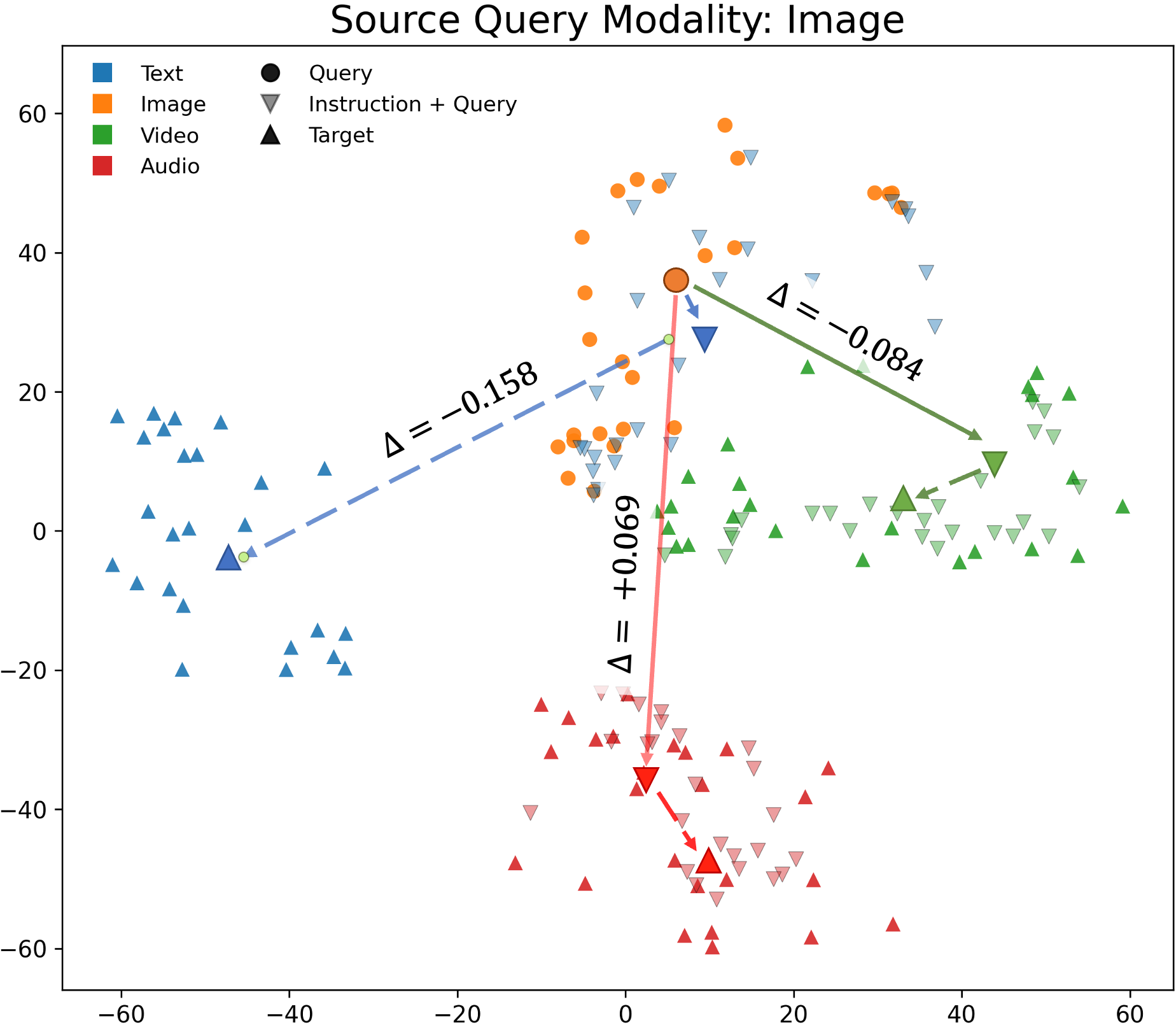
Figure 5: Heatmap illustrating instruction-induced changes in cosine distance between query and target modality for Omni-Embed-Nemotron.
Diagnostic and Qualitative Analysis
Detailed studies using OmniSET demonstrate that explicit instructions specifying target modality rarely achieve reliable retrieval. This effect is robust across evaluated directions (T→I, I→V, V→A, etc.), and the asymmetry inherent in cross-modal alignment is exacerbated by synthetic data dependencies, as video and audio instances are generated directly from image and text, respectively.
Representative examples from hard negative pools, such as “A bus with a horse printed on the side,” “A passenger train sits at a station in the dark,” and “A cat sniffing a sandwich by an apple and a phone,” further confirm model failures to enforce modality constraints in the presence of semantically close distractors.

Figure 6: Example hard negative set from OmniSET demonstrating high semantic overlap yet distinct modality.

Figure 7: Another hard negative set from OmniSET illustrating modality-specific retrieval difficulties.

Figure 8: Hard negative set showcasing fine-grained discrimination requirements in multimodal retrieval.
Agentic and Audio Task Evaluation
MMEB-V3 expands evaluation to agent tasks, including tool retrieval, GUI control, and memory retrieval—settings crucial for realistic AI agent deployment. Experiments show that models specialized in certain modalities (WAVE for audio) can attain stronger scores in their targeted domains, but lose generality and perform poorly across agent tasks. Conversely, fully multimodal models (Omni-Embed-Nemotron) provide stable—even if not optimal—performance across all categories.
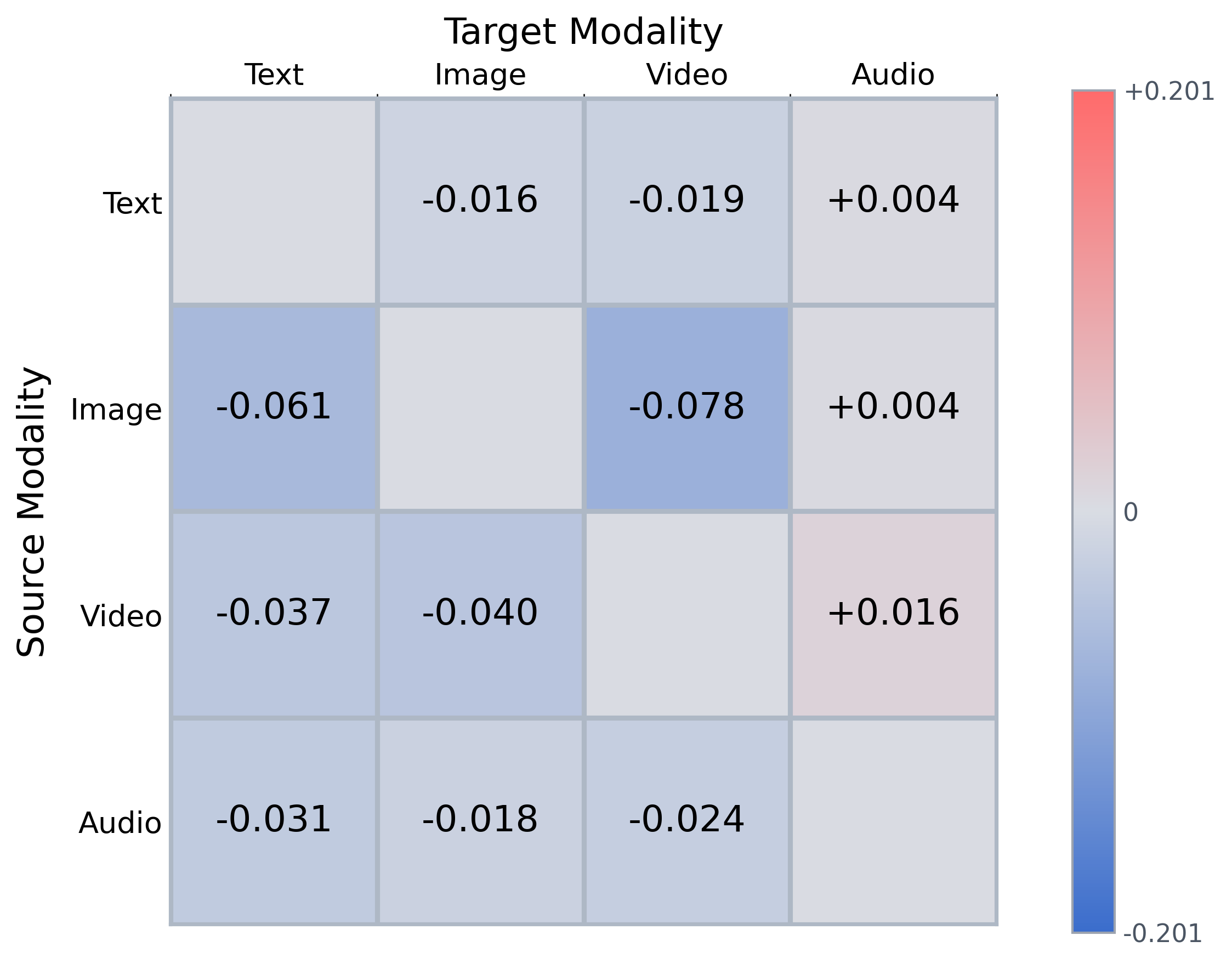
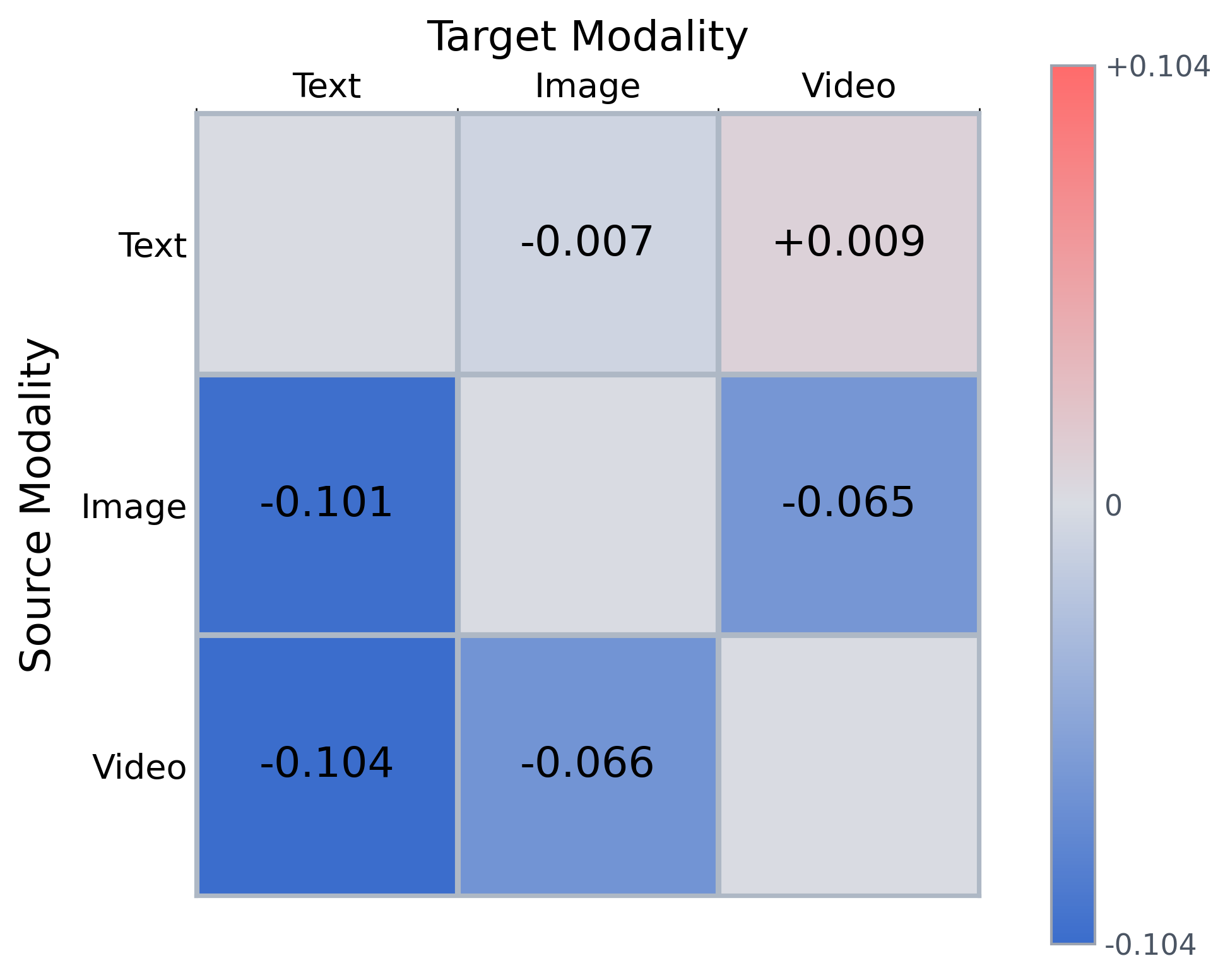
Figure 9: WAVE model overview, emphasizing unified audio-visual embedding architecture.
Embedding Space Geometry and Instruction Response
Visualization of embedding space geometry (t-SNE plots) and instruction-induced shifts across models reveals that models with well-separated modality clusters (Omni-Embed-Nemotron) can register stronger embedding changes in response to instructions, though this does not translate into effective modality-constrained retrieval. Models focused on limited modalities (WAVE) display more entangled distributions and limited responsiveness.
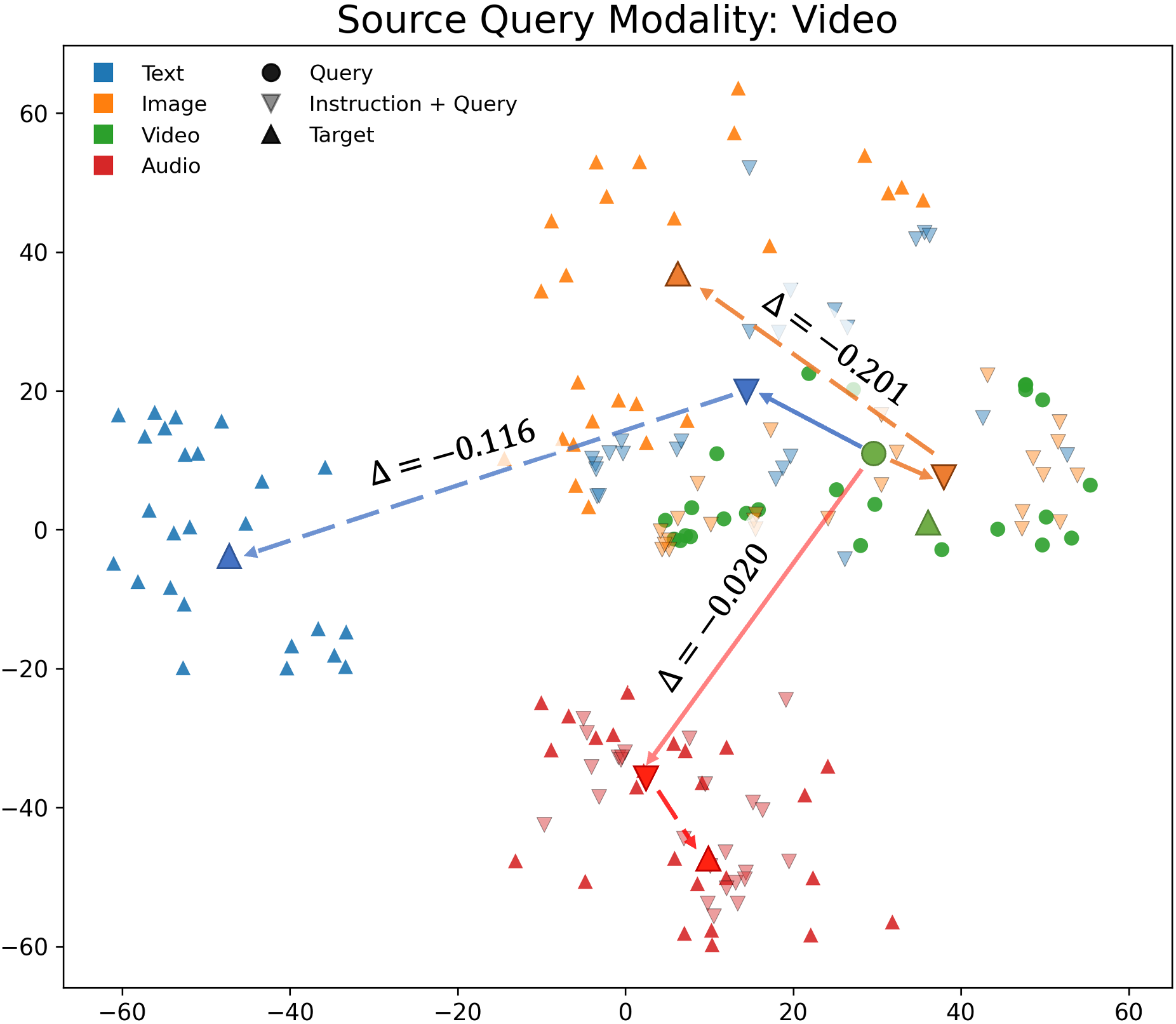
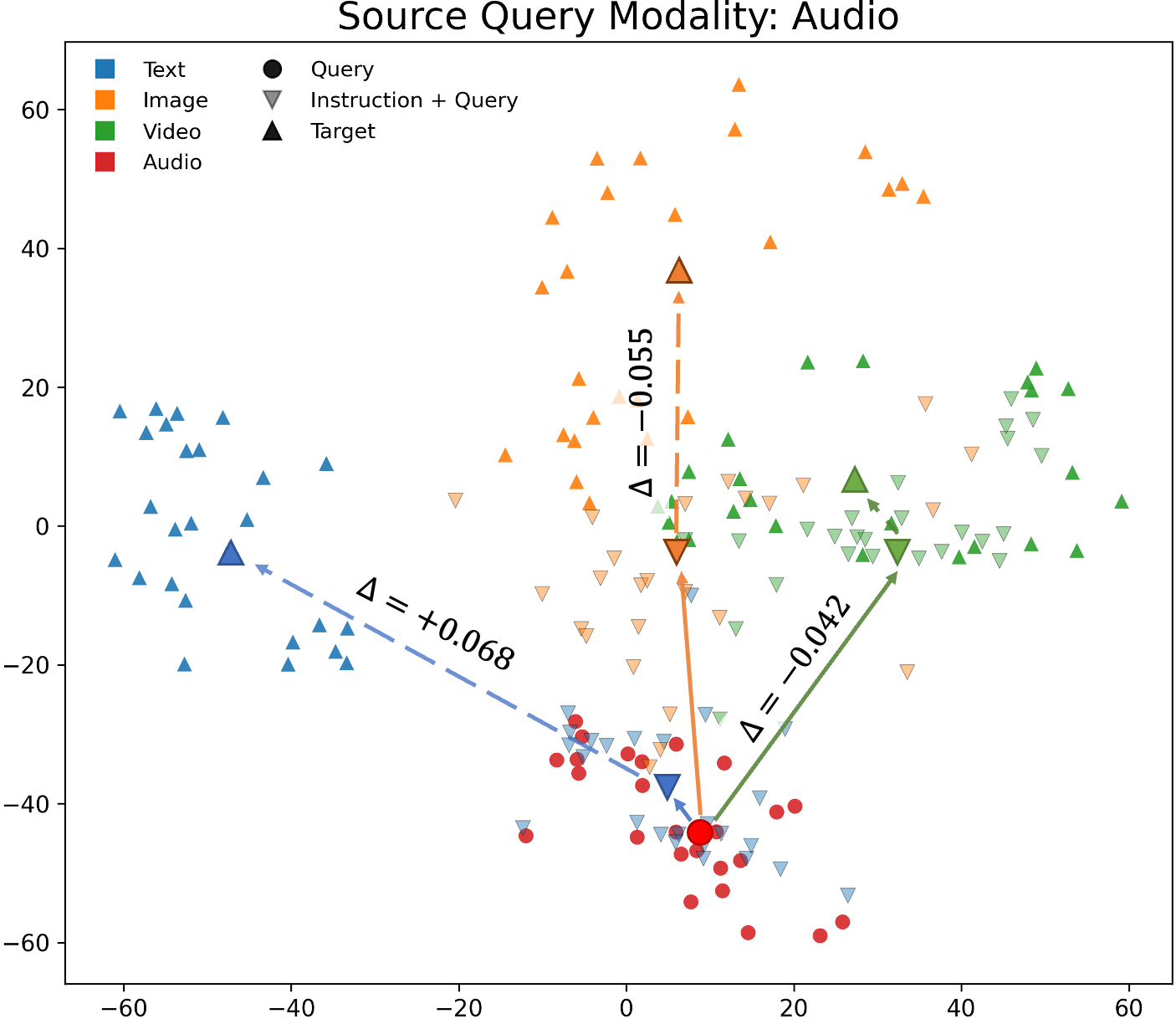
Figure 10: t-SNE visualization for video queries, showing instruction-induced shifts relative to modality clusters.
Implications and Future Research Directions
The analysis provided by MMEB-V3 elucidates several critical implications:
- Practical: In agentic and RAG workflows, embedding model failures to enforce modality constraints can induce cascading errors in tool invocation, GUI manipulation, or memory access, degrading system reliability.
- Theoretical: The results highlight limitations of current contrastive and instruction-finetuning objectives for multimodal embedding alignment. There is a need for new training strategies that directly optimize cross-modal targets under explicit instruction constraints, possibly incorporating stronger modality disentanglement and robust negative sampling.
- Research Trajectory: Future developments should address instruction-conditioned modality enforcement, explicitly tackle directional cross-modal alignment, and integrate more human-annotated multi-modal data or ablation studies separating synthetic and real pairs.
Conclusion
MMEB-V3 provides a comprehensive testbed for multimodal embedding models, systematically diagnosing instruction-conditioned failures and cross-modal asymmetry. Despite advances in unified embedding architectures, current models are not reliably modality-aware under instruction constraints. The benchmark and diagnostic analysis underscore the need for principled approaches to controllable omni-modality embeddings, particularly as AI agents and RAG pipelines increasingly depend on robust cross-modal retrieval and agentic memory utilization (2604.23321).

