- The paper introduces RoutIR, a Python-based service that dynamically composes and serves retrieval pipelines for RAG applications.
- It leverages asynchronous batching, caching, and modular pipeline orchestration to optimize throughput and reduce query latency.
- Experimental results demonstrate high query throughput and efficient resource management, validating its effectiveness in real-world RAG scenarios.
RoutIR: Fast Serving of Retrieval Pipelines for RAG Systems
Introduction
Retrieval-Augmented Generation (RAG) systems constitute an integral part of modern information retrieval, where LLMs generate queries, process retrieved documents, and synthesize responses. However, serving dynamic and complex RAG pipelines online with state-of-the-art retrieval models presents considerable engineering and architectural challenges, particularly as most academic IR platforms and toolkits are built around the static, batch-centric Cranfield paradigm. The paper "RoutIR: Fast Serving of Retrieval Pipelines for Retrieval-Augmented Generation" (2601.10644) introduces RoutIR, a lightweight, extensible, and efficient Python package for wrapping, composing, and serving arbitrary IR pipelines via a flexible HTTP API, enabling seamless integration into contemporary RAG workflows.
System Architecture and Design Principles
RoutIR is fundamentally a service layer designed to mitigate the disconnect between advanced retrieval model development and their deployment as online, query-efficient services. Its architecture emphasizes modularity, extensibility, and resource efficiency while maintaining minimal dependencies beyond Python and model-specific packages. The core abstractions in RoutIR are Engines, Processors, and Pipelines:
- Engines encapsulate retrieval models (e.g., dense, sparse, rerankers) and expose a unified interface for querying and integration.
- Processors wrap Engines, handling asynchronous batching and robust caching (in-memory or Redis), thus maximizing throughput and ensuring reproducibility.
- Pipelines allow users to dynamically compose Engines into complex, multi-stage retrieval-operational graphs, specified at query time via a minimal JSON syntax or a context-free grammar.
The HTTP API exposes these capabilities without requiring any client-side dependencies, allowing integration with any downstream RAG library or orchestration system.
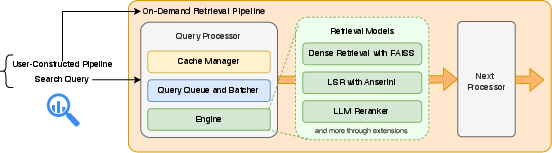
Figure 1: RoutIR service architecture—user HTTP requests specify retrieval pipelines and queries, which RoutIR orchestrates, leveraging per-processor queuing, caching, and pipeline coordination for both sequential and parallel workflows.
Notably, RoutIR supports the unification and orchestration of disparate computational resources through Relay Engines, delegating requests to remote RoutIR instances—an essential capability for cluster-based and distributed research environments.
Online Serving and Throughput Optimization
Conventional IR toolkits, e.g., PyTerrier [PyTerrier], Anserini [anserini], and BEIR [thakur2021beirheterogenousbenchmarkzeroshot], target offline experimentation and lack online API exposure and asynchronous query batching. RoutIR addresses the throughput and latency requirements of online RAG with native support for:
- Asynchronous query batching: Queries are accumulated and dispatched jointly, optimizing hardware utilization (especially for bi-encoder/cross-encoder GPU inference) and delivering high throughput under concurrent loads.
- Result caching: Prevents redundant computation for repeated queries, critical in looped/feedback-based RAG pipelines.
Empirical evaluations on TREC NeuCLIR MLIR (76 queries, 10M documents) using three contrasting models—a multi-vector dense retriever (PLAID-X), learned sparse retriever (MILCO+Anserini), and a dense FAISS-based retriever (Qwen3)—demonstrate robust batched throughput (NLIR: up to 9.6 queries/sec), strong sequential latency, and ease of pipeline composition. For example, Qwen3 yielded 0.430 nDCG@20, 9.6 queries/sec throughput, and 1.23 sec/query latency. Batched processing consistently delivered higher aggregate throughput than sequential querying, a crucial attribute for scalable RAG serving.
Dynamic Pipeline Construction and Integration
One of RoutIR's distinctive contributions is its user-facing, on-the-fly pipeline specification. The pipeline is described using an expressive string-based DSL supporting composition, parallelization, result fusion (e.g., reciprocal rank fusion), and sequential reranking. For example:
1
2
3
4
5
|
{
"pipeline": "{qwen3-neuclir,plaidx-neuclir}RRF%50>>rank1",
"collection": "neuclir",
"query": "where is Taiwan"
} |
This pipeline fuses the results of Qwen3 and PLAID-X via reciprocal rank fusion, limits candidates, and reranks with Rank1. Pipelines are instantiated dynamically per request, supporting adaptive behaviors, runtime constraint management, and even LLM-driven agentic workflows.
RoutIR natively supports a variety of built-in Engines but is designed to easily integrate arbitrary backends (e.g., Anserini, Pyserini, FAISS, in-house models) by subclassing the Engine interface and implementing batch query methods. Integration with toolkits is illustrated via succinct code snippets, and custom engines can be loaded via straightforward JSON configuration and import mechanisms.
Real-World Utility and Deployment in RAG Research
RoutIR's architecture has been validated through deployment in high-scale, multi-researcher settings. At the JHU SCALE 2025 workshop, RoutIR concurrently served PLAID-X, SPLADE-v3, and Qwen3 over multiple TREC collections using modest hardware (NVIDIA TITAN RTXs), achieving practical query latency for both cached and uncached scenarios. Furthermore, RoutIR powered the TREC RAGTIME track endpoint, supporting CPU-backed retrieval at sub-second latencies across large-scale document sets.
Its minimalistic REST API, asynchronous serving, and rich pipeline language enable direct integration into state-of-the-art RAG orchestration frameworks such as GPT Researcher [Elovic_gpt-researcher_2023]. Only trivial code is needed to use RoutIR as the retrieval layer for agent-driven, iterative, or multi-agent generative architectures.
Academic IR frameworks, including Galago, Indri, Patapsco, Terrier, PyTerrier, Anserini, Capreolus, OpenNIR, Tevatron, and MTEB, excel at batch experimentation but are limited for dynamic, generation-driven, or agentic retrieval. They often focus on static, benchmark-oriented offline evaluation and seldom provide web APIs for integration with external generation modules. By contrast, production search systems (ElasticSearch, Vespa, OpenSearch) expose robust HTTP interfaces but are inflexible, deeply tied to their indexing architectures, and less suitable for rapid academic prototyping or method extension.
RoutIR bridges this gap by providing research-grade flexibility, extensibility for novel models, and first-class support for online, multi-stage, agent-driven RAG workflows.
Implications and Future Directions
Practically, RoutIR reduces engineering friction in embedding retrieval into complex RAG system pipelines, supports rapid prototyping of retrieval architectures, and enables comparative evaluation in fully dynamic, agentic scenarios—a growing necessity for LLM-centric IR research. Theoretically, its extensibility and pipeline abstraction provide a foundation for research into optimal pipeline design, adaptive workflow generation, and end-to-end learning over retrieval and generation modules.
The paper indicates several avenues for near-term development, including deeper LLM reranker integration, standardized model context protocol interfaces, and more sophisticated resource management strategies. The open-source nature of RoutIR and its performance characteristics position it as a backbone infrastructure candidate for RAG and LLM research ecosystems.
Conclusion
RoutIR (2601.10644) operationalizes the fast, robust, and modular online serving of arbitrary retrieval pipelines for RAG applications. Its architecture addresses the limitations of both academic and production IR platforms, offering an extensible interface for arbitrary model composition, efficient asynchronous serving, and seamless integration with advanced RAG orchestration systems. Experimental results validate its efficacy and resource efficiency in high-volume, real-world retrieval scenarios. RoutIR's public availability and continuous development are poised to accelerate progress in both experimental IR and real-world retrieval-augmented generation system design.