- The paper presents a novel latent measure learning framework that utilizes normalizing flows to effectively parameterize multiscale stochastic models.
- It introduces a scalable inference method by employing Monte Carlo-based gradient optimization and Bayesian variational techniques to quantify uncertainty.
- Empirical results demonstrate significantly improved drift recovery and generalization for partially observed slow dynamics in synthetic multiscale systems.
Learning Stochastic Multiscale Models through Normalizing Flows
Multiscale Stochastic Systems: Model Reduction and Inference
The paper addresses inference for multiscale stochastic dynamical systems characterized by coupled slow-fast SDEs. The slow component X(n) evolves under drift and diffusion modulated by latent fast variables Y(n). Statistical learning is challenged by limited observability: only a single trajectory of the slow process is accessible, while the fast dynamics are latent and often intractable. The authors pursue a principled model reduction via stochastic averaging, leveraging scale separation to derive an effective SDE for the slow variables with averaged drift and diffusion, where the averaging is performed with respect to the unknown invariant distribution of the fast process.
Crucially, the reduced model's coefficients are characterized via conditional expectations over this invariant distribution, which is implicitly defined by a high-dimensional stationary PDE. Conventional approaches (e.g., Fokker–Planck equation-based estimation, classical SDE parameter inference) are computationally prohibitive or ill-posed in this regime. The paper re-formulates the inference problem as latent-measure learning: reconstruct the effective drift and diffusion by learning the equilibrium effect of the fast variables from partial, trajectory-level observations.
Normalizing Flow-based Latent Measure Parameterization
To overcome the infinite-dimensional inference, the authors propose parameterizing the latent invariant measure using normalizing flows. Normalizing flows provide expressive, computationally tractable parameterizations of complex distributions by transporting a simple reference law (e.g., standard Gaussian) via invertible neural networks. The pushforward measure realizes an explicit density amenable to optimization via gradient-based methods.
The estimation procedure replaces the full space of admissible invariant measures with a family of neural pushforward distributions, justified via universal approximation theorems and Wasserstein metric density results. The flow is trained to maximize a penalized likelihood induced by the reduced slow SDE, where the likelihood is computed via Monte Carlo integration over latent samples (using the flow's reparameterization trick for efficient gradient estimates).
Bayesian Variational Uncertainty Quantification
The Bayesian extension introduces a second normalizing flow to approximate the posterior over neural flow parameters, facilitating epistemic uncertainty quantification for the inferred effective dynamics. The variational posterior is trained to maximize the ELBO by nested Monte Carlo sampling, utilizing the same flow-based reparameterization for computational scalability. This formulation yields uncertainty-aware estimators for the effective drift and diffusion, allowing propagation of model uncertainty through downstream stochastic system predictions.
Theoretical Guarantees
The paper provides proof of convergence: penalized likelihood minimization over increasingly expressive flow architectures approaches the global MLE set for the latent measure, under suitable moment and Lipschitz assumptions on the drift kernel. Wasserstein convergence rates are established, and the identifiability of the effective drift (as opposed to the full latent invariant measure) is analyzed in terms of the kernel structure.
Empirical Results
Experiments are conducted on synthetic multiscale SDE systems, including particle-solvent interaction models and nonlinear double-well dynamics. The structured normalizing flow estimator exhibits superior accuracy in drift recovery relative to unstructured neural network baselines, with mean squared errors up to an order of magnitude lower for increasing scale parameters.
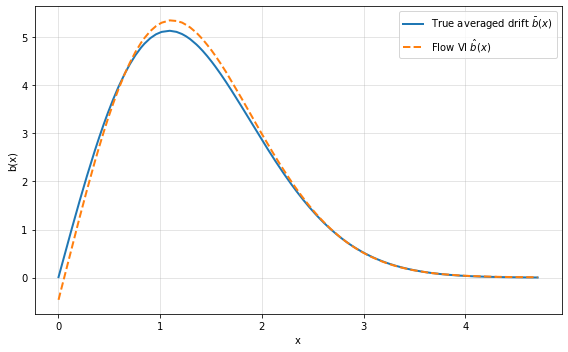
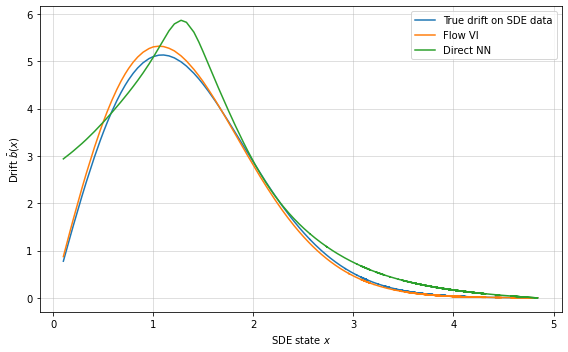
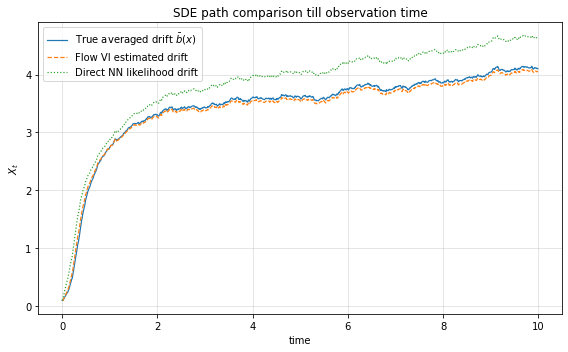
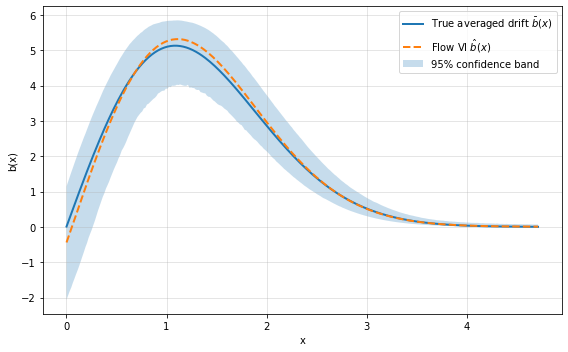
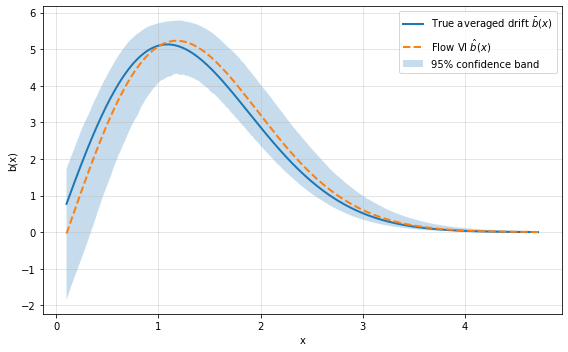
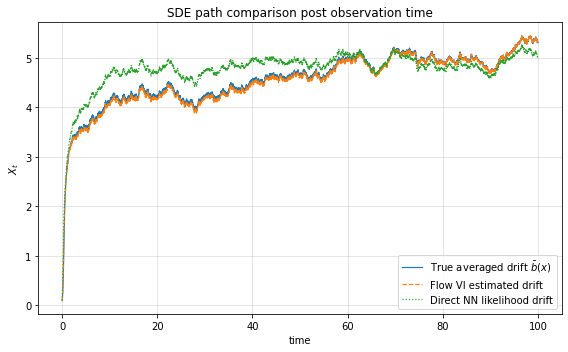
Figure 1: One-dimensional drift recovery with confidence bands, demonstrating both the accuracy and uncertainty quantification provided by the flow-based Bayesian estimator.
Furthermore, the method demonstrates excellent generalization: SDE trajectories generated by the learned averaged drift closely mimic ground truth behavior both within and beyond the observation window. These results indicate genuine learning of the underlying averaged dynamics, not mere interpolation or overfitting.
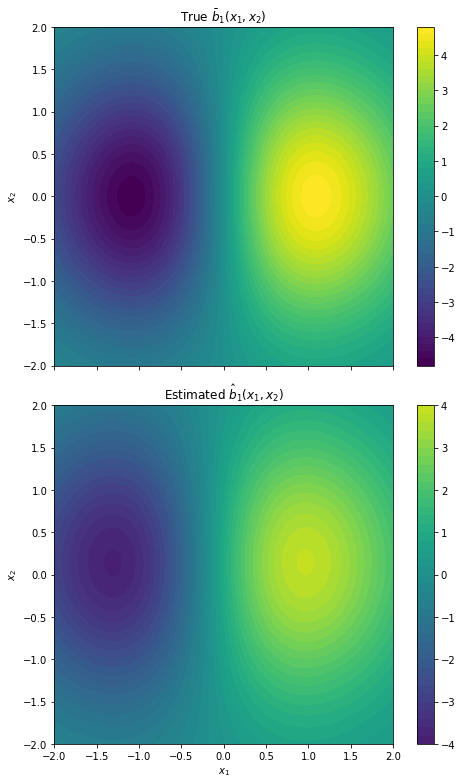
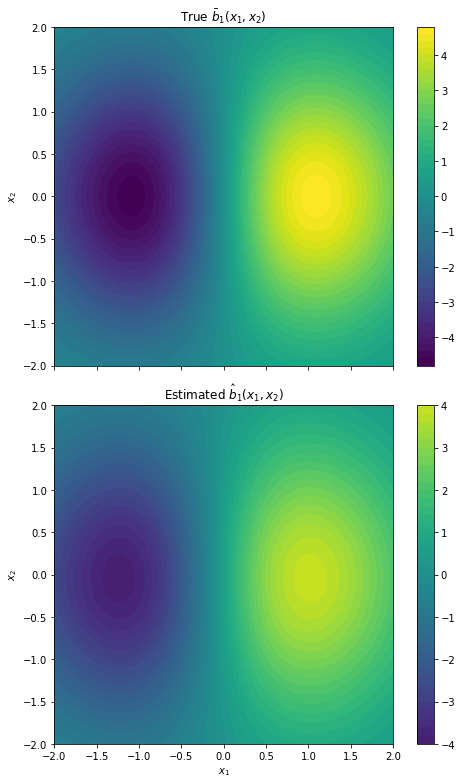
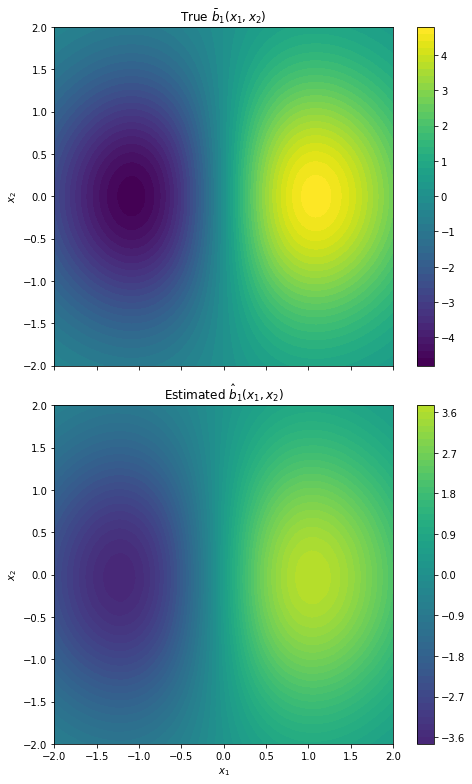
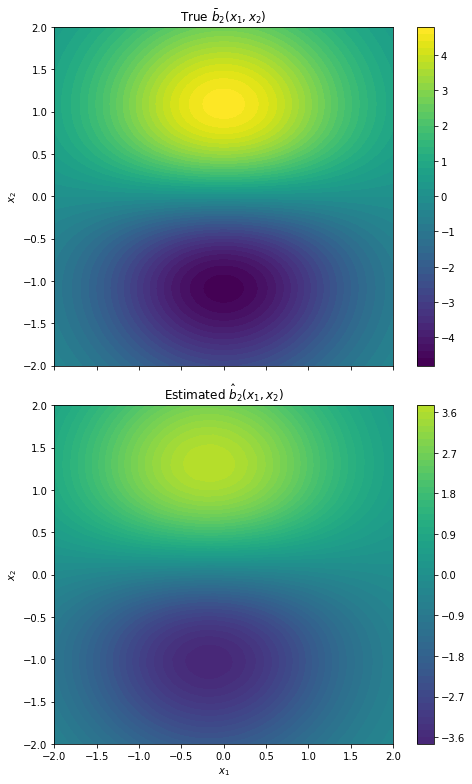
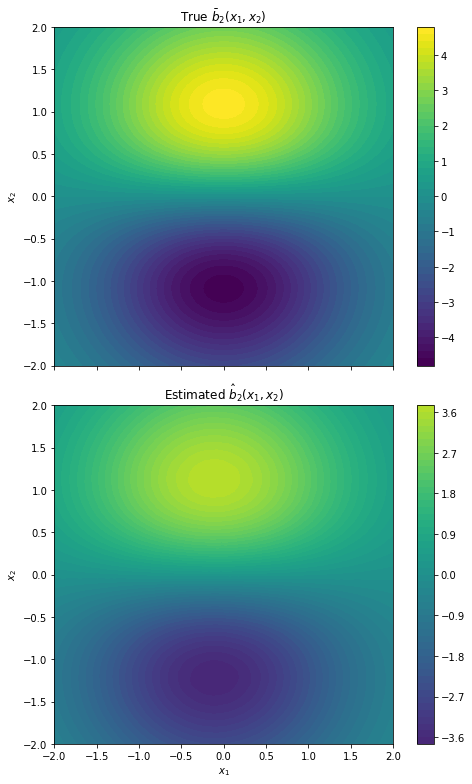
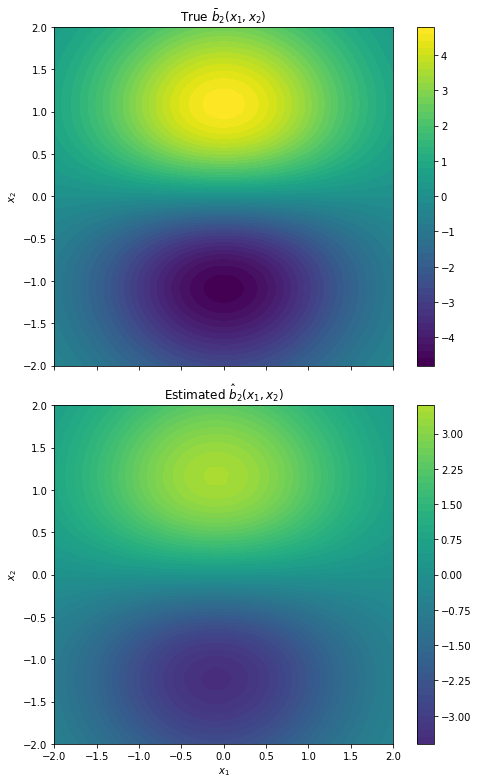
Figure 2: Two-dimensional drift recovery for b1 and b2, with improved accuracy as the scale parameter n increases.
Finite-time law comparison reveals the method's strength in reproducing not only path-level dynamics but also the probabilistic structure of the averaged system across empirical distributions.
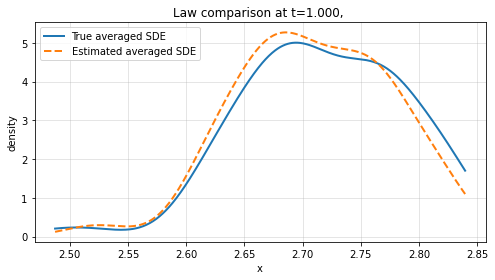
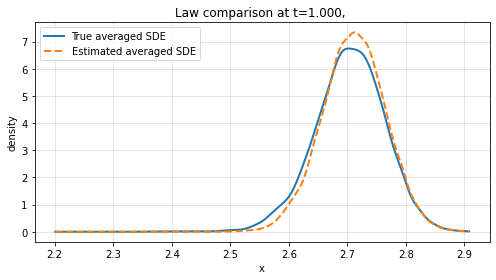
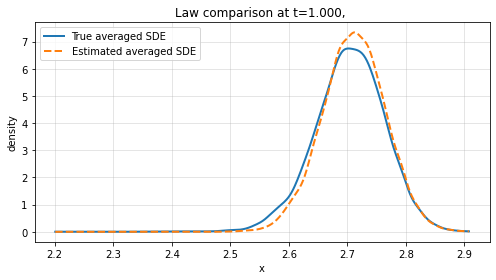
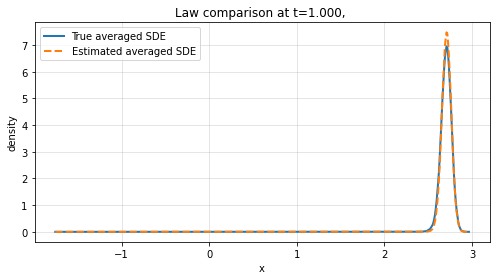
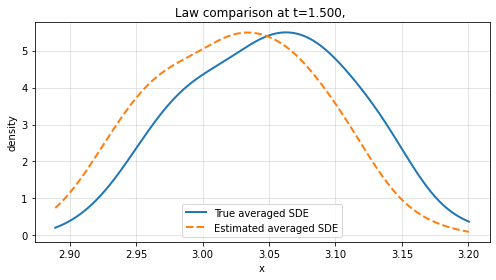
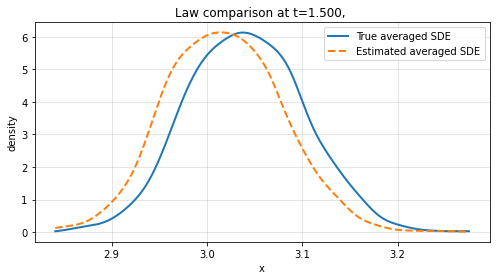
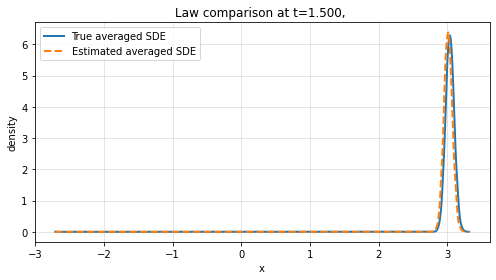
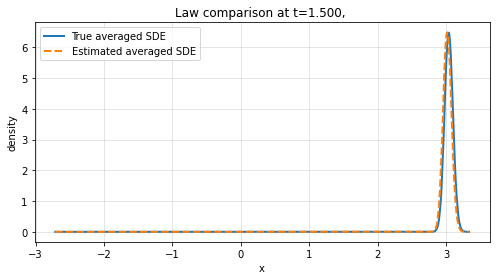
Figure 3: Law comparison at t=1 and t=1.5 for increasing sample path numbers L, showing convergence between learned and true marginal distributions.
The flow estimator precisely recovers nontrivial nonlinear averaged drifts, including double-well potentials with highly nonlinear dependence on fast variables.
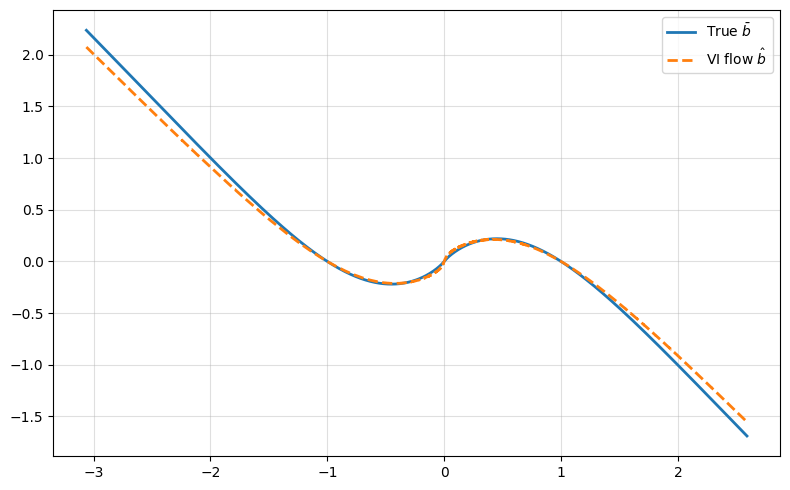
Figure 4: Comparison of the estimated drift and the true averaged drift for a nonlinear double-well model, validating the estimator’s recovery of both global and local dynamics.
Practical and Theoretical Implications
The method unifies stochastic model reduction with deep density estimation, providing a scalable trajectory-based framework for partially observed multiscale systems. It is suitable for high-dimensional latent spaces due to expressive flow architectures, supports efficient gradient-based learning, and yields uncertainty-aware predictions. The approach avoids labor-intensive grid-based PDE solvers and is robust to sparse or noisy observational regimes.
From a theoretical standpoint, the formulation builds on universal approximation properties of neural flows, advances nonparametric Bayesian inference for stochastic differential models, and supplies a concrete bridge between infinite-dimensional latent measure learning and trajectory-based statistical criteria. The methodology is extendable to more general settings, including strongly coupled slow-fast systems and discretely observed regimes.
Future Directions
Extensions could include (i) flow-based parameterization for fully coupled slow-fast systems (where fast dynamics depend explicitly on slow variables), (ii) handling sparsity and noise in observed slow variables, and (iii) incorporating continuous-time flow models (neural ODEs). The development of more expressive neural architectures and scalable Bayesian training algorithms will further broaden applicability in high-dimensional biological, physical, or engineering systems, and could impact data-driven surrogate modeling, statistical estimation, and uncertainty quantification for complex multiscale phenomena.
Conclusion
This paper delivers a mathematically principled, computationally scalable approach for learning effective dynamics in partially observed multiscale stochastic systems by parameterizing latent equilibrium couplings with normalizing flows and optimizing penalized likelihoods via Monte Carlo-based variational inference. The approach demonstrates high accuracy and uncertainty quantification in synthetic benchmarks, underpinned by theoretical guarantees of estimator convergence. The framework's modular nature and reliance on expressive density modeling suggest promising avenues for further development in both practical inference and foundational stochastic analysis (2605.09718).