- The paper introduces a scalable variational framework that approximates the backward conditional score with neural networks for joint smoothing and parameter estimation.
- The method employs a variational EM algorithm, combining neural score estimation and Monte Carlo ELBO maximization to achieve stable convergence and accurate trajectory reconstruction.
- Empirical evaluations on biochemical and physical systems demonstrate enhanced performance and reduced variance compared to traditional MCMC approaches, even with extremely sparse observations.
Variational Inference for SDE Smoothing from Sparse Data Using Dynamic Neural Flows
Introduction and Motivation
Stochastic Differential Equations (SDEs) are fundamental for modeling systems subject to intrinsic noise, especially in fields such as quantitative biology, finance, and physics. The key inferential challenge involves reconstructing both the latent state trajectories and the parameters governing these dynamics from partially observed, noisy, and usually sparse data. Classical approaches mainly discretize the state space and apply Markov Chain Monte Carlo (MCMC) or particle MCMC/particle filtering techniques, suffering from poor scalability, path degeneracy, and inefficiency in high-dimensional or low-data regimes.
The paper "Variational Smoothing and Inference for SDEs from Sparse Data with Dynamic Neural Flows" (2605.05606) introduces a scalable variational learning framework for joint smoothing and parameter estimation in partially observed nonlinear SDEs. The distinctive technical advancement is the characterization and direct neural approximation of the backward conditional score (the pathwise gradient of the log-smoothing function that solves a backward Kolmogorov equation with observation-induced jump discontinuities). This facilitates construction of a posterior SDE with an adaptive, observation-dependent drift, enabling robust variational inference directly in the path space.
Methodological Framework
Path-Space Posterior Characterization
Given discrete, noisy measurements of a latent SDE dXt=b(κ,Xt)dt+σ(Xt)dWt at timepoints {tm}, the posterior (smoothing) law of the trajectory, conditioned on all observations, is characterized as the law of a diffusion with the prior drift augmented via the spatial gradient of a time- and observation-conditional "message function" (the solution to a backward Kolmogorov PDE with multiplicative jump conditions at the observation times).
Neural Backward Conditional Score Approximation
The essential computational technique is to model the (generally intractable) conditional score as a neural network, trained to satisfy both the interval-wise PDE and the jump condition at each observation. Specifically, over each interval (tm−1,tm], a neural network hθm approximates the log-message function, with the neural parameters trained to minimize a residual sum-of-squares for both the PDE inside each interval and the jump at endpoints.
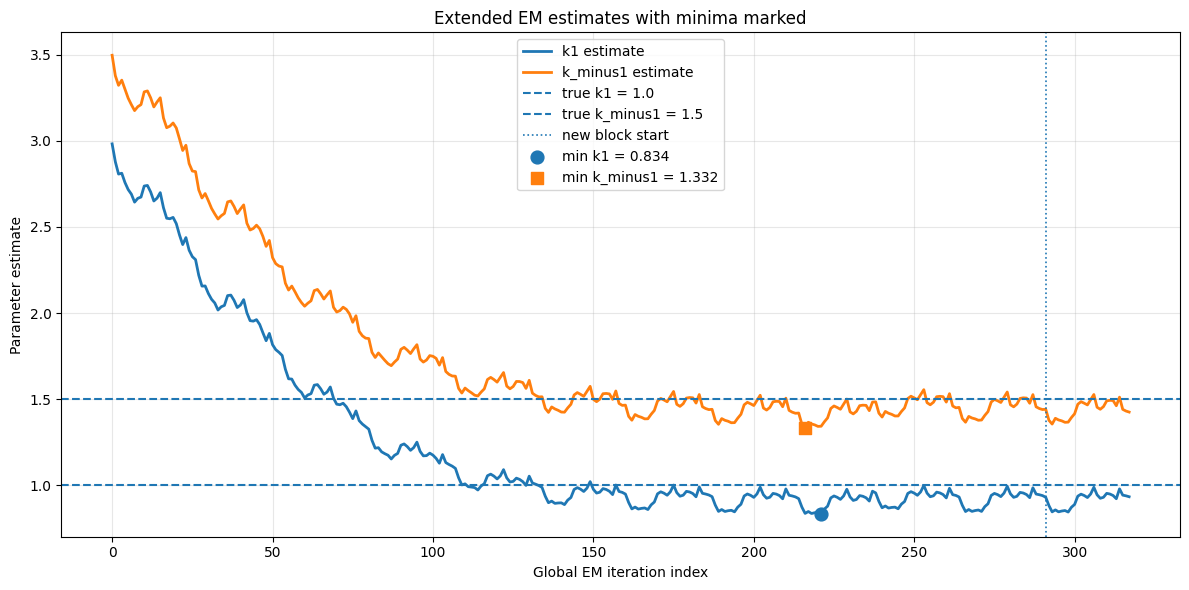
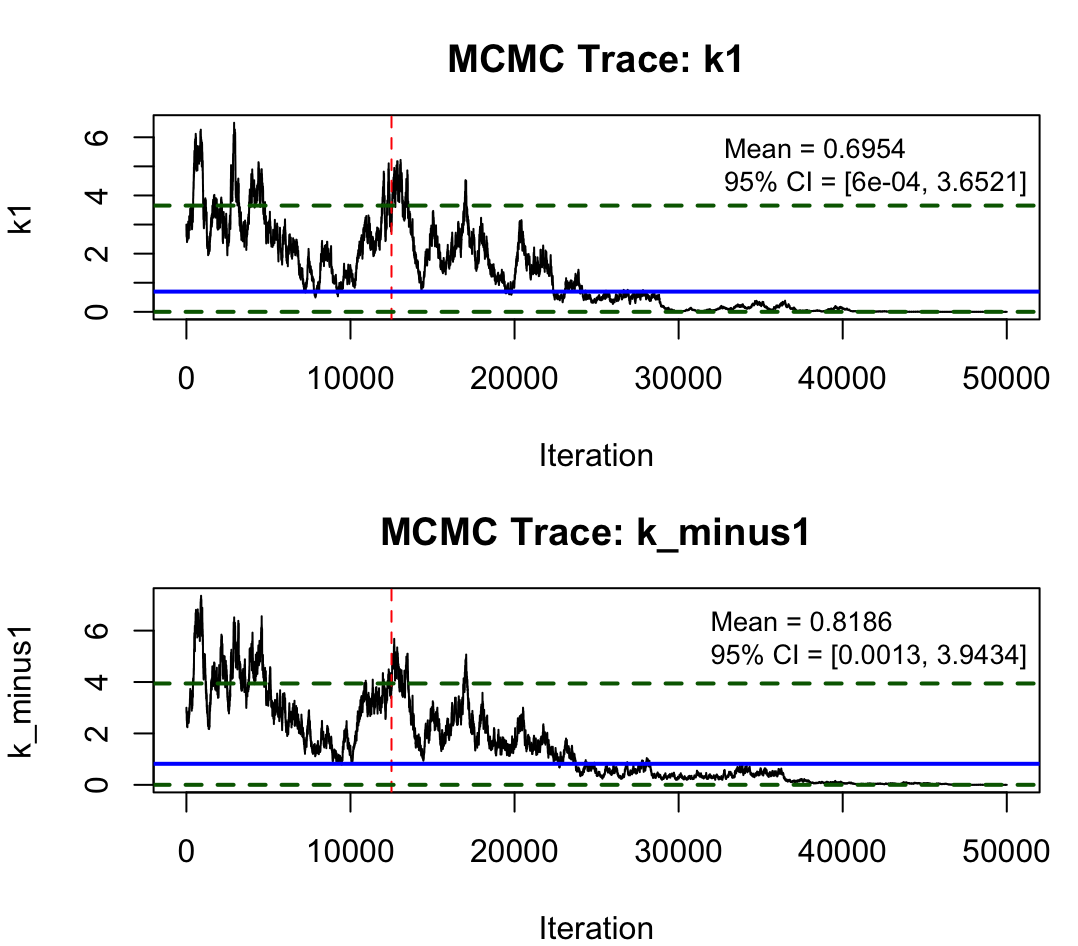
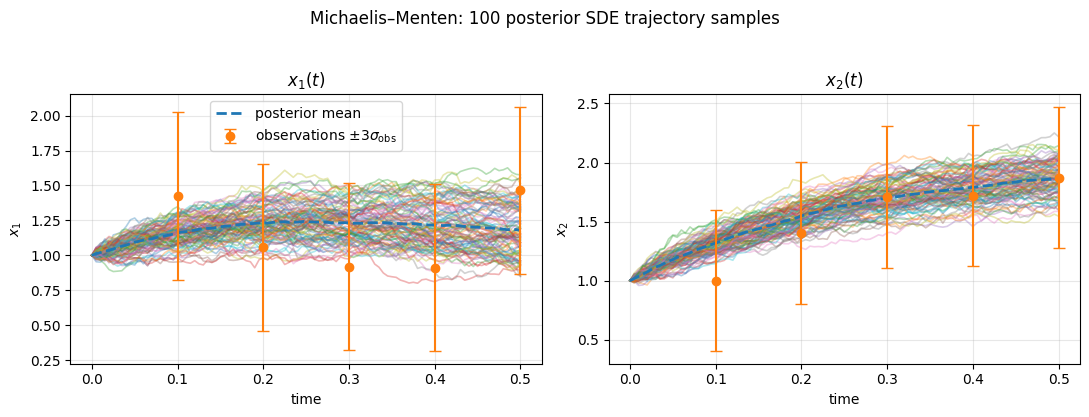
Figure 1: Illustration of the overall PINN-based method, enforcing both the continuous-time PDE and discrete-time jump conditions on the score network family across observation intervals.
Variational EM Algorithm
Parameter learning proceeds via a variational Expectation-Maximization (EM) procedure:
- E-step: For fixed parameters, the neural networks are optimized to approximate the conditional score and, hence, the smoothing distribution.
- M-step: Samples from the induced posterior SDE are used to compute a Monte Carlo Evidence Lower Bound (ELBO), and the parameters κ are updated to maximize this objective, leveraging automatic differentiation for efficient gradient computation.
This approach avoids the primary pitfalls of discretize-then-condition MCMC regimes by performing variational inference with respect to the actual path-space smoothing law, leading to greater numerical stability and efficiency.
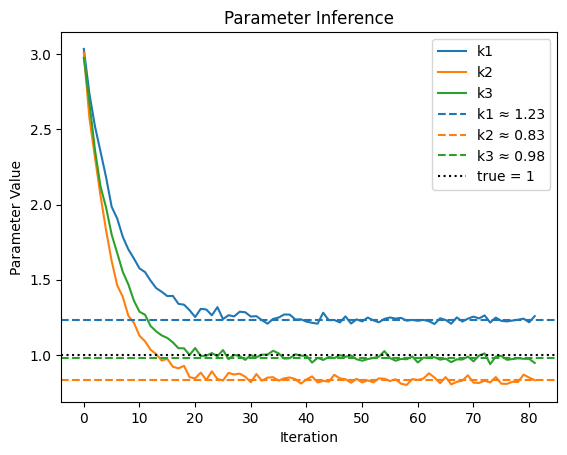
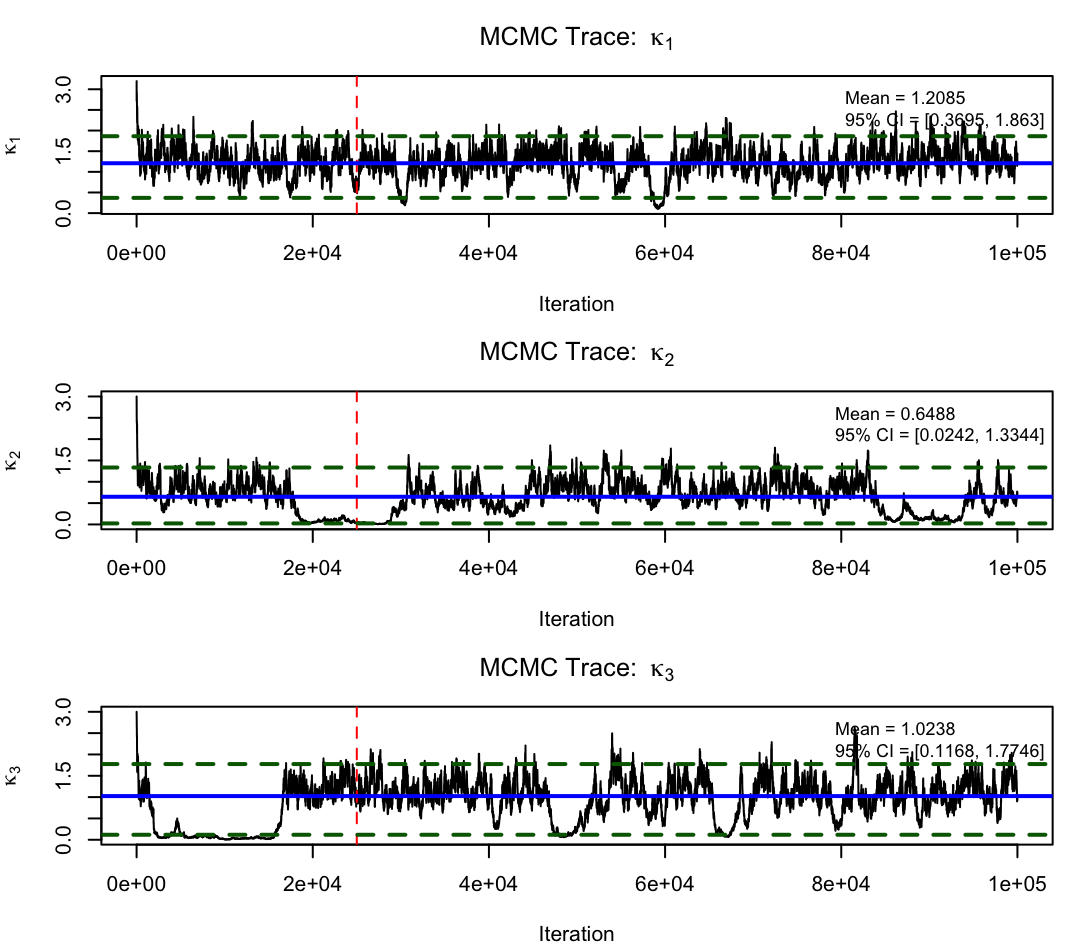
Figure 2: The entire proposed method pipeline, encompassing the neural score learning, SDE trajectory sampling, and parameter ELBO maximization.
Empirical Evaluation
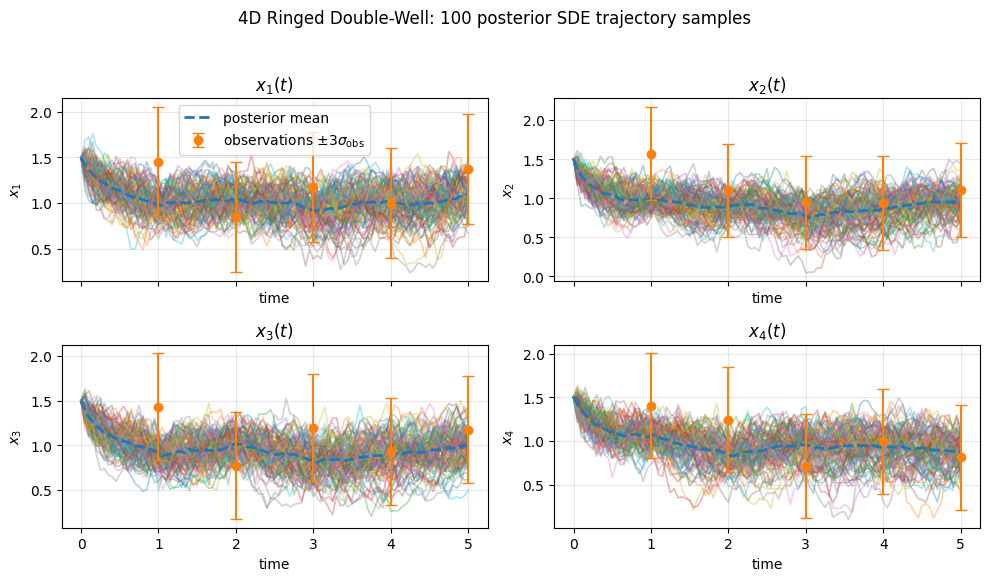
The efficacy and robustness of the proposed approach are demonstrated through inference tasks on representative nonlinear SDEs:
Strong numerical results are observed: parameter inference with the neural approach achieves reliable, monotonic convergence and accurate latent state reconstructions with only five observation points. Classical MCMC shows poor mixing and wide fluctuations, especially in higher dimensions.
Numerical Verification and Validation
The paper further validates the method on 1D Geometric Brownian Motion (GBM) and 1D Double Well SDEs, where the ground-truth smoothing distributions are available via finite-difference solvers of the Kolmogorov equations.
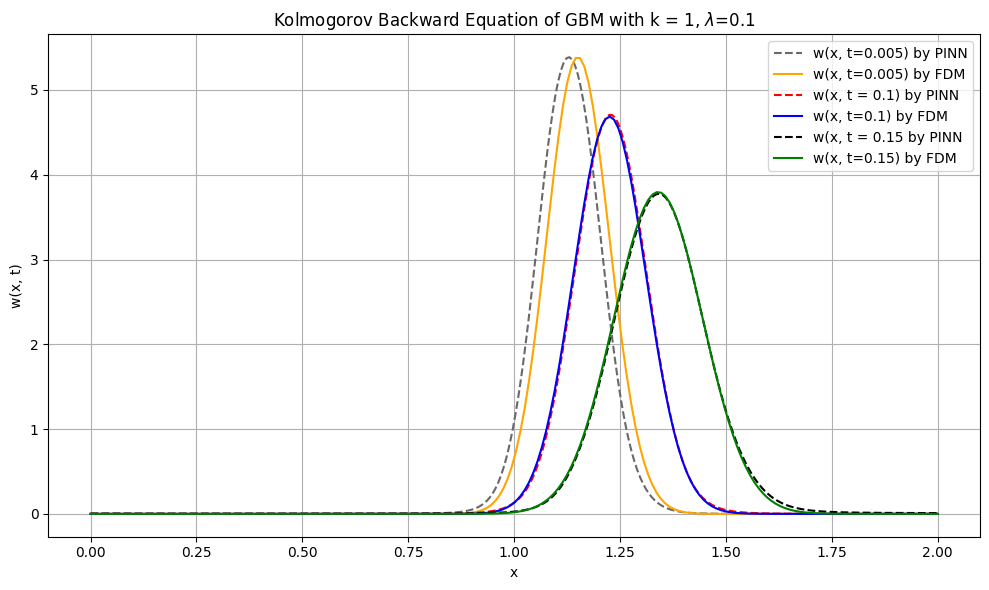
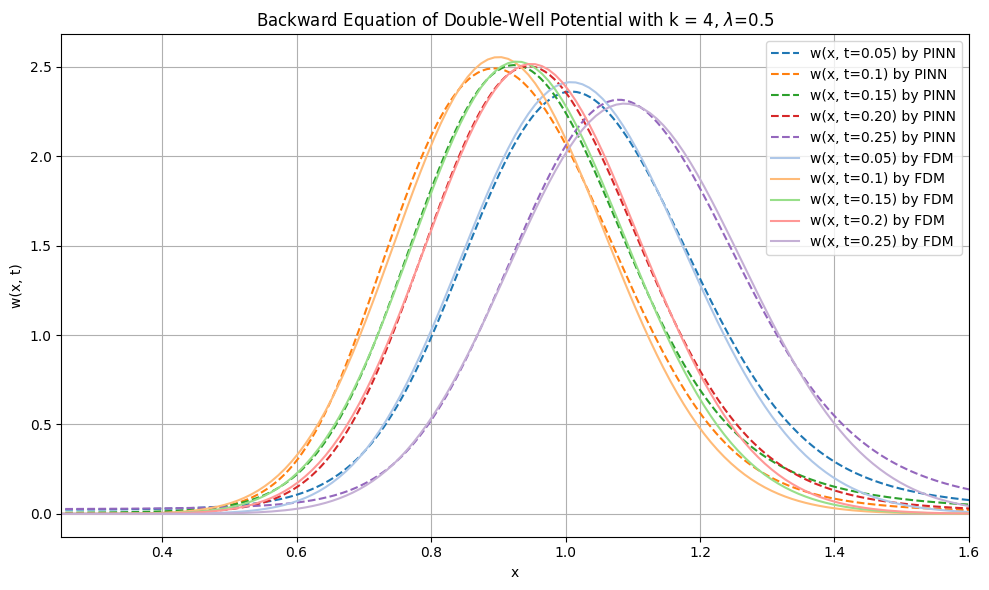
Figure 4: Comparison of smoothing distributions for 1D GBM, showing close alignment between neural and PDE-based solutions.
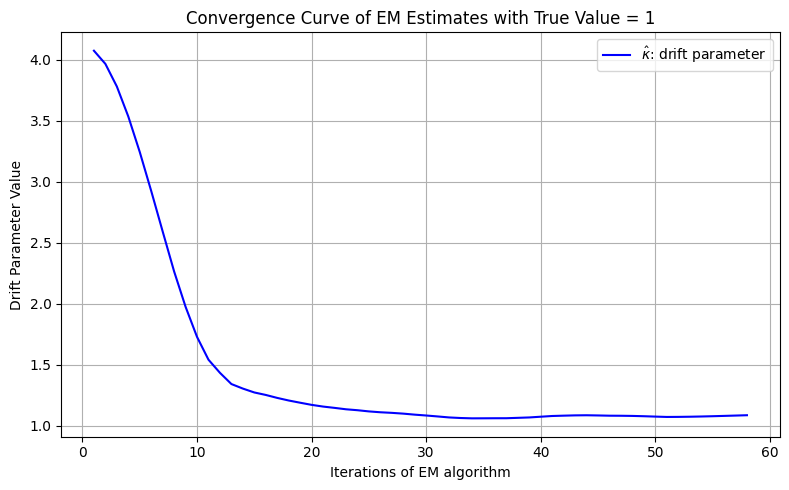
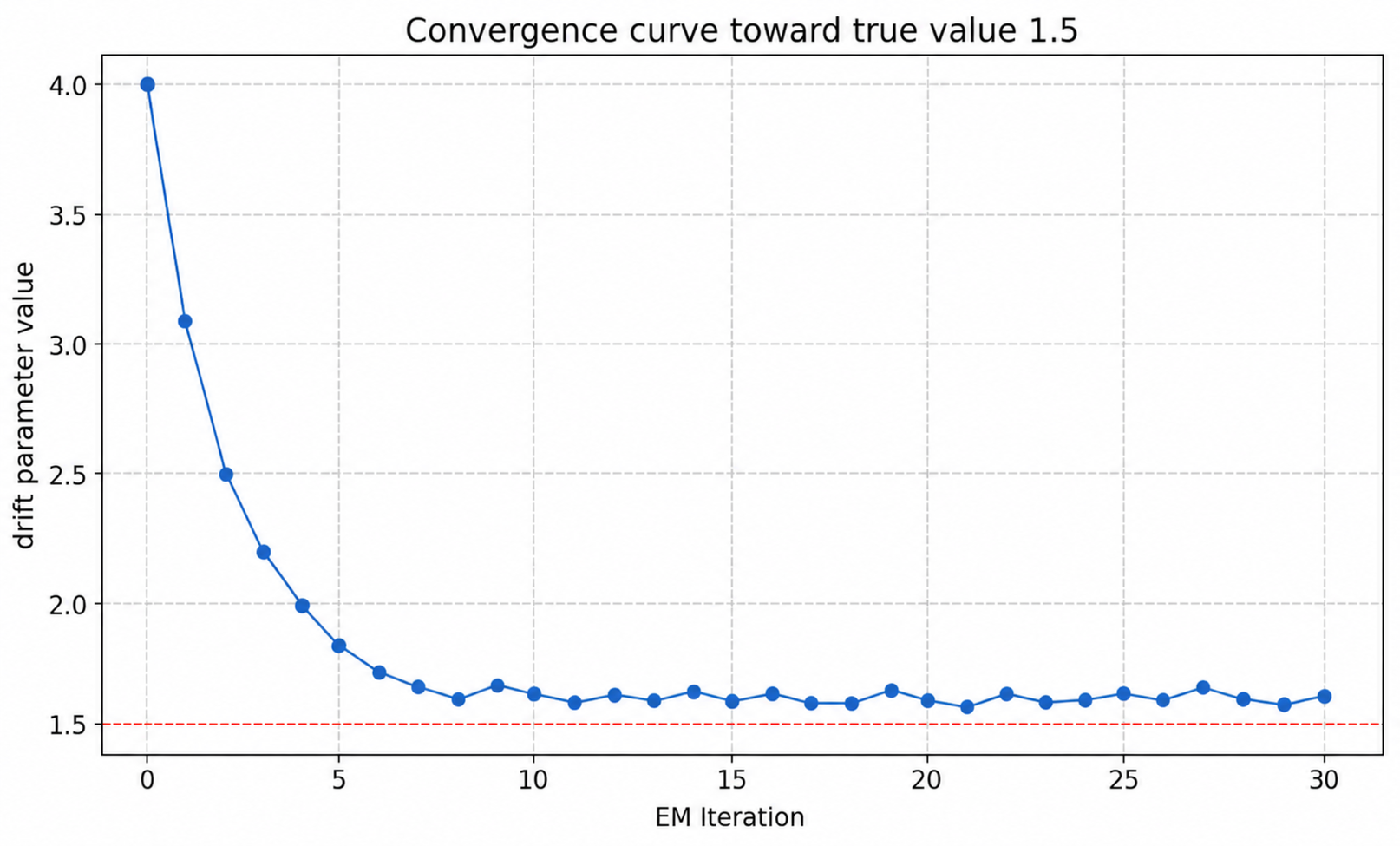
Figure 5: Demonstration of rapid, stable parameter inference in 1D GBM, closely tracking the true drift parameter.
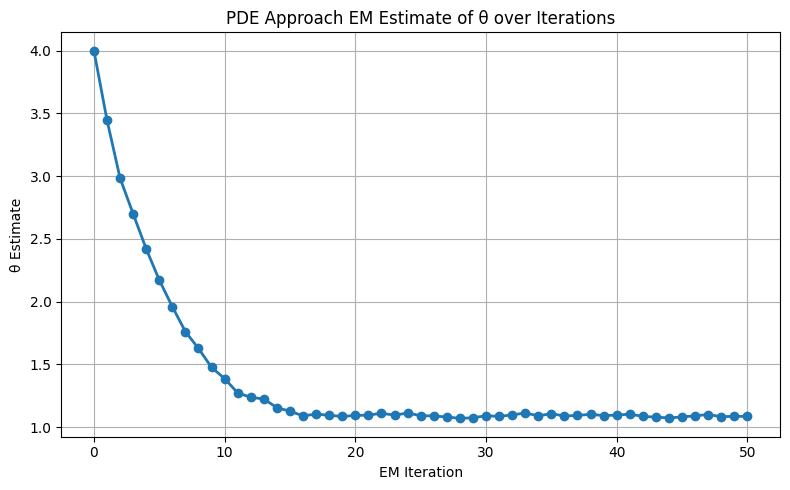
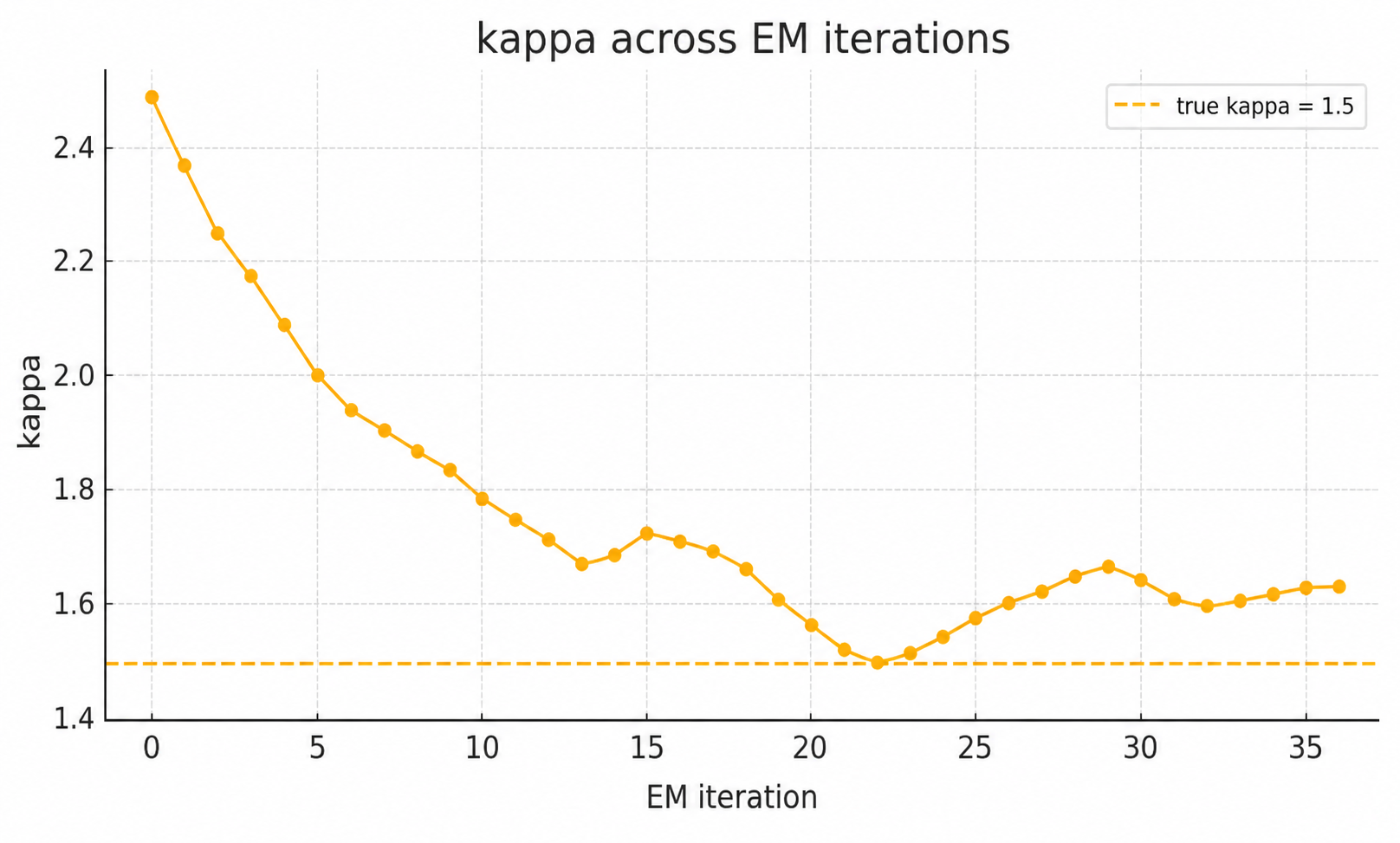
Figure 6: Parameter inference in the 1D double well SDE, with convergence to the true nonlinear drift parameter.
These ablation experiments confirm that the neural variational method mirrors the performance of numerical PDE approaches while retaining scalability, expressivity, and automatic adaptability to arbitrary drift/diffusion forms and data sparsity.
Practical and Theoretical Implications
The framework significantly advances continuous-time SDE inference from sparse and noisy partial observations. By elevating the neural network learning target from time marginals to entire path-space smoothings, it bypasses the curse of dimensionality inherent to prior-discretization or bridge-simulation. The method exploits the compositional modularity of neural approximators, facilitating training in parallel and adaptation to increasing observation regimes or dimensionality with minimal additional complexity.
Limiting factors include potential issues with nonconvex optimization when learning high-dimensional score fields and the need for sufficiently expressive neural architectures to capture intricate score landscapes. However, batching, GPU acceleration, and warm-starts across EM iterations ensure practical scalability even in demanding settings.
Theoretically, this approach opens a pathway toward unified, physics-constrained, data-driven SDE inference where Bayesian confidence quantification aligns seamlessly with neural function approximation. By leveraging pathwise variational objectives and distributional control theory, it aligns with emerging paradigms at the intersection of generative modeling, stochastic simulation, and PDE-informed machine learning.
Conclusion
This work establishes a robust, variational neural framework for smoothing and parameter inference in SDEs under data scarcity and nonlinear latent dynamics. By circumventing the bottlenecks of classical discretization-based methods, it enables accurate and scalable reconstruction of both parameters and trajectories, with empirical results demonstrating marked improvements in stability, accuracy, and sample efficiency relative to MCMC schemes. Open directions include further theoretical analysis of the optimization landscape, development of more expressive score architectures, and extension to high-dimensional and multiscale systems.