Single-Configuration Attack Success Rate Is Not Enough: Jailbreak Evaluations Should Report Distributional Attack Success
Published 9 May 2026 in cs.CR and cs.AI | (2605.09070v1)
Abstract: Many jailbreak attack research papers report attack success rates for a limited number of parameter settings, even though there are many combinations of parameter settings that could be used. Further, when new jailbreak papers are released, they often benchmark results against single configurations of existing attacks. This position paper argues such practices are fundamentally insufficient for characterising the threat posed by parameterised jailbreak attacks, and comparing attacks. Most jailbreak attacks expose multiple internal parameters, system prompt templates, conversation rounds, cipher dispersion, teaching shots, and ASR varies substantially across these parameters. Reporting only the best-case configuration discards two pieces of information that defenders genuinely need: how typical that performance is across the variant space, and how much of the attack surface is missed by selecting a single variant. We propose two new measures for jailbreak attacks: the Variant Sensitivity Measure (VSM) and Union Coverage (UC). VSM quantifies how far the best reported ASR deviates from the mean ASR across the tested variant space, UC is the total fraction of prompts resulting in unsafe responses across all tested configurations. We empirically demonstrate the importance of these measures using two attack families across three open-source target models. For PAIR, the best template reaches 69% ASR on Mistral-7B and 75% on Qwen3-0.6B, while UC rises to 88% and 93%, respectively. For bijection on Mistral-7B, the best variant reaches 81% ASR, but the 36-variant union covers 100% of HarmBench-100 prompts. We argue that distributional reporting, publishing VSM alongside ASR and enumerating variant coverage as fully as compute allows, should become the new minimum standard for parameterised jailbreak evaluation.
The paper demonstrates that relying solely on the best-case single-configuration ASR misrepresents the true vulnerability of LLMs.
It introduces Variant Sensitivity Measure (VSM) and Union Coverage (UC) as comprehensive metrics to quantify distributional attack success.
Empirical studies reveal that aggregate evaluation exposes a larger attack surface, informing more robust defensive strategies.
Distributional Attack Success Rates for Jailbreak Evaluation: Beyond Single-Configuration ASR
Motivation and Critique of Current Evaluation Practice
The paper "Single-Configuration Attack Success Rate Is Not Enough: Jailbreak Evaluations Should Report Distributional Attack Success" (2605.09070) offers a substantive critique of the current methodology for evaluating LLM jailbreak attacks. Traditionally, attack research has converged on the reporting of Attack Success Rate (ASR) achieved under a handful of, or a single, configuration. Subsequent benchmarking then treats these headline ASR values as representative of the threat posed by the entire parameterised attack family. However, parameterised attacks—such as PAIR, bijection learning, and GCG—expose a multidimensional variant space, where hyperparameters (system prompt templates, conversation rounds, cipher dispersion, teaching shots, and more) substantially affect measured ASR.
The paper demonstrates that reporting only the best-case (single-configuration) ASR is fundamentally incomplete. This practice discards critical distributional information: how representative is the best-case ASR within the broader variant space, and how much of the attack surface is uncovered only when multiple configurations are considered? As a result, defenders can systematically underestimate the cumulative set of prompts exposed by an attack, and comparative claims between attacks become opaque.
Proposed Metrics: Variant Sensitivity Measure and Union Coverage
To address these deficiencies, the authors propose two complementary metrics:
Variant Sensitivity Measure (VSM): This metric quantifies the deviation between the best single-configuration ASR and the mean ASR across the evaluated variant space:
VSM=Best ASRBest ASR−Mean ASR
A higher VSM indicates that the best-case configuration overstates typical performance, signaling a fragile or non-representative headline number.
Union Coverage (UC): UC is the fraction of prompts for which any configuration in the evaluated variant space elicits a successful jailbreak. It quantifies the total reachable attack surface, irrespective of which configurations (potentially complementary and covering different subsets of prompts) succeed:
UC=∣P∣⋃v∈VS(v)
The gap between single-configuration ASR and UC captures prompts missed in single-variant evaluation but vulnerable in aggregate.
Empirical Evidence: Case Studies
Two attack families—PAIR and bijection learning—were systematically evaluated against three open-source LLMs (including Mistral-7B-Instruct and Qwen3-0.6B), using a stratified subset (100 prompts) from HarmBench.
Significant gaps were found between the best single-configuration ASR and UC, with VSM values indicating the non-representativeness of the headline numbers:
PAIR (template and conversation round variants):
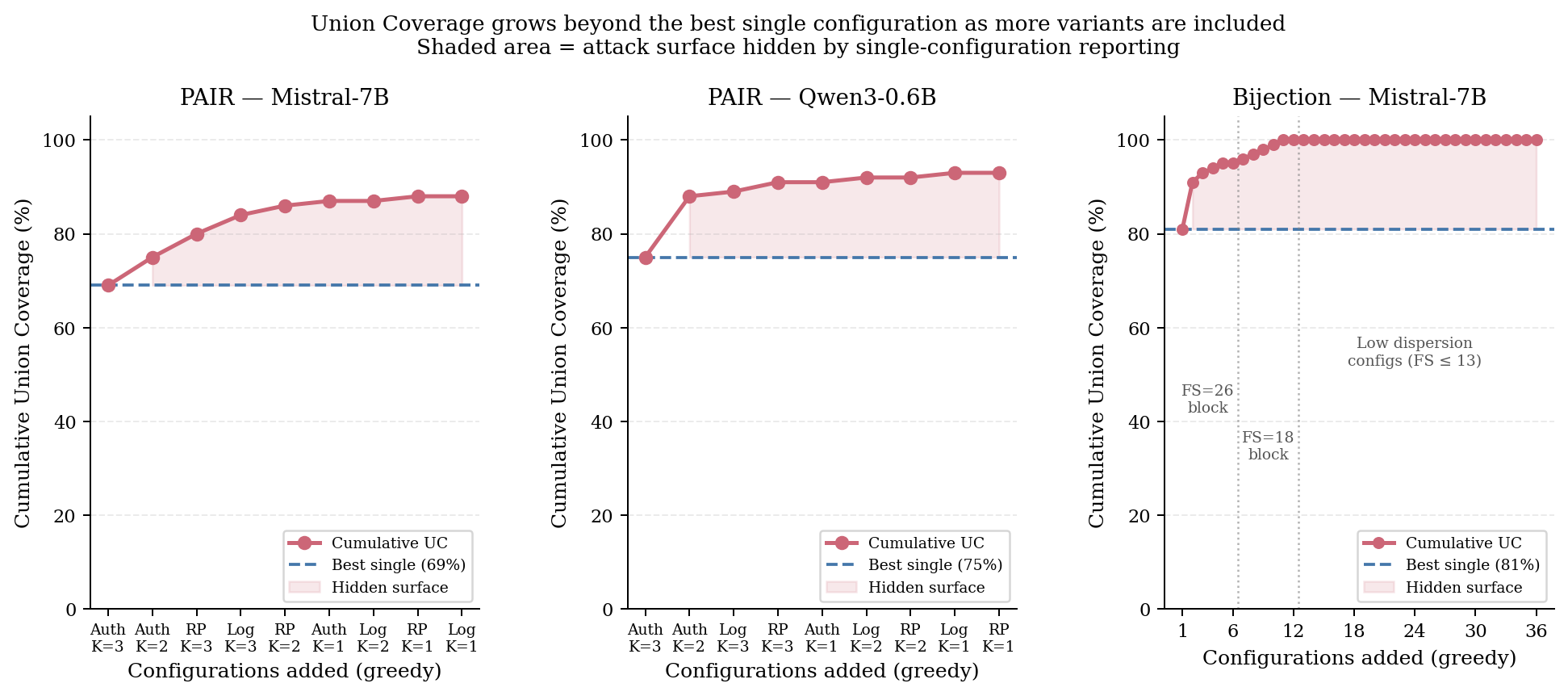
On Mistral-7B, the best template (Authority Endorsement, K=3) achieves 69% ASR (VSM=0.425), while UC reaches 88% (a 19 percentage point gap).
On Qwen3-0.6B, best-case 75% ASR (VSM=0.312) contrasts with 93% UC.
Bijection Learning (dispersion and teaching-shot variants):
On Mistral-7B, the best variant achieves 81% ASR but UC reaches 100%—every HarmBench prompt can be jailbroken by some configuration (VSM=0.803).
Even on models with lower best-case ASR (e.g., Llama-3.1-8B with 17% ASR), UC can be much higher (43%).
This is systematically illustrated by the growth of cumulative coverage as configurations are greedily added, clearly showing that the attack surface revealed by full-variant evaluation far exceeds that indicated by the best single configuration.
Figure 1: Cumulative Union Coverage across tested configurations, where each panel demonstrates how aggregate coverage increases over the best single-configuration ASR as multiple variants are combined.
Implications for Evaluation and Threat Modeling
The findings have immediate implications for researchers and practitioners:
Defensive Prioritisation: UC is the operationally meaningful quantity for defenders tasked with patching vulnerable prompts or assessing cumulative risk, as adversaries may trivially enumerate attack variants.
Fair Comparison: VSM provides diagnostic clarity, allowing researchers to avoid comparing attacks whose best-case ASRs arise from different distributions over highly sensitive variant spaces.
Metric Inflation and Underestimation: Single-configuration ASR can underestimate the attack surface by as much as 33% (as shown empirically), and in high-VSM settings, claim representativeness that is not borne out in aggregate.
Standardisation: Attacks with "complementary" variants (i.e., configurations that jailbreak disjoint prompt sets) pose broader risks than headline ASR values imply.
Computational Considerations and Limitations
Distributional reporting does not require exhaustive search over the exponentially large variant spaces. The recommendation is to report per-variant ASR, VSM, and UC for the subset of the variant space that was actually evaluated, which typically entails little extra computational cost compared to current practice. For extremely high-dimensional spaces, efficient subspace enumeration and reporting on the explored domain remains valuable.
Empirically, the paper’s analysis covers only two prominent attack families; however, its structural critique and proposed methodology generalise to any parameterised jailbreak family (GCG, AutoDAN, TAP, CodeAttack, etc.) where per-configuration performance is nonuniform. Extension to closed-source, API-gated frontier models is a future research direction.
Future Directions
This work motivates several lines of inquiry:
Automated Exploration: Systematic, automated identification of complementary configurations to map the reachable attack surface with minimal computational resources.
Robust Benchmarking: Integration of VSM and UC as default metrics in red-teaming frameworks and public leaderboards.
Defense Response: Development of mitigations that address aggregate vulnerability rather than best-case configurations, e.g., defense-aware variant oversampling or ensemble robustness.
Conclusion
The predominant practice of reporting single-configuration ASR for LLM jailbreak attacks does not capture the breadth and distributional characteristics of the real attack surface. This paper advances the field by introducing VSM and UC as diagnostic, complementary metrics, empirically demonstrating their necessity, and arguing that their widespread adoption will enable more interpretable, actionable, and fair evaluation of parameterised attacks. Distributional reporting should be adopted as the normative standard for LLM jailbreak research and defense assessment, supplanting headline-driven iteration with sound comparative methodology.