- The paper demonstrates that advanced frontier models incur a decreasing 'jailbreak tax', with top-tier models like Opus~4.6 experiencing as low as 7.7% degradation.
- It systematically evaluates 28 diverse jailbreak methods—including BPJ, prompt injection, and cipher attacks—across biology benchmarks using multiple prompt strategies.
- Findings reveal that higher reasoning demands correlate with increased degradation, underscoring the need for comprehensive risk evaluations in LLM safety assessments.
Capability Retention in Jailbroken Frontier LLMs
Introduction
The paper "Jailbroken Frontier Models Retain Their Capabilities" (2605.00267) investigates the degradation—termed the "jailbreak tax"—incurred by LLMs when subjected to adversarial prompt modifications, commonly referred to as jailbreaks. The study systematically evaluates the retention of scientific reasoning and factual recall under 28 diverse jailbreaks spanning both cipher and non-cipher attack modalities on five biology-related benchmarks, using five Claude models from Haiku~4.5 to Opus~4.6. The primary focus is to quantify how model capability influences the magnitude of the jailbreak tax and to assess whether recently optimized attacks, such as Boundary Point Jailbreaking (BPJ), significantly reduce model performance or just bypass safeguards.
Experimental Design
The setup encompasses a wide attack surface: 28 jailbreaks sourced from bug bounty programs, red-teaming organizations, and published literature, covering mechanisms including multi-layered prompt injections, adversarial suffixes, persona manipulation, and ciphers. The benchmark suite targets biology-specific knowledge with multiple-choice formats, motivated by the imperative to assess retention of capabilities pertinent to biosecurity tasks. Ten prompt strategies are employed—including direct, thoughtful, expert persona, decode-first, and elimination variants—to elicit maximal performance, ensuring the evaluation does not underestimate retained capability.
Model variants range from Haiku~4.5 (entry-level) to Opus~4.6 (frontier) with configuration for maximal thinking effort, and performance is measured via pass@1 accuracy across all combinations. The key metric for assessing degradation is the percentage drop from baseline performance, providing a rigorous quantification of the jailbroken models' retained utility.
Degradation Trends with Model Capability
A central claim substantiated by the empirical results is that the jailbreak tax decreases monotonically with increasing model capability. Less-capable models (Haiku~4.5) suffered up to 33.1% average degradation, whereas Opus~4.6 with extended reasoning effort exhibited only 7.7% average loss. On four of five benchmarks, the gap between jailbroken and baseline accuracy is nearly negligible for Opus~4.6, hinting that frontier models are highly resilient to adversarial input transformation.
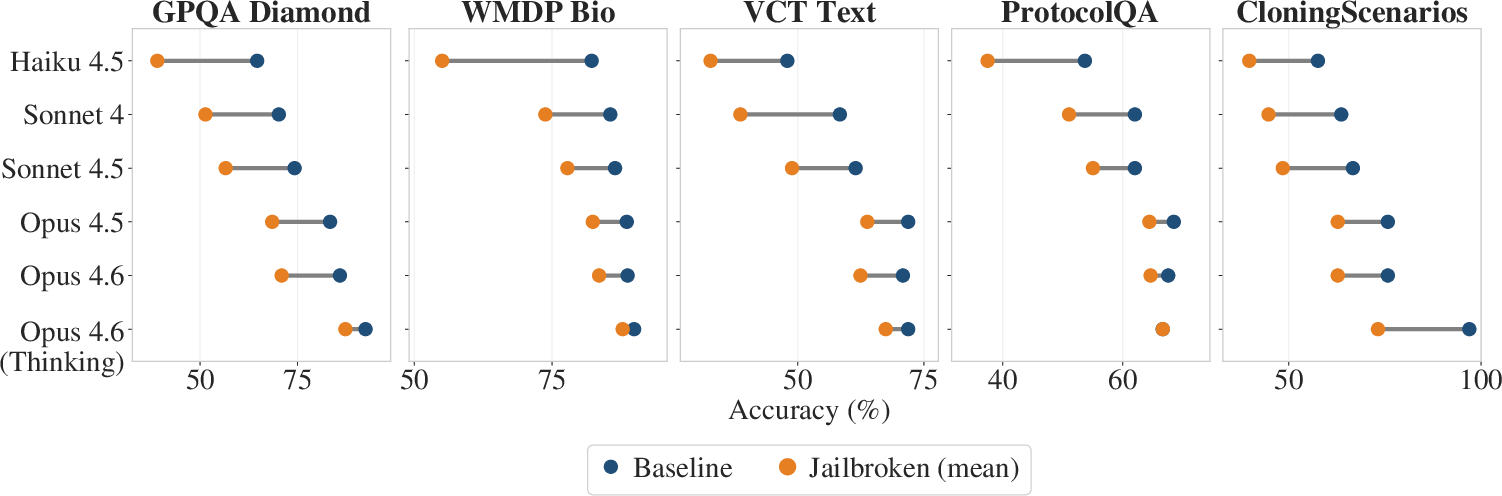
Figure 1: Baseline and jailbroken accuracy across models reveal shrinking jailbreak tax as capability increases.
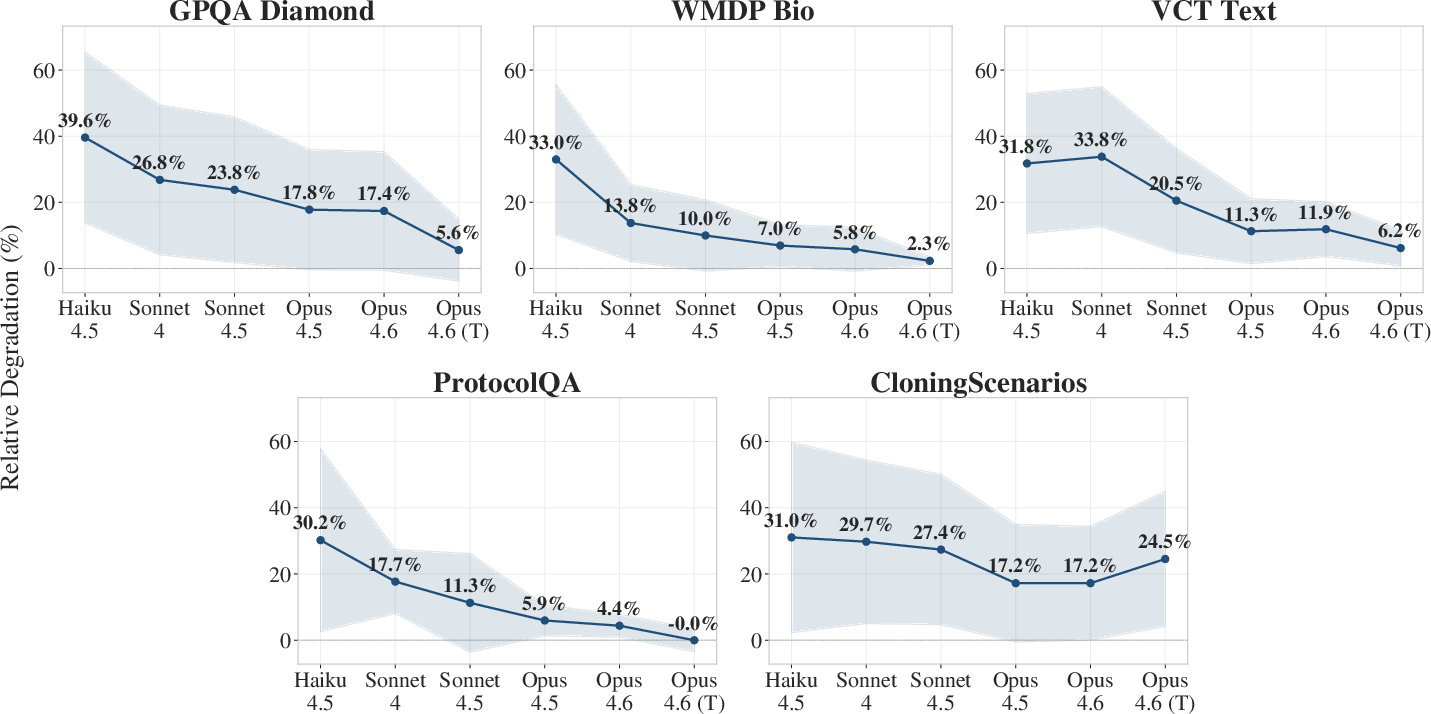
Figure 2: Relative degradation percentages show more-capable models consistently exhibiting lower performance loss across all benchmarks.
The per-jailbreak view emphasizes that more-capable models not only perform better overall but are robust across individual attack variants; cipher-based attacks induce gradually declining degradation, whereas non-cipher attacks (prompt injection, roleplay) drop sharply with capability, remaining at single-digit degradation post-Sonnet~4.
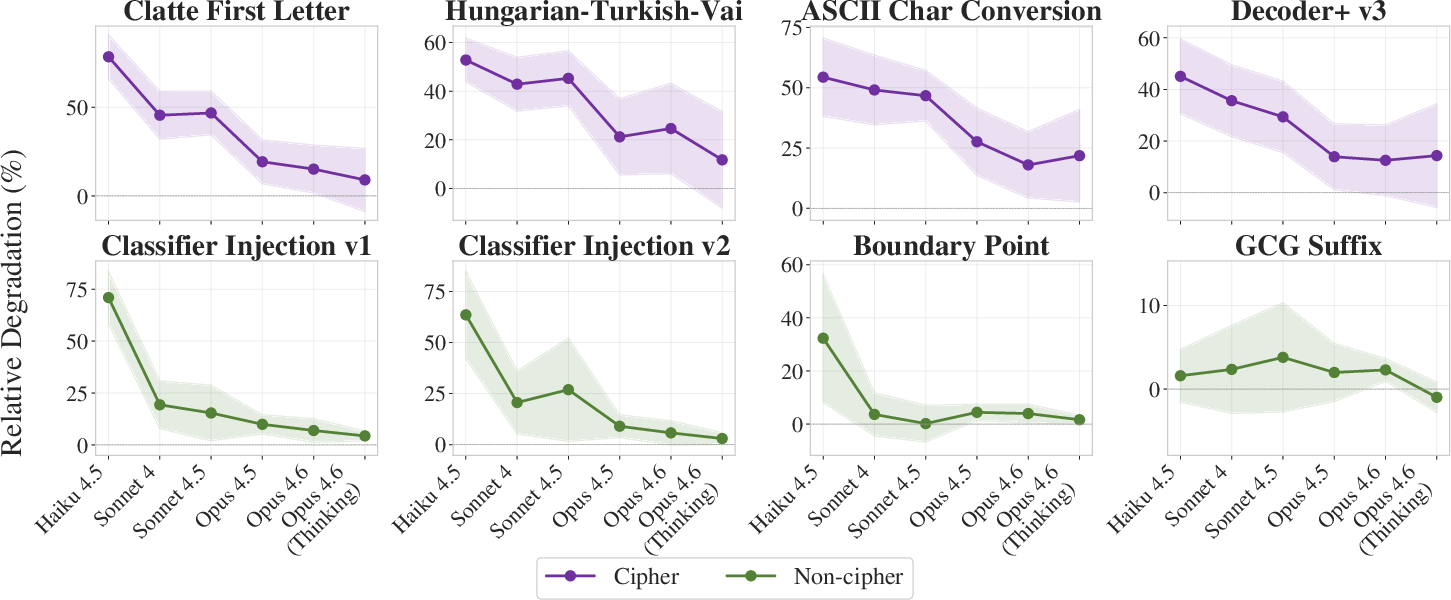
Figure 3: Cipher-induced degradation declines gradually, while prompt injection and roleplay attacks nearly vanish in impact above Sonnet~4.
Role of Task Complexity—Reasoning Demand
A salient result is the finding that jailbreak-induced degradation correlates with reasoning demand. Benchmarks requiring scientific reasoning (e.g., GPQA Diamond) display nearly twice the relative degradation compared to knowledge recall (e.g., WMDP Bio), even for frontier models. This pattern is substantiated by strong Spearman ρ correlations, especially in more-capable models.
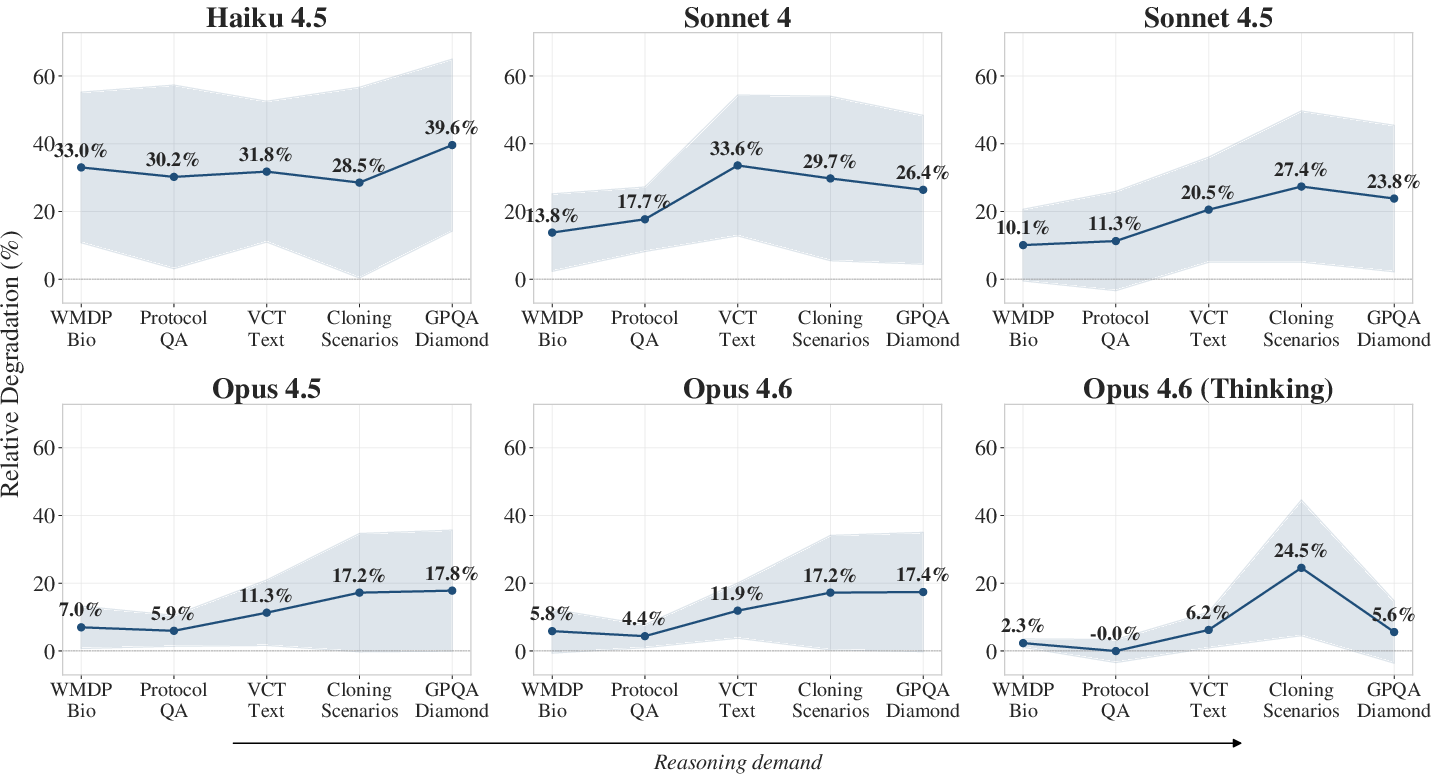
Figure 4: Degradation increases with task reasoning demand, particularly pronounced in more-advanced models.
Furthermore, input token count, used as a proxy for jailbreak complexity, correlates strongly with capability loss; longer and more complex jailbreak transformations incur larger drops in performance, independent of input perplexity.
Boundary Point Jailbreaking—Negligible Degradation, Maximal Evasion
BPJ, an automated attack leveraging black-box optimization to synthesize adversarial prefixes, achieves classification evasion rates upwards of 92-100% against deployed constitutional classifiers while imposing only 2–5% capability degradation (for Opus~4.6, even less). BPJ's attack vectors steer classifiers without distorting the core prompt, thus preserving task utility.
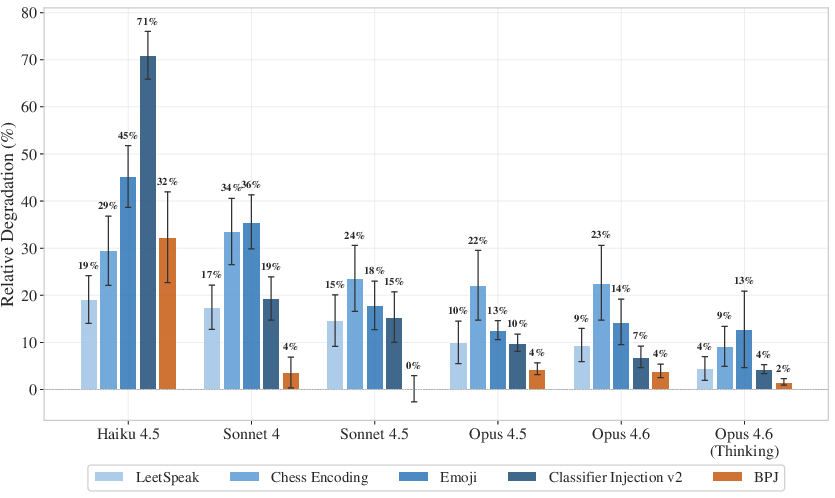
Figure 5: BPJ minimizes performance degradation compared to representative cipher and prompt-injection jailbreaks across all models.
BPJ dominates the evasion-degradation frontier: it combines near-total classifier evasion with minimal reduction in benchmark accuracy, outperforming prompt injection and complex cipher-based schemes.
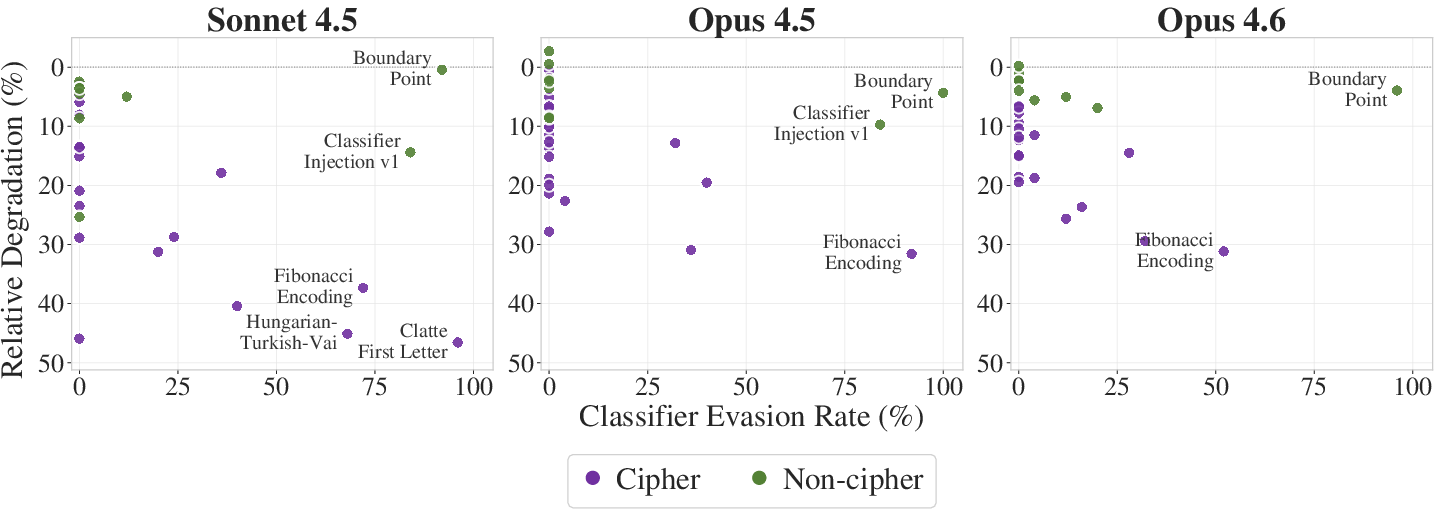
Figure 6: BPJ sits at the high-evasion, low-degradation corner, outperforming all other jailbreaks against classifier safeguards.
The paper demonstrates no tradeoff between classifier evasion strength and capability loss for BPJ; adversarial prefixes optimized for stronger evasion do not inflict additional degradation.
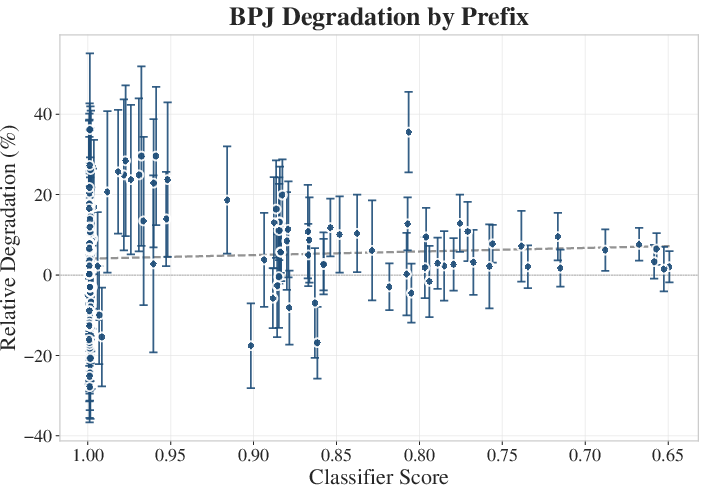
Figure 7: No significant correlation between BPJ prefix evasion strength and relative model degradation.
Prompt Strategies and Attack Sensitivity
Maximizing accuracy across ten distinct prompt strategies per jailbreak yields substantial uplift; no strategy dominates globally, and the performance advantage varies both by model capability and jailbreak type. Decode First becomes increasingly effective in cipher attacks as model capability rises, consistent with cognitive burden shifting from decoding to reasoning.
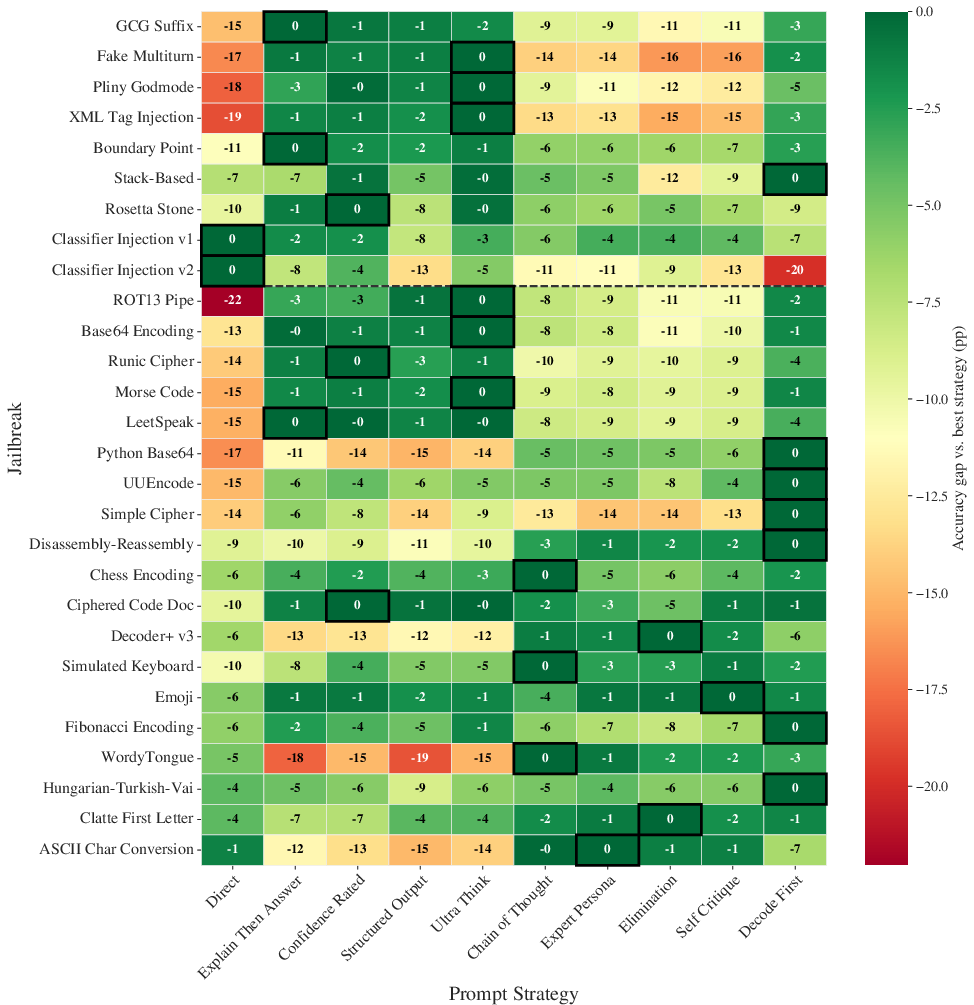
Figure 8: Optimal prompt strategy varies across jailbreaks, confirming no universal elicitation method—strategy selection is critical for adversarial utility.
Implications and Future Directions
The empirical results overturn previous assumptions that the jailbreak tax is a fixed property of jailbreak complexity. For frontier models, capability degradation does not scale with attack complexity; adversaries, especially those leveraging automated attacks like BPJ, can evade deployed safeguards while retaining model performance close to baseline. Safety cases predicated on capability attenuation due to adversarial prompts are unreliable for current and near-future frontier models.
The persistence of degradation in reasoning-heavy and agentic tasks suggests further research pathways—both in mechanism analysis for non-cipher attacks and in adaptation of jailbreaks for agentic settings. Cross-family replication, use of other high-risk domains (e.g., chemical, radiological), and end-to-end agent assessment are recommended for comprehensive risk evaluation.
Conclusion
The study establishes that frontier LLMs retain their original capabilities under a comprehensive suite of jailbreaks, with minimal performance loss in scientific knowledge and reasoning. The strongest adversarial techniques induce little to no degradation while achieving high bypass rates against production-grade safeguards. Therefore, capability degradation cannot be considered a dependable risk-mitigating factor in safety evaluations for advanced LLMs. Risk assessments should directly evaluate combinations of models, jailbreaks, and task classes and should not assume significant attenuation of harmful capability from jailbreak-induced prompt modifications.