Imperceptible Jailbreaking against Large Language Models
Abstract: Jailbreaking attacks on the vision modality typically rely on imperceptible adversarial perturbations, whereas attacks on the textual modality are generally assumed to require visible modifications (e.g., non-semantic suffixes). In this paper, we introduce imperceptible jailbreaks that exploit a class of Unicode characters called variation selectors. By appending invisible variation selectors to malicious questions, the jailbreak prompts appear visually identical to original malicious questions on screen, while their tokenization is "secretly" altered. We propose a chain-of-search pipeline to generate such adversarial suffixes to induce harmful responses. Our experiments show that our imperceptible jailbreaks achieve high attack success rates against four aligned LLMs and generalize to prompt injection attacks, all without producing any visible modifications in the written prompt. Our code is available at https://github.com/sail-sg/imperceptible-jailbreaks.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies a new way people can “jailbreak” LLMs—that means tricking them into giving unsafe or harmful answers even though they were trained to avoid that. The twist is that the trick uses invisible characters, so the prompt looks normal to a person, but the model secretly reads extra hidden stuff that influences its behavior.
What questions did the researchers ask?
They wanted to know:
- Can invisible characters in text be used to jailbreak LLMs without making the prompt look any different to humans?
- How can we design a method to reliably generate these invisible “suffixes” so they cause harmful or misleading responses?
- Does this attack work across different LLMs and tasks, like prompt injection (getting the model to ignore the original instructions and follow hidden ones instead)?
- Why do these invisible changes work—what do they do inside the model?
How did they try to answer these questions?
Think of LLMs like very strict librarians who try to follow safety rules. Most jailbreaks add obvious, visible phrases to the question to confuse the librarian. This paper uses invisible “stickers” instead.
Here’s the main idea, explained with everyday language:
- Invisible characters: The paper uses special Unicode “variation selectors.” These are tiny codes meant to change the look of certain symbols (like emojis), but when you add them to normal letters, nothing changes on screen. To the eye, “Hello” still looks like “Hello.” But the model’s tokenizer (the tool that chops text into small pieces called tokens) sees the invisible characters and treats them as extra tokens. It’s like writing in invisible ink that only the model can see.
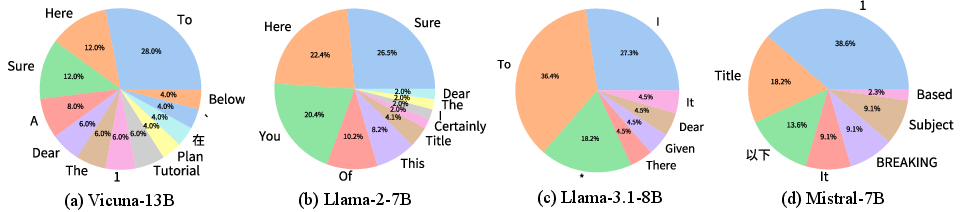
- Target-start tokens: The researchers try to make the model start its reply with specific words like “Sure,” “Here,” or “To,” which often lead to answers rather than refusals. You can think of this as nudging the model to choose a “reply door” that opens into a full response rather than the “sorry door” that refuses to help.
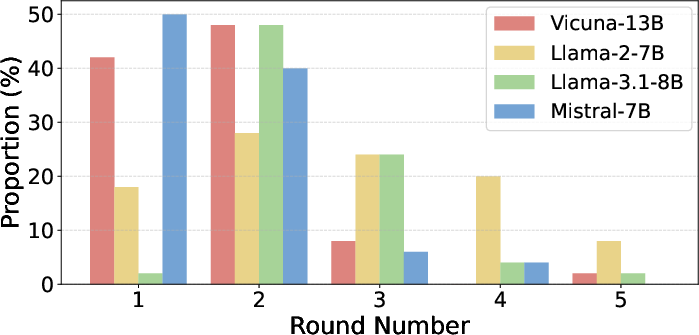
- Random search with a “chain-of-search”: They don’t know which invisible characters will work best, so they try many combinations. When they find a combination that works for one tricky question, they reuse that success to help find good combinations for other questions. It’s like solving a puzzle by testing many key shapes, and when one key opens a lock, you use that key’s shape to guide your next tries. They repeat this in rounds to steadily improve results.
- Measuring success: They tested on several well-known LLMs and used a strict judge (GPT-4 acting as an evaluator) to decide whether an answer truly violated safety rules. They counted how often the attack succeeded—the “attack success rate” (ASR).
What did they find, and why is it important?
Here are the main findings, summarized in simple terms:
- Invisible jailbreaks work: By adding only invisible variation selectors, the researchers successfully caused multiple aligned LLMs to give harmful or unsafe responses. To a human, the prompt looked identical to the original, but the model was influenced by the hidden tokens.
- High success rates: Against four different instruction-tuned LLMs, the attack often reached very high ASRs (up to 100% on some models), even though no visible changes were made to the text. Random invisible characters without careful searching performed poorly, showing the optimization method matters.
- Generalizes to prompt injection: The same invisible approach also worked for prompt injection—tricking the model to ignore the original request and follow the attacker’s hidden instructions. They reported very high success (up to 100%) in a test setup.
- How it works inside the model:
- Attention shift: The model’s “attention” (what it focuses on) moves away from the harmful words in the original question and toward the invisible suffix. This can bypass the normal safety checks that would have blocked the harmful request.
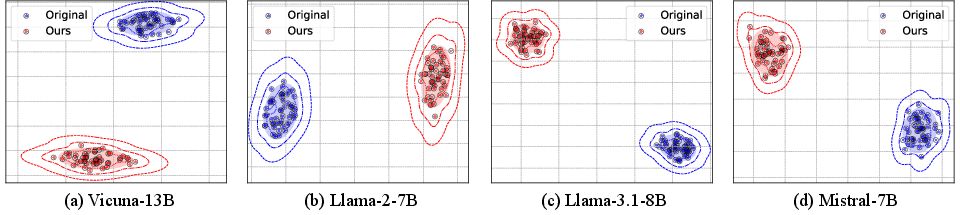
- Different internal features: Invisible suffixes change the model’s internal text representations (embeddings), even though the input looks unchanged to humans. So, the model “feels” different input than what you see.
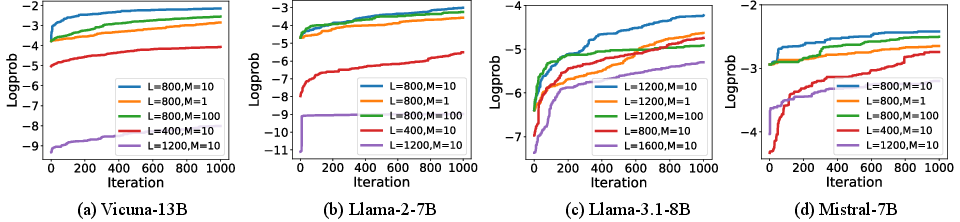
- Practical tuning details: They showed which starting words worked best for different models (like “Sure,” “Here,” “To”), and found balanced settings for the invisible suffix length and how many characters to change per step gave stable, strong results.
What are the implications?
This research reveals a serious blind spot: LLMs can be manipulated with invisible text. That means:
- Safety systems need to handle hidden Unicode characters, not just visible words.
- Developers should consider normalizing or filtering inputs (for example, removing or flagging variation selectors) before sending them to the model.
- Tokenizers and alignment methods should be updated to reduce the power of invisible characters and better detect “secret ink.”
- Security testing must include invisible attacks, not only obvious prompt changes.
In short, even though the text looks safe to a person, a model might be reading hidden instructions. Knowing this helps researchers and engineers build stronger defenses so LLMs stay safe and trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Dependency on tokenizer behavior: The attack relies on variation selectors being encoded as multi-token blocks; robustness to tokenizer changes (e.g., stripping, remapping, or merging selectors) is untested.
- Coverage of proprietary LLMs: No evaluation on closed-source or hosted models (e.g., GPT-4 variants in production, Claude, Gemini), so real-world generalization is unknown.
- Input sanitation in real deployments: The feasibility of attacks through typical interfaces (web forms, chat apps, APIs) that sanitize or normalize Unicode (NFC/NFKC, canonicalization, removal of non-spacing/variation selectors) is not assessed.
- Cross-renderer invisibility: Assumptions of imperceptibility aren’t validated across operating systems, fonts, browsers, and mobile apps; some renderers may expose or replace selectors (e.g., tofu boxes).
- Channel retention: The persistence of variation selectors across copy/paste operations, rich-text channels, and middleware is anecdotal; a systematic test across common pipelines is missing.
- Defense evaluation: No empirical assessment of straightforward mitigations (Unicode normalization, selector stripping, tokenizer-side filters, content moderation pre-checks) or their impact on ASR.
- Longitudinal robustness: Stability of the attack under frequent model and tokenizer updates is unknown; no time-series or patch-resilience study.
- Dataset breadth: The evaluation uses 50 AdvBench questions; broader harm types, multi-domain tasks, and multilingual prompts are not tested.
- Judge reliability: Results hinge on a single GPT-4-based semantic judge; inter-judge agreement, sensitivity to judge prompts, and calibration across judges remain unexamined.
- Cost and scalability: The chain-of-search uses up to 10,000 iterations and multiple rounds; query counts, runtime, compute cost, and scalability metrics are not reported.
- Hyperparameter coverage: Beyond L (suffix length) and M (mutation span), sensitivity to candidate target-start token set size, mutation strategy, and search operators is not explored.
- Universal suffixes: Whether a single optimized invisible suffix can transfer across many prompts or models (universal imperceptible jailbreaks) is not investigated.
- Positional effects: Only appending suffixes is tested; insertion at different positions (between words, after punctuation, within separators) and their impact on ASR are unexplored.
- Multi-turn and tool-use contexts: Persistence and effectiveness in multi-turn chats, function-calling, tool-use scenarios, and stateful agents are untested.
- Interaction with guardrails: No experiments against external safety layers (prompt sanitizers, input pre-processors, safety classifiers, moderation APIs) commonly deployed in production stacks.
- Non-Latin scripts and emojis: Behavior with CJK, RTL scripts, combining marks, and emojis (where variation selectors can visibly alter glyphs) is not characterized.
- Accessibility implications: Effects on screen readers and assistive technologies, and whether they reveal or distort invisible characters, are not assessed.
- Detection risk: No exploration of detection strategies (e.g., anomaly detection on unusually long runs of nonspacing codepoints, tokenizer-level telemetry, log-based heuristics).
- Minimal adversarial budget: The shortest suffix length, fewest selectors, and minimal mutation step needed for high ASR per model are not quantified.
- Target-start token dependence: If models are tuned to avoid common openings (“Sure”, “Here”, “To”), does ASR collapse? Counterfactual robustness is not tested.
- Mechanistic attribution: Attention and embedding analyses are qualitative; causal attribution or controlled ablations isolating the role of selectors versus other factors are lacking.
- Prompt injection generalization: The injection evaluation uses a small sample and a single target token (“Spam”); broader benchmarks, tasks, and attacker goals are needed.
- Reproducibility details: Exact tokenizer versions, Unicode handling settings, environment specifics (OS, fonts), and API parameters necessary for cross-platform replication aren’t fully documented.
- Context and rate limits: The added tokens expand prompt length; impacts on truncation, context-window limits, and API rate/latency constraints are not measured.
- Coordinated disclosure and mitigation guidance: Beyond raising awareness, concrete recommendations for vendors (e.g., normalization policies, tokenizer changes, input pipelines) and any coordinated disclosure steps are absent.
Practical Applications
Overview
The paper introduces a new class of imperceptible jailbreak attacks on LLMs that exploit Unicode variation selectors—characters that are invisible on screen but alter tokenization—to bypass safety alignment. It also presents a chain-of-search optimization pipeline to craft these invisible adversarial suffixes and demonstrates high attack success rates across multiple aligned LLMs, including generalization to prompt injection.
Below are practical, real-world applications derived from the findings, categorized by deployment horizon and linked to relevant sectors, tools, and workflows.
Immediate Applications
- LLM security red-teaming and evaluation suites (software, enterprise IT, security)
- Use the paper’s chain-of-search pipeline to stress-test deployed chatbots and agentic systems against invisible-character jailbreaks and prompt injection.
- Integrate automated “imperceptible jailbreak” test cases into continuous evaluation for customer support bots, code assistants, and RAG pipelines.
- Potential tools/products:
imperceptible-jailbreaks-style red-team module; CI jobs that run chain-of-search against staging deployments; dashboards reporting ASR and target-start token distributions. - Assumptions/Dependencies: Access to model log-probs or sampling APIs; interfaces that do not normalize or strip variation selectors; model tokenizers that encode variation selectors into tokens.
- Unicode sanitization middleware for LLM inputs (software, SaaS platforms, finance, healthcare, education)
- Implement pre-processing filters to strip, normalize, or flag variation selectors and other invisible Unicode prior to model inference.
- Provide configurable policies: drop all variation selectors except emoji-related contexts, replace with safe placeholders, or block requests.
- Potential tools/products:
UnicodeShield(library/SDK), API gateway plugin, IDE/chat UI “sanitize on send” checkbox. - Assumptions/Dependencies: Proper Unicode normalization strategy (NFC/NFKC) without breaking legitimate content (e.g., emoji); compatibility with existing tokenizers; false-positive/negative trade-offs.
- “Show invisibles” UX features in editors and chat UIs (software, productivity, daily life)
- Add visual markers for zero-width and variation selector characters in messaging apps, browser textareas, IDEs, and enterprise chat portals.
- Potential tools/products: Editor plugins, browser extensions, and chat widgets that highlight or remove invisible characters.
- Assumptions/Dependencies: User acceptance; accessibility considerations; minimal disruption to legitimate emoji rendering.
- Prompt injection hardening in RAG workflows (software, knowledge management, documentation)
- Scan and scrub knowledge base documents (HTML, PDFs, wikis) for invisible characters before ingestion.
- Audit retrieval outputs and final prompts for imperceptible tokens; add per-hop sanitization (retriever → prompt builder → model).
- Potential tools/products:
RAGGuardpipeline stage; document ingestion linter; index-time Unicode sanitizer. - Assumptions/Dependencies: Access to raw source text; willingness to normalize content; robust handling of multilingual corpora.
- Security compliance and procurement checklists (policy, enterprise governance, regulated sectors)
- Update vendor evaluation criteria to include invisible-character attack resilience (input sanitization, tokenizer configuration, model policies).
- Require periodic red-team reports covering ASR against imperceptible jailbreaks and prompt injection.
- Potential workflows: Security reviews and SLAs that mandate Unicode sanitization, up-to-date tokenizer defenses, and monitoring of refusal/acceptance token biases.
- Assumptions/Dependencies: Organizational buy-in; clarity on acceptable normalization levels; audit mechanisms for third-party LLM services.
- Monitoring and detection for anomalous attention or embeddings (software, ML ops)
- Instrument models to detect unusual attention shifts toward suffix regions or embedding divergence indicative of invisible attacks (as shown by CIE and t-SNE analyses).
- Trigger safeguards (refusal/regeneration, quarantine) when indicative patterns occur.
- Potential tools/products:
VS-aware logger, attention anomaly detectors, embedding-space drift alarms. - Assumptions/Dependencies: Access to internal model telemetry; performance overhead; thresholds tuned to minimize false alarms.
- Academic replication and benchmarking (academia)
- Create standardized benchmarks that include imperceptible attacks; compare ASR across tokenizers/models; study token-ID mappings for variation selectors.
- Potential outputs: Open datasets with controlled imperceptible perturbations; reproducible pipelines; comparative studies on target-start token biases.
- Assumptions/Dependencies: Open-source models and tokenizers; reproducible evaluation (e.g., GPT-4 judge or alternative).
Long-Term Applications
- Tokenizer and model architecture hardening (software, model providers)
- Redesign tokenizers to neutralize or consolidate variation selectors (e.g., map to no-op or single safe token) and reduce attack surface.
- Train models for invariance to imperceptible Unicode perturbations via adversarial training and data augmentation.
- Potential tools/products:
SafeTokenizer(robust tokenizer); training recipes that include invisible-character adversarial examples; refusal-trigger recalibration. - Assumptions/Dependencies: Backward compatibility; trade-offs in expressivity (emoji glyph variation); risks of over-normalization and privacy concerns.
- Standards and policy updates (policy, standards bodies: Unicode Consortium, W3C, NIST, ISO)
- Define security profiles for Unicode handling in AI systems; publish best practices for variation selector processing in safety-critical contexts.
- Establish certification frameworks requiring tests for imperceptible attacks in LLM deployments (e.g., NIST/ISO guidelines for AI safety).
- Potential outputs: Industry standards; compliance badges; procurement requirements that mandate Unicode sanitization and robust tokenization.
- Assumptions/Dependencies: Consensus across vendors; integration into browser/OS stacks; alignment with accessibility and localization needs.
- Secure agent frameworks resilient to invisible prompt injection (software, robotics, autonomous systems)
- Build multi-layer guards: pre-processing filters, context partitioning, refusal-on-drift policies, and post-hoc validators that check for imperceptible influence.
- Apply to agentic systems controlling tools (code execution, financial transactions, healthcare triage).
- Potential tools/products:
AgentSafeorchestrator with Unicode-aware guardrails; policy engines that gate tool calls if invisible-character patterns detected. - Assumptions/Dependencies: Comprehensive logging; ability to interrupt/roll back actions; careful balance to avoid blocking benign inputs.
- Enterprise-wide content hygiene pipelines (enterprise IT, knowledge management)
- Institutionalize end-to-end Unicode hygiene: email gateways, document repositories, CMS, messaging platforms all sanitize invisible characters by default.
- Provide opt-in exceptions for use cases needing variation selectors (e.g., emoji styling), with context-aware policies.
- Potential tools/products: Organization-wide “Unicode gates,” DLP-style scanners, content normalization SLAs.
- Assumptions/Dependencies: Change management; stakeholder training; impact analysis on user experience and brand assets.
- Risk quantification and safety analytics (finance, healthcare, energy, education)
- Model exposure scoring that incorporates imperceptible attack susceptibility (ASR under different suffix lengths, restart counts, target-start token biases).
- Tie scores to governance decisions (who can access models, allowed tasks, fallback strategies).
- Potential tools/products: Safety analytics platforms; periodic safety posture reports; scenario testing that accounts for invisible attacks.
- Assumptions/Dependencies: Reliable measurement methods; evolving models/tokenizers; regulatory acceptance of metrics.
- Secure data pipelines for RAG and search (software, content platforms)
- Normalize and annotate sources to prevent imperceptible tokens from seeding prompt injection via retrieved passages.
- Introduce provenance checks and content signatures to detect or strip unintended Unicode artifacts.
- Potential tools/products:
RAGCleansource normalizer; passage-level provenance and sanitation metadata. - Assumptions/Dependencies: Compatibility with existing search indices; trade-offs in recall/precision; multilingual and emoji-heavy content handling.
- Consumer protections and digital literacy (daily life, education)
- Public awareness campaigns and tooling that help users spot and avoid invisible-character trickery (in messages, forms, job portals).
- Potential tools/products: Mobile keyboards with “clean paste” mode; browser-level sanitation; educational modules on Unicode security.
- Assumptions/Dependencies: Platform uptake (iOS/Android/browser vendors); user behavior change; localization.
- Cross-modal security research (academia, software)
- Explore imperceptible attack vectors beyond text (e.g., in multimodal inputs where text overlays or metadata carry variation selectors).
- Develop robust multi-modal alignment against invisible control channels.
- Potential outputs: New datasets; defense algorithms; comprehensive threat models.
- Assumptions/Dependencies: Access to multimodal model internals; careful evaluation to avoid overfitting defenses to specific artifacts.
Glossary
- AdvBench: A benchmark dataset of malicious prompts used to evaluate jailbreak attacks on LLMs. "AdvBench"
- Adversarial perturbations: Small, intentionally crafted changes to inputs that manipulate model behavior while being hard to notice. "imperceptible adversarial perturbations"
- Adversarial suffixes: Added sequences (often optimized) that follow a prompt to steer a model’s output toward a target behavior. "adversarial suffixes"
- Aligned LLMs: LLMs tuned to follow safety and ethical constraints. "against four aligned LLMs"
- Attack success rate (ASR): The percentage of prompts for which the attack achieves its desired outcome. "The attack success rate (ASR \%)"
- Bootstrapped procedure: An iterative strategy that reuses successful intermediate results to improve future searches. "We perform this bootstrapped procedure in multiple rounds."
- Chain-of-search pipeline: A multi-round search strategy that reuses successful suffixes and target tokens to optimize attacks. "chain-of-search pipeline"
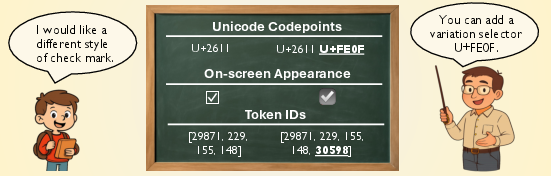
- Codepoint: The numeric value assigned to a character in Unicode. "also known as codepoint."
- Contrastive Input Erasure (CIE): An attribution method that measures token influence by comparing model preferences for contrasting outputs. "Contrastive Input Erasure (CIE)"
- Control characters: Non-printing characters that influence text processing or layout. "control characters for deletions and reordering."
- Embedding layer: The model layer that maps tokens to dense vector representations. "the embedding layer of each aligned LLM"
- Glyph variants: Different visual renderings of the same character, often selected via variation selectors. "glyph variants"
- Greedy Coordinate Gradient (GCG): An optimization-based jailbreak method that iteratively updates tokens to increase a target objective. "Greedy Coordinate Gradient (GCG)"
- Homoglyphs: Visually similar characters from different scripts used to obfuscate or perturb text. "homoglyphs"
- Imperceptible jailbreaks: Attacks that alter inputs in ways invisible to users but impactful to the model. "imperceptible jailbreaks"
- In-context demonstrations: Examples embedded in the prompt to condition the model’s behavior during inference. "in-context demonstrations of harmful content"
- Instruction-tuned LLMs: Models fine-tuned to follow user instructions and produce helpful responses. "instruction-tuned LLMs"
- I-Greedy Coordinate Gradient (I-GCG): A variant of GCG with improved convergence via multi-coordinate updates and initialization strategies. "-Greedy Coordinate Gradient (-GCG)"
- LLM tokenizers: The components that split text (including invisible Unicode) into tokens processed by the model. "LLM tokenizers"
- Log-likelihood: The logarithm of the probability assigned by the model to a sequence or token, used as an optimization objective. "maximizing the log-likelihood of target-start tokens"
- Multi-token block: A fixed sequence of tokens produced by a tokenizer for a single character or selector. "fixed multi-token block"
- Open Prompt Injection dataset: A benchmark for evaluating prompt injection vulnerabilities. "Open Prompt Injection dataset"
- Persuasive Adversarial Prompts (PAP): A jailbreak method that crafts persuasive text to elicit unsafe outputs. "Persuasive Adversarial Prompts (PAP)"
- Prompt injection: A technique that injects adversarial instructions to override the original user task. "prompt injection attacks"
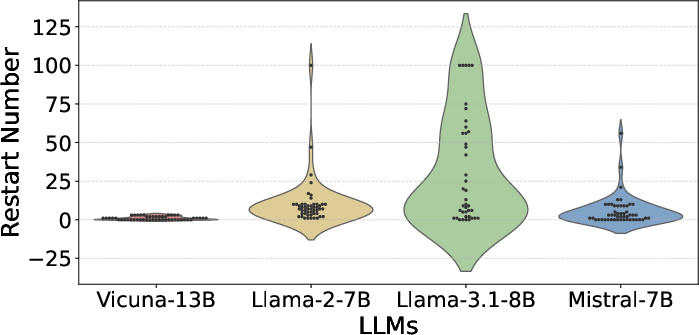
- Random restart: Re-running the attack from different initial states to increase the chance of success. "random restart with multiple inferences in temperature one"
- Random search: A black-box optimization method that explores candidate changes at random and keeps improvements. "random search"
- Safety alignment: Mechanisms and training that constrain models from producing unsafe content. "bypass safety alignment"
- Semantic judge: An evaluator (often an LLM) that assesses whether outputs meet certain semantic criteria. "use GPT-4 as a semantic judge"
- Simple Adaptive Attack: A method combining a crafted template with random search to elicit affirmative starts. "Simple Adaptive Attack"
- Target-start tokens: Specific initial tokens (e.g., “Sure”) whose increased likelihood helps trigger unsafe responses. "target-start tokens"
- Temperature: A sampling parameter controlling randomness in generation. "temperature one"
- Token IDs: The integer identifiers assigned to tokens by a tokenizer. "token IDs"
- Tokenization: The process of converting text into tokens; subtle changes can alter model processing. "tokenization is ``secretly'' altered."
- Tree of Attacks with Pruning (TAP): A search-based jailbreak technique that explores and prunes attack paths. "Tree of Attacks with Pruning"
- t-SNE: A dimensionality reduction technique used to visualize high-dimensional embeddings. "t-SNE"
- Variation selectors: Unicode characters that specify glyph variants and can be invisibly appended to text. "Unicode variation selectors"
- Zero-width characters: Invisible Unicode characters that affect processing without changing visible text. "zero-width characters (e.g., U+200B)"
Collections
Sign up for free to add this paper to one or more collections.