- The paper demonstrates that LLMs encode six distinct metacognitive states that are linearly decodable and organized across transformer layers.
- It reveals that activation steering can causally modulate specific dimensions—such as computational effort and self-assessed capability—with measurable effects.
- Results show that joint control and cross-domain generalization support a modular latent control manifold, advancing reliable LLM evaluation and deployment.
Introduction and Motivational Context
This paper develops a systematic, mechanistic analysis of functional metacognition in LLMs, moving beyond behavioral observations of evaluation awareness to demonstrate that a set of dissociable, internal metacognitive state variables are encoded, decodable, and in several cases causally effective within the residual stream activations of diverse LLM architectures.
The study is motivated by the observation that LLMs exhibit context-sensitive shifts in reasoning behavior, especially regarding evaluation scenarios, but prior literature has generally modeled such phenomena as a unitary artifact ("test mode") rather than as a structured internal geometry. This work proposes that LLMs maintain an explicit, decomposable subspace of functional metacognitive states analogous to latent self-related variables in human reasoning. Six such dimensions are formalized: evaluation awareness, self-assessed capability, perceived risk, computational effort, audience expertise adaptation, and intentionality.
Methodology and Framework
Functional metacognition is operationalized as a set of paired prompt framings designed to manipulate only the self-related context of the LLM, holding all task content constant. For each of the six candidate dimensions, 200 positive/negative prompt pairs are constructed that induce measurable shifts in response style and content. The analysis pipeline consists of three sequential experimental protocols:
- Probing: Linear probes (logistic regression classifiers) are trained on layerwise residual stream activations, using the prompt last-token hidden state, to decode each metacognitive dimension. Probe accuracy is evaluated across five model scales and two architectures (Qwen and Llama-4).
- Causal Intervention (Activation Steering): Probe-derived directions in activation space are selectively injected during generation (steering), and the resulting shifts in composite behavioral metrics are quantified.
- Generalization and Joint Control: Probes are tested for cross-task transfer to out-of-domain factual QA sets not seen during probe training, and multidimensional joint steering (simultaneous intervention along all six probes) is conducted to evaluate independence and controllability.
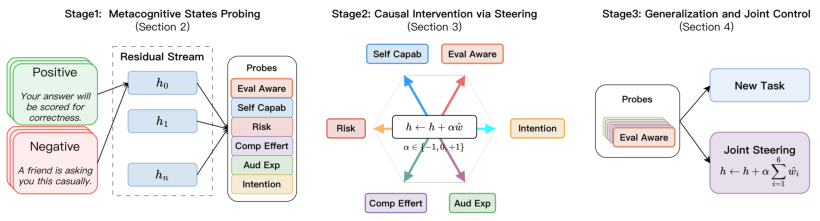
Figure 1: The experimental framework—probing, steering, and generalization—systematically decomposes and tests metacognitive representation and causality in LLMs.
Probing Results: Scale, Layerwise Localization, Structural Independence
Linear Decodability and Emergent Structure
All six metacognitive states are linearly decodable with increasing accuracy as model scale grows. In Qwen models, probe accuracy scales from 0.63 (0.6B), 0.85 (14B), to near-perfect separation at 30B and 235B, while Llama-4 lags at 0.74 average accuracy and exhibits below-chance performance for audience expertise. There is a sharp capacity threshold (∼10B) above which all six dimensions become robustly encoded.
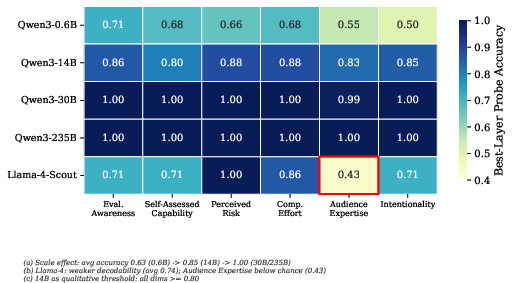
Figure 2: Best-layer linear probe accuracy for each metacognitive dimension; scale dependence and dimension hierarchy are evident.
Layerwise Profiles
Layerwise accuracy curves reveal that "low-level" states (effort, risk, evaluation) are encoded immediately in early layers, while "high-level" audience and intentionality states emerge only after progressive computation in deeper blocks. For large-scale Qwen models, computational effort is decodable at the first block, while audience expertise requires many transformer layers for robust separation.
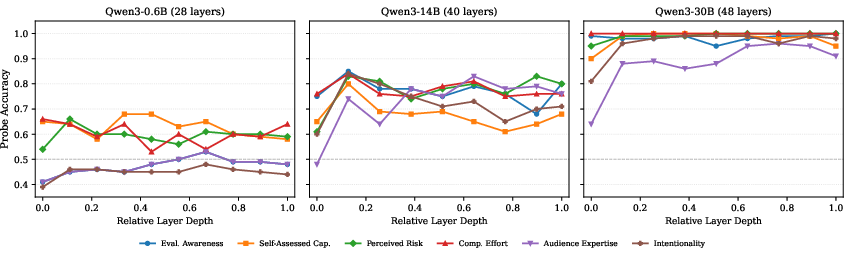
Figure 3: Probe accuracy as a function of layer depth and model scale; early encoding for some states, gradual refinement for others.
Structural Orthogonality
Pairwise cosine similarities confirm that probe directions form a near-orthogonal basis in activation space (maximum off-diagonal ∣cosθ∣<0.25, mean <0.06). PCA of mean activation differences indicates that while a "prompt has been modified" factor dominates superficial differences, the discriminative probes isolate independent geometries corresponding to each state.
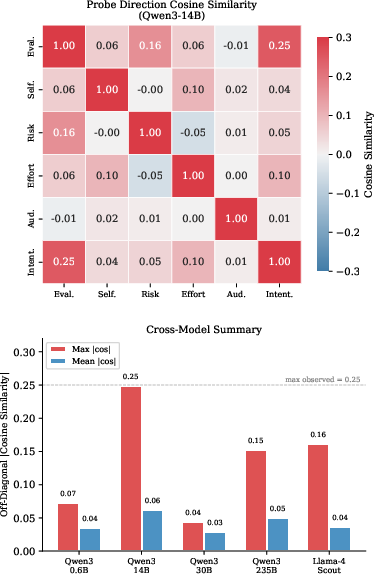
Figure 4: Cosine similarity matrices demonstrate the independence of the six metacognitive axes.
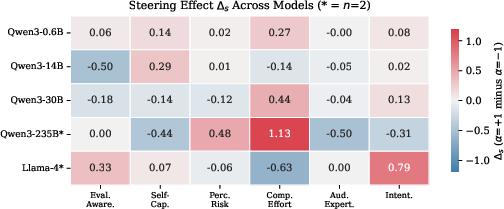
Causality: Activation Steering and Behavioral Modulation
Activation steering experiments probe whether probe-derived directions are causally downstream. Key results:
These results demonstrate that a subset of linearly decodable metacognitive states (notably, computational effort and capability) are also causally effective, while others remain representationally silent for generation.
Generalization and Joint Control: Task-Independence and Simultaneity
Cross-Task Transfer
Probes trained on mathematical and knowledge-intensive tasks (GSM8K, MMLU-Pro) are applied without retraining to an out-of-domain factual QA corpus (SimpleQA). Four of six dimensions transfer with ≥75% accuracy (random baseline 50%), and two reach 100% (mean for Qwen family: 0.81). This provides strong evidence against task-specific shortcut or LoRA-style adapter explanations.
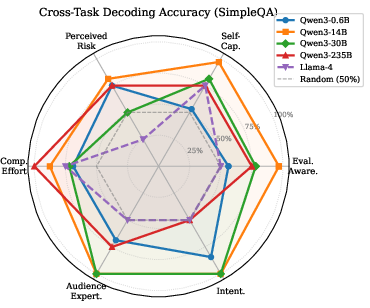
Figure 6: Cross-task probe transfer performance; Qwen-14B and Qwen-30B models generalize metacognitive decoding to new task domains, while Llama-4 approaches chance.
Multi-Dimensional Orthogonal Steering
Joint control experiments inject all six probe directions simultaneously at their respective best layers. With increasing model scale, joint steering shifts more dimensions in the predicted direction (1/6 at 0.6B, 5/6 at 30B, 4/6 at 235B), confirming lack of destructive interference and genuine geometric independence of these internal variables.
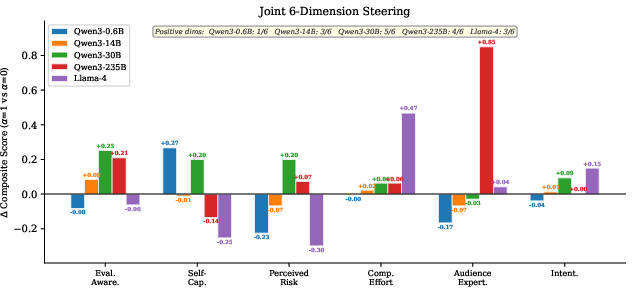
Figure 7: Change in per-dimension composite behavioral score under joint six-axis intervention—joint controllability grows with scale.
Qualitative analysis shows marked coherence: responses become more formal, concise, confident, and on-task, with systematic reductions in hedging and increased explicit answer formatting under multi-steering.
Contrasts with Adapter Hypothesis
A systematic experimental matrix rules out the alternative hypothesis that probe vectors correspond to task/domain-specific shallow features rather than genuine metacognitive states. The empirical signature—generalization, orthogonality, joint control—matches only the functional metacognition hypothesis, not the adapter hypothesis.
Limitations
Key limitations include:
- Decodability vs. causality: Several states (notably audience expertise) are reliably decodable but not causally active, indicating that linear separability does not guarantee intervention efficacy.
- Restricted geometry: The analysis is limited to linear contrasts and binary framings; the full structure of functional metacognition could span nonlinear manifolds or support more nuanced, high-arity factors.
- Evaluation confound: Behavioral validation relies on LLM-based metrics, implicating potential evaluator-model covariance.
Theoretical and Practical Implications
The existence of decomposable, controllable metacognitive subspaces in LLMs has both theoretical and operational consequences:
- Theoretical: These findings instantiate a modular, latent control manifold in LLMs, analogous to neuromodulatory axes in biological cognition (e.g., confidence, risk sensitivity; see [Montague et al., 1996], [Fleming, 2024]). They suggest that self-related functional states are not emergent artifacts, but distinct computational objects accessible to mechanistic analysis and intervention.
- Evaluation: Benchmark performance is not a pure reflection of task competence, but is modulated by the model's internal metacognitive configuration—complicating attempts at objective model comparison or reliability assessment.
- Deployment and Control: Activation steering offers a practical, training-free mechanism to dynamically adjust self-assessment, caution, verbosity, and related behavioral facets, relevant for reliable, context-sensitive deployment and alignment.
- Future Directions: Advancing unsupervised discovery of higher-rank metacognitive manifolds, comparing architectures/training protocols for their impact on metacognitive subspaces, and integrating activation steering into adaptive serving pipelines are promising research avenues.
Conclusion
This paper systematically decouples evaluation artifacts from genuine internal metacognitive variables in LLMs using mechanistic, probe-based decomposition. It demonstrates that multiple, orthogonal dimensions of self-related state are linearly decodable, often causally active, and generalize across tasks and domains. The functional metacognition hypothesis is strongly supported, and the approach shifts the scientific focus from benchmarking behavioral artifacts to controlling and interpreting latent control states, with substantial implications for reliable evaluation, safe deployment, and the future design of adaptive, self-modulatory AI systems.