- The paper introduces a meta-d' and signal detection theory approach to quantify LLMs' ability to assess and regulate uncertainty in binary decision tasks.
- Experimental results demonstrate variable metacognitive efficiency across models, with GPT-5 achieving M_ratio values ranging from 0.65 to 0.90 depending on the task.
- The study shows that LLMs adjust their decision thresholds in response to risk, highlighting practical implications for model selection and enhanced human-AI collaboration.
Introduction
This work addresses the quantification and interpretation of metacognitive competence in modern AI, focusing on LLMs. The paper delineates rigorous techniques for evaluating metacognitive sensitivity and control—specifically, the degree to which LLMs assess and regulate their own uncertainty in binary decision tasks. Drawing on methodologies from cognitive neuroscience and psychology, the authors advocate the adoption of the meta-d′ framework, along with signal detection theory (SDT) approaches, as robust gold-standards for metacognition analysis in AI systems. Empirical results are presented for three leading LLMs (GPT-5, DeepSeek-V3.2-Exp, and Mistral-Medium-2508) across multiple tasks with varying risk and uncertainty profiles.
The core methodological contribution is an argument for the meta-d′ framework as a superior metric for metacognitive sensitivity. Meta-d′ measures the ability of an agent to discriminate between correct and incorrect decisions via confidence ratings, controlling for differences in primary task performance (d′). The central insight is that raw indices of metacognitive sensitivity (e.g., confidence-accuracy correlations) are confounded by the variance in type 1 performance, and only ratios such as Mratio=meta-d′/d′ provide task- and model-comparable measures of metacognitive efficiency.
Additionally, the authors extend the SDT formalism to analyze the spontaneous regulation of the decision criterion (c) by LLMs under manipulated risk conditions. They probe whether models calibrated their choices conservatively when certain responses were associated with higher ostensible risk, operationalized through carefully controlled prompts.
Experimental Paradigm
Empirical evaluation utilized two classes of experiments:
- Meta-d′ Experiments: Each LLM performed three binary forced-choice tasks (sentiment analysis, oral vs. written text classification, and word depletion detection). After each judgment, the LLM rated its confidence on a 5-point scale. This experimental arrangement enables the quantification of d′, meta-d′, and d′0 for each model-task pair.
- d′1-Calibration Experiments: The same discrimination tasks were presented, but now the reward/risk configuration for each possible response was manipulated at the prompt level. The type 1 decision criterion d′2 and its normalized form d′3 were computed to evaluate models' adaptive modulation of response bias as a function of contextual risk.
Results
The analysis demonstrated measurable, albeit suboptimal, metacognitive sensitivity (d′4) in all three LLMs across all tasks. d′5 values, representing metacognitive efficiency, varied by model and task, with values spanning from moderate (d′6) to near-optimal (d′7). Critical findings include:
- Task Dependence: Considerable intra-model variance of d′8 across tasks, implying that model-level metacognitive profiles are context-sensitive rather than global.
- Model Comparison: GPT-5 routinely exhibited higher metacognitive efficiency relative to DeepSeek-V3.2-Exp, with Mistral-Medium-2508 displaying intermediate or context-variable d′9 (Figure 1).
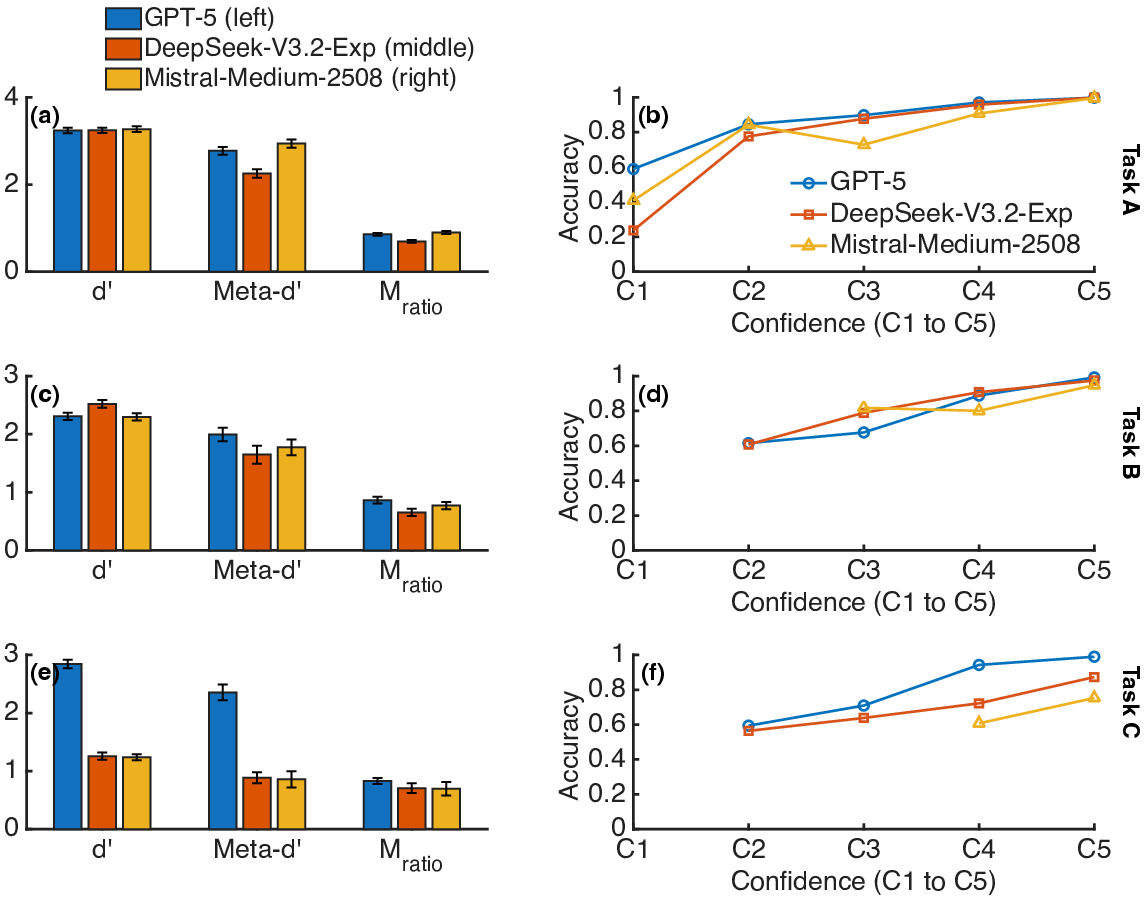
Figure 1: d′0, meta-d′1, and d′2 for all three models and tasks, revealing variable metacognitive efficiency across models and task domains.
The distribution of conditional confidence ratings further substantiated metacognitive differentiation, with confidence more sharply distinguishing correct from incorrect responses in settings with higher d′3 (Figure 2).
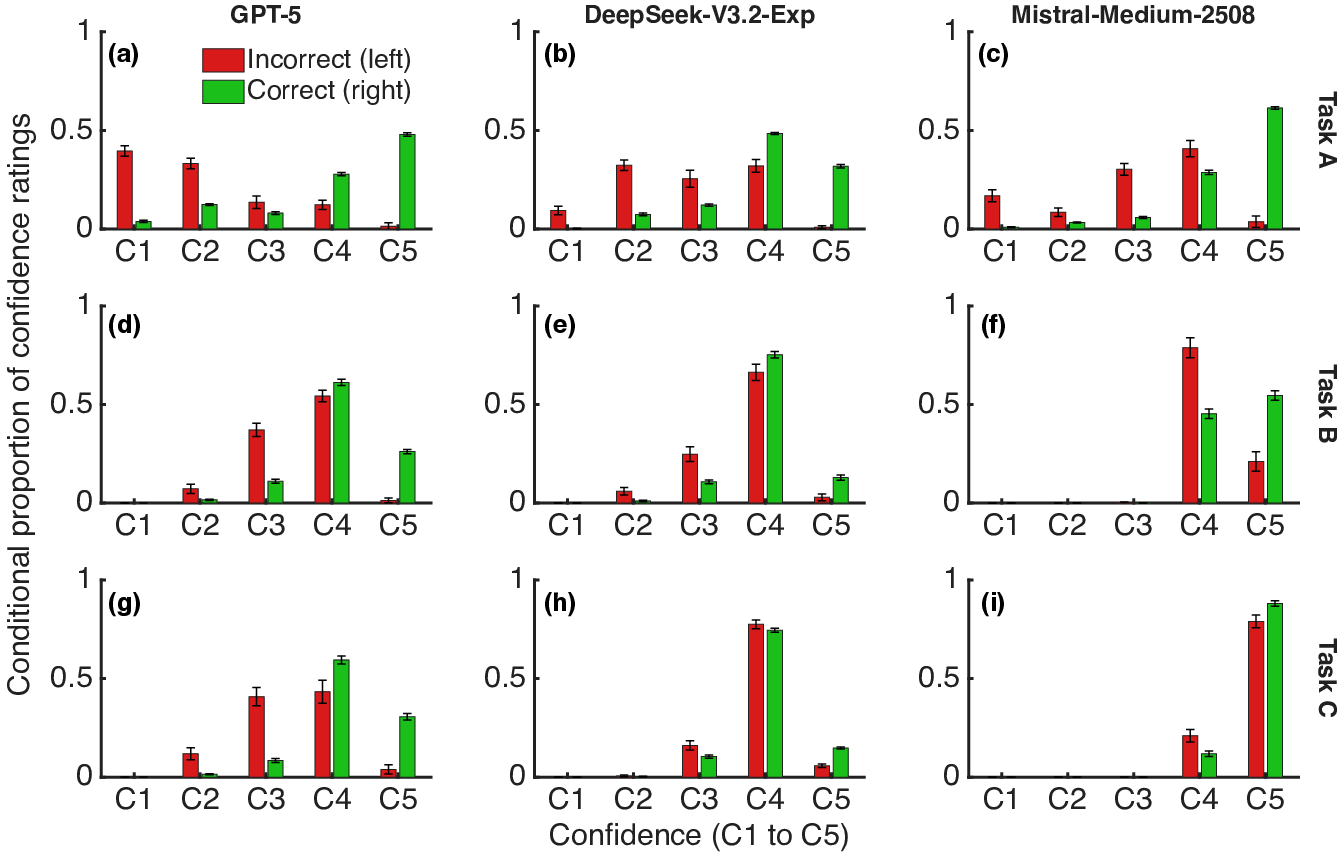
Figure 2: Conditional proportions of confidence ratings, comparing correct and incorrect primary responses across tasks and models.
Contextual Regulation of Decision Criterion
In scenarios where the risk associated with specific responses was manipulated via prompting, all tested LLMs (especially GPT-5) demonstrated systematic shifts in decision criterion d′4. The direction and magnitude of these criterion shifts adhered to the manipulated risk profile, with higher risk inducing conservative (i.e., risk-averse) decision thresholds for the penalized class (Figure 3).
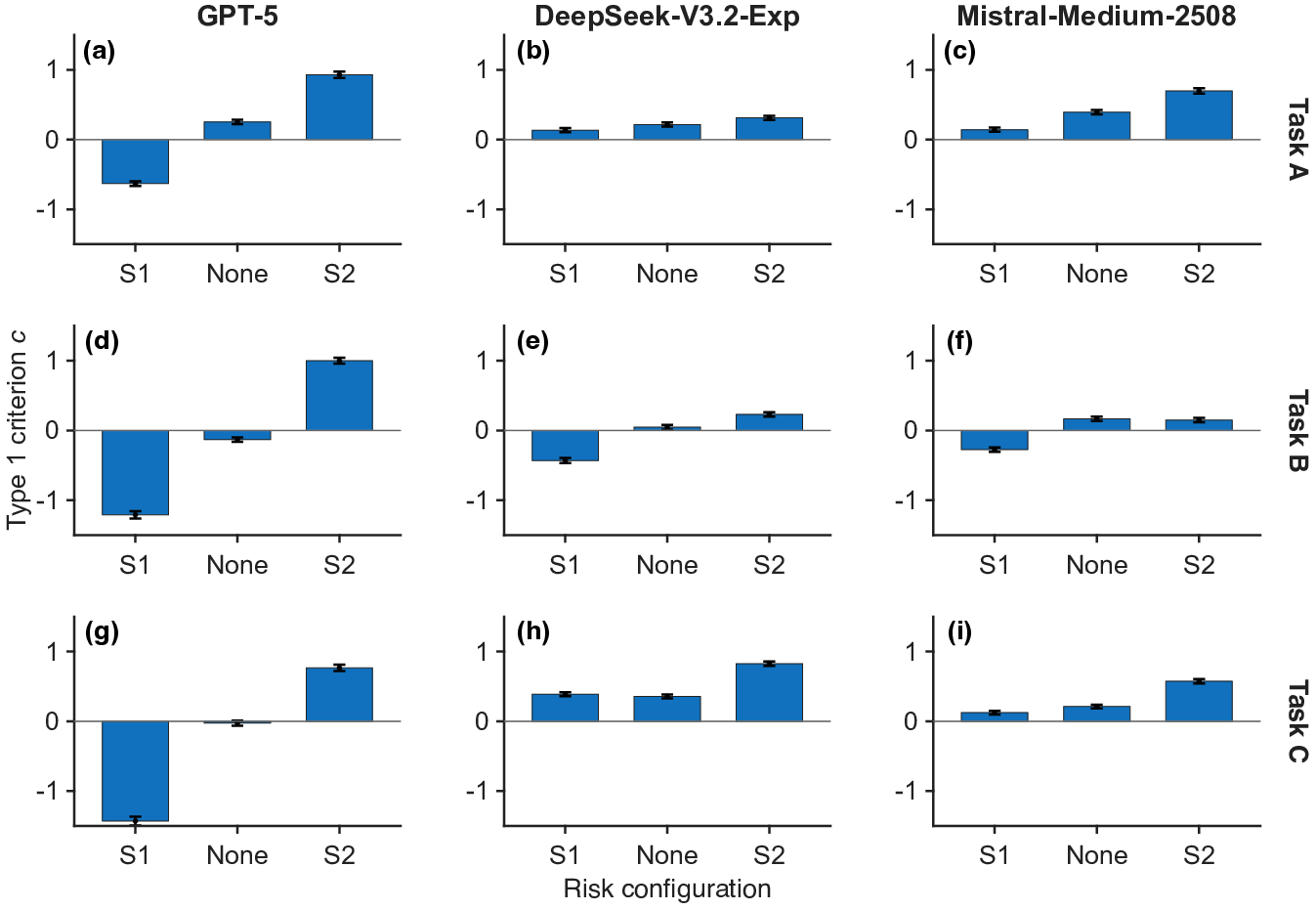
Figure 3: Type 1 criterion d′5 across three risk configurations for all models and tasks, showing effective criterion calibration in response to prompt-induced risk.
Normalized criterion d′6 analysis confirmed that adaptive regulation persisted after accounting for differences in sensitivity, reinforcing the finding that LLMs modulate their response policies to reflect risk contexts (Figure 4).
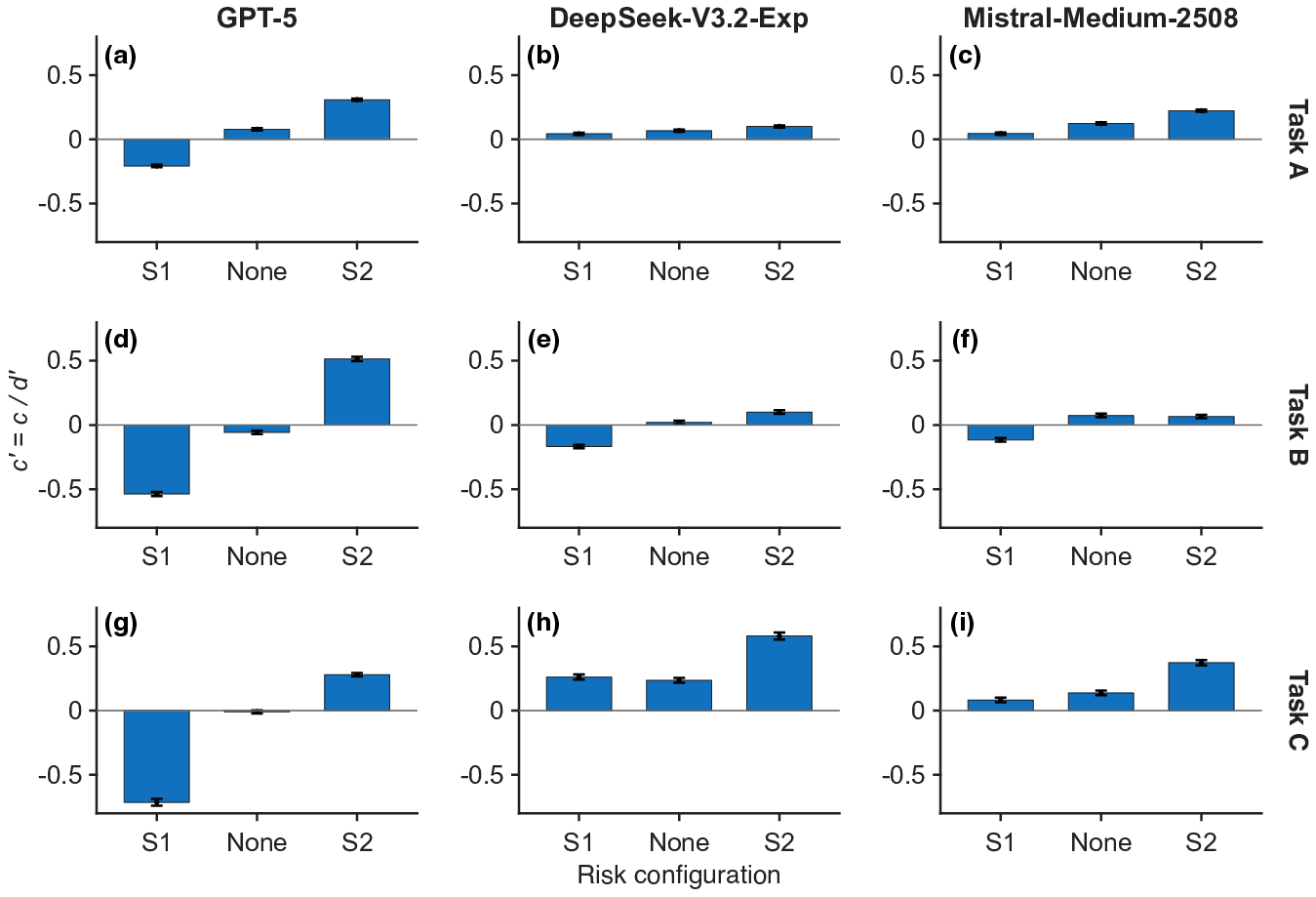
Figure 4: d′7 across risk configurations, indicating robust context-dependent criterion modulation.
Sample Size and Stability
Extensive simulation and real-trial data validated the statistical reliability of SDT-based estimators for both type 1 and metacognitive sensitivity metrics, even at high values of d′8 (Figure 5). The hierarchical Bayesian estimation procedure further enhanced measurement stability with large trial counts.
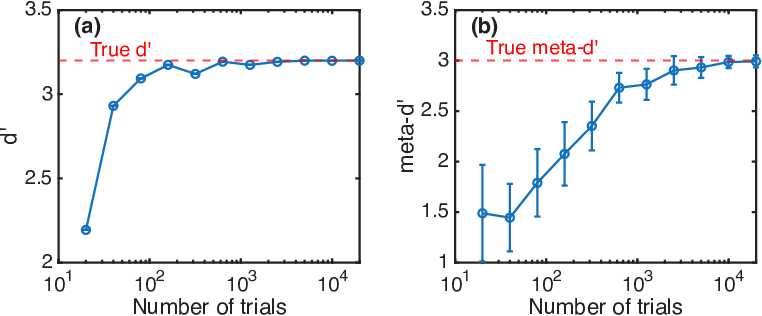
Figure 5: Convergence of d′9 and meta-d′0 estimation as a function of number of trials, supporting the reliability of results.
Implications and Future Directions
The demonstrated methodology enables principled and comparative assessment of AI metacognition, critical for model selection in high-stakes or collaborative decision environments. Practical implications include:
- Model Selection: Distinguishing between models on the basis of metacognitive efficiency, not merely task accuracy, is essential for contexts where uncertainty quantification and self-critique are operationally vital (e.g., medical diagnostics, autonomous agents).
- Human-AI Collaboration: Accurate and calibrated confidence signaling can inform more effective human-AI interaction strategies, aligning with recent findings on uncertainty communication [steyvers2025improving].
- Risk Reactivity: The ability of LLMs to dynamically calibrate their decision thresholds in response to explicit risk cues suggests latent capabilities for policy adaptation and context-sensitive decision making.
The analysis reveals that while LLMs possess measurable metacognitive sensitivity, it is consistently suboptimal relative to type 1 information—contradicting any claim to "human-level" or "ideal observer" metacognition at scale. This suboptimality is neither uniform nor negligible and can be significantly modulated by both task and prompt design. The authors note that many variations in procedure (batch submission, sequential prompting, scale design, parameterization) and more complex tasks (e.g., requiring exploration-exploitation tradeoffs) offer fruitful avenues for future research. Notably, the Eleusis Benchmark is suggested as a promising paradigm to probe more active and complex forms of AI metacognition, particularly when coupled with psychophysical analysis.
Importantly, the present methodology offers a conceptual grounding for addressing "hallucinations"—viewed here as highly confident errors—by separating metacognitive failures from mere factual inaccuracies.
Conclusion
This work establishes a robust methodological baseline for the scientific study and comparative analysis of metacognition in LLMs. The use of meta-d′1 and SDT-derived bias metrics enables fine-grained, theoretically justified measurement of models’ capacity for self-evaluation and adaptive control under risk and uncertainty. The demonstrated empirical results reveal that while current LLMs display measurable metacognitive competence, substantial gaps remain to the ideal observer standard, with significant variability across models and tasks. The framework supports future evaluation protocols as AI is further integrated into critical, collaborative, or autonomous decision-making processes.