- The paper demonstrates that MLS-Bench isolates algorithmic innovation by systematically evaluating 140 tasks across 12 ML domains.
- The paper reveals a significant gap between agent-driven tuning and human-designed, scalable ML innovations.
- The paper confirms that increased compute and context yield marginal gains, emphasizing the need for robust scientific reasoning in ML research.
Rigorous Evaluation of Algorithms That Build Better AI: An Expert Analysis of MLS-Bench
Motivation and Benchmark Positioning
MLS-Bench addresses a critical gap in the evaluation of advanced AI agents: the need to rigorously and systematically assess an AI system's capacity to invent generalizable and scalable ML methods rather than simply tune or recombine existing methods. While agent benchmarks for ML engineering and competition-style challenges (e.g., MLE-Bench, MLAgentBench, MLR-Bench) have proliferated, these tasks primarily reward engineering optimizations, pipeline tuning, or dataset-specific heuristics, obfuscating genuine algorithmic innovation. MLS-Bench directly targets ML science: the production of reusable, transferable method-level contributions that persist under controlled evaluation and across scales.
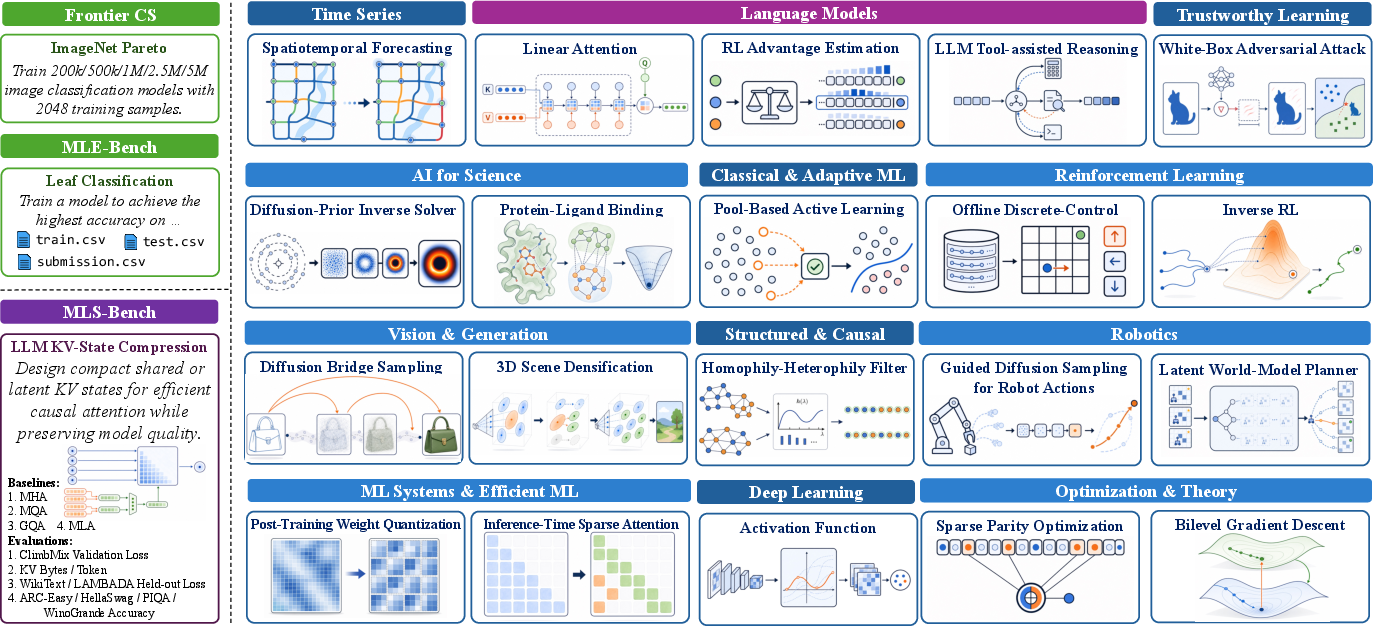
Figure 1: MLS-Bench provides a broad, holistic benchmark spanning 140 tasks across 12 ML domains, enabling precise comparisons to prior task typologies and benchmarks.
MLS-Bench Design Principles and Structure
MLS-Bench comprises 140 tasks grouped over 12 major ML domains (including language modeling, optimization, deep learning, vision, RL, ML systems, and trustworthy learning). Each task is meticulously formulated to isolate a targeted method class under strict edit scopes—ensuring that observed improvements derive exclusively from substantive changes to the algorithm or method, not from auxiliary modifications such as harness rewrites, hyperparameter exploits, or model scale increases. This is enabled via:
- Baseline-Calibrated Scaffolding: Editable regions are just sufficient to faithfully express all strong human baselines—any broadening or narrowing breaks either expressive power or attributional correctness.
- Parameter-Budget Enforcement: For tasks modulating model structure, capacity is capped at baseline level, nullifying "scale hacking."
- Cross-Setting Generalization: Each task includes at least three distinct evaluation settings; aggregation is structured such that gains in one cannot compensate for failure in another, enforcing actual generalization.
- Multi-Seed Stability: Tasks use multiple random seeds to guarantee score orderings reflect method merit, not variance.
- Strong Human Baselines in Context: Baseline method implementations and results are supplied in the test context, measuring the system’s ability to innovate given what is already known.
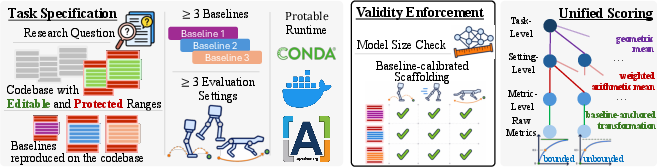
Figure 2: MLS-Bench’s methodology enforces task specification, validity checking, and integrated, bounded scoring to ensure rigorous, reproducible evaluation.
Empirical results in the benchmark expose a salient method-discovery gap. Fifteen leading agent architectures (e.g., Claude Opus, GPT-5.x, Gemini Pro, DeepSeek, Qwen) are compared to human-implemented SOTA methods. Even after iterative refinement with all strong baselines provided, frontier agents remain far from reliably closing the gap with human-designed algorithms when tasked with genuine method innovation as opposed to engineering refinements.

Figure 3: MLS-Bench-Lite evaluations of fifteen models underscore a persistent discovery gap between LLM agents and human SOTA across all covered domains.
Crucially, vanilla (first proposal) vs. iterative (agent-driven, multiple tests) results demonstrate that while some improvements are captured through exploration and recombination, agent approaches typically saturate below baseline performance. This deficit is particularly pronounced in settings requiring novel hypothesis generation and cross-distribution generalization; agents are far stronger at low-level parameter tuning or combining familiar code motifs than at constructing new algorithms that survive MLS-Bench’s multi-setting, baseline-calibrated controls.
Ablations: Scientific Innovation vs. Engineering, Hacking Controls, and Generalization
Ablation studies demonstrate that:
- Scientific Innovation vs. Engineering: Prompting agents to perform scientific method discovery yields notably weaker performance than prompting for engineering optimization; weaker agents, in particular, display a marked preference for tuning or recombination of existing ideas over genuine innovation.
- Hacking Defenses: Removing model capacity checks allows agents to trivially defeat baselines via scale increase, rather than through method-level improvements—affirming the necessity of capacity enforcements within the benchmark.
- Generalization: Multi-setting tasks reveal that iterative agent refinement may generalize within-distribution but rarely provides robust solutions OOD, with most agent improvements anchored to visible evaluation cases.
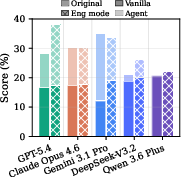
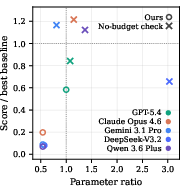
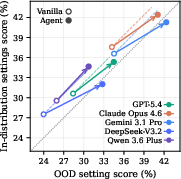
Figure 4: Evaluation protocol ablations show that agent models primarily excel at engineering optimization, that budget checks block model-size exploitation, and that iterative refinement yields only minor OOD generalization.
Analysis of Scaling, Resource Allocation, and Context Use
Scaling inference-time compute (via more tokens, more exploration, or population-based search) produces incremental improvements on simpler tasks but saturates rapidly; more compute, search, or contextual knowledge alone does not bridge the scientific innovation gap. Test-time training approaches (e.g., TTT-Discover) tend to overfit observed settings, deteriorating in hidden or OOD scenarios. In compute-constrained, resource-adaptive settings—modeling human scientific workflow constraints—agents not only fail to improve, but often worsen as they allocate trials suboptimally.
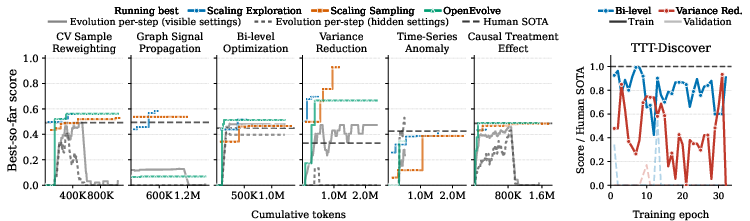
Figure 5: Additional inference, exploration, and evolutionary compute at test-time only modestly improves agent scores and can exacerbate overfitting to visible settings.
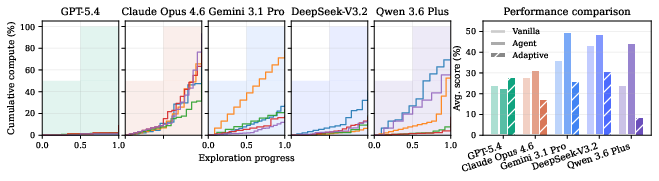
Figure 6: In adaptive compute allocation experiments, agents given freedom to choose experiments often underperform compared to fixed protocols, highlighting deficiencies in resource allocation and experimental design.
Moreover, the injection of extra context (e.g., web search, detailed derivations, additional theoretical background) confers only modest gains, primarily in agents with stronger base capabilities—indicating that the primary limitation is not access to knowledge but rather the inferences and hypothesis generation abilities required to transform knowledge into new mechanisms.
Agent Behavior Patterns and Failure Modes
Case studies and expert evaluations indicate that agents:
- Consistently recombine ingredients from visible baselines but rarely introduce truly novel ideas, and only sporadically supply scientifically motivated hypotheses for their changes.
- Performance is strongly correlated to code similarity with strong baselines (particularly among less capable models), rather than distance from past methods.
- Even when agents attempt formal novelty (e.g., new normalization or quantization schemes), the underlying mechanisms typically underperform, indicating a lack of the experimental design, ablation, and reasoning required for scalable algorithmic validation.
Implications and Future Directions
MLS-Bench’s comprehensive evaluation reveals several critical implications:
- Current LLM Agents Remain Fundamentally Limited in their ability to autonomously produce generalizable, scalable innovations in machine learning. The bottleneck is not simply in proposal generation but in the design of controlled, informative experiments and the ability to generalize claims about new methods beyond specific benchmark instances.
- Engineering, Tuning, and Recombination are relatively tractable for agents, but the transition to scientific discovery — forming hypotheses, designing evidence, and validating at scale — remains elusive.
- More Compute and More Context are Insufficient: The gap exposed by MLS-Bench pertains to higher-order research workflows, not merely raw model scale or context-windows.
- Rigorous Evaluation Protocols are Essential: Without scaffolded edit boundaries, baseline calibration, and capacity controls, ostensible "discovery" would be swamped by optimizations orthogonal to method-level progress.
MLS-Bench stands as a durable community resource that will chart future progress in research agent architectures, LLM scientific reasoning, and autonomous ML research workflows. The gap it identifies highlights the need for advances in agent-based hypothesis formation, adaptive evidence gathering, cross-distribution synthesis, and the nuanced reasoning that underpins modern ML science.
Conclusion
MLS-Bench sets a new standard for evaluating AI systems in their capacity to build better AI through true algorithmic invention. It exposes persistent and quantifiable shortfalls of current agent technologies in transcending engineering optimization for scientific, generalizable method discovery. Closing this gap will demand research on scientific reasoning, experimental design, resource allocation, and hypothesis-driven discovery beyond existing paradigms in LLM-based agents. MLS-Bench provides both a rigorous yardstick and a continually evolving testbed for such future developments.
(2605.08678)