- The paper introduces the Bayesian Sensitivity Value (BSV) to assess causal estimator robustness with evidence-based priors, replacing traditional worst-case paradigms.
- BSV employs Monte Carlo sampling to compute expected sensitivity over realistic assumption violations in high-dimensional settings.
- Empirical evaluations in simulations and a diabetes treatment case demonstrate that BSV effectively distinguishes actionable subgroup sensitivities.
Bayesian Sensitivity Analysis for Causal Inference with Evidence-Based Priors
Introduction
This paper rigorously investigates sensitivity analysis in causal inference, emphasizing the limitations of traditional worst-case paradigms in high-dimensional, real-world contexts. Through a detailed generalization of the s-value framework, the authors propose the Bayesian Sensitivity Value (BSV) as a more informative and actionable criterion for quantifying the robustness of causal estimators under domain-informed priors. The approach systematically unifies sensitivity estimation across key causal assumptions: unconfoundedness (ε), conditional outcome model specification (μ), and external validity (pX), and demonstrates its utility both in controlled simulations and a non-trivial diabetes application.
Limitations of Worst-Case Sensitivity Analyses
Conventional sensitivity analysis metrics are typically based on worst-case violations, seeking the minimal deviation from assumed data-generating mechanisms that suffices to reverse the causal conclusion. While this approach is mathematically tractable and conservative, it becomes uninformative and often misleading as the dimension of the underlying assumption space grows, due to the exponential proliferation of implausible violations.
The empirical demonstrations in the paper reveal that worst-case optimal distributions or parameter settings identified by such analysis are frequently at odds with established empirical facts and prior knowledge, particularly when real-world constraints or dependencies between covariates are not respected.
For instance, in high-dimensional settings, the worst-case sensitivity approaches its maximum for nearly all subpopulations and assumption perturbations, making it "flat" and unusable for differentiating which subgroups or covariates drive result instability.
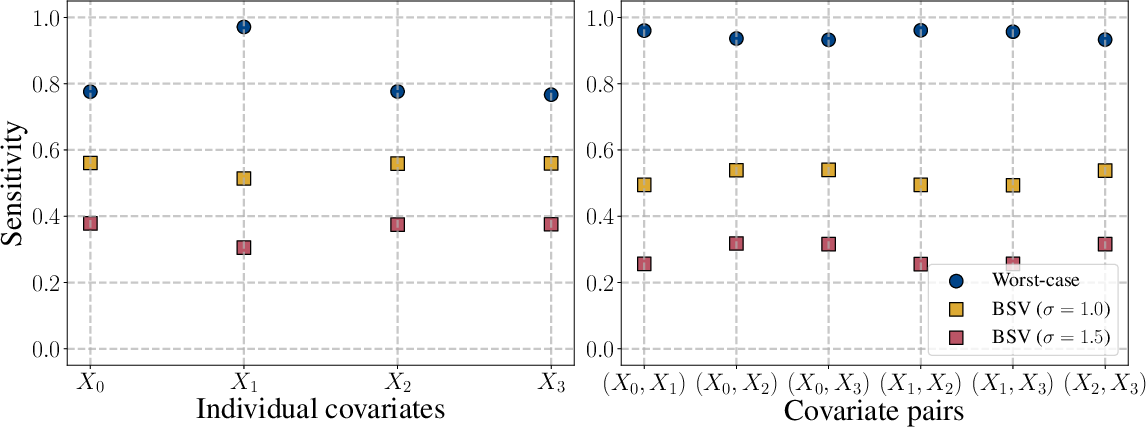
Figure 1: Worst-case sensitivity to unconfoundedness parameter ε increases rapidly as the number of observed confounders and hence the dimension of A grows, making the criterion uninformative.
Generalized Sensitivity Framework
The approach formalizes the impact of assumption violations by considering a unified function a=(ε,μ,pX) parameterizing violations, and studies the consequences of deviations in each factor independently. For a chosen functional component, the set of plausible values (A) and a convex divergence (D) with respect to the baseline are specified. The classical s-value (worst-case) is then the minimal divergence required to cross a user-defined decision threshold for the average treatment effect (ATE).
However, the generalized framework fundamentally diverges by supporting subspace-specific and prior-informed analyses. Practitioners can now partition the vast assumption space in semantically meaningful ways (e.g., focus on particular joint covariate distributions), and leverage empirical or subject-matter knowledge to restrict which violations are evaluated as plausible sources of estimator instability.
Bayesian Sensitivity Value (BSV): Motivation and Definition
To address the excessively pessimistic and practically uninformative nature of worst-case analyses, the BSV is introduced. Instead of optimizing over all possible violations, BSV computes the expected sensitivity (as measured by divergence from baseline) of those assumption-specific perturbations that reverse the causal decision, with respect to a user- or evidence-specified prior ε0 over ε1. This yields:
ε2
Crucially, the BSV is tunable via the prior, admits empirical Bayes instantiations (EBSV) using data-derived distributional estimates, and naturally generalizes to high-dimensional settings without being dominated by unrealistic violation scenarios.
The inferential and algorithmic procedures are Monte Carlo-based: samples are repeatedly drawn from the prior, and those leading to causal decision reversals are used to estimate the BSV, allowing practitioners to report both the likelihood and the plausible "size" of reversal-inducing violations.
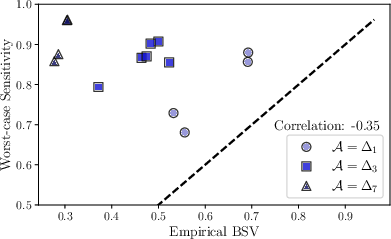
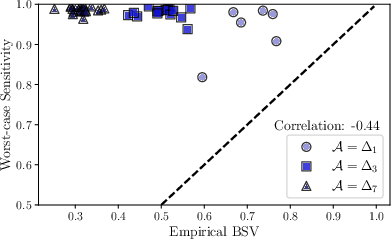
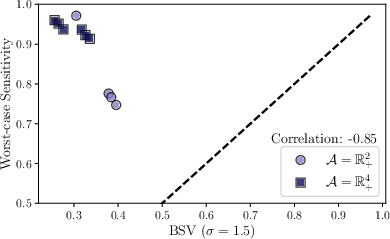
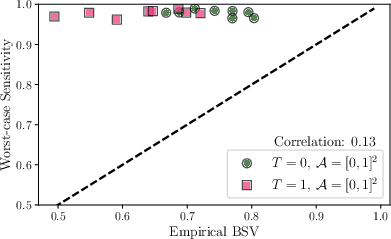
Figure 2: Sensitivity to ε3 under both worst-case and Bayesian criteria, showing that BSV with empirical priors provides meaningful differentiation between subpopulations in high dimensions.
Empirical Evaluation in Simulation and Real-World Settings
High-Dimensional Simulations
Simulated studies over increasing numbers of binary covariates reveal acute shortcomings of worst-case sensitivity: as the assumption space grows, nearly every subpopulation receives maximum sensitivity, eliminating any capacity for prioritization or targeted further investigation.
In contrast, BSV (including with uniform priors) remains variable and continues to discriminate between subsets of covariates and parameter subspaces. Moreover, when empirical priors are used to reflect realistic data-generating processes (e.g., population-level covariate distributions), the patterns identified are notably distinct from both the worst-case and uninformed Bayesian versions.
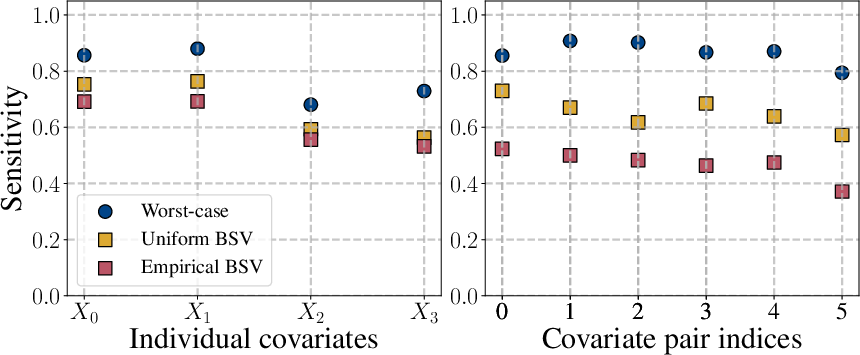
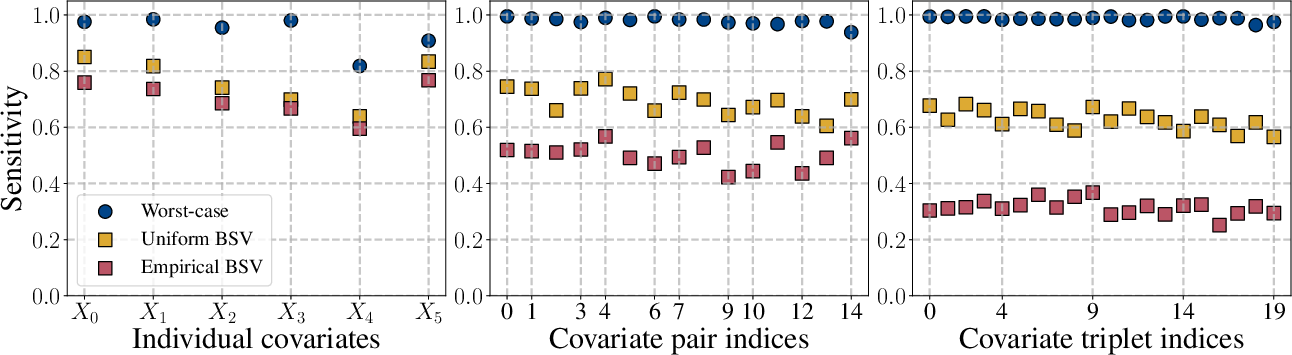
Figure 3: Simulation with four covariates demonstrates that Bayesian criteria retain discriminatory power across subpopulations, whereas worst-case analysis is saturated.
Subgroup Analysis of Conditional Outcome Distributions
Analysis of sensitivity with respect to conditional outcome models (ε4) showcases that worst-case analysis ascribes maximal sensitivity nearly everywhere, thereby failing to distinguish between settings. The BSV, however, identifies lower sensitivity regions (e.g., for the ε5 treatment group), which is critical for resource allocation and robust experimental design.
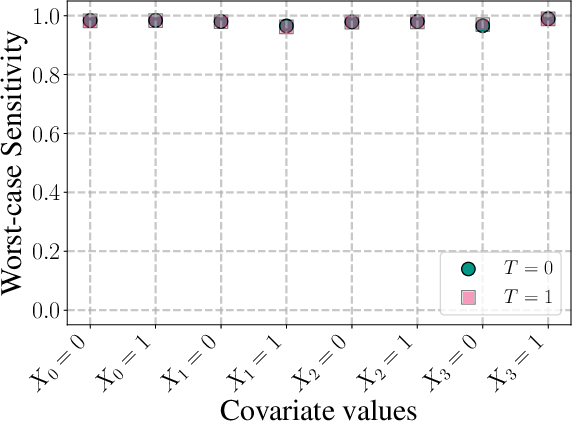
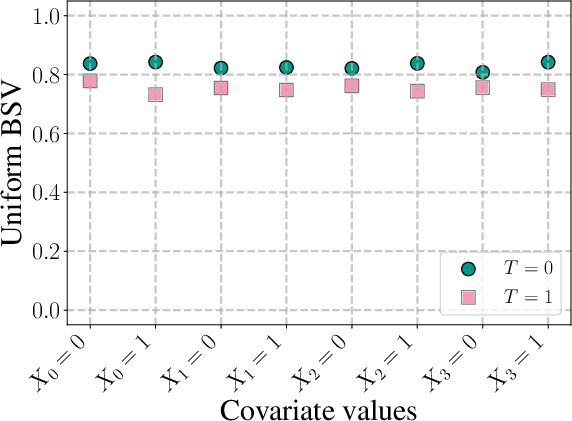
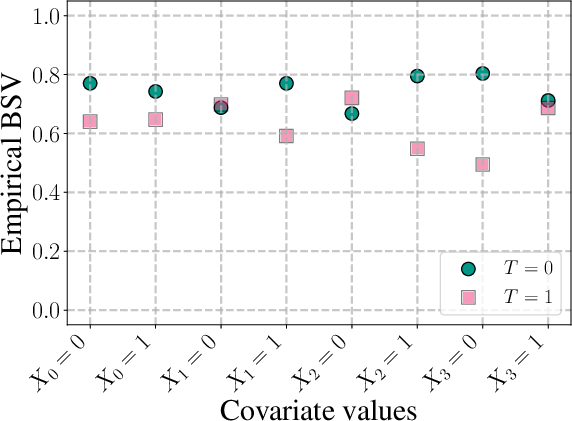
Figure 4: In simulation, BSV with respect to ε6 attributes lower sensitivity to ε7, while worst-case methods attribute maximal sensitivity across all settings, eliminating interpretability.
Practical Application: Diabetes Treatment Efficacy
A real-data case study examines treatment effects (Semaglutide vs. Tirzepatide) on weight loss using observational, language-model-extracted evidence. The external priors are constructed from medical and demographic sources (e.g., NHANES, UCI Diabetes). In this context, BSV exposes that extreme sensitivity indicated by worst-case methods on certain covariate subgroups (e.g., patients with high weight) is not supported when using evidence-based priors; these subpopulations are less prone to estimator instability than the worst-case would suggest. Hence, empirical BSV analyses can guide practical study refinement and experimental follow-up.
Implications and Theoretical Consequences
This work establishes that sensitivity analysis in causal inference must transcend worst-case logic, especially in domains where the assumption space is intrinsically high-dimensional and real-world dependencies can be captured through external databases or empirical priors. The unified BSV formalism ensures that resources and methodological attention can be focused where actual instability under plausible assumption violations threatens validity, as opposed to being driven by combinatorial artifacts of uninformative worst-case optimization.
The approach highlights several critical recommendations for causal inference practice:
- Practitioners should leverage empirical databases to build informative priors for sensitivity computation, rendering sensitivity metrics actionable and interpretable.
- Inference about subpopulation-level sensitivity should be based on expectation, not arbitrary least-plausible paths to conclusion reversal.
- In high-stakes or high-cost settings, the Bayesian approach enables efficient resource allocation, prioritizing subgroups according to realistic robustness assessments.
Limitations and Avenues for Future Work
While BSV addresses many pitfalls of worst-case analysis, it also introduces explicit dependence on the quality and representativeness of the chosen priors. In settings involving fundamentally unidentifiable parameters (e.g., unmeasured confounding coefficients), constructing credible priors from data remains non-trivial. The authors also point out that naive rejection sampling can become computationally prohibitive for rare event estimation, indicating the value of developing more sophisticated constrained samplers (e.g., MCMC with rare-event targeting).
Other worthy extensions include joint analysis across assumption types (rather than univariate perturbations), and theoretically principled selection or aggregation of prior models.
Conclusion
This paper rigorously demonstrates, both theoretically and empirically, that Bayesian sensitivity analysis—grounded in empirical priors—overcomes fundamental limitations of worst-case sensitivity in causal inference. The BSV is capable of distinguishing actionable and robust subpopulation patterns even in high-dimensional and complex settings, and its application to a real-world medical treatment analysis illustrates practical impact. These contributions shift sensitivity analysis toward a paradigm that is more tightly coupled to scientific reality, enabling evidence-based decisions about estimator robustness, resource prioritization, and experimental design.