- The paper demonstrates how Bayesian frameworks encode expert beliefs through priors to stress-test assumption violations in causal inference.
- It details implementation strategies using Stan, addressing challenges such as exposure misclassification, unmeasured confounding, and MNAR outcomes.
- The study reveals that robust estimation via tipping point analyses and nonparametric models quantitatively assesses bias in causal effect estimation.
Bayesian Sensitivity Analyses in Causal Inference: A Unified Implementation-Focused Perspective
Introduction
This work provides an in-depth guide and practical demonstration of Bayesian sensitivity analyses addressing key sources of bias in causal inference from observational data. The paper emphasizes the Bayesian framework's capacity to encode subject-matter beliefs regarding assumption violations through prior distributions, facilitating robust inference by stress-testing untestable assumptions. Implementation-level guidance is foregrounded, highlighting how typical causal questions complicated by exposure misclassification, unmeasured confounding, and missing-not-at-random (MNAR) outcomes can be systematically addressed using Stan.
Bayesian Causal Inference Under Standard Assumptions
The analysis begins from the canonical point-treatment inference setup, where standard assumptions (SUTVA, unconfoundedness, positivity) permit identification of the average treatment effect (ATE), denoted Ψ=E[Y1−Y0], via the g-formula:
Ψ(η,θ)=∫(E[Y∣A=1,L=l;η]−E[Y∣A=0,L=l;η])fL(l;θ)dl.
Here, all unknowns are treated as random variables, and Bayesian posterior inference proceeds by sampling latent parameters (η,θ) given observed data DO. The core implementation issue addressed is the translation of such Bayesian models into Stan, leveraging its explicit blockwise syntax for specifying data, parameters, and model structure, and generating posterior draws of functionals such as the ATE.
Sensitivity Analyses: Stress-Testing Identification and Statistical Assumptions
Bayesian sensitivity analysis is naturally conceptualized as a missing data problem. Assumption violations are recast as the presence of unobserved data (e.g., true exposure, confounder, or outcome) and corresponding nonidentified sensitivity parameters. The typical workflow involves:
- Identifying the estimand in terms of the complete data distribution, including sensitivity parameters.
- Specifying models for all data—including mechanisms of missingness or error—parametrized by both identifiable and nonidentifiable components.
- Using MCMC in Stan to draw samples from the joint or marginal posterior over latent data and parameters.
- Evaluating the estimand (e.g., ATE) across posterior draws.
- Systematically varying sensitivity parameters (often with point mass priors), tracing the effect on posterior inference to visualize robustness or identify “tipping point” thresholds.
Exposure Misclassification
A prototypical example is inference under misclassification of a binary treatment variable. The model distinguishes true exposure A (unobserved) from observed, error-prone A~, parameterizing the misclassification process with sensitivity and specificity parameters (ξ1,ξ2). As these parameters are nonidentifiable, inference under fixed (often literature- or expert-informed) values is standard, allowing the posterior distribution of the ATE to be compared under varying degrees of misclassification.
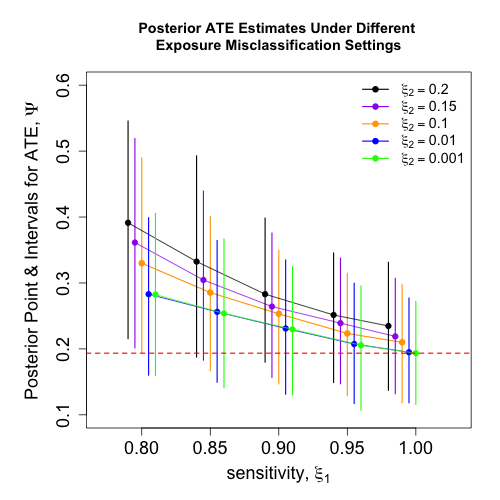
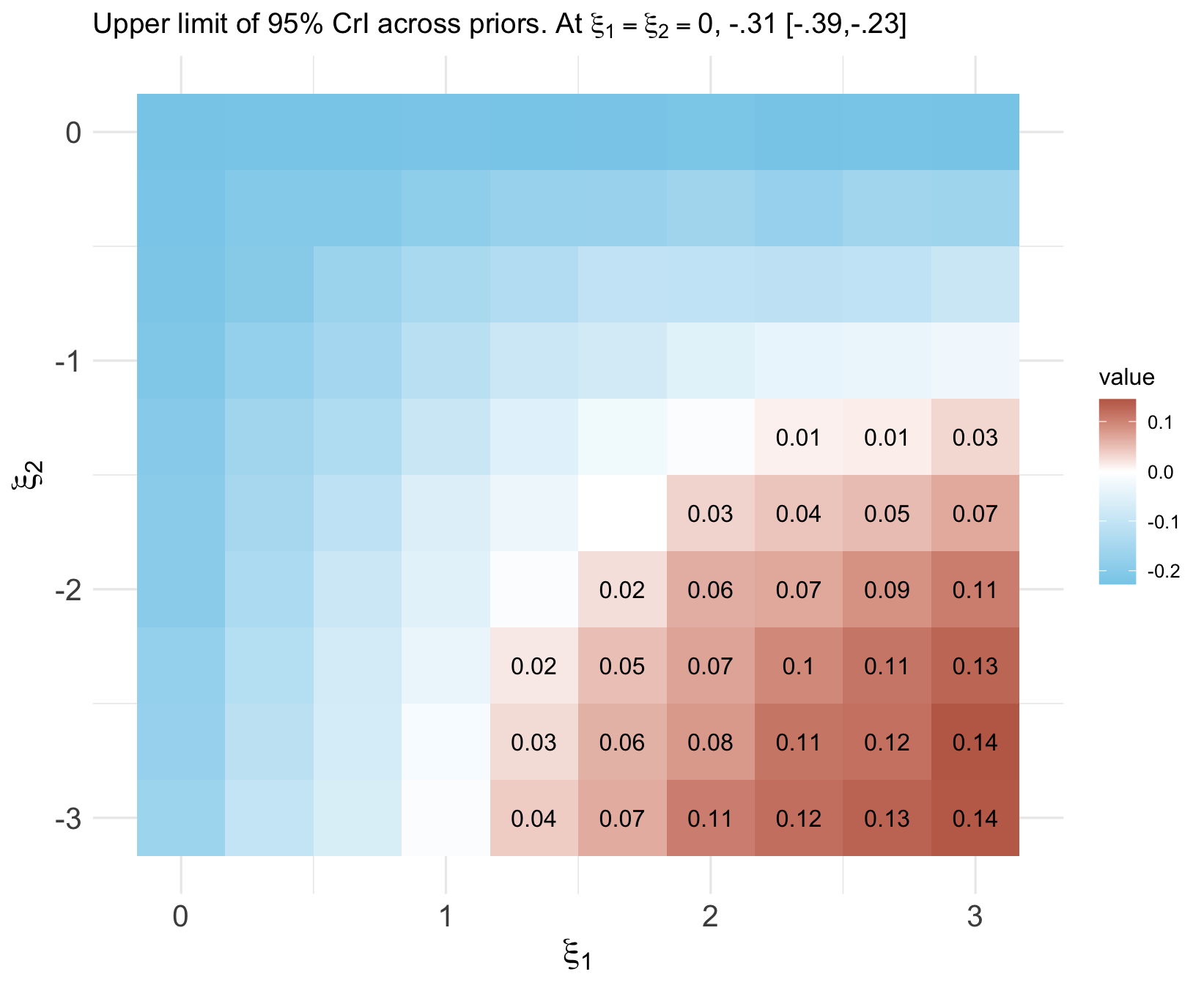
Figure 1: Posterior mean and 95% credible intervals for the ATE under various levels of treatment misclassification, with critical “tipping point” quantification.
Marginalization over the discrete latent indicators is performed analytically to yield a Stan-computable mixture log-likelihood. Results demonstrate nontrivial sensitivity: with increased misclassification (lower ξ1, higher ξ2), ATE credible intervals expand and may cross the null, illustrating potential bias magnitude.
Unmeasured Confounding
For sensitivity to unmeasured confounding, an unobserved continuous confounder U is incorporated into outcome and treatment models, each parameterized by nonidentified log-odds coefficients (ξ1,ξ2). Priors are fixed at null or alternative values, reflecting varying beliefs about plausible confounder effects. Stan implementation is straightforward since latent U is continuous, allowing full Bayesian posterior simulation.
Notably, results illustrate that modest deviations from unconfoundedness (in plausible E-value ranges) can materially alter inferences, often shifting credible intervals to include or exclude null effects—a phenomenon immediately readable from “tipping point” analyses.
Missing Not-at-Random Outcomes
For MNAR scenarios, the missingness mechanism is explicitly modeled as a function of latent outcome, observed treatment, and covariates, governed by sensitivity parameters. Inclusion of outcome in the missingness regression (logistic or otherwise) induces dependence that violates missing-at-random (MAR), necessitating bespoke Bayesian inference. Because Stan does not allow discrete parameters in the sampling block, the paper details analytical marginalization over missing outcomes for the observed data likelihood and mixture-based coding of the posterior.
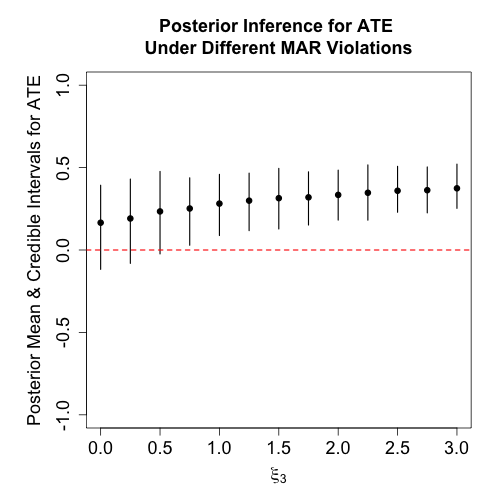
Figure 2: Sensitivity of the ATE to increasing deviations from MAR in the outcome missingness mechanism; credible intervals crossing the null reflect increased sensitivity.
Applied examples show that for datasets with high proportions of missing outcomes, even moderate MNAR deviations rapidly shift posterior inference, emphasizing the practical necessity of explicit sensitivity quantification.
Bayesian Nonparametric Sensitivity Analyses
To address model flexibility and overcome parametric constraints, the paper demonstrates application of truncated stick-breaking (TSB) mixtures as nonparametric priors over the full data-generative process. The mixture induces highly adaptive outcome and covariate regression functions, with the unidentifiable aspects (missingness, misclassification, unmeasured confounding) still captured by explicit, lower-dimensional sensitivity parameters.
When fitting TSB models in Stan, mixture weights are parameterized via Beta priors (stick-breaking process), and standardization for the ATE is performed over the fitted mixture. This approach allows regions of the parameter space with observed data to inform the mixture-driven regression, while inference in unobserved regions is necessarily governed by the sensitivity parameter priors.
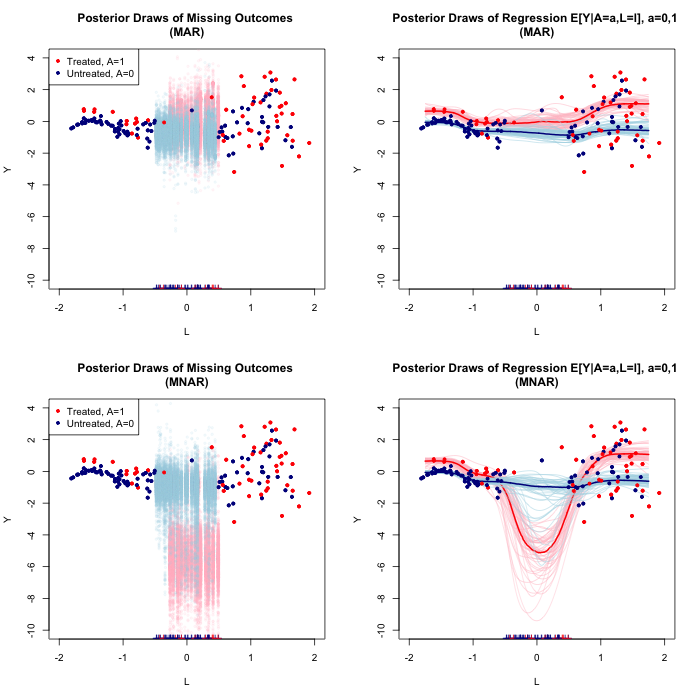
Figure 3: Posterior inference for MNAR outcomes using TSB mixtures, demonstrating shifts in pointwise posterior distributions of missing outcomes and treatment regression lines as MNAR sensitivity parameters are modified.
Practical and Theoretical Implications
The guide underscores several advantages and challenges for practical researchers:
- Bayesian sensitivity analysis, especially in Stan, gives direct control over encoding subject-matter assumptions and expert beliefs regarding assumption violations.
- Utilization of flexible nonparametric models, coupled with explicit sensitivity parameters, bridges the gap between robust model fitting and bias analysis.
- Implementation is feasible with public software, provided care is taken with the necessary marginalizations and custom log-likelihoods.
- Tipping point analyses illuminate the robustness or fragility of causal inferences, which is critical for transparent reporting and policy translation.
On the theoretical level, the framework demonstrates that Bayesian inference unifies parameter and missing data estimation and makes clear the precise location and magnitude of “ignorability gaps.” Sensitivity analysis becomes an explicit part of inference rather than an afterthought or post hoc critique.
Future Directions and Outlook
Opportunities for extension include developing more sophisticated priors over sensitivity parameters (beyond point mass), integrating external validation data, and expanding to longitudinal/complex treatment regimes (e.g., dynamic treatment regimes with time-varying confounding and measurement error). Furthermore, increased automation of the analytical marginalization steps and enhanced computational strategies for high-dimensional or non-discrete missing data can further broaden access.
Conclusion
This work synthesizes and operationalizes Bayesian sensitivity analysis for a range of causal inference problems, providing methodological clarity, detailed implementation advice, and vivid empirical illustrations. By mapping inference under assumption violation to Bayesian missing data modeling, and exploiting Stan’s programmability, robust causal effect estimation—accounting for both structural and statistical uncertainty—becomes tractable and transparent. The approach is poised for broader adoption in applied biomedical research, contingent upon expanded practitioner familiarity with both theoretical grounding and practical modeling skills.