- The paper introduces GraP, a gradient-based algorithm that dynamically adjusts composite loss weights to enhance downstream task efficacy.
- The method leverages embedding-space gradient comparisons and composite gradient normalization to streamline weight updates with moderate additional cost.
- GraP achieves competitive performance on vision and sequence tasks, reducing the need for extensive hyperparameter searches in multi-loss pretraining.
Gradient-Based Composite Loss Weighting for Efficient Pretraining
Selecting optimal weights in composite objectives during pretraining is critical for effective representation learning, particularly in multi-objective or multi-task regimes. Exhaustive strategies—such as grid, random, or Bayesian search—suffer from combinatorial expense as the number of loss components increases. Moreover, naive approaches (e.g., uniform weighting) fail to account for the diverse impact each loss term exerts on the shared representation, often yielding suboptimal downstream performance. "When Losses Align: Gradient-Based Composite Loss Weighting for Efficient Pretraining" (2605.07756) addresses these challenges by introducing a bilevel optimization perspective where the goal is to select loss weights that maximize downstream task efficacy.
Methodological Framework
The paper examines a general pretraining architecture comprising a shared encoder and multiple loss-function-specific heads, with an additional head for the downstream task. Each pretraining loss receives an adjustable, non-negative weight. The optimal weight vector w is defined by the downstream target metric, not by balancing among pretraining losses themselves.
A succinct overview of the methodology is provided in Figure 1:
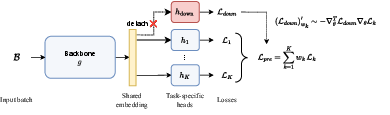
Figure 1: The GraP framework aligns the composite pretraining gradient with the downstream gradient in representation space, updating weights online.
The key technical innovation lies in the GraP (Gradient-aligned Pretraining) algorithm, which performs loss-weight updates via online stochastic gradient steps. The hypergradient (i.e., the gradient of the downstream loss with respect to the pretraining loss weights) simplifies, under a single SGD step, to the inner product between downstream and per-loss gradients. GraP leverages this structure to obtain efficient alignment signals—by comparing gradients in the shared representation (embedding) space, not in parameter space—thus circumventing the necessity for K complete backward passes at each iteration.
The authors also address scale ambiguity in the composite objective by proposing normalization on the norm of the composite gradient, not the weight vector itself. This normalization preserves the alignment direction between pretraining and downstream gradients more faithfully than common alternatives such as simplex or ℓ2-norm weight normalization.
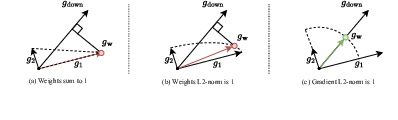
Figure 2: Comparison of normalization constraints; composite-gradient normalization preserves optimal alignment between composite and downstream gradients.
Empirical Evaluation
The efficacy of GraP is established through experiments on event-sequence modeling and self-supervised vision benchmarks. Datasets include Churn, AgePred, AlfaBattle, MIMIC-III, Taobao, CIFAR-10/100, and ImageNet-100. The results across sequence learning tasks consistently show that GraP matches or modestly surpasses equal-weights or strong multi-task optimizers such as GradNorm, DWA, MGDA, and PCGrad, while requiring a single training run with moderate (<50%) computational overhead—contrasting with 50× or greater cost for Bayesian optimization-based tuning.
Representative weight trajectories for several datasets highlight that GraP identifies and suppresses redundant loss terms in composite objectives, frequently reducing their weights to near-zero without degrading downstream performance.
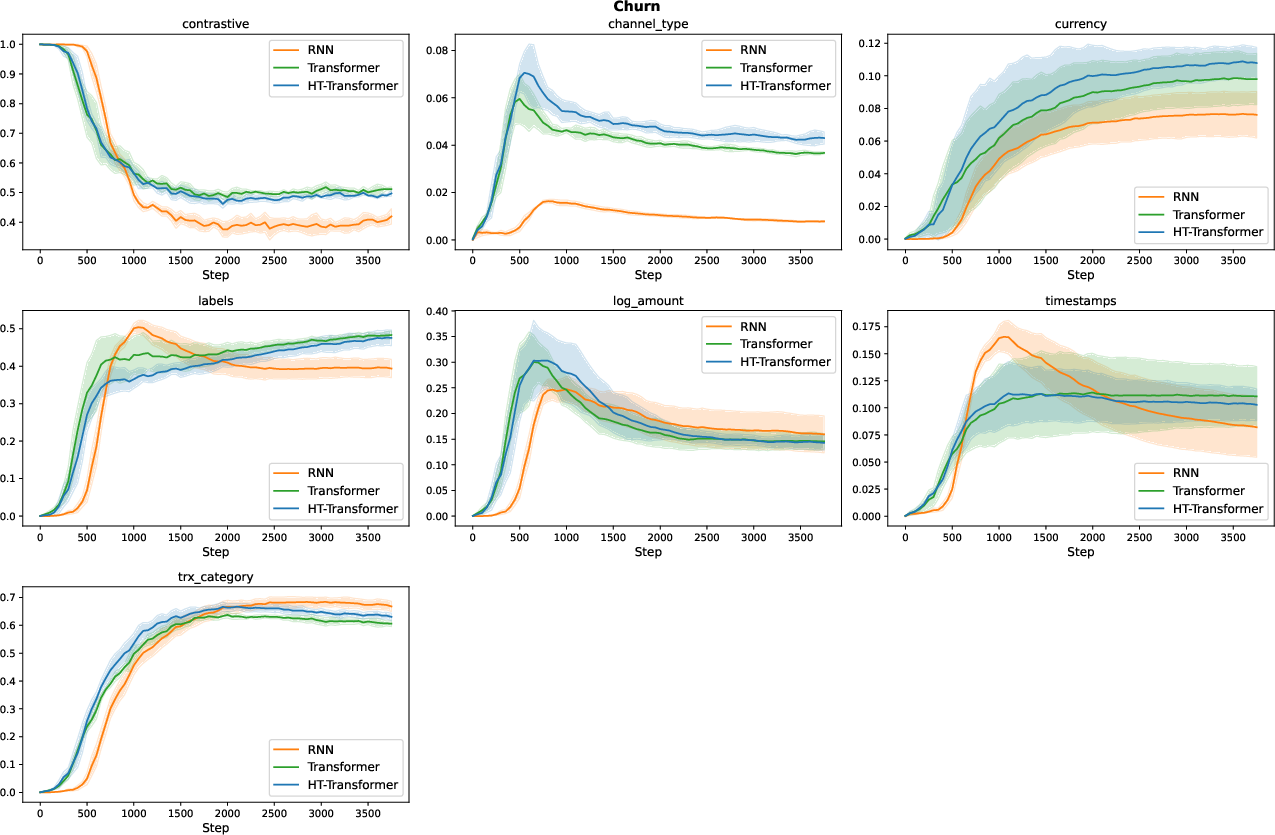
Figure 3: Training dynamics of pretraining loss weights on the Churn dataset.
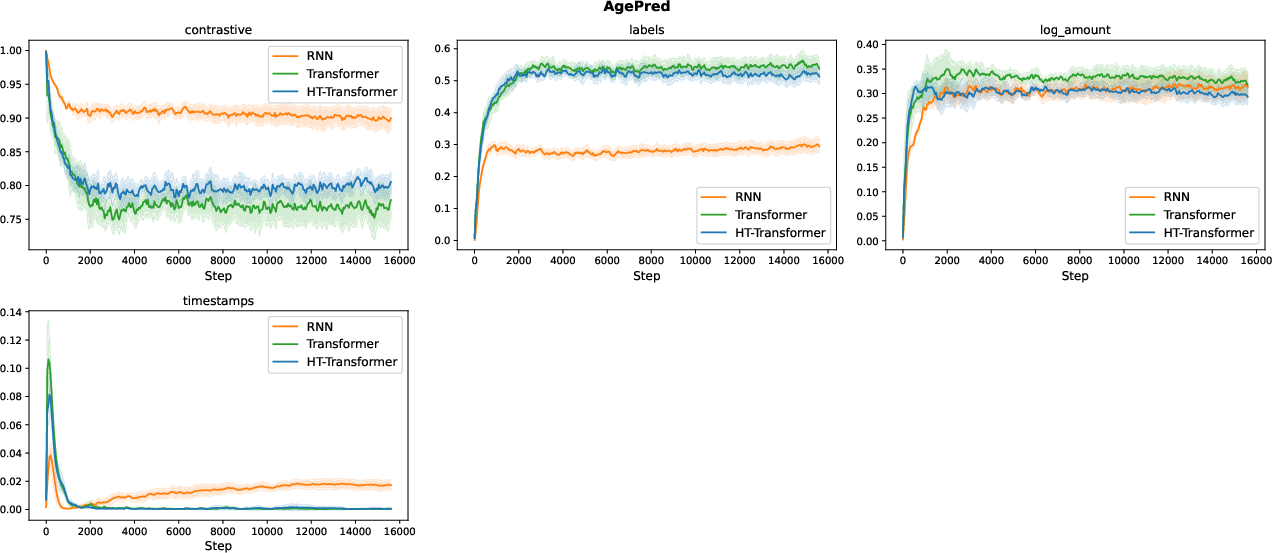
Figure 4: Weight update trajectories observed on the AgePred dataset, showing strong and consistent adjustment.
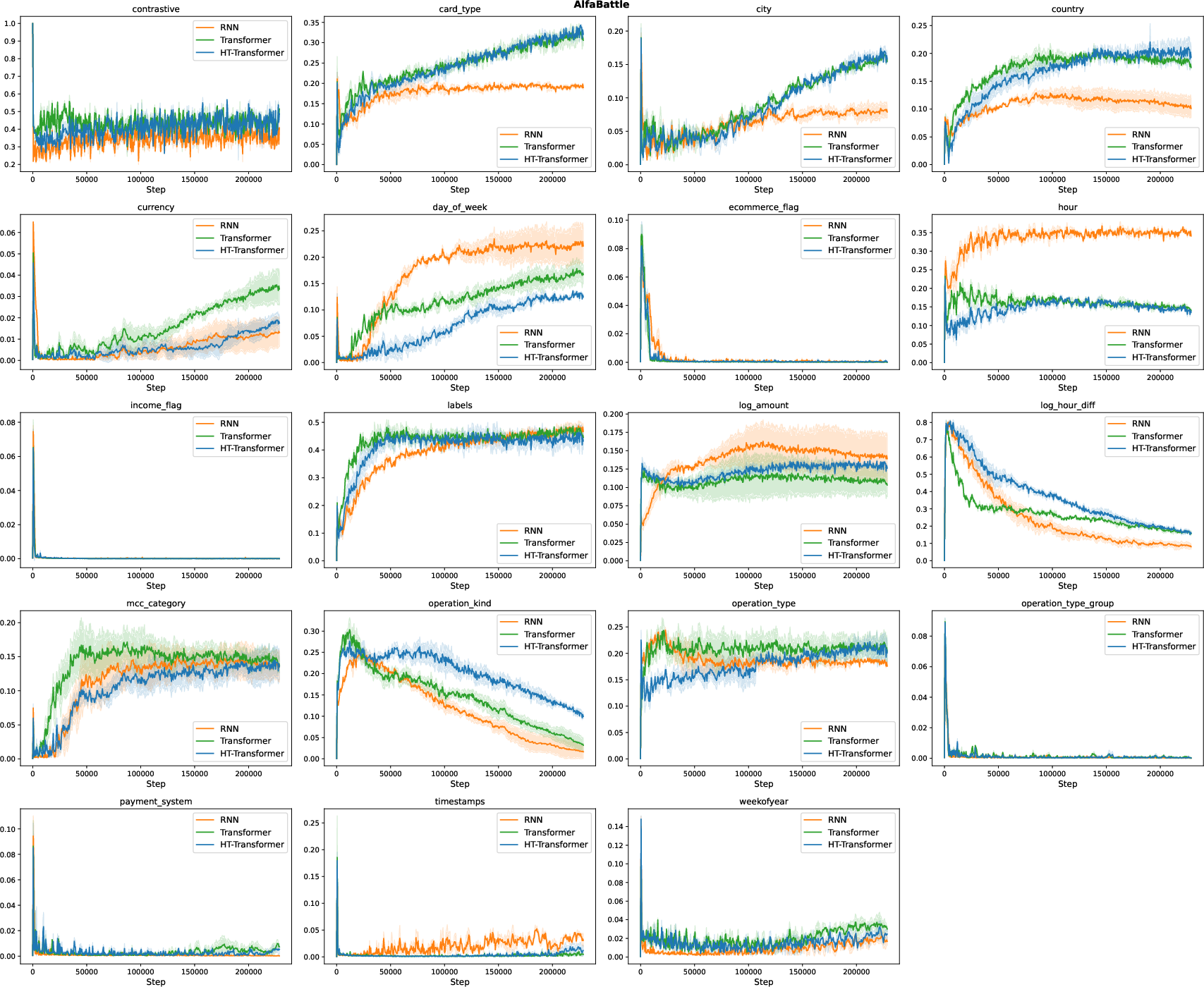
Figure 5: Loss weight evolution for AlfaBattle; unnecessary loss terms are rapidly down-weighted.
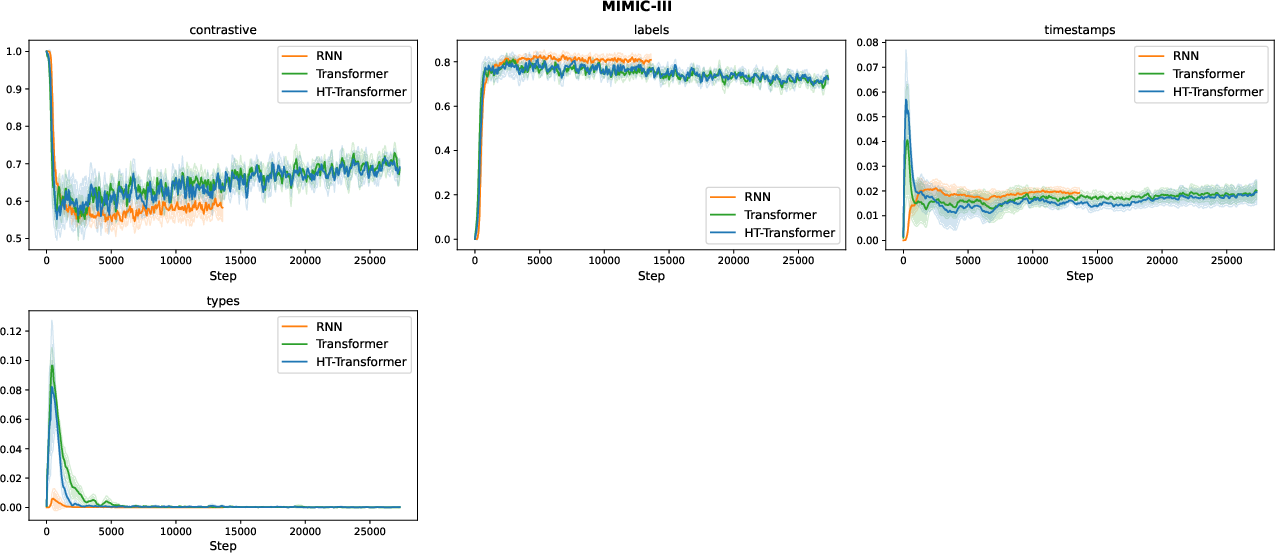
Figure 6: Weight adaptation curve for MIMIC-III, indicating smooth and interpretable tuning.
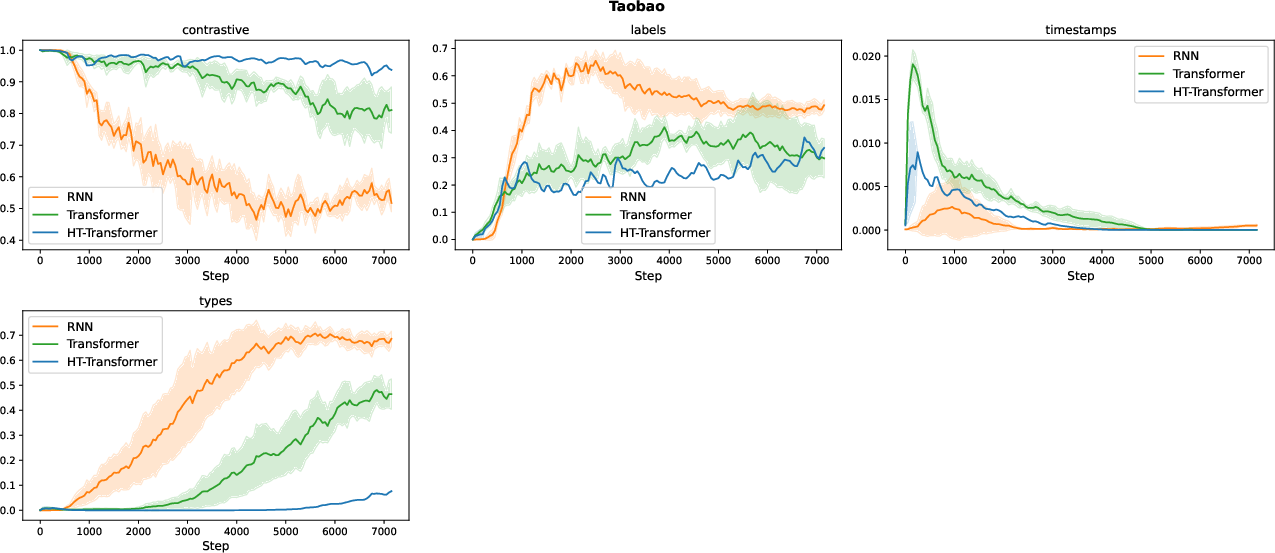
Figure 7: GraP weight trajectories for Taobao dataset; distinct losses receive divergent weights over training.
For computer vision tasks, particularly on All4One (a multi-loss self-supervised learning benchmark), GraP aligns closely with hand-tuned configurations and provides performance that is consistently within the variance of other advanced weighting approaches.
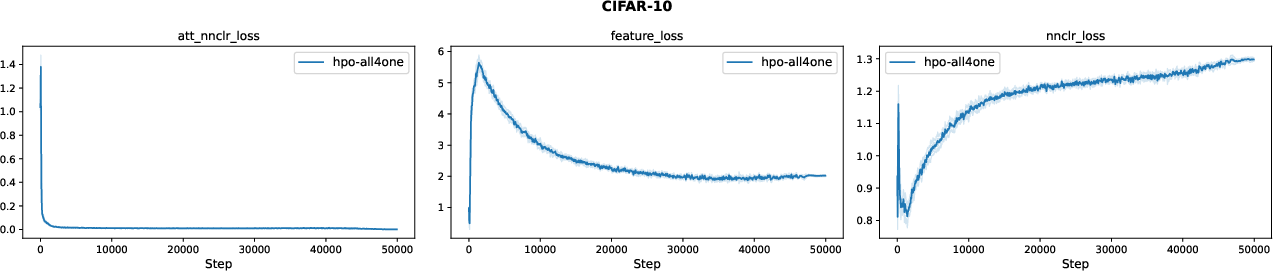
Figure 8: GraP loss weights evolution for CIFAR-10; the method reliably identifies impactful losses.
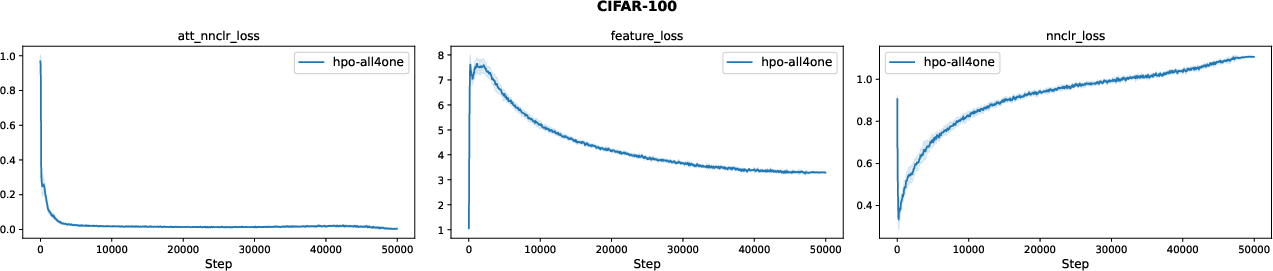
Figure 9: Adaptive loss weighting over time in CIFAR-100 training.
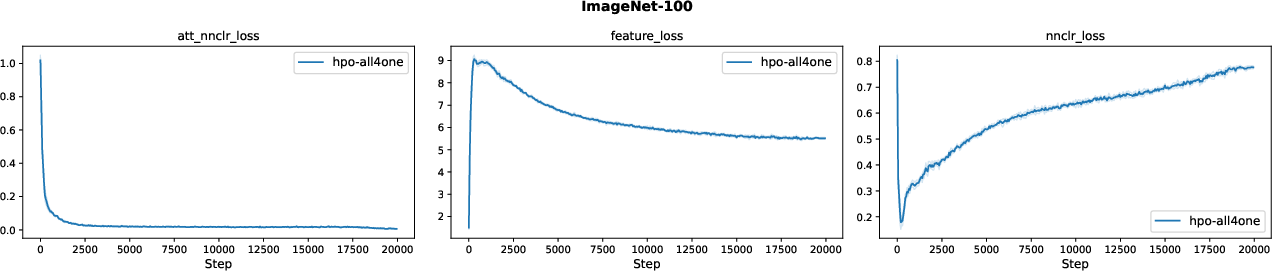
Figure 10: ImageNet-100 weight trajectories further indicate stability and elimination of negligible losses.
Computational and Practical Trade-Offs
Empirical results show that GraP incurs a manageable computational overhead (typically 30–50% relative to standard pretraining) due to additional head-specific backward operations, but is orders of magnitude more efficient than search-based HPO methods.
The approach requires slightly increased memory consumption due to caching per-loss gradients at the embedding level. Nonetheless, the overhead remains moderate compared to model size in modern vision tasks.
Theoretical Properties and Extensions
The work carefully addresses scale ambiguity and overparameterization in the loss weighting procedure, showing that only the direction (not norm) of the composite update matters for downstream transfer. The embedding-space gradient approximation is formally shown to provide an upper-bound surrogate of the true hypergradient under mild Jacobian regularity assumptions.
The bilevel optimization perspective suggests theoretical extensions to multi-step rollouts and potential improvements using exponential moving averages or implicit differentiation. However, preliminary experiments did not yield significant benefits from these modifications, due to the smooth and monotonic evolution observed in empirical weight trajectories.
Limitations and Future Directions
GraP requires each loss to correspond to a separate head. Scenarios where shared heads process multiple objectives may present interference effects not directly addressed. Additionally, highly correlated loss terms can result in the dominance of the most aligned objective, with little use of complementary information. Incorporating correlation- or uncertainty-aware strategies may mitigate this. The method's adjustment of composite gradient norm may interact with learning rate schedules, potentially requiring compensatory tuning for stability.
Implications and Prospects for AI
This gradient-aligned approach to composite loss weighting streamlines hyperparameter optimization for complex pretraining pipelines. Practically, it enables scalable development in settings with numerous heterogeneous losses (such as multi-formatted sequential data), democratizing robust pretraining without extensive compute resources for HPO. Theoretically, it ties pretraining more directly to downstream utility, suggesting a blueprint for future bilevel methods in representation learning and automated curriculum design.
A promising avenue is exploiting the method as a mechanistic loss selection process—transitioning from manual recipe engineering to data-driven, downstream-informed objective design. In large-scale self-supervised learning, especially as tasks proliferate (e.g., in multimodal or hierarchical pretraining), the necessity for automated, efficient, and robust loss weighting will only grow.
Conclusion
GraP is an efficient, gradient-based solution for online loss-weight adaptation in multi-loss pretraining settings. It matches or outperforms search-based and multi-tasking baselines with a fraction of the computational cost, while simultaneously providing interpretable diagnostics about the necessity and impact of individual pretraining objectives. As composite objectives proliferate in large-scale foundation model design, such bilevel, gradient-aligned weighting schemes are poised to become central tools for scalable and effective representation learning.