BioProVLA-Agent: An Affordable, Protocol-Driven, Vision-Enhanced VLA-Enabled Embodied Multi-Agent System with Closed-Loop-Capable Reasoning for Biological Laboratory Manipulation
Abstract: Biological laboratory automation can reduce repetitive manual work and improve reproducibility, but reliable embodied execution in wet-lab environments remains challenging. Protocols are often unstructured, labware is frequently transparent or reflective, and multi-step procedures require state-aware execution beyond one-shot instruction following. Existing robotic systems often rely on costly hardware, fixed workflows, dedicated instruments, or robotics-oriented interfaces. Here, we introduce BioProVLA-Agent, an affordable, protocol-driven, vision-enhanced embodied multi-agent system enabled by Vision-Language-Action (VLA) models for biological manipulation. The system uses protocols as the task interface and integrates protocol parsing, visual state verification, and embodied execution in a closed-loop workflow. A Tailored LLM Protocol Agent converts protocols into verifiable subtasks; a VLM-RAG Verification Agent assesses readiness and completion using observations, robot states, retrieved knowledge, and success/failure examples; and a VLA Embodied Agent executes verified subtasks through a lightweight policy. To improve robustness under wet-lab visual perturbations, we develop AugSmolVLA, an online augmentation strategy targeting transparent labware, reflections, illumination shifts, and overexposure. We evaluate the system on a hierarchical benchmark covering 15 atomic tasks, 6 composite workflows, and 3 bimanual tasks, including tube loading, sorting, waste disposal, cap twisting, and liquid pouring. Across normal and high-exposure settings, AugSmolVLA improves execution stability over ACT, X-VLA, and the original SmolVLA, especially for precise placement, transparent-object manipulation, composite workflows, and visually degraded scenes. These results suggest a practical route toward accessible, protocol-centered, and verification-capable embodied AI for biological manipulation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper presents a low-cost robot “team” that can follow biology lab instructions written in everyday language, watch what it’s doing with cameras, check its own work, and then try again or ask for help if something looks wrong. The goal is to make lab work more reliable and accessible, especially for places that can’t afford expensive robots.
What questions the researchers wanted to answer
- Can a robot read natural-language lab protocols (the step-by-step instructions scientists write) and turn them into doable, checkable steps without a human translating them into robot code?
- Can the robot tell if a step is safe to start and whether it finished correctly by looking at the scene and using common lab knowledge?
- Can a small, low-cost robot handle tricky lab objects—like transparent tubes and shiny surfaces—that are hard for cameras to see?
- Can we make the robot more stable in real labs with bad lighting or glare by “training its eyes” to handle these problems?
How the system works (everyday explanation)
Think of the robot as a tiny team with different roles that work together in a loop: read, check, do, then double-check.
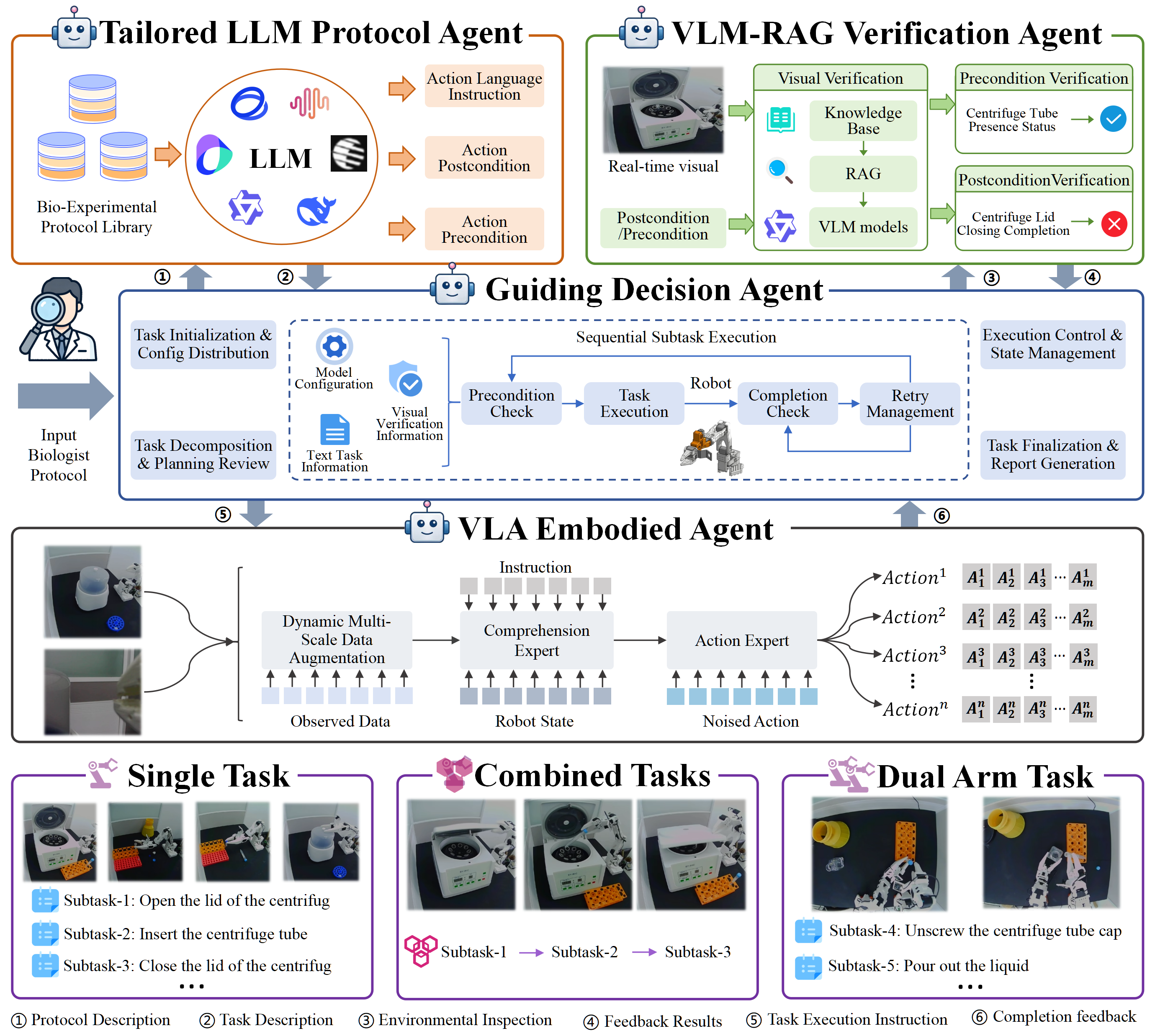
- The Manager: Keeps track of progress, decides what to do next, and when to retry or call a human.
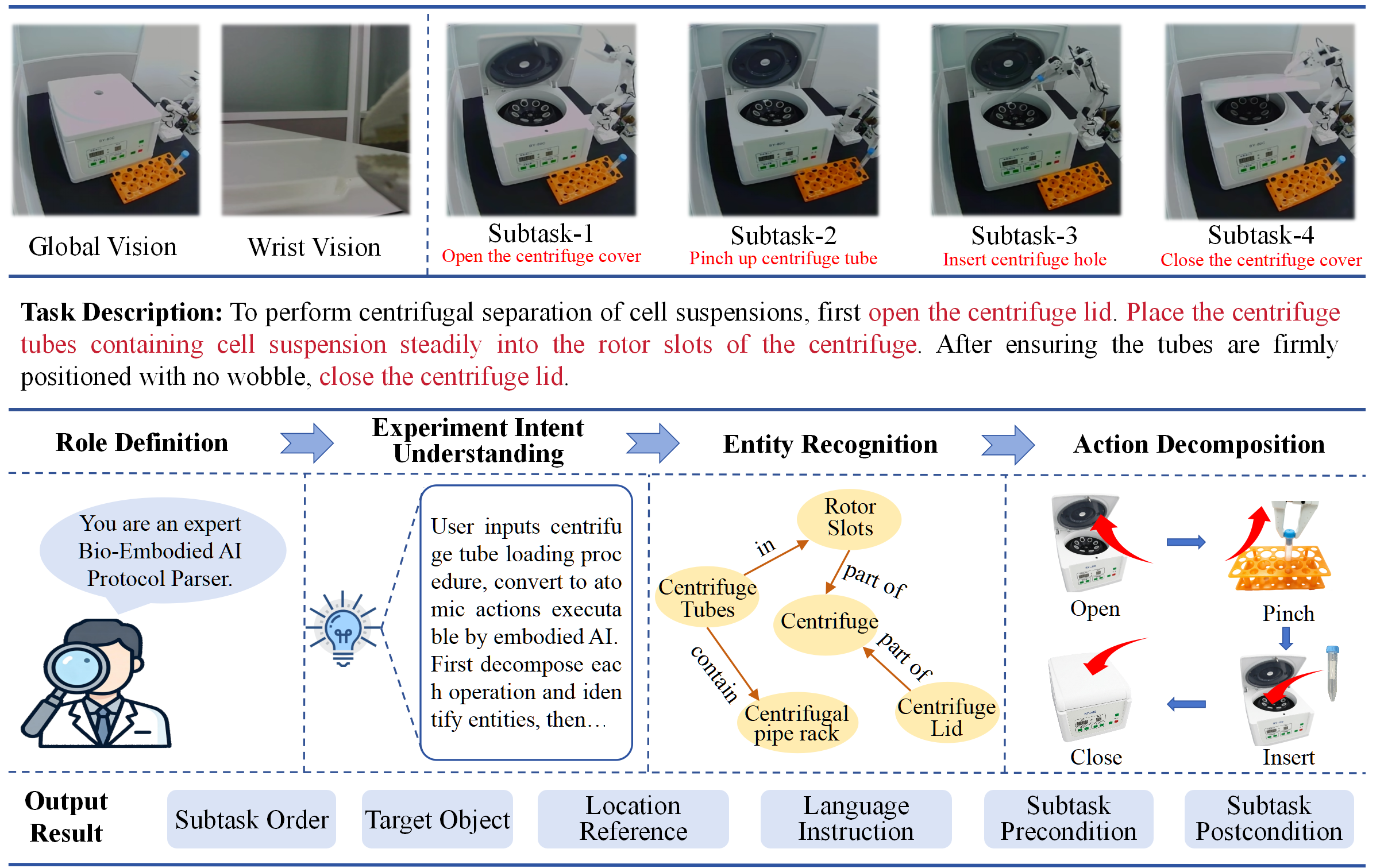
- The Reader (LLM Protocol Agent): Reads the lab protocol written in normal language and breaks it into small, clear steps. For each step, it notes:
- What to do
- What must be true before starting (preconditions)
- How to tell if it worked (completion checks)
- Helpful pointers to lab know-how
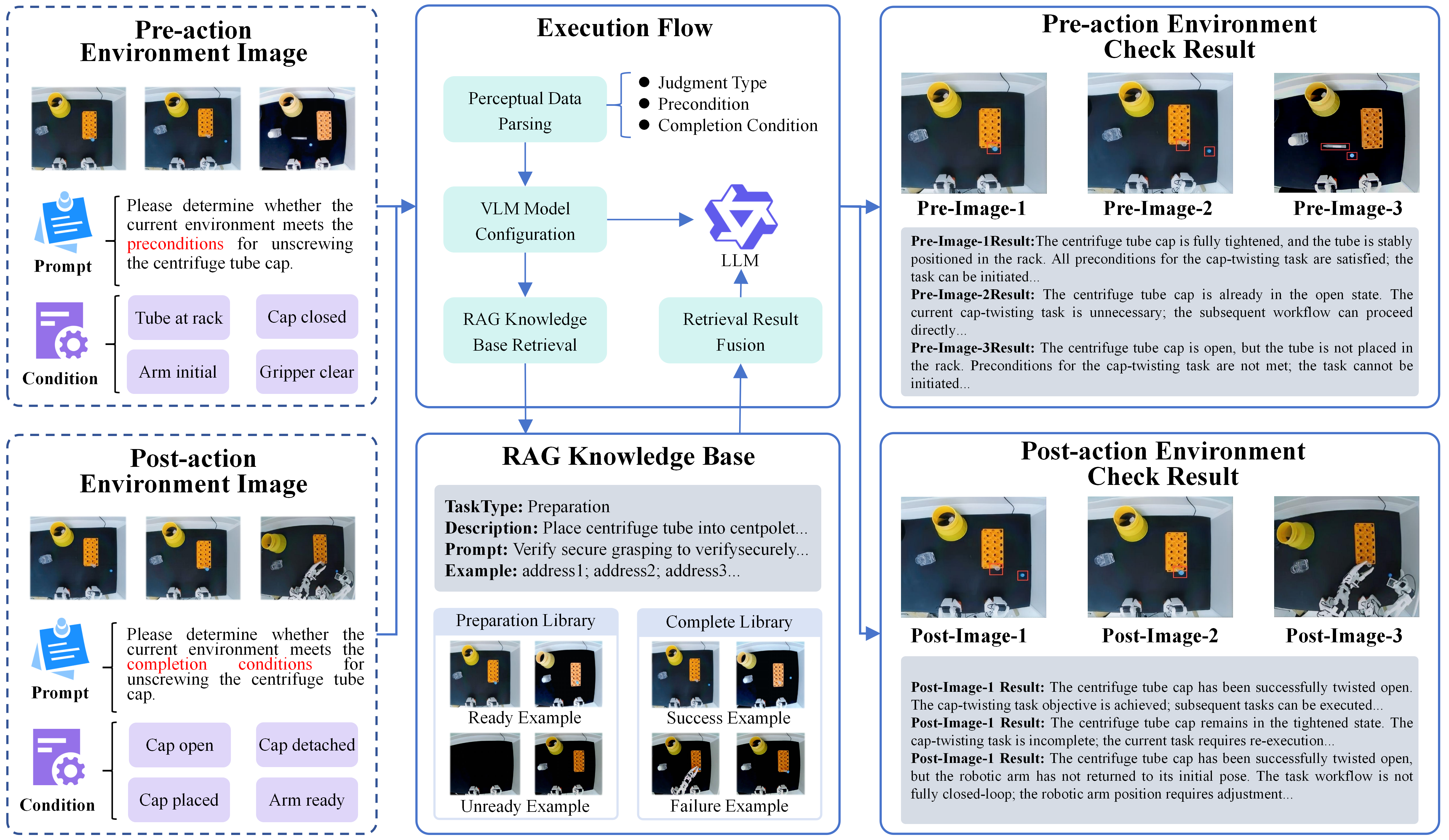
- The Checker (VLM‑RAG Verification Agent): Looks at camera images and robot status, and compares them with examples and lab knowledge. It answers:
- “Is it safe/ready to start this step?”
- “Did the step finish correctly?”
- If not, it explains what went wrong (for example, “The tube cap is still on”).
- The Doer (VLA Embodied Agent): Translates the step into actual arm movements, guided by images and the instruction. It uses a compact “vision‑language‑action” policy that maps “what it sees” and “what it’s told” into “what it should do.”
Closed loop means the robot doesn’t just follow a list blindly. It checks before acting and after acting. If a step isn’t ready (say, a tube isn’t in the right place), it can reorder steps, retry, or ask a human for help.
Handling hard-to-see lab stuff
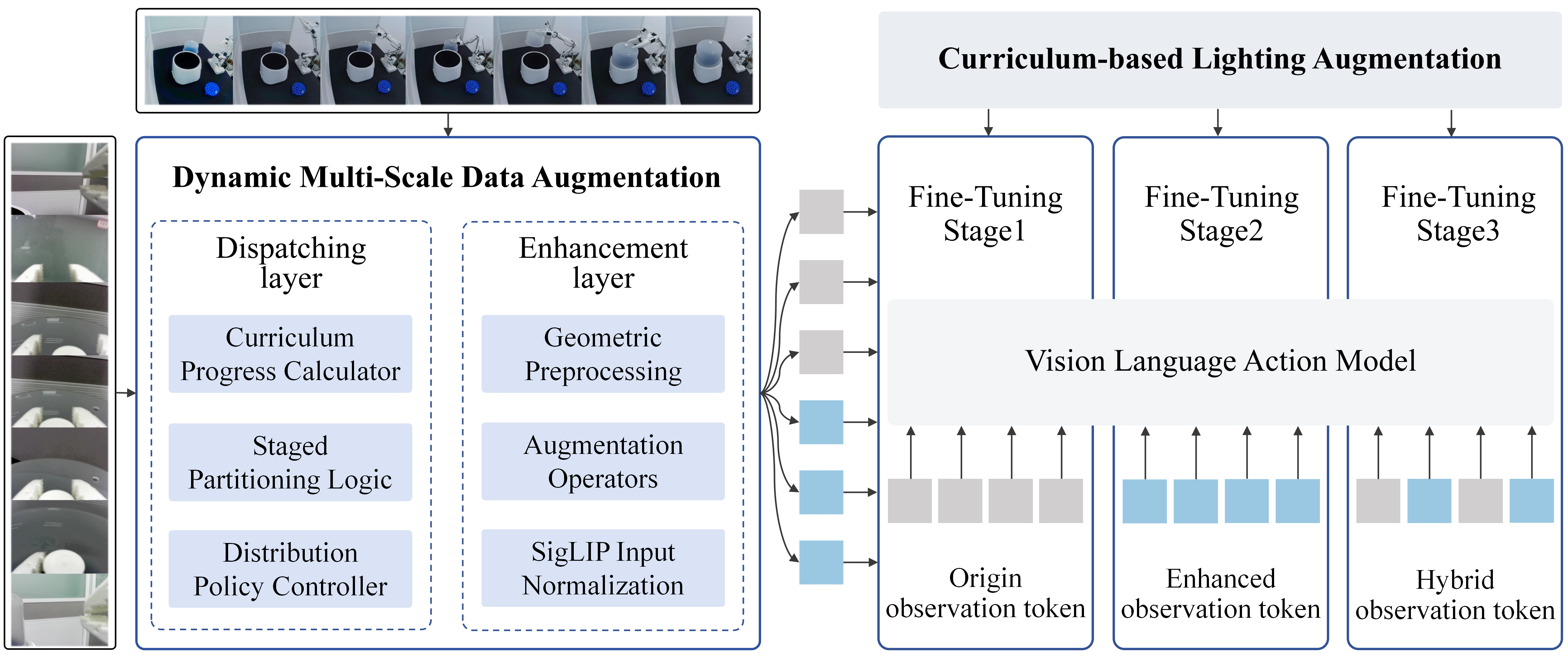
A big problem in real labs is that many items are transparent or shiny—like centrifuge tubes and bottle caps. Bright lights, reflections, and overexposure can confuse cameras. The team adds a training trick called AugSmolVLA:
- Imagine practicing a sport in all kinds of “bad weather”—too bright, too dark, lots of glare—so you won’t be thrown off later. AugSmolVLA does that for the robot’s vision by randomly changing brightness, contrast, and glare during training.
- It uses a “learn easy things first, then harder ones” schedule. First the robot learns with normal images, then with tougher lighting, then with a mix. This helps it stay steady in messy, real-world conditions without needing to build a huge extra dataset.
What they tested and what they found
What they tested:
- A set of lab tasks that feel like real work: placing tubes into racks, opening/closing lids, throwing used tubes away, sorting, unscrewing and tightening caps with two arms, and pouring liquid into a bottle. They built a benchmark with:
- 15 basic “atomic” tasks
- 6 multi-step workflows
- 3 bimanual tasks (using both arms)
- They ran the robot under normal lighting and “harsh” lighting (overexposed, reflections, etc.).
Main results:
- The system is affordable: they built it on a low-cost platform (about 800–850 USD in hardware), which lowers the barrier for small labs.
- The closed-loop design (read–check–do–check again) made execution more reliable for long, multi-step procedures by catching problems early instead of letting small mistakes snowball.
- Their vision training (AugSmolVLA) made the robot more stable than several known methods (ACT, X‑VLA, and the base SmolVLA), especially when:
- Precisely placing tubes
- Handling transparent objects
- Running multi-step workflows
- Working in bright or visually messy scenes
- Overall, the robot did a better job of starting steps only when ready, finishing steps correctly, and staying steady even with bad lighting.
Why this matters:
- Better stability means fewer ruined experiments and less repeat work.
- Being able to read protocols directly means biologists don’t need to write robot code.
- Cheaper hardware plus smarter software can bring automation to many more labs.
Why this work is important
- Accessibility: Many labs can’t afford fancy robot setups. A system that works on affordable hardware helps spread automation more widely.
- Reliability and safety: By checking conditions before acting and verifying outcomes, the robot reduces errors and can pause or ask for help when needed. That makes lab work more consistent and safer.
- Flexibility: Because it uses normal language protocols and can adapt step order, it’s easier to apply to different experiments without rewriting scripts.
- Future potential: This approach—protocol-driven, vision-checked, and action-capable—could become a general assistant for labs, helping scientists focus on thinking and design while the robot handles repetitive or delicate tasks. With more training data and broader task libraries, it could expand to more complex experiments.
In short, the paper shows a practical path to smarter, more trustworthy, and more affordable lab robots: a robot “team” that reads instructions, checks its surroundings, acts carefully, and learns to see well even when the lighting isn’t perfect.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes BioProVLA-Agent and AugSmolVLA for affordable, protocol-centered wet-lab manipulation, but several aspects remain unaddressed or insufficiently evaluated. The following list highlights concrete gaps and open questions to guide future research:
- Dataset scope and diversity
- Single-lab setup with a fixed robot (So-ARM101), camera placement, and a limited set of objects; unclear generalization to new labs, camera poses, backgrounds, benches, and labware categories (e.g., microplates, pipette tips, Petri dishes, microcentrifuge tubes).
- Only 100 demonstrations per atomic task and 3 bimanual tasks; the dataset size and task variety may be insufficient for robust long-horizon generalization and dual-arm dexterity.
- No explicit train/test splits for compositional generalization (e.g., unseen combinations of objects and subtasks or new protocols from the same primitives).
- Release status of datasets, models, and prompts is not specified; reproducibility and community benchmarking are unclear.
- Evaluation design and statistical rigor
- Single-task success rates use three repeats; composite workflows use 20 trials; no confidence intervals beyond standard error and no statistical significance tests across baselines.
- Metrics (SR, CR) omit timing, retries, recovery actions, and safety events; lack of metrics for error accumulation, time-to-completion, and robustness under perturbations.
- Limited failure analysis: no systematic error taxonomy or root-cause attribution across perception, planning/verification, and control components.
- Verification (VLM-RAG) module transparency and reliability
- Insufficient detail on the knowledge base: curation process, provenance, size, coverage, versioning, and update policy; unclear how success/failure exemplars are collected and scaled.
- Retrieval method and hyperparameters (embeddings, similarity metric, k, reranking) and their effect on verification accuracy are not ablated.
- No quantitative evaluation of verification accuracy (precision/recall, F1, calibration) for preconditions and completion checks; false positive/negative rates and their impact on execution are unreported.
- Reliance on single-view RGB observations in verification; no experiments on multi-view setups or active perception to reduce occlusion-induced verification errors.
- Closed-loop scheduling and protocol semantics
- Reordering logic when preconditions fail is heuristic; no formal mechanism (e.g., constraint satisfaction or temporal logic) to ensure that retries/reordering preserve scientific validity, biosafety, and step dependencies.
- No modeling of conditionals, loops, timers, or parallelism in protocols; unclear handling of time-sensitive steps (e.g., incubation) and temporal constraints in long-horizon workflows.
- Protocol parsing (Tailored LLM Agent) robustness
- No quantitative benchmark on protocol parsing accuracy (e.g., against BioProt or similar datasets), nor assessment of sensitivity to protocol style, ambiguity, or domain-specific jargon.
- Mapping to a “closed” atomic action set may limit expressiveness; unclear handling of nuanced operations (e.g., “mix gently,” “avoid bubble formation,” “vortex 5 s,” “keep on ice”).
- Lack of safeguards against LLM hallucinations in parsed preconditions and completion criteria; no verification of semantic consistency across steps.
- Embodied control and sensing limitations
- SmolVLA-based control relies on RGB and robot state only; no tactile/force/torque sensing, which is critical for cap twisting, tight fits, and robust grasping under uncertainty.
- Dual-arm coordination is limited to three tasks; collision avoidance, role assignment, and synchronization across more complex bimanual tasks are unexplored.
- No assessment of trajectory smoothness, contact forces, or compliance control—key for fragile labware and safe human-robot interaction.
- Visual robustness beyond illumination
- AugSmolVLA augmentation targets brightness/contrast/overexposure but not other wet-lab perturbations: specular glare dynamics, refraction through curved liquids, lens smudges/condensation, motion blur, occlusions by hands/tools, camera pose drift, background clutter, and partial transparency at object boundaries.
- No experiments with alternative sensing modalities (e.g., depth with active IR, NIR, polarization, multi-view) that are known to mitigate transparent-object challenges.
- No ablation on augmentation schedules/intensities or comparisons with stronger generative/data-centric augmentations tailored to transparency and liquids.
- Liquids and fine-grained outcomes
- Liquid manipulation is limited to pouring; there is no measurement of poured volume, spill detection, wetness detection, or closed-loop adjustments based on fluid flow feedback.
- Tasks like pipetting, aspirate/dispense with volume control, and contamination-aware liquid handling remain unaddressed.
- Safety, biosafety, and compliance
- No treatment of sterile technique, contamination control, or biosafety levels (e.g., BSL-2) and their operational constraints (tool sterilization, sterile workspace maintenance).
- Safety interlocks for equipment (e.g., centrifuge lock states), fail-safe mechanisms, and recovery protocols (e.g., spills, dropped tubes) are not formalized or evaluated.
- Human-in-the-loop triggers are described qualitatively; thresholds, escalation policies, and operator workload impact are not measured.
- Real-time performance and resource constraints
- No profiling of latency and jitter across agents (LLM/VLM/VLA) vs. control loop requirements; unclear feasibility on low-cost hardware without cloud dependence.
- Energy and compute constraints on the ~$800–850 platform are not quantified; the trade-off between model size, throughput, and performance is unexplored.
- Generalization and transfer
- Cross-embodiment generalization (to other robot arms, grippers, end-effectors) is untested; policies and prompts may overfit the So-ARM101 and specific gripper geometry.
- Transfer to new labware classes, unseen object geometries, and different manufacturers’ equipment (tolerances, affordances) is not evaluated.
- Calibration and deployment burden
- Camera and robot extrinsic calibration procedures, drift handling, and re-localization strategies are unspecified; robustness to setup changes is unknown.
- No assessment of setup time, maintenance overhead, and durability in humid, corrosive, or spill-prone environments typical of wet labs.
- Human factors and usability
- No user studies assessing whether domain scientists can reliably provide protocols, interpret system feedback, and intervene effectively without robotics expertise.
- Explainability and auditability of agent decisions (especially verification and reordering) are not validated with end-users.
- Integration with lab information systems (LIMS) and provenance
- Lack of integration with LIMS, sample tracking, barcode/RFID systems, and metadata capture for experiment provenance and reproducibility audits.
- Ethical, security, and privacy considerations
- Cloud reliance (if any) for LLM/VLM is not discussed; data privacy and security for lab images/protocols are unaddressed.
- No discussion on safe operation boundaries to prevent misuse or unintended automation in sensitive biological contexts.
These gaps suggest concrete next steps: build a broader multi-lab benchmark with richer tasks (including liquid metrology and sterile operations), quantify verification accuracy and latency, introduce tactile/multimodal sensing, formalize protocol constraints in the scheduler, expand augmentation to non-illumination perturbations, perform user studies, integrate with LIMS and safety protocols, and evaluate cross-embodiment and cross-site generalization with transparent release of data, code, and prompts.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities of BioProVLA-Agent and AugSmolVLA, given modest setup and task-specific adaptation.
- Low-cost robotic assistant for routine wet-lab manipulations
- Sectors: healthcare (clinical labs), biotechnology, academic research labs, community/citizen labs
- What: Automate repetitive tasks demonstrated in the paper—opening/closing lids, loading/removing tubes, rack placement/sorting, discarding consumables, cap twisting, and pouring—on a ~USD 800–850 hardware platform.
- Tools/products/workflows: Deploy the multi-agent stack (Guiding Decision Agent + Tailored LLM Protocol Agent + VLM-RAG Verification Agent + VLA Embodied Agent); add a top-down/view camera; define SOPs as natural-language protocols; run closed-loop execution with pre/post verification.
- Assumptions/dependencies: Availability of a compatible low-cost arm (e.g., So-ARM101-class), safe operating area and fixtures for task objects, task demonstrations or fine-tuning data for local variants, and a knowledge base seeded with success/failure examples for the target labware.
- Protocol-to-Action SDK for SOP standardization and training
- Sectors: academia, industry QA/QC labs, education
- What: Use the Tailored LLM Protocol Agent to convert unstructured protocols into structured, stepwise representations with preconditions and completion criteria; use this as a machine-readable SOP for training, auditing, or semi-automated execution (even without a robot).
- Tools/products/workflows: A “Protocol Parser” microservice that exports JSON task graphs; integrates with LIMS for step gating and sign-off; auto-generates checklists and training materials.
- Assumptions/dependencies: Quality of protocol text and domain prompts; validation by domain experts to avoid misinterpretation of implicit constraints; organizational acceptance of natural-language interfaces.
- Vision-based pre/postcondition verifier as a QA overlay
- Sectors: healthcare (CLIA/ISO labs), pharma QC, academic labs
- What: Deploy the VLM-RAG Verification Agent and cameras to gate human or robotic actions—confirm readiness (e.g., correct tube type positioned) and verify completion (e.g., tube inserted in the correct rack slot) before allowing progression.
- Tools/products/workflows: “Lab-Guard” plugin that sits alongside existing manual workflows; integrates retrieval of success/failure exemplars for interpretability; logs outcomes for audit trails.
- Assumptions/dependencies: Camera placement and calibration; curated knowledge base relevant to local labware; defined false-positive/false-negative tolerances; privacy/compliance for image data.
- AugSmolVLA augmentation plugin for robust manipulation with transparent/reflective labware
- Sectors: robotics, biotech, pharma, food & beverage packaging
- What: Improve VLA policy robustness under illumination shifts, specular reflections, and overexposure using the curriculum-based online augmentation described in AugSmolVLA.
- Tools/products/workflows: A training-time augmentation library that can be applied to SmolVLA or similar VLA policies; packaged recipes for “transparent object” scenarios.
- Assumptions/dependencies: Access to demonstration data for tasks; compute for fine-tuning; representative lighting/camera conditions during training.
- Human-in-the-loop closed-loop automation with exception handling
- Sectors: industry labs, academic labs
- What: Use the Guiding Decision Agent to orchestrate execution, retries, task reordering, and human intervention triggers based on verification outputs; reduce error propagation in long-horizon tasks.
- Tools/products/workflows: Workflow engine with dashboards that pause, request re-verification, or solicit operator input when checks fail; semi-autonomous “co-pilot” mode for lab technicians.
- Assumptions/dependencies: Defined escalation policies; operator availability; clear safety limits for robot motion in shared spaces.
- Adoption of the hierarchical wet-lab benchmark for research and model evaluation
- Sectors: academia, robotics R&D
- What: Use the 15 atomic tasks, 6 composite workflows, and bimanual tasks (cap twisting, pouring) to evaluate policy generalization and verification strategies in realistic wet-lab settings.
- Tools/products/workflows: Benchmark suites and evaluation metrics (SR/CR) with LeRobot-formatted datasets and teleoperation tooling.
- Assumptions/dependencies: Access to similar lab assets (centrifuge, water bath, tubes, racks) and a compatible dual-arm setup if testing bimanual tasks.
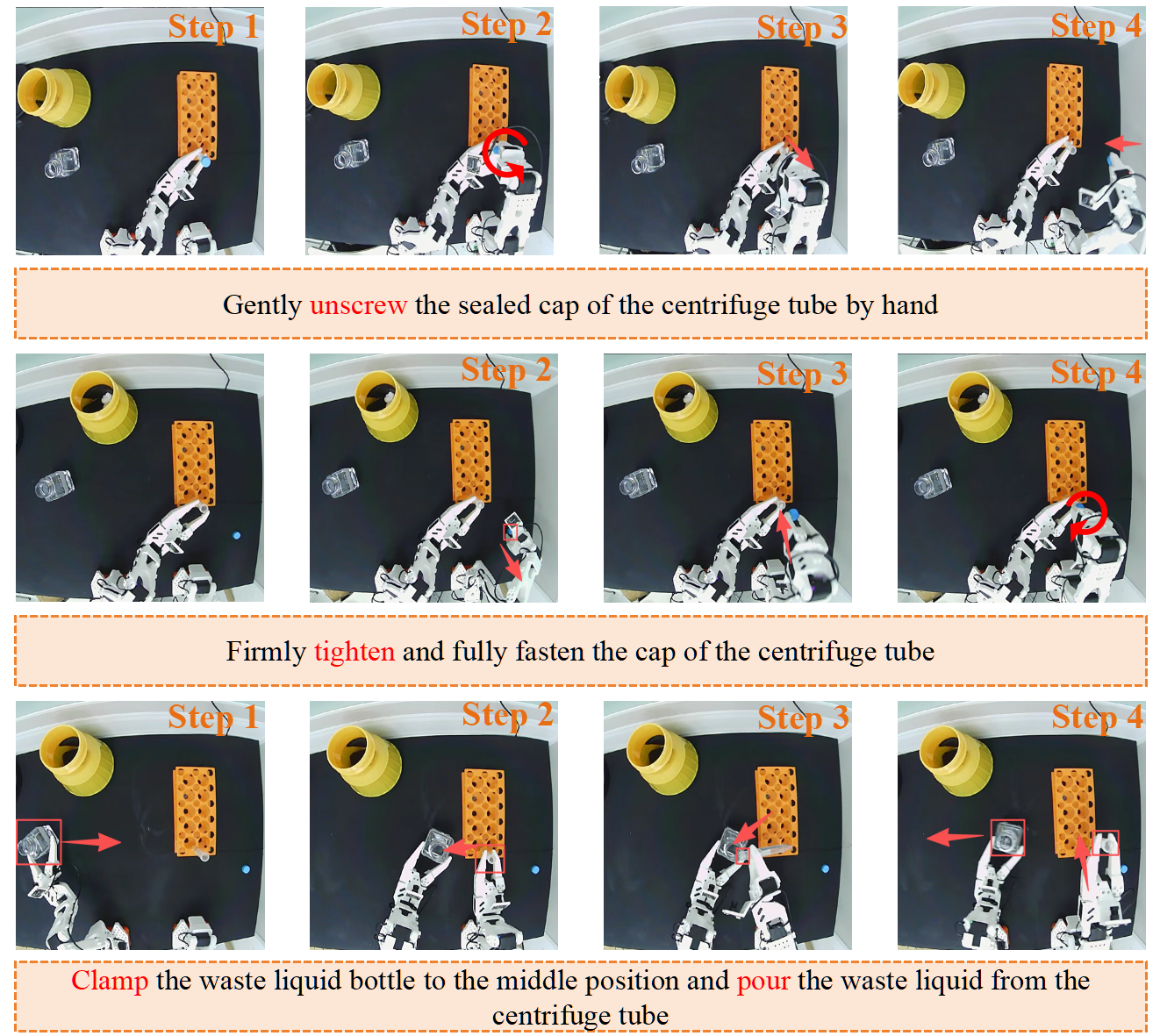
- Bimanual manipulation for cap management and waste pouring
- Sectors: clinical sample prep, biotech R&D
- What: Automate unscrewing/tightening centrifuge tube caps and pouring waste liquid into a designated bottle with verification-driven gating; reduce ergonomic strain and improve consistency.
- Tools/products/workflows: Dual-arm policy deployment from the VLA Embodied Agent; integrated QA checks on cap state and liquid transfer targets.
- Assumptions/dependencies: Reliable grippers/fixtures; safeguards against spills; validated success criteria in the knowledge base.
- Teaching modules for robotics and bio-lab courses
- Sectors: education (STEM, vocational training)
- What: Introduce students to protocol parsing, multimodal verification, and VLA control on low-cost hardware; blend robotics and lab safety curricula.
- Tools/products/workflows: Course kits with prebuilt tasks, code notebooks, and evaluation scripts; simulation-to-real demos using the benchmark tasks.
- Assumptions/dependencies: Faculty preparedness; safe demo environments; budget for low-cost arms and cameras.
- Retrofit kit for incumbent low-cost arms
- Sectors: robotics integrators, makerspaces, teaching labs
- What: Port the BioProVLA-Agent software stack and AugSmolVLA training recipes to commodity arms (where feasible), enabling wider deployment without proprietary ecosystems.
- Tools/products/workflows: “Protocol-to-Action” SDK with drivers for popular arms; camera mounting and calibration guides; starter knowledge-base content.
- Assumptions/dependencies: Kinematics/drivers for target arms; re-collection of demonstrations for hardware with different reach/grasp capabilities; safety reviews.
Long-Term Applications
These opportunities require additional research, scaling, validation, or integration beyond the paper’s current scope.
- General-purpose autonomous lab technician for end-to-end protocols
- Sectors: biofoundries, pharma R&D, academic core facilities
- What: Execute diverse biological protocols from natural language with robust pre/post verification, dynamic reordering, and continuous logging; handle long-horizon workflows reliably.
- Tools/products/workflows: Expanded protocol libraries; broader atomic action sets (pipetting, microplate handling); richer knowledge bases; multi-sensor fusion (vision + force/torque).
- Assumptions/dependencies: Extensive demonstrations across many protocols; advanced grippers and sterile handling; biosafety certification; integration with LIMS and facility scheduling.
- Sterile liquid-handling and precision operations (pipetting, aspirate/dispense)
- Sectors: synthetic biology, clinical diagnostics, pharma manufacturing
- What: Extend VLA capabilities and verification to microliter-scale liquid handling in sterile/clean environments, integrating with open-source liquid handlers or custom end-effectors.
- Tools/products/workflows: Pipetting end-effectors, sterile enclosures, force/vision fusion for meniscus detection; verified pre/post conditions for contamination control.
- Assumptions/dependencies: Hardware upgrades; sterile protocol constraints; regulatory validation for accuracy and contamination.
- Regulatory-grade compliance and audit trails (GLP, CLIA, ISO)
- Sectors: clinical labs, regulated pharma
- What: Leverage VLM-RAG’s interpretable checks to produce granular, timestamped logs and visual evidence for each step; enable automated audit readiness and deviation reports.
- Tools/products/workflows: Immutable logs, video annotations, knowledge-base versioning, and signer workflows integrated with QMS.
- Assumptions/dependencies: Validation against regulatory standards; privacy and data governance; robust failure classification accuracy.
- Multi-robot, multi-station coordination in self-driving labs
- Sectors: biofoundries, materials/chemistry autonomous labs
- What: Extend the Guiding Decision Agent to coordinate fleets of robots across stations (centrifuges, incubators, liquid handlers) with shared verification services.
- Tools/products/workflows: Task schedulers, queuing, resource allocation, and inter-robot communication; unified knowledge bases and global state representations.
- Assumptions/dependencies: Reliable station interfaces; standardized machine-readable protocols; facility-level safety interlocks.
- Chain-of-custody and EHR/LIMS integration for clinical sample processing
- Sectors: healthcare, diagnostics
- What: Automate accessioning, labeling checks, tube sorting, and pre-analytical steps with closed-loop verification; maintain chain-of-custody and metadata synchronization.
- Tools/products/workflows: API connectors to LIMS/EHR; barcode/RFID reading; verification prompts tied to patient/sample metadata.
- Assumptions/dependencies: Compliance with HIPAA/GDPR; device cybersecurity; hospital IT integration.
- Standardization and open formats for machine-readable protocols
- Sectors: academia, standards bodies, industry consortia
- What: Contribute to or extend formats (e.g., LAP/ProtoCode-like) to capture preconditions, completion criteria, and verification hooks natively for robotic execution.
- Tools/products/workflows: Authoring tools with validation; shared repositories of protocols with embedded verification examples; community benchmarks.
- Assumptions/dependencies: Consensus across stakeholders; clear ontologies for labware/actions; maintenance of public knowledge bases.
- Cross-domain transfer: chemical labs, microfluidics, and manufacturing
- Sectors: chemistry, microfabrication, pharma fill–finish, food & beverage QA
- What: Adapt AugSmolVLA and verification loops to transparent containers, reflective metals, and liquid interfaces common in these domains; verify sequence-critical operations.
- Tools/products/workflows: Domain-specific knowledge bases and success/failure exemplars; tailored action spaces and fixtures.
- Assumptions/dependencies: Task-specific demonstrations; process safety considerations; new sensors for non-biological cues (e.g., thermal, weight).
- Assistive robotics in homes and eldercare
- Sectors: consumer robotics, healthcare support
- What: Translate closed-loop verification and transparent-object robustness to daily tasks (e.g., handling glasses, bottles, pill organizers) with pre/post checks for safety.
- Tools/products/workflows: Consumer-grade robot kits; simplified protocol authoring (“recipes”); safety-focused verification prompts.
- Assumptions/dependencies: Domestic variability (lighting, clutter); human-robot safety and liability; robust generalization beyond lab-like setups.
- Remote, shared self-driving labs for education and citizen science
- Sectors: education, open science
- What: Operate low-cost robots as remotely accessible lab stations; students author protocols in natural language, observe closed-loop execution with verification-based feedback.
- Tools/products/workflows: Cloud-hosted protocol parsing and verification; booking systems; streaming and logging for assessment.
- Assumptions/dependencies: Network reliability; sandboxed safety controls; scalable maintenance of low-cost hardware.
- Data and model marketplaces for wet-lab manipulation
- Sectors: software/tooling, robotics vendors
- What: Curate and share demonstration datasets, verification prompts, and trained policies for common lab tasks; offer fine-tuning services.
- Tools/products/workflows: “WetLabBench” benchmark hub; “Protocol-to-Action” models; plug-and-play verification packs per labware set.
- Assumptions/dependencies: IP/data-sharing agreements; quality assurance for contributed datasets; reproducibility across hardware variants.
Each application’s feasibility depends on task coverage, data availability for fine-tuning, hardware capability (e.g., grippers, dual-arm coordination), camera quality/placement, and the maturity of the knowledge base and prompts. Safety, compliance, and integration with existing systems (LIMS/EHR/QMS) are critical dependencies for regulated environments.
Glossary
- action prediction horizon: the number of future time steps for which the policy outputs actions in each inference. Example: "and denotes the action prediction horizon."
- ACT: an imitation-learning approach that mitigates long-horizon error accumulation by chunking actions. Example: "AugSmolVLA improves execution stability over ACT, X-VLA, and the original SmolVLA"
- affordance: in robotics, the actionable possibilities an object or scene offers to an agent. Example: "affordance assessment"
- AugSmolVLA: a SmolVLA variant with online visual-perturbation augmentation tailored to wet-lab conditions. Example: "we further develop AugSmolVLA, an online augmentation strategy tailored to transparent labware, specular reflections, illumination shifts, and overexposure."
- atomic action space: a predefined, closed set of primitive operations the robot can execute. Example: "maps the explicit action predicates in the protocol to a predefined atomic action space"
- bimanual: involving two arms operating in coordination for a task. Example: "3 representative bimanual tasks"
- BioProVLA-Agent: the proposed affordable, protocol-driven, vision-enhanced embodied multi-agent system for wet-lab manipulation. Example: "Here, we introduce BioProVLA-Agent, an affordable, protocol-driven, and vision-enhanced embodied multi-agent system enabled by Vision-Language-Action (VLA) models for biological laboratory manipulation."
- biofoundry automation: integrated, automated facilities and workflows for biological engineering and experimentation. Example: "integrates machine learning, LLMs, and biofoundry automation"
- closed-loop-capable reasoning: decision-making that uses feedback from verification and sensing to iteratively adjust actions. Example: "closed-loop-capable reasoning"
- Completion Rate (CR): a metric for multi-step tasks measuring the proportion of successfully completed steps. Example: "For composite-task experiments, the Completion Rate (CR) is used as the evaluation metric."
- composite workflows: multi-step procedures composed of multiple atomic tasks. Example: "6 composite workflows"
- cryotube: a small, cryogenic storage tube used for biological samples. Example: "1.8 mL cryotubes"
- curriculum learning: a training strategy that introduces tasks or perturbations from easy to hard. Example: "a curriculum-learning-based online data augmentation strategy"
- Diffusion Policy: a policy that generates actions via a conditional diffusion process for visuomotor control. Example: "Chi et al. proposed Diffusion Policy, which formulates robotic action generation as a conditional diffusion process"
- diffusion Transformer: a Transformer architecture used within diffusion models for action generation. Example: "adopts a diffusion Transformer"
- dual-Arm: robotic systems or tasks involving coordinated control of two arms. Example: "dual-Arm manipulation"
- embodied: AI systems that perceive and act through a physical body (robot) in the real world. Example: "vision-enhanced embodied multi-agent system"
- flow matching: a generative modeling technique used to learn mappings between distributions, here for control. Example: "built on a pretrained VLM and flow matching"
- foundation-model-based: leveraging large, pretrained multimodal or LLMs for downstream tasks. Example: "Existing foundation-model-based robotic systems"
- Guiding Decision Agent: the coordinator that schedules tasks, handles retries, and manages verification/execution flow. Example: "The Guiding Decision Agent coordinates protocol parsing, state verification, and embodied execution"
- human-in-the-loop teleoperation: data collection or control where a human guides or intervenes during robot operation. Example: "via human-in-the-loop teleoperation."
- imitation learning: learning control policies by mimicking expert demonstrations. Example: "long-horizon imitation learning"
- LeRobot format: a standardized data format for storing robot demonstrations and observations. Example: "All data were stored in the LeRobot format"
- long-horizon: tasks or protocols involving many sequential steps with dependencies. Example: "long-horizon protocols"
- observation-to-action mapping: direct mapping from sensory inputs to control actions without intermediate symbolic reasoning. Example: "direct observation-to-action mapping"
- OT-2: a benchtop liquid-handling robot platform for laboratory automation. Example: "operation scripts for an OT-2 liquid-handling robot"
- PaLM-E: a multimodal embodied LLM integrating vision, state, and text for planning and reasoning. Example: "Driess et al. proposed PaLM-E"
- parametric models: models whose knowledge is stored in learned parameters (e.g., neural networks), as opposed to external databases. Example: "combines parametric models with external knowledge bases"
- precondition: a required state that must hold before a task can be executed. Example: "precondition verification"
- RDT-1B: a diffusion-Transformer-based foundation model for dual-arm manipulation. Example: "Liu et al. proposed RDT-1B, which adopts a diffusion Transformer"
- ReKep: a VLM-based method for spatial reasoning and constraint generation for robotic tasks. Example: "ReKep"
- Retrieval-Augmented Generation (RAG): augmenting model outputs with information retrieved from an external knowledge base. Example: "Retrieval-Augmented Generation (RAG) combines parametric models with external knowledge bases"
- RoboChemist: a framework using VLMs for planning, visual prompting, and monitoring in chemical experiments. Example: "the RoboChemist framework"
- RoboVQA: a visual question answering benchmark for long-horizon robotic tasks. Example: "RoboVQA"
- RT-2: a vision-language-action model that transfers web-scale pretraining to robotic control. Example: "Zitkovich et al. proposed RT-2, which transfers Internet-scale vision-language pretraining knowledge to robotic control"
- self-driving laboratories: automated labs capable of autonomous planning and execution of experiments. Example: "self-driving laboratories in chemistry and materials science"
- semantic verification: checking task feasibility and completion using high-level semantic cues (e.g., from VLMs) before/after actions. Example: "explicit semantic verification before and after execution"
- serum bottle: a laboratory bottle used to hold liquids, here for waste or sample collection. Example: "a 25 mL serum bottle"
- SmolVLA: a lightweight vision-language-action model designed for low-cost, low-computation deployment. Example: "Shukor et al. proposed SmolVLA, emphasizing VLA deployment under low-cost and low-computation conditions"
- specular reflections: mirror-like reflections that can degrade visual perception of shiny/transparent objects. Example: "specular reflections"
- Success Rate (SR): the proportion of successful trials for a single atomic task. Example: "the Success Rate (SR) is used as the primary evaluation metric."
- Tailored LLM Protocol Agent: the component that parses natural-language protocols into structured, verifiable subtasks. Example: "The Tailored LLM Protocol Agent converts unstructured biological protocols into executable and verifiable subtask units"
- transparent labware: clear laboratory vessels (e.g., tubes, bottles) that complicate vision due to transparency. Example: "transparent labware"
- VLA (Vision-Language-Action): models that map visual and language inputs to robotic action outputs. Example: "Vision-Language-Action (VLA) models"
- VLA Embodied Agent: the module that generates and executes low-level actions from instructions and observations. Example: "The VLA Embodied Agent produces the final embodied execution."
- VLA policy: the learned controller within a VLA model that outputs action sequences. Example: "a lightweight VLA policy"
- VLM (Vision-LLM): models that jointly process visual and textual inputs for reasoning or perception. Example: "Vision-LLM (VLM)-based methods"
- VLM-RAG Verification Agent: the verifier that uses VLMs plus retrieved knowledge to assess preconditions and completion. Example: "the VLM-RAG Verification Agent reasons over real-time visual observations, robot states, retrieved operation knowledge, and reference success/failure examples"
- VoxPoser: a VLM-based approach for spatial reasoning and constraint generation for robot planning. Example: "VoxPoser"
- wet-lab: real-world laboratory environments dealing with physical experiments and materials (as opposed to simulations). Example: "real wet-lab environments"
- X-VLA: a VLA approach using soft prompts to handle data heterogeneity across embodiments. Example: "Zheng et al. proposed X-VLA, which uses soft prompts to address data heterogeneity across robotic embodiments"
Collections
Sign up for free to add this paper to one or more collections.