- The paper introduces a capability-driven pipeline that decomposes embodied task planning into sequential vision-language sub-problems using a unified VLM.
- It employs a multi-stage training paradigm—including supervised fine-tuning, DAgger-like training, and expert-guided reinforcement—to enhance sample efficiency and robustness.
- Empirical results show state-of-the-art success rates across benchmarks while the modular design provides transparency for error analysis and interpretability.
RoboAgent: Capability-Chaining for Embodied Task Planning
The embodied task planning (ETP) problem presents agents with complex, long-horizon tasks specified in natural language, demanding robust perception, reasoning, and sequential decision-making from visual observation streams. While large Vision-LLMs (VLMs) have shown strong capabilities in multimodal reasoning, their effectiveness in ETP has remained limited due to the requirements for multi-turn interaction, precise context management, and hierarchical long-term reasoning.
"RoboAgent: Chaining Basic Capabilities for Embodied Task Planning" (2604.07774) introduces a capability-driven planning pipeline to better exploit the reasoning potential of VLMs in embodied agents. The key principle is explicitly decomposing planning into a sequence of vision-language problems via a set of core capabilities, invoked through a central scheduler—all supported by a unified, end-to-end trained VLM backbone, without external symbolic tools.
RoboAgent Framework
The RoboAgent architecture introduces a hierarchical structure where planning is modularized into a scheduler and five domain-specific capabilities, all parametrized by a single VLM. The scheduler processes the task specification and interaction context, dynamically invoking capabilities to handle specific sub-problems. Each capability maintains its context and is responsible either for high-level reasoning or generating environment-interacting actions.
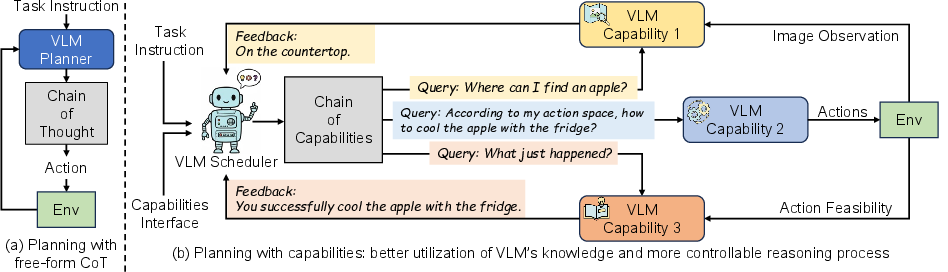
Figure 1: Diagrammatic comparison between conventional CoT-enhanced planners and the RoboAgent pipeline, which modularizes reasoning via explicit capability invocation and unified VLM.
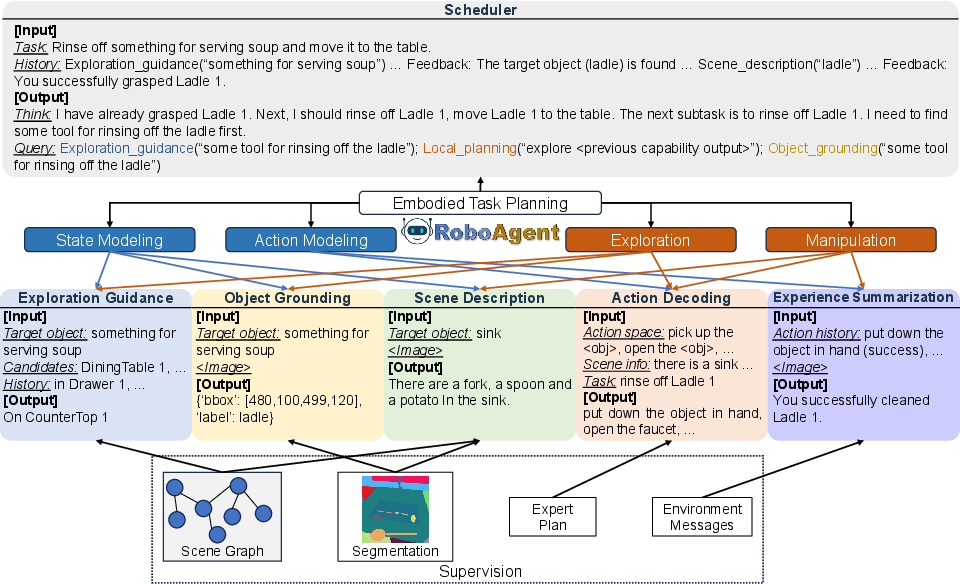
Figure 2: Schematic of RoboAgent's scheduler and the five vision-language capabilities.
The five defined capabilities are:
- Exploration Guidance (EG): Commonsense-driven predictions for where to search for target objects.
- Object Grounding (OG): Open-vocabulary visual object localization and annotation.
- Scene Description (SD): Contextual description of object state and relations.
- Action Decoding (AD): Translation of high-level intentions into executable atomic actions.
- Experience Summarization (ES): Analysis of execution results and error diagnostics.
By chaining these capabilities, the agent can transparently trace and explain its reasoning processes, enabling fine-grained supervision and improved interpretability compared to prior black-box approaches.
Multi-Stage Training Paradigm
RoboAgent’s VLM backbone is optimized via a three-stage pipeline:
- Supervised Fine-Tuning (SFT) on Expert Trajectories: Expert plans provide demonstrations for capability invocation and task decomposition. Privileged simulator information (object locations, segmentation masks) enables accurate, capability-specific supervision during this stage.
- DAgger-like Training on Model-Generated Data: The model is deployed to collect trajectories and error-corrective supervision is synthesized via the simulator, providing fine-grained corrective signals for open-vocabulary and complex environments. Data augmentation extensively enhances object / action description diversity.
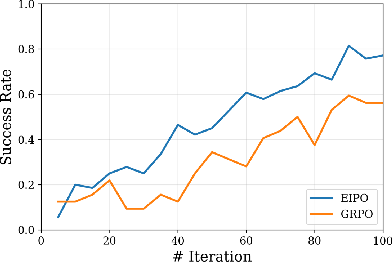
- Reinforcement Fine-Tuning (RFT) with Expert-Guided Policy Optimization: An Expert-Induced Policy Optimization (EIPO) algorithm is proposed, where the scheduler receives per-step rewards based on expert policy advantage, enabling stable offline policy refinement and improved scheduler generalization.
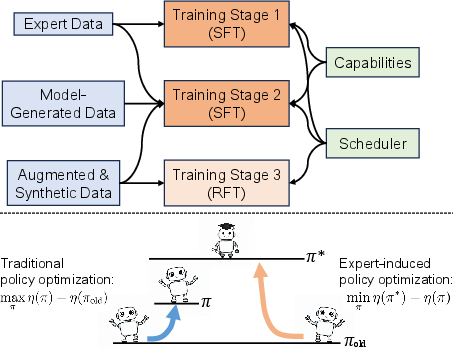
Figure 3: Overview of training stages and EIPO objective, contrasting conventional RL with expert advantage-based optimization.
This pipeline crucially addresses covariate shift and sparse-reward exploration issues typical in embodied settings, yielding improved sample efficiency and robustness.
Empirical Results
Extensive experiments across three major ETP benchmarks—ALFWorld, EB-ALFRED, and LoTa-WAH—demonstrate strong empirical results.
RoboAgent preserves strong generalization across seen/unseen splits, diverse task templates, and even with substantial simulator discrepancies in out-of-domain (OOD) transfer scenarios. The ablation studies substantiate the vital role of DAgger-based fine-tuning and RFT, and demonstrate that explicit capability invocation consistently yields higher SR and robustness relative to direct action decoding approaches.
Transparency and Failure Analysis
The explicit capability design provides unique transparency into agent reasoning, facilitating granular error diagnosis. Manual analysis shows most failures arise from open-vocabulary visual recognition (OG), ambiguous or underspecified instructions, or inherent simulation limitations. This insight is leveraged to inform future data augmentation and capability enhancements.
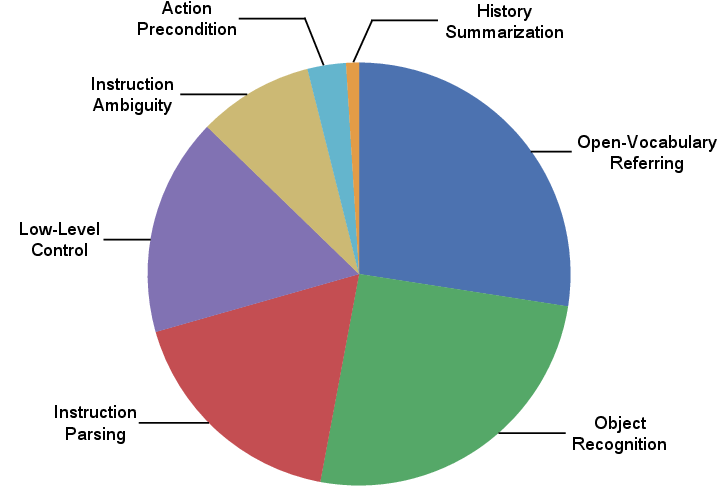
Figure 5: Error distribution breakdown on EB-ALFRED, exposing predominant sources of failure in OG and instruction interpretation.

Figure 6: Visualization of typical RoboAgent failure cases involving missed instruction cues and open-vocabulary object misidentification.
Practical Implications and Theoretical Considerations
Practically, RoboAgent’s end-to-end capability-chaining leverages VLMs' perception and reasoning skills in a scalable framework directly adaptable to various instruction and observation modalities. The explicit modularization is well-aligned with the current trends of compositional generalist agents and offers routes towards more interpretable, verifiable autonomous systems.
Theoretically, the EIPO algorithm highlights a new direction in offline RL for VLM-based agents, using stable expert advantages to mitigate reward variance and policy drift. The capability-driven approach provides a structure for incorporating additional expert knowledge, synthetic compositional tasks, and continual adaptation—crucial for scalable agent architectures.
Future Research Directions
Potential avenues include:
- Scaling to richer, more diverse and longitudinal embodied datasets, encompassing further household and industrial domains.
- Dynamic extension or adaptation of the capability set, potentially via meta-learning or automated skill discovery.
- Integration with low-level visuomotor controllers for seamless plan-to-execution pipelines.
- Application of EIPO and related expert-advantage optimization in broader RLHF or world model training contexts for VLM agents.
Conclusion
RoboAgent introduces and validates a scalable, modular, and interpretable VLM-driven architecture for embodied task planning. The explicit chaining of core capabilities, coupled with a robust multi-stage training paradigm and stable expert-guided policy optimization, yields state-of-the-art empirical performance and effective generalization across task domains and modalities. The framework paves the way for future research on compositionality, modular reasoning, and general-purpose embodied AI.