Optimizer-Model Consistency: Full Finetuning with the Same Optimizer as Pretraining Forgets Less
Abstract: Optimizers play an important role in both pretraining and finetuning stages when training LLMs. In this paper, we present an observation that full finetuning with the same optimizer as in pretraining achieves a better learning-forgetting tradeoff, i.e., forgetting less while achieving the same or better performance on the new task, than other optimizers and, possibly surprisingly, LoRA, during the supervised finetuning (SFT) stage. We term this phenomenon optimizer-model consistency. To better understand it, through controlled experiments and theoretical analysis, we show that: 1) optimizers can shape the models by having regularization effects on the activations, leading to different landscapes around the pretrained checkpoints; 2) in response to this regularization effect, the weight update in SFT should follow some specific structures to lower forgetting of the knowledge learned in pretraining, which can be obtained by using the same optimizer. Moreover, we specifically compare Muon and AdamW when they are employed throughout the pretraining and SFT stages and find that Muon performs worse when finetuned for reasoning tasks. With a synthetic language modeling experiment, we demonstrate that this can come from Muon's strong tendency towards rote memorization, which may hurt pattern acquisition with a small amount of data, as for SFT.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper asks a simple, practical question about training LLMs: when you first train a model on tons of mixed text (“pretraining”) and later teach it a new skill with a small, high‑quality dataset (“finetuning”), what training method helps it learn the new skill without forgetting what it already knew?
Their main finding: if you finetune the model using the same kind of optimizer (the training “style” or “coach”) that was used during pretraining, the model learns the new task just as well (or better) and forgets less of its old knowledge. The authors call this “optimizer‑model consistency.”
They also compare two popular optimizers—AdamW (very common) and Muon (newer)—and find a surprise: even though Muon often produces a stronger model after pretraining, it can perform worse than AdamW after finetuning on reasoning tasks like math. A small, controlled experiment suggests Muon may memorize specific examples more quickly but learn general patterns less reliably when data is limited.
What the researchers wanted to find out
They focused on three kid‑friendly questions:
- Does using the same optimizer for finetuning as for pretraining help the model learn new skills while forgetting less?
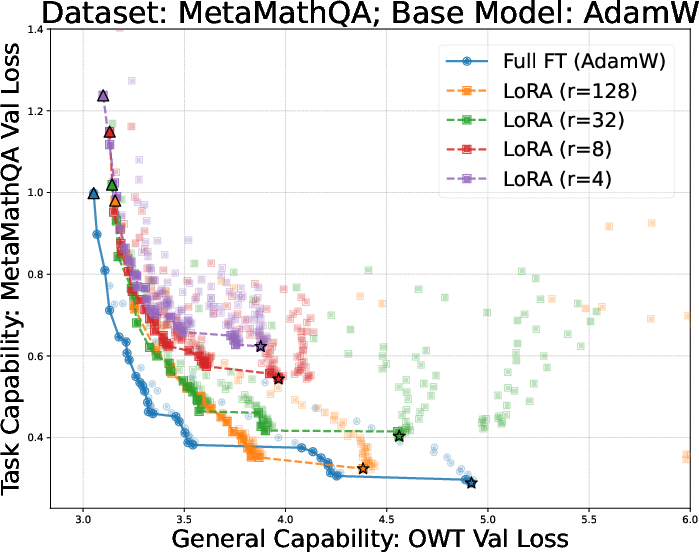
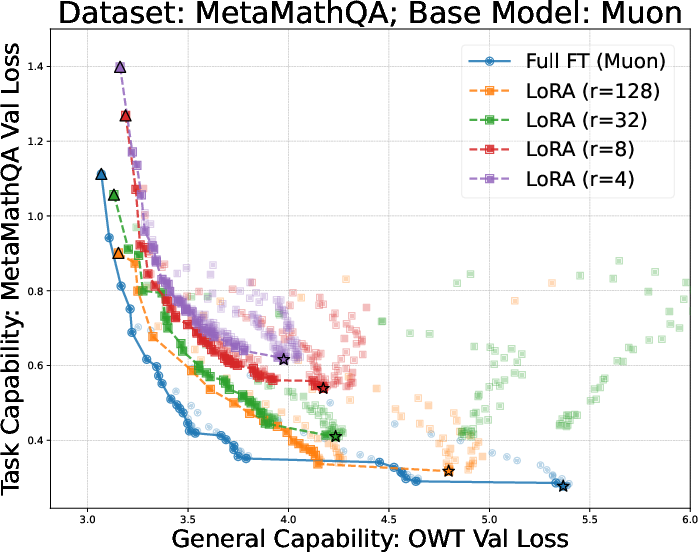
- Is LoRA (a popular, lightweight finetuning method) better or worse than full finetuning for this “learn‑new, forget‑less” balance?
- Why would the “same optimizer” help? Is there a simple reason inside how models store information?
- How do two specific optimizers—AdamW and Muon—compare across both pretraining and finetuning, especially on tasks that require reasoning?
How they studied it (in everyday terms)
Think of training a model like teaching a student:
- Pretraining: a long period where the student reads lots of books and learns general language skills.
- Finetuning: a short extra course (like a math or coding workshop) with limited time and materials. The goal is to add a new skill without making the student forget how to write or speak.
Now think of optimizers as “training styles” or “coaches”:
- AdamW and Muon are two coaching styles that push the student to learn in slightly different ways.
- LoRA is like adding small, detachable “notebooks” to the student’s brain instead of rewriting everything—cheap and quick, but limited.
What they did:
- Experiments on two model sizes:
- A smaller model (GPT‑2 small) that they fully pretrained themselves.
- A larger one (Llama‑2‑7B) where they did finetuning.
- Finetuning tasks:
- Math (MetaMathQA), instruction following (Alpaca), and coding (Magicoder).
- How they measured “learning” and “forgetting”:
- Learning: performance on the new task (lower loss or higher accuracy is better).
- Forgetting: how much performance on generic language (the pretraining data) got worse.
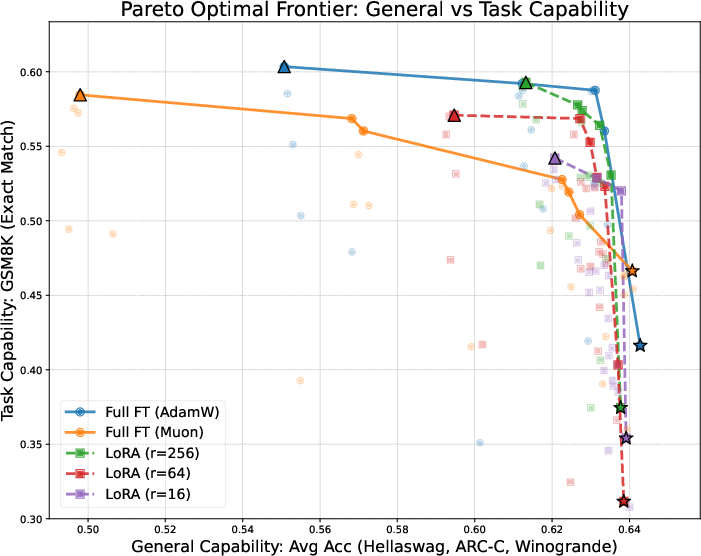
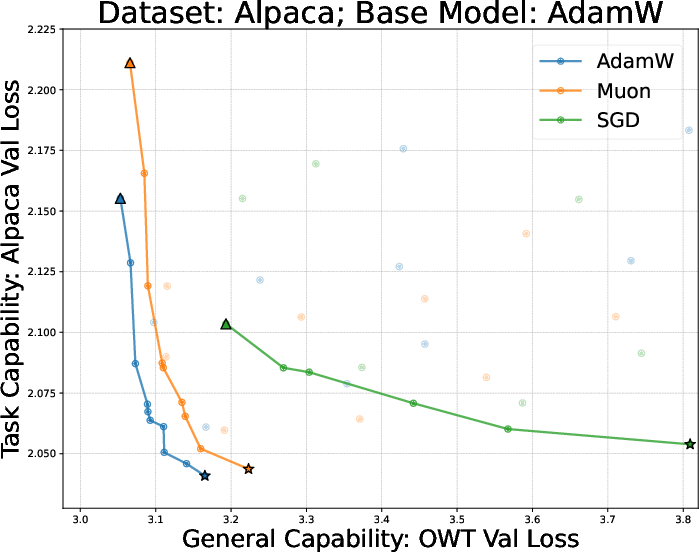
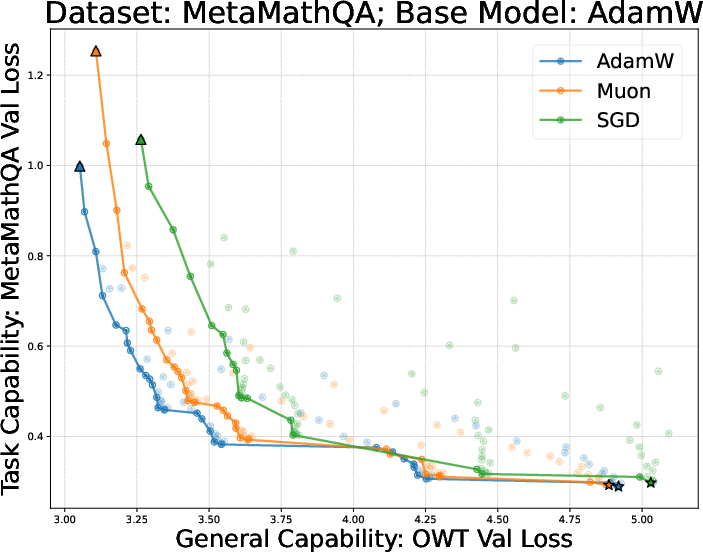
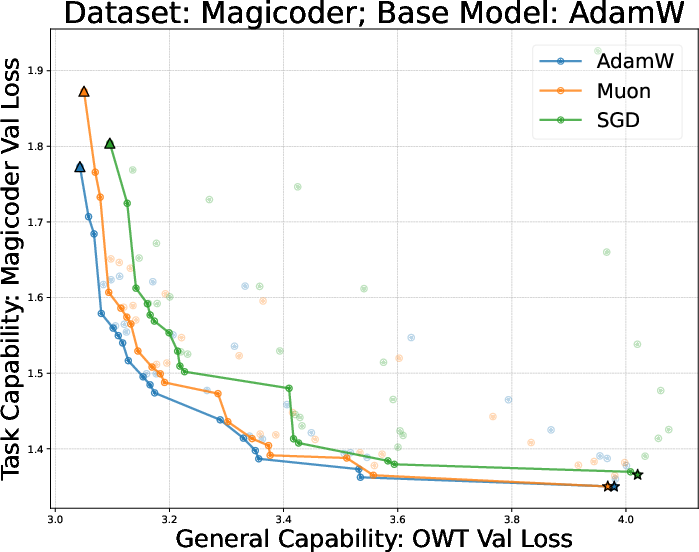
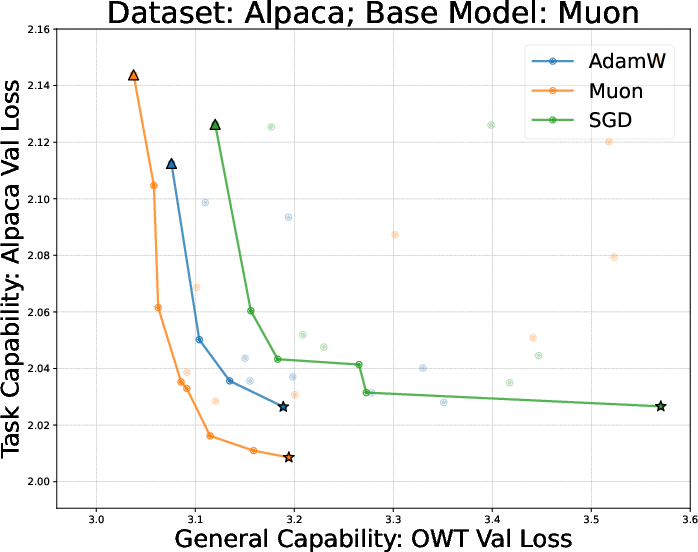
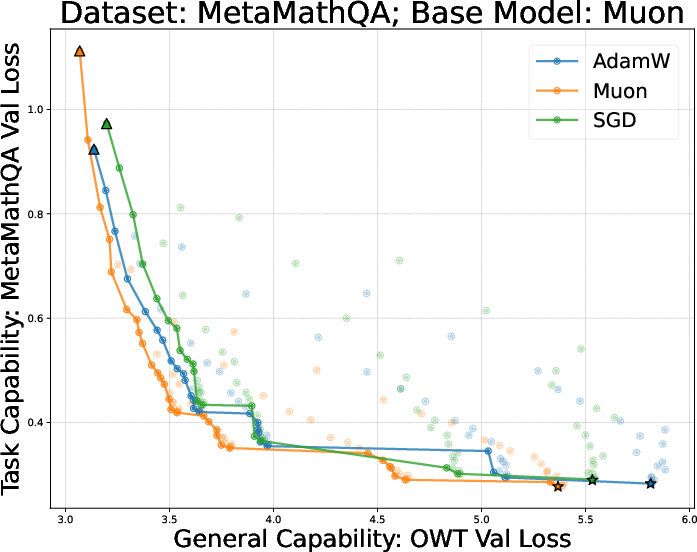
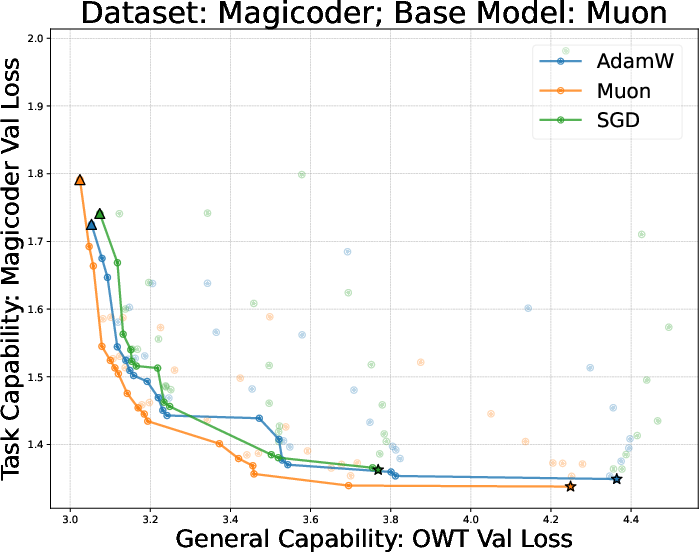
- They tried many learning rates and training durations and plotted a curve called a Pareto frontier (a line of “best trade‑off” points—like the best combinations of learning a lot and forgetting little).
A simple theory to explain why this works:
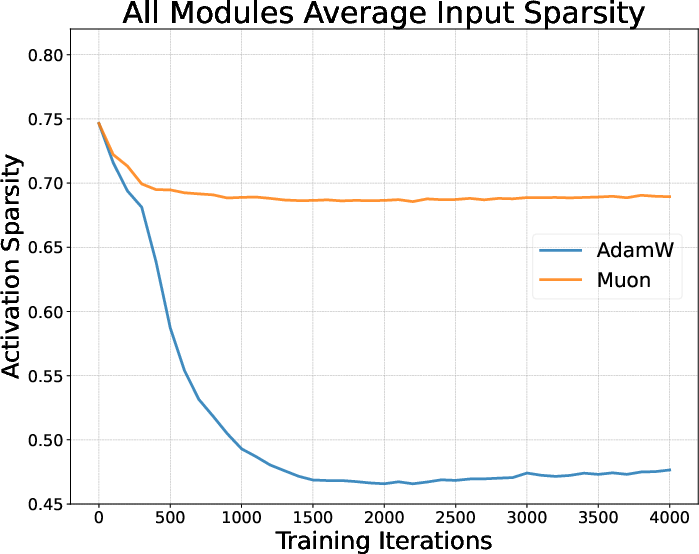
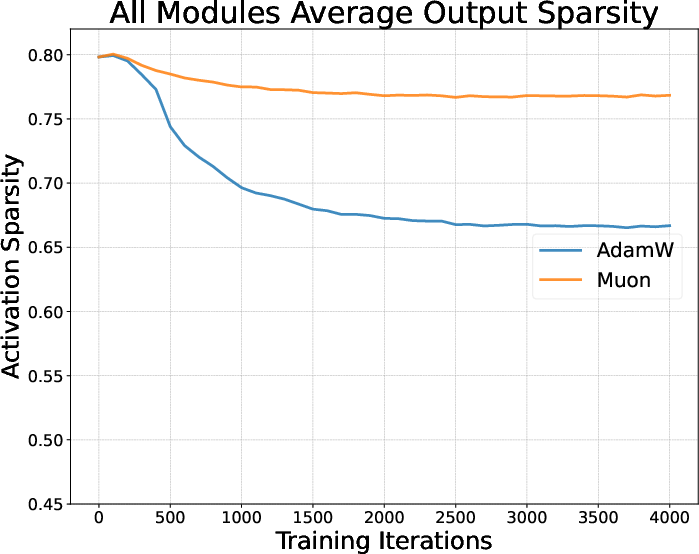
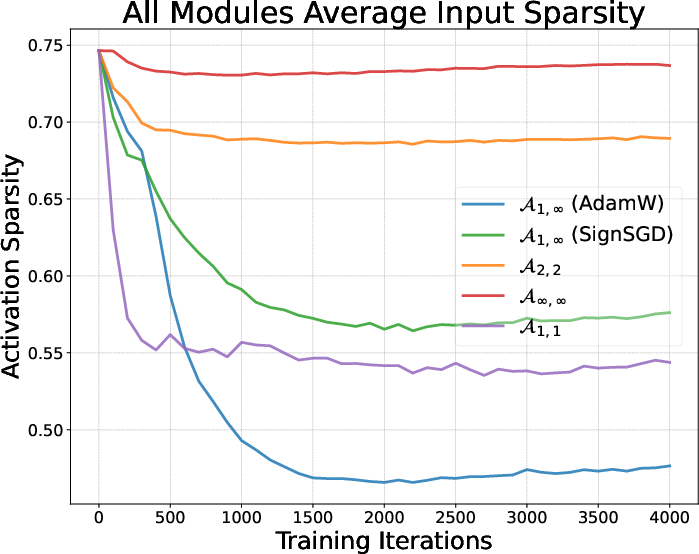
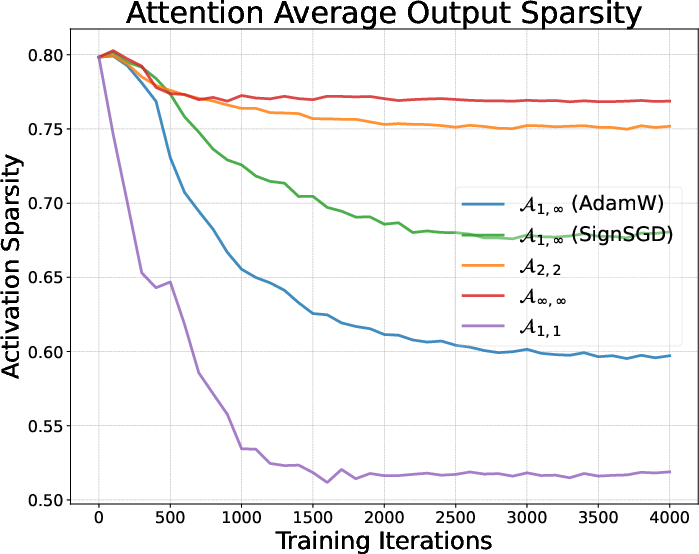
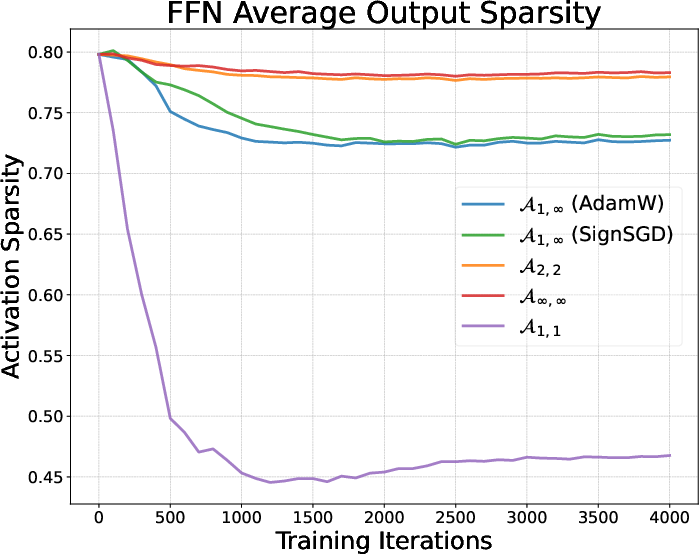
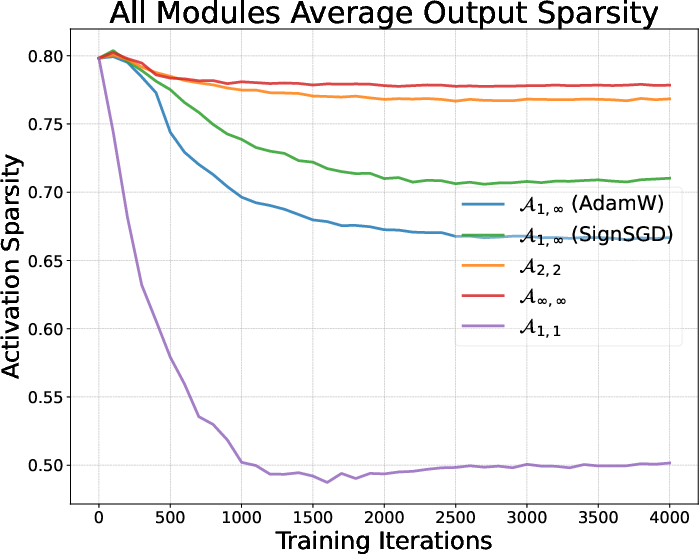
- Different optimizers shape the model’s “habits” during pretraining—what parts of the model are active and how they fire (called “activations”). You can think of them as how the student organizes notes—some styles favor sparse, focused notes (few active features at a time), others spread out the attention more evenly.
- Because these habits differ, using a different optimizer in finetuning can clash with what the model is used to—like switching from a flash‑card coach to an essay‑coach mid‑course. That mismatch can cause more forgetting.
- Using the same optimizer keeps the “habits” consistent, so the update fits the model’s internal structure better and preserves more of what it already knows.
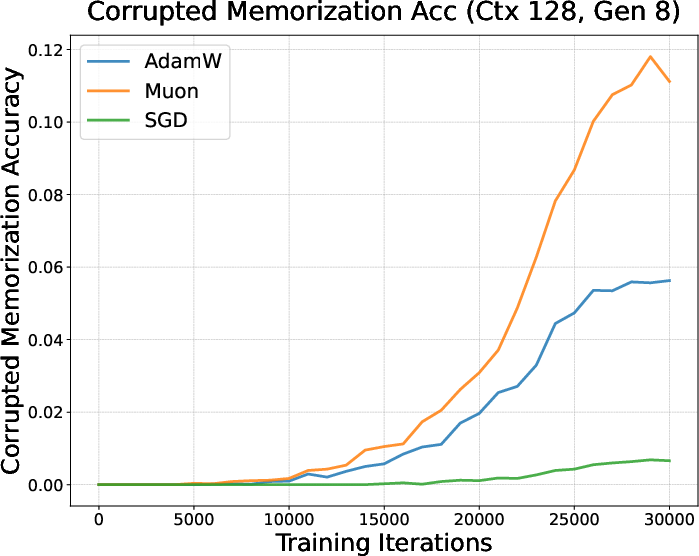
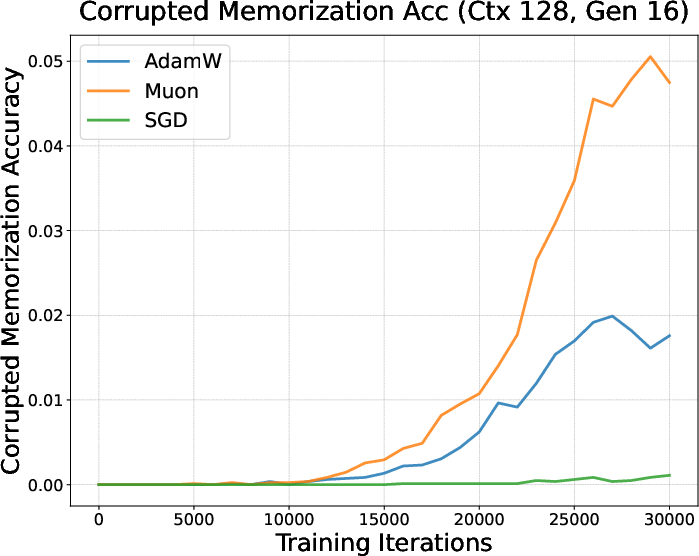
A memorization experiment:
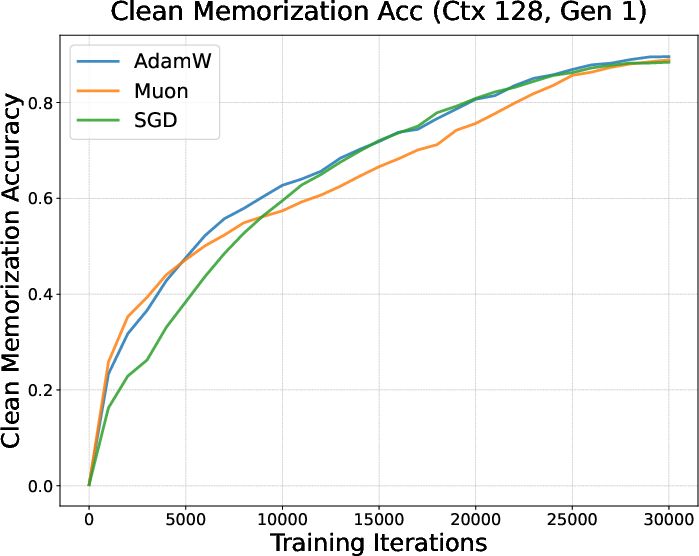
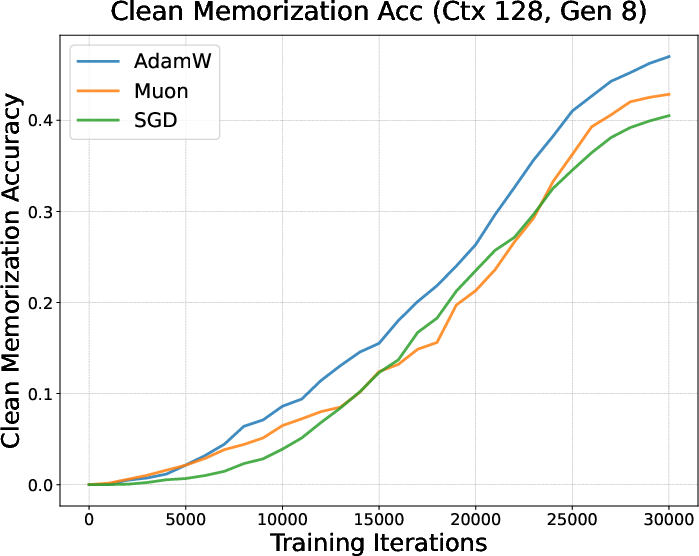
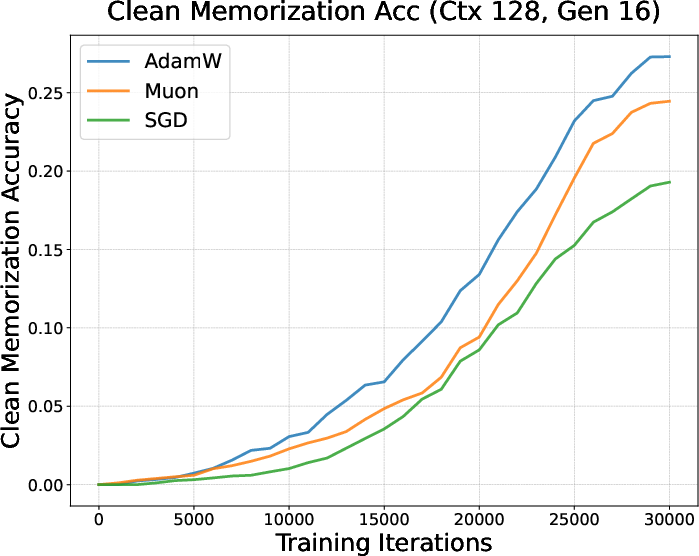
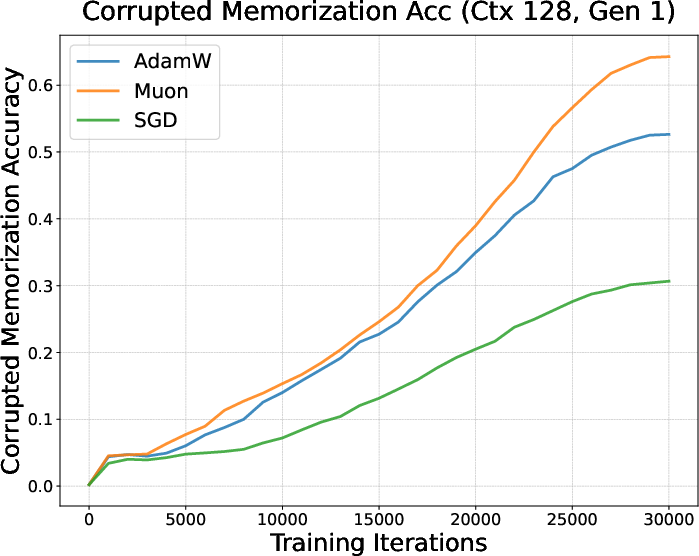
- They mixed normal sentences (clean data) with shuffled‑word sentences (corrupted data) where no real pattern exists (you can only memorize them).
- They trained with AdamW, Muon, and SGD and checked how quickly models:
- Learned patterns (clean data).
- Memorized noise (corrupted data).
- Result: Muon started memorizing the corrupted data earlier and more strongly, but didn’t learn the clean patterns as well under limited data—suggesting a tendency toward rote memorization when time/data are short (like in finetuning).
What they found (key results)
- Using the same optimizer for finetuning as for pretraining is best for the learn‑new/forget‑less balance.
- On both the small (GPT‑2) and larger (Llama‑2‑7B) settings, full finetuning with the same optimizer sat on the “best trade‑off” curve: less forgetting for the same (or more) learning.
- Full finetuning can beat LoRA on both learning and forgetting—if you choose the learning rate carefully.
- LoRA often forgets less at its “best learning” setting, but when you scan across learning rates, there’s always a full‑finetune setting that forgets less while learning the same or better.
- Why this happens:
- Optimizers make the model develop different activation “habits” during pretraining (for instance, AdamW tends to make activations sparser; Muon spreads them more).
- Finetuning with the same optimizer matches these habits and “fits” the local landscape around the pretrained checkpoint, leading to less forgetting.
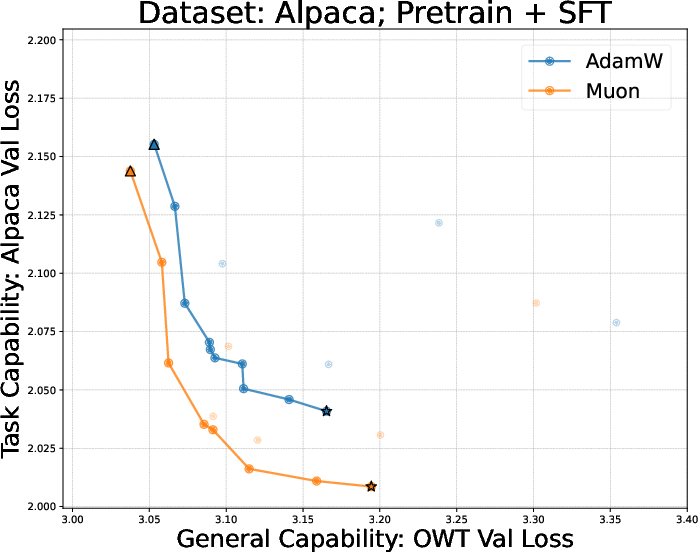
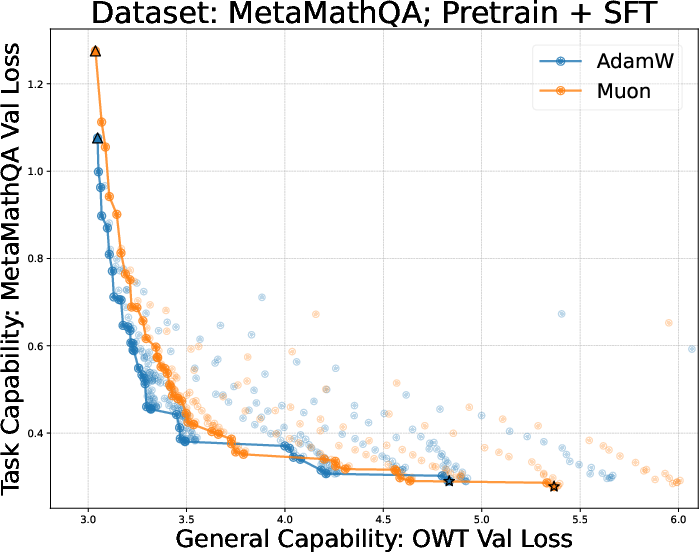
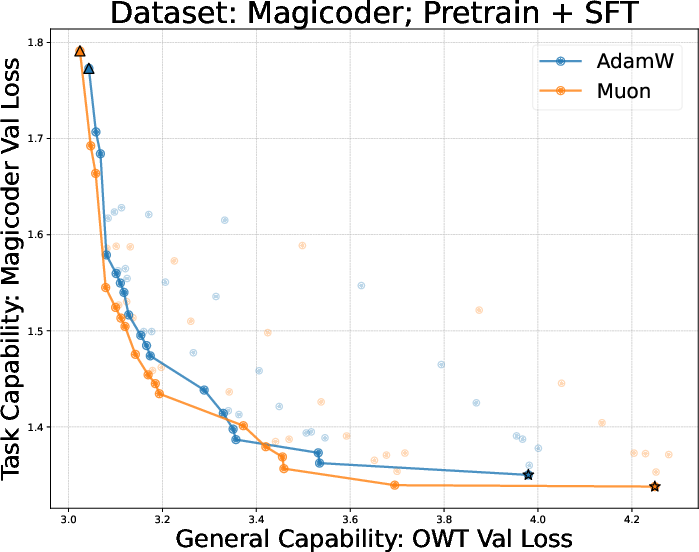
- AdamW vs Muon across pretraining + finetuning:
- Muon often gives better pretrained models.
- But after finetuning on reasoning tasks (like math), Muon’s advantage can shrink or vanish—and sometimes it’s worse than AdamW.
- The synthetic experiment suggests a reason: Muon memorizes faster but may pick up general patterns more slowly when data is limited, which is common in finetuning.
Why this matters (practical impact)
- If you’re finetuning a model, use the same optimizer family that was used in pretraining to reduce forgetting while still learning the new task well.
- Don’t assume LoRA always forgets less. Full finetuning, with a well‑chosen learning rate, can be better on both learning and forgetting.
- When judging optimizers, don’t just look at pretraining scores. Check the whole pipeline—pretraining plus finetuning—especially on reasoning tasks.
- For Muon users: Muon can shine in pretraining, but you may need a carefully designed finetuning strategy (or alternative finetuning settings) to avoid excessive memorization and get strong reasoning gains from small finetuning datasets.
In short: training style matters. Keeping the same style from pretraining into finetuning helps the model keep its old skills while gaining new ones—and being mindful of how each optimizer learns (pattern‑finding vs memorization) can lead to better overall performance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future work.
- Scale and generality: Results are primarily on GPT‑2‑small and a single Llama‑2‑7B SFT setting; no Muon‑pretrained 7B+ checkpoints are evaluated. It remains unknown whether optimizer‑model consistency holds across 7B–70B+ models, diverse architectures (e.g., RMSNorm variants, GQA/MoE), and broader training regimes.
- Variance and statistical robustness: The paper does not report variability across random seeds or confidence intervals. It is unclear how stable the Pareto frontiers and conclusions are under seed, data shuffle, and run-to-run variance.
- Breadth of tasks: Only three SFT datasets (instruction following, math, code) are used. The phenomenon’s robustness on broader tasks (e.g., multilingual, long‑context, retrieval‑augmented, safety alignment, factuality, reasoning benchmarks like MMLU/BBH/GSM8K, code pass@k) is untested.
- Forgetting metric validity: Forgetting is proxied by OpenWebText validation loss (GPT‑2) and a “general knowledge” metric (7B) without assessing whether these correlate with real‑world capability retention (e.g., MMLU, HELM composites). The sensitivity of conclusions to the choice of forgetting metric is unquantified.
- Learning metric validity: Learning is measured as task validation loss rather than standard task‑specific metrics (e.g., accuracy, exact match, pass@1/10, human preference). It is unknown if the learning–forgetting tradeoff persists under more task‑faithful evaluations.
- Hyperparameter scope: Pareto frontiers sweep learning rate and training period but not other influential knobs (weight decay, betas/momentum, grad clipping, cosine/step LR schedules, warmup, microbatch size, gradient norm constraints, EMA, Adam ε). Whether optimizer‑model consistency survives a broader hyperparameter search is unanswered.
- Fairness of optimizer comparisons: Some settings differ across methods (e.g., Adam without weight decay for Llama‑2‑7B) and may advantage specific optimizers. A fully controlled ablation (identical schedules/regularizers/clipping) is missing.
- Architecture‑specific effects: LayerNorm type (LN vs RMSNorm), activation functions (GELU vs SwiGLU), RoPE variants, kv‑caching, and residual scaling may interact with activation statistics and optimizer regularization. These interactions are not explored.
- Time‑to‑result and efficiency: The paper does not report wall‑clock time, memory, or throughput differences among optimizers during SFT. Practical tradeoffs (e.g., Muon’s overhead vs gains) remain unquantified.
- Longevity of retention: Forgetting is measured immediately post‑SFT. Whether optimizer‑model consistency persists over longer SFT, multi‑epoch finetuning, sequential multi‑task finetuning, or after RLHF/DPO stages is unknown.
- Continual learning settings: The work does not evaluate multi‑task or sequential SFT (task streams), where catastrophic forgetting is classically studied. It is unclear if the conclusions extend to longer task sequences with or without rehearsal.
- Interaction with PEFT beyond LoRA: Only LoRA is tested; no comparison with QLoRA, AdaLoRA, LoKr, DoRA, IA³, prompt‑/prefix‑tuning, adapters, or hybrid schemes. Whether any PEFT method can match or surpass full‑FT under optimizer‑model consistency remains open.
- LoRA search space: LoRA ranks and hyperparameters (rank, α, dropout, scaling) are only lightly varied. It is untested if richer LoRA configurations, longer training, or optimizer‑consistent regularization can close the gap to full FT.
- Mixed or changing pretraining optimizers: The analysis assumes a single pretraining optimizer family. Many large models use mixed optimizers or curriculum schedules. How optimizer‑model consistency manifests when pretraining uses a mixture or switches optimizers is unstudied.
- Layer‑wise heterogeneity: The theorem suggests matching α across pretraining and SFT globally. Real models may exhibit layer‑wise differences in activation statistics and curvature. Whether per‑layer optimizer choices (or mixtures) further improve tradeoffs is untested.
- Theory relies on strong approximations: Key assumptions (Fisher≈Hessian, block‑diagonal Hessian, Kronecker factorization, independence of x and δ, alignment of norms, and that optimizers “regularize” activations in senses) are not empirically validated at scale. Direct curvature measurements and alignment tests are missing.
- Mapping Adam to A_{1,∞}: Treating Adam as an A_{1,∞}‑family optimizer via SignSGD is heuristic. A rigorous derivation and tests against SignSGD/Lion family members are needed to substantiate theoretical claims and Theorem 1’s prescriptions.
- Mechanism validation: The causal pathway from optimizer‑induced activation regularization to reduced forgetting is hypothesized but not established. Interventions (e.g., whitening/reshaping activations, freezing norms, modifying LayerNorm statistics) to test causality are not performed.
- Activation statistics beyond sparsity: Evidence centers on a sparsity proxy. Comprehensive activation distributions (per‑layer and per‑token norms across p, anisotropy, covariance spectra, sparsity patterns through depth) and their evolution during SFT are not reported.
- Early‑training measurements: Activation sparsity comparisons are taken after 4k pretraining iterations (for analysis plots), which may not reflect converged properties. Whether the same trends hold at later stages is unknown.
- Muon memorization evidence: The “memorization vs pattern learning” conclusion relies on a synthetic corrupted‑text setup. It remains unclear if the same behavior holds on real SFT distributions (e.g., math/code with limited data) with stronger memorization probes (nearest‑neighbor recall, exposure metrics).
- Privacy and safety implications: If Muon promotes memorization, does this increase training‑data leakage risk? No privacy leakage or exact‑match exposure analyses are performed.
- Interplay with RLHF/DPO and preference tuning: The study focuses on SFT. Whether optimizer‑model consistency holds—or reverses—during human preference optimization and post‑training alignment is untested.
- Long‑context and retrieval‑augmented settings: How optimizer‑model consistency interacts with long‑context tasks (e.g., 32k–1M tokens) and retrieval, where activation statistics differ, is unexplored.
- Quantization and low‑precision finetuning: The behavior under QLoRA/4‑8‑bit quantization or NF4 precision is not studied. It is unknown whether consistency benefits persist or are attenuated by quantization noise.
- Regularization and clipping effects: Weight decay, dropout, gradient clipping, and spectral norm constraints may counteract optimizer‑induced activation properties. Their moderating role on learning–forgetting is not ablated.
- Practical guidance scope: The prescriptive recommendation (“use the same optimizer family as pretraining”) lacks guidance for cases where the pretraining optimizer is unknown, proprietary, or mixed. Heuristics for inferring or adapting to the implicit α,β from observed activation statistics are not provided.
- Extensions to other matrix optimizers: Beyond Muon and AdamW, it remains unknown how Shampoo/Soap, K‑FAC, GaLore, ASGO, Mars, Sophia, Lion, AdaFactor, or structured/low‑rank preconditioners behave under the same evaluation and theory.
- Combined methods: Whether hybrid strategies—e.g., PEFT plus small full‑FT subsets, per‑layer optimizer mixing, or activation‑aware regularizers—can match/surpass full FT while retaining efficiency is not investigated.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s findings that organizations can implement with current tools and models.
- Consistency-aware finetuning defaults in LLM pipelines
- Sectors: software/ML tooling, foundation model providers
- Application: When finetuning a checkpoint, default to the same (family of) optimizer used in pretraining (e.g., AdamW for Llama-2), and perform a brief learning-rate/step sweep to select a Pareto-optimal point on the learning–forgetting frontier.
- Tools/workflows: Add an “optimizer-consistency” flag to training scripts; enrich training configs with pretraining optimizer metadata; implement a small LR grid with “forgetting-aware early stopping.”
- Assumptions/dependencies: Pretraining optimizer is known; full finetuning is feasible on available hardware; a proxy for pretraining distribution is available to measure forgetting.
- Add forgetting metrics to standard SFT evaluation
- Sectors: industry ML teams, academia
- Application: Alongside task validation metrics, track the loss (or perplexity) on a held-out pretraining-like corpus to quantify forgetting, and publish Pareto curves for each finetune.
- Tools/workflows: Extend evaluation harnesses (e.g., Hugging Face Trainer) with a “base-corpus” validation set; dashboards showing learning vs. forgetting over steps.
- Assumptions/dependencies: Reasonable proxy for the pretraining distribution; compute overhead for dual validation.
- Model-card “optimizer lineage” and finetuning guidance
- Sectors: model hubs, model vendors, compliance
- Application: Include the pretraining optimizer family and recommended SFT optimizers in model cards; warn when PEFT choices (e.g., LoRA) trade off worse on forgetting at matched learning.
- Tools/workflows: Model-card schema updates; CI checks that pin SFT defaults to consistent optimizers.
- Assumptions/dependencies: Availability of accurate pretraining metadata.
- Enterprise SFT runbooks that prioritize consistency over PEFT
- Sectors: enterprise AI, healthcare, finance, legal-tech
- Application: Prefer full finetuning with pretraining-consistent optimizers for high-stakes deployments where retaining general knowledge (e.g., medical safety, compliance rules) is critical; if PEFT is mandatory, use higher LoRA ranks and conservative LRs to approach the full-finetune frontier.
- Tools/workflows: Policy-based selection in AutoML; fallbacks to LoRA with rank/lr guidance.
- Assumptions/dependencies: Budget for full finetuning vs. PEFT; organizational risk appetite.
- Risk controls for Muon in small-data reasoning SFT
- Sectors: code assistants, math/reasoning tutors, research LLMs
- Application: If a base model was pretrained with Muon and SFT data are small and reasoning-heavy, expect relatively more rote memorization and potentially worse generalization; mitigate by curriculum design, stronger regularization, lower LR, or mixing pattern-first objectives before aggressive optimization.
- Tools/workflows: Curriculum schedulers; loss mixing (e.g., auxiliary pattern-consistency losses), LR warmup and caps; increased validation on compositional splits.
- Assumptions/dependencies: The paper’s synthetic evidence generalizes; monitoring reveals early-onset memorization.
- Forgetting-aware early stopping and LR scheduling
- Sectors: software/ML tooling, MLOps
- Application: Jointly monitor task learning and base-corpus forgetting to stop training or reduce LR when the Pareto frontier turns unfavorable.
- Tools/workflows: Two-objective schedulers; Pareto-based early stopping hooks in trainers.
- Assumptions/dependencies: Stable forgetting proxy; reproducible validation signals.
- Continual update procedures that keep optimizer consistent across tasks
- Sectors: customer-support bots, domain-specialized assistants
- Application: When sequentially finetuning on new domains, keep the optimizer family fixed to reduce catastrophic forgetting; interleave small replay of prior-domain data where possible.
- Tools/workflows: Task-switch pipelines with consistent optimizer settings; lightweight replay buffers.
- Assumptions/dependencies: Storage and licensing for replay data; clear task boundaries.
- Safety and privacy governance adjustments
- Sectors: policy/compliance, privacy engineering
- Application: Since consistency reduces forgetting, organizations handling “right-to-be-forgotten” or sensitive content should plan for explicit unlearning steps; do not rely on routine SFT to erase prior content.
- Tools/workflows: Unlearning pipelines; data scrubbing audits; documentation of optimizer choices in governance artifacts.
- Assumptions/dependencies: Legal and data-retention requirements; availability of unlearning methods.
- Domain deployments that must retain general competence
- Sectors: healthcare, finance, aviation/industrial, education
- Application: For clinical or regulatory assistants, finetune with the pretraining-consistent optimizer to maintain general safety knowledge while adding domain skills; track forgetting as a safety KPI.
- Tools/workflows: Safety gates tied to forgetting thresholds; rollbacks if general-knowledge regression is detected.
- Assumptions/dependencies: Certified evaluation suites; domain oversight.
- Productization: “Consistency-aware finetuning” service
- Sectors: AI platforms, cloud providers
- Application: Offer finetuning as a managed service that automatically detects base optimizer, runs small Pareto sweeps, and returns checkpoints at different learning–forgetting tradeoffs for downstream selection.
- Tools/workflows: Service APIs; AutoML sweepers; reporting of Pareto points.
- Assumptions/dependencies: Vendor access to model metadata; cost controls for sweeps.
- Developer guidance for PEFT users
- Sectors: OSS communities, edtech startups
- Application: If constrained to LoRA, raise rank and reduce LR to approach full-finetune forgetting; prefer full finetuning with consistent optimizer when retention matters (e.g., tutoring systems that must keep language fluency while adding curriculum-specific skills).
- Tools/workflows: PEFT presets labeled by “retention priority”; examples in docs.
- Assumptions/dependencies: Compute vs. retention trade-off is acceptable.
- Personal assistants and on-device models
- Sectors: consumer, mobile
- Application: For user-personalization SFT, use the base model’s optimizer to minimize degradation of general abilities; if privacy requires on-device PEFT, choose higher-rank adapters and conservative LRs.
- Tools/workflows: Lightweight on-device consistent optimizers; calibrated LR schedules.
- Assumptions/dependencies: Device constraints; energy/cost budgets.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development before broad deployment.
- Optimizer-aware PEFT methods that match activation regularization
- Sectors: software/ML research, OSS
- Application: Design adapter architectures or preconditioners that emulate the activation regularization of the pretraining optimizer (e.g., A_{α,β}-aligned adapters) to recover full-finetune-like forgetting behavior with parameter efficiency.
- Dependencies: Theory and empirical validation across scales; efficient implementations.
- Adaptive optimizers that morph during SFT
- Sectors: optimizer research, hardware–software co-design
- Application: Develop SFT optimizers that begin with pattern-first (less memorization) updates and gradually increase capacity, or interpolate between AdamW-like A_{1,∞} and Muon-like A_{2,2} to target desired points on the learning–forgetting curve.
- Dependencies: Reliable on-line signals for when to switch modes; scalable kernels.
- Standardization of optimizer metadata in model cards
- Sectors: policy/consortia, model hubs
- Application: Establish a standard field for “pretraining optimizer family” plus SFT guidance; require disclosure in procurement and safety audits for high-stakes deployments.
- Dependencies: Community consensus; updates to documentation tooling.
- Benchmarks and certification for learning–forgetting tradeoffs
- Sectors: academia, regulators, safety labs
- Application: Create public suites that quantify retention vs. task gains; certify models that meet domain-specific forgetting thresholds (e.g., healthcare safety).
- Dependencies: Representative pretraining-proxy corpora; accepted metrics.
- Unlearning methods that leverage optimizer mismatch
- Sectors: privacy/compliance
- Application: Explore using controlled optimizer inconsistency and LR schedules as a tool to accelerate forgetting of targeted content before precise unlearning is applied.
- Dependencies: Predictive models of forgetting dynamics; legal validation.
- Muon-friendly finetuning strategies for reasoning
- Sectors: code/maths assistants, research
- Application: Design curricula, regularizers, or architectural tweaks that counter Muon’s tendency toward early memorization in small SFT, preserving its pretraining advantages while improving reasoning gains.
- Dependencies: Larger-scale studies; new objectives that emphasize compositionality.
- Continual-learning systems built on optimizer consistency
- Sectors: robotics, industrial automation, customer support
- Application: For lifelong adaptation, maintain optimizer family consistency across task updates and incorporate small replay/elastic regularization to preserve core competencies.
- Dependencies: Data retention policies; real-time constraints.
- Hardware support for matrix-norm-based preconditioning
- Sectors: AI accelerators, systems
- Application: Provide primitives for efficient A_{α,β}-style updates (e.g., fast norm estimation, per-layer normalization) to scale optimizer-consistent finetuning on-device and in datacenters.
- Dependencies: Kernel design; compiler support.
- Educational technology and curricula-aligned tutors
- Sectors: education
- Application: Finetune base models for curricula while preserving general language ability; study optimizer-consistent finetuning as a method to avoid “narrowing” student-facing models.
- Dependencies: Age-appropriate safety evaluation; privacy-preserving SFT pipelines.
- Sector-specific policies for model updates
- Sectors: healthcare, finance, public sector
- Application: Issue guidance that model updates must demonstrate acceptable forgetting profiles using optimizer-consistent SFT or equivalent, with documented evaluation on base-corpus proxies.
- Dependencies: Regulatory adoption; auditable processes.
Notes on assumptions and dependencies that affect feasibility
- Scale and generality: Core experiments are on GPT-2 and Llama-2-7B; extrapolation to frontier scales is plausible but unconfirmed.
- Theory approximations: Explanations rely on Fisher/Hessian approximations and activation–weight alignment; some assumptions may be looser in practice.
- Metadata availability: Many closed models do not disclose pretraining optimizers; standards would help.
- Compute constraints: Full finetuning is more expensive than PEFT; organizations must budget for LR sweeps and dual validation.
- Data proxies: Measuring forgetting requires a pretraining-like corpus; choices here influence conclusions.
- Task dependence: The Muon memorization tendency is most salient in small-data, reasoning-heavy SFT; results may vary by domain and data scale.
Glossary
- : A matrix-induced operator norm used to define optimizers that constrain updates based on input-output vector norms. "we denote ${A}_{\alpha,\beta} \triangleq \max_{x \neq 0}\frac{Ax}_{\beta}{x}_{\alpha}$ and the optimizer derived from as ."
- AdamW: An adaptive gradient optimizer with decoupled weight decay, widely used for training transformers and LLMs. "Among the optimizers, the current workhorse for LLM training is undoubtedly AdamW~\citep{kingma2014adam,loshchilov2017decoupled} and its variants, with Muon~\citep{jordan2024muon} and other recently emerged matrix-structured optimizers as strong competitors applied in frontier model training~\citep{team2026kimi,zeng2025glm,deepseekai2026deepseekv4}."
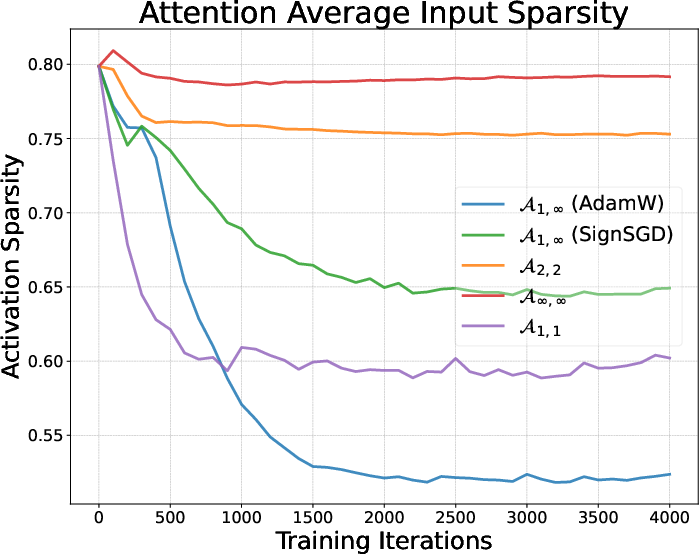
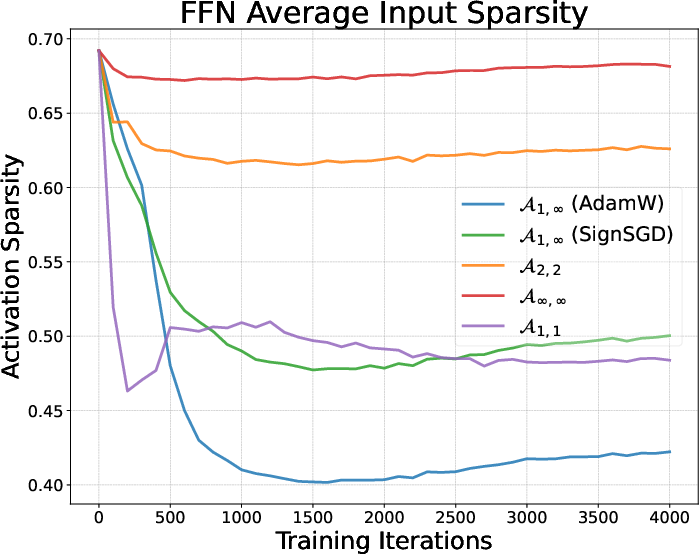
- Activation sparsity: The property that many components of an activation vector are near zero, often associated with L1-like regularization. "Activation sparsity of AdamW and Muon."
- Block-wise diagonal (Hessian structure): The assumption/observation that the Hessian can be approximated by blocks aligned to layers with small off-diagonal coupling. "the Hessians of neural networks are typically block-wise diagonal with respect to layers~\citep{martens2015optimizing,singh2021analytic,nayak2025sculpting}"
- Fisher Information matrix: The expected outer product of gradients, often used as a practical approximation to the Hessian in deep networks. "we further consider the Fisher Information matrix as an effective approximation of the Hessian ~\citep{martens2015optimizing}"
- Hessian: The second-derivative matrix of the loss with respect to parameters, describing local curvature. "we further consider the Fisher Information matrix as an effective approximation of the Hessian "
- Kronecker product: A matrix operation producing a block matrix from two matrices, used in curvature approximations. "where denotes the Kronecker product"
- Learning-forgetting tradeoff: The balance between gaining performance on a new task and preserving previously learned capabilities. "We call balancing the two factors the learning-forgetting tradeoff."
- LoRA: A parameter-efficient fine-tuning method that inserts low-rank adapters into layers to reduce trainable parameters. "parameter-efficient training methods are also powerful, with LoRA~\citep{hu2022lora} as the most popular and representative one."
- Matrix induced norms: Operator norms induced by vector norms on inputs/outputs, used to derive structured optimizers. "we focus on the matrix induced norms under the framework"
- Matrix-structured optimizers: Optimizers that exploit the matrix/tensor structure of network parameters for preconditioning or constraints. "and other recently emerged matrix-structured optimizers as strong competitors applied in frontier model training~\citep{team2026kimi,zeng2025glm,deepseekai2026deepseekv4}."
- Muon: A matrix-aware optimizer (approximately ) designed for stable, full-rank updates in deep networks. "Muon achieves better pretraining performance compared to AdamW."
- Optimizer-model consistency: The phenomenon that using the same optimizer family for pretraining and fine-tuning yields better learning–forgetting outcomes. "We term this phenomenon optimizer-model consistency."
- Pareto frontier: The set of configurations that are non-dominated with respect to simultaneous objectives (here, learning vs. forgetting). "we plot a Pareto frontier where each point corresponds to a learning rate choice and a training period for a specific training method."
- Parameter-efficient training: Techniques that fine-tune a small subset or low-rank subspace of parameters to reduce compute/memory. "parameter-efficient training methods are also powerful"
- Pretrained checkpoint: A saved model state obtained after large-scale pretraining, used as the starting point for fine-tuning. "With the pretrained checkpoint in hand, we typically start the finetuning stage with supervised finetuning (SFT)"
- Regularization effects on the activations: Implicit constraints imposed by the optimizer that shape input/output activations (e.g., sparsity vs. density). "optimizers can shape the models by having regularization effects on the activations"
- Rote memorization: Learning by exact recall of training examples rather than extracting generalizable patterns. "strong tendency towards rote memorization"
- SignSGD: An optimizer that uses only the sign of gradients (linked here to in the induced-norm framework). "SignSGD~\citep{bernstein2018signsgd} is by noticing that the vector infinite norm is equivalent to ."
- Singular sparsity: A measure of how concentrated a matrix’s singular values are, indicating effective rank characteristics. "and singular sparsity is ."
- Stable rank: An effective-rank metric defined from singular values, less sensitive to small singular values than the true rank. "the stable rank is "
- Supervised finetuning (SFT): Fine-tuning on labeled, task-specific data to adapt a pretrained model to downstream tasks. "we typically start the finetuning stage with supervised finetuning (SFT), where models are trained upon the pretrained checkpoints with high-quality but relatively small amounts of data"
- Taylor expansion: A local series approximation of a function, here used to approximate loss changes after small parameter updates. "We have the following Taylor expansion approximation of the pretraining loss increase after SFT:"
- Vectorizing (weights): Flattening a matrix into a vector (e.g., by stacking rows) for analysis/derivations. "the operation means vectorizing by stacking the rows"
- Weight decay: A regularization technique that penalizes parameter magnitude, commonly implemented as decoupled L2 decay. "even without weight decay"
Collections
Sign up for free to add this paper to one or more collections.

