Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting
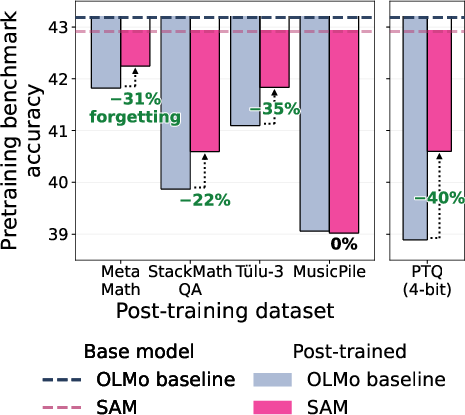
Abstract: Pretraining optimizers are tuned to produce the strongest possible base model, on the assumption that a stronger starting point yields a stronger model after subsequent changes like post-training and quantization. This overlooks the geometry of the base model which controls how much of the base model's capabilities survive subsequent parameter updates. We study three pretraining optimization approaches that bias optimization toward flatter minima: Sharpness-Aware Minimization (SAM), large learning rates, and shortened learning rate annealing periods. Across model sizes ranging from 20M to 150M parameters, we find that these interventions consistently improve downstream performance after post-training on five common datasets with up to 80% less forgetting. These principles hold at scale: a short SAM mid-training phase applied to an existing OLMo-2-1B checkpoint reduces forgetting by 31% after MetaMath post-training and by 40% after 4-bit quantization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting — A Simple Explanation
What is this paper about?
This paper looks at a common problem in training AI models called catastrophic forgetting. That’s when a model learns something new (like how to follow instructions better) but then forgets things it knew before (like coding or math skills). The authors show a better way to do the early training (pretraining) so the model holds onto its old skills even after later changes like fine-tuning or compression.
What questions did the researchers ask?
- Can we train base models so they don’t forget as much when we later fine-tune them on new tasks?
- Are there simple training tweaks that make models less sensitive to changes (like fine-tuning or quantization) without needing special tricks during fine-tuning?
- Do these ideas still help on bigger models?
How did they study it? (Methods in everyday language)
Think of training a model like finding a good spot to rest in a big, bumpy landscape (the “loss landscape”). A low spot is good (low loss), but some low spots are sharp and pokey (sharp minima): if you move even a little, you slip and do worse. Other low spots are wide and flat (flat minima): you can shuffle around a bit and still be fine. Fine-tuning and compression nudge the model’s “position.” If the model sits in a sharp spot, even small nudges can make it forget; if it’s in a flat spot, it keeps its skills.
The team tested three pretraining tricks that encourage landing in flatter spots:
- Sharpness-Aware Minimization (SAM): a training method that specifically looks for places that stay good even if you wiggle the weights a little.
- Higher peak learning rate: taking bigger steps early on tends to avoid sharp, fragile pits.
- Shorter learning-rate “annealing” at the end: instead of slowly shrinking the step size for a long time (which can settle you into sharp pits), shrink it for a shorter period.
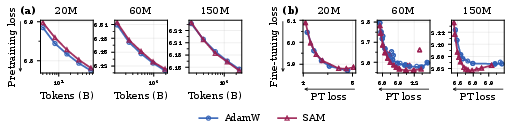
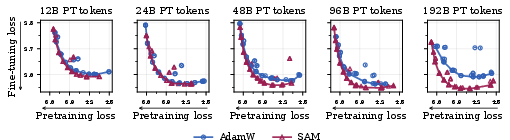
They trained LLMs of different sizes (20M, 60M, 150M parameters) on up to 192B tokens, then:
- Fine-tuned them on several tasks (coding, math, instruction following, music).
- Compressed them with 4-bit quantization (like shrinking a photo to take less space).
- Added tiny random weight noise (to test general sensitivity).
They measured a “learning–forgetting tradeoff”: how much the model improves on the new task versus how much it forgets its old skills. They also tried a larger model (OLMo-2-1B) and added a short SAM phase mid-training to see if the ideas scale.
What did they find, and why is it important?
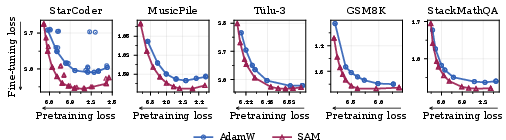
- SAM clearly reduced forgetting after fine-tuning. For example, on a coding task (StarCoder), models trained with SAM forgot up to 80% less than standard training when they reached the same fine-tuning quality.
- The benefits grew with more pretraining data and often with bigger models. Standard training became more fragile as training went on, but SAM stayed robust.
- The same protections showed up beyond fine-tuning:
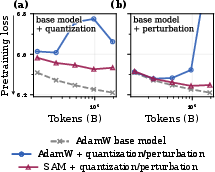
- Under 4-bit quantization, SAM-trained models lost much less performance (about 2–3× less loss in tough, high-token settings).
- Models were also less sensitive to small random weight changes.
- You can get much of SAM’s benefit cheaper by using it only late in training (during the final “annealing” phase). That adds only about 10% extra compute instead of ~100% for using SAM the whole time.
- At 1B scale (OLMo-2-1B), a short SAM mid-training phase (50B tokens) cut forgetting by:
- 31% after fine-tuning on MetaMath.
- 40% after 4-bit quantization.
- And it did this even though the SAM base model was slightly worse before fine-tuning—the SAM version ended up better after fine-tuning or compression.
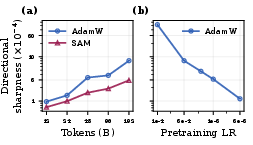
Why does this work? Because flatter “valleys” mean small changes to the model (from fine-tuning or compression) don’t hurt as much. The authors also measured the model’s “sharpness” and showed that SAM and larger learning rates really do reduce the kind of sharpness that matters for fine-tuning.
What does this mean going forward? (Implications)
- Don’t pick pretraining settings only by how good the base model looks before fine-tuning. Pick settings that also make the model stable under future changes.
- Practical recipe: keep your usual setup, but during the last part of training, switch to SAM or use a shorter annealing period and/or a slightly higher peak learning rate. This gives you more “forgetting-proof” checkpoints with little extra cost.
- This can make models more reliable after fine-tuning and easier to deploy after compression—useful for real-world systems that need to learn new skills without losing old ones.
Helpful terms (in plain language)
- Pretraining: the big first phase where the model learns general language skills from lots of text.
- Fine-tuning (post-training): a later phase where the model learns a specific task (like math or coding).
- Catastrophic forgetting: when learning the new task makes the model lose earlier abilities.
- Quantization: compressing the model’s numbers to use fewer bits (e.g., 4-bit), which saves memory and speed but can hurt accuracy.
- Learning rate: how big a step the model takes during each training update.
- Annealing: slowly lowering the learning rate near the end of training.
- Sharpness/flatness: how sensitive performance is to tiny changes in the model’s weights; flat is safer, sharp is fragile.
- SAM (Sharpness-Aware Minimization): a training method that favors flat, stable solutions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide actionable follow-up research.
- External validity across scales and architectures
- Validate beyond a single 1B mid-training case: do sharpness-aware annealing gains persist for 3B–70B+ models trained from scratch (not just mid-trained) and for mixture-of-experts or encoder–decoder architectures?
- Assess robustness under large-batch pretraining regimes common at scale; SAM’s behavior depends on batch size, yet batch-size–sharpness interactions are not ablated.
- Breadth of downstream settings
- Test with realistic post-training pipelines (e.g., SFT+RLHF/DPO, multi-stage instruction tuning, PEFT methods like LoRA/IA3, adapters, and parameter-efficient merging). The current evaluation uses full-parameter fine-tuning with a narrow set of losses and no PEFT variants.
- Examine multi-task fine-tuning and continual-learning sequences (task curricula, task interleaving, replay) to see whether pretraining-time sharpness mitigation composes with complex adaptation protocols beyond a single downstream dataset.
- Generality across domains and data distributions
- Expand downstream tasks beyond code, math, instruction following, and music to include diverse natural language reasoning, multilingual data, long-context tasks, and multimodal settings.
- Quantify how the similarity between pretraining and fine-tuning distributions mediates forgetting (the paper notes Tülu-3 is “closer” to DCLM but does not systematically measure or control for distributional distance).
- Metrics and evaluation design
- Validate that pretraining validation loss (and the OLMo benchmark-suite proxy at 1B) is an adequate operational measure of “forgetting” and correlates with capability retention on real-world evaluations; include capability-level metrics (accuracy, pass@k, exact match) and human eval where relevant.
- Report learning–forgetting frontiers in terms of sample efficiency and wall-clock/step efficiency (e.g., steps or tokens required to reach a target downstream performance), not only final losses.
- Assess statistical robustness: include multiple seeds, uncertainty intervals, and standardized hyperparameter sweeps to disentangle method effects from tuning variance.
- Optimizer and schedule ablations
- Beyond AdamW vs SAM, compare other pretraining optimizers (e.g., Adafactor, Sophia, Lion, Muon, Shampoo/Adagrad variants) and sharpness-aware variants (ASAM, ESAM, GSAM, SWA) to determine whether the effect is SAM-specific or a general “flatness-first” principle.
- Systematically ablate SAM hyperparameters (ρ, per-layer normalization, ascent steps, gradient clipping, weight decay interactions) and the fraction/timing of the annealing window under SAM.
- Explore schedule design space beyond cosine and WSD (e.g., linear, polynomial, step, two-phase restarts) and warmup duration; quantify how each phase (warmup, hold, decay) influences sharpness and forgetting.
- Mechanistic understanding of geometry
- Measure richer geometric diagnostics: full/leading Hessian spectrum, trace, directional spectra across multiple downstream directions, local Lipschitz constants, and parameterization-invariant sharpness metrics; current analysis focuses on a single fine-tuning direction and one task (StarCoder).
- Identify conditions for the quadratic approximation to reliably predict forgetting (radius of validity, dependence on fine-tuning LR, token budget, and optimizer); provide theoretical or empirical bounds on approximation error.
- Disentangle whether reduced forgetting arises from flatter minima, different representation learning (e.g., sparsity, feature reuse), or implicit regularization effects not captured by Hessian curvature alone.
- Compression coverage
- Extend beyond 4-bit weight-only PTQ with bitsandbytes NF4 to additional compression settings: activation quantization, 3/2-bit regimes, group/scale strategies, AWQ/GPTQ/QuIP/QAT, outlier handling, per-channel vs per-group quantization, and mixed-precision activation/KV-cache quantization.
- Evaluate pruning (structured/unstructured), low-rank factorization, distillation, and model merging; the paper explicitly leaves pruning for future work.
- Fine-tuning protocol realism
- Vary fine-tuning duration, batch sizes, weight decay, regularization, and early stopping to test whether conclusions hold under common practitioner recipes; current fine-tuning uses “one epoch or 10M tokens, no weight decay.”
- Evaluate PEFT and frozen-backbone setups (LoRA, adapters) where parameter updates are localized—does pretraining flatness still reduce forgetting when Δ is constrained or low-rank?
- Cost, efficiency, and systems considerations
- Quantify training throughput, memory overhead, and implementation complexity of SAM and sharpness-aware annealing at scale, including parallelism strategies; report compute-normalized gains (e.g., improvements per GPU hour).
- Optimize late-phase interventions: What is the minimal effective annealing fraction, and does adaptive or data-dependent triggering (e.g., curvature thresholds) outperform fixed schedules?
- Token budget and mid-training policies
- For the 1B experiment, vary mid-training length, data mixture, and learning-rate policy during the SAM phase to identify when sharpness-aware mid-training yields the largest gains and when it plateaus.
- Investigate whether periodic “geometry refresh” phases (brief SAM bursts) during long pretraining are superior to a single late annealing period.
- Interaction with batch size, gradient noise, and regularization
- Characterize how gradient noise scale, batch size, label smoothing, dropout, and weight decay modulate curvature and forgetting; SAM’s theoretical target (trace vs spectral norm) changes with batch size but is not empirically mapped here.
- Safety, alignment, and reliability impacts
- Evaluate whether sharpness-aware pretraining interacts with safety/alignment post-training (e.g., refusal rates, harmlessness helpfulness tradeoffs), adversarial robustness, or calibration; current study focuses on utility metrics.
- Reproducibility and openness
- Provide complete training configs, seeds, and code for SAM annealing at scale; detail the 1B “benchmark-suite” composition and calibration data for quantization to ensure comparability and independent verification.
- Negative side effects and trade-offs
- Quantify potential downsides: base-model performance regressions, slower downstream learning dynamics, stability issues under very high LRs or extremely short annealing, or degraded in-context learning/induction capabilities.
- Test whether sharper models might be preferable for certain downstream tasks that benefit from high plasticity or rapid specialization, and how to adaptively select between “flat” and “sharp” checkpoints.
Practical Applications
Overview
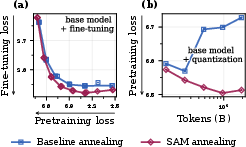
This paper shows that making pretrained models less sensitive to parameter perturbations (by biasing optimization toward flatter minima) substantially reduces catastrophic forgetting during post-training (e.g., SFT/RLHF) and under compression (e.g., 4-bit quantization). Three practical knobs are studied: (1) Sharpness-Aware Minimization (SAM), (2) higher peak learning rates, and (3) shorter learning-rate annealing. A low-cost, deployable recipe—switching to SAM only during the final annealing phase—captures most benefits while adding ~5–10% compute. Gains hold across sizes (20M–150M) and at 1B scale (mid-training OLMo-2-1B), even when base-model loss slightly worsens.
Below are actionable applications and workflows, grouped by timelines, with sector links and dependencies noted.
Immediate Applications
These can be deployed with today’s tooling in standard deep learning stacks (PyTorch, DeepSpeed, Megatron, Lightning, HF Accelerate).
- Industry (model providers, foundation model teams)
- Adopt sharpness-aware annealing in pretraining pipelines
- Workflow: Use your existing schedule (e.g., WSD or cosine) and switch from AdamW to SAM only during the last 5–10% of training steps; reuse base hyperparameters with ρ≈0.05 as a starting point; keep batch size small-to-moderate to match paper conditions.
- Expected outcome: Lower post-training forgetting (31–35% at 1B mid-training in the paper) and better quantization robustness (up to 40% less performance drop at 4-bit).
- Dependencies/assumptions: SAM roughly doubles per-step cost during the SAM phase only; small batch sizes amplify SAM’s effect on Hessian trace; may need minor LR/ρ retuning per architecture.
- Adjust LR policies to improve post-training robustness (even if base loss slightly worsens)
- Workflow: Increase peak LR (up to ~10× prior choice) and shorten the anneal fraction (e.g., from ~20% to 5–10%) while monitoring “learning–forgetting” curves (fine-tuning loss vs. pretraining-loss degradation).
- Expected outcome: Better learning–forgetting and compression–forgetting tradeoffs; delayed onset of catastrophic overtraining.
- Dependencies/assumptions: May hurt base-model validation loss; need stability checks, gradient clipping, and warmup; ensure optimizer/hardware can handle larger step sizes.
- Enterprise fine-tuning (software, healthcare, finance, legal, customer support)
- Choose SAM-annealed base checkpoints for domain SFT to reduce capability loss
- Example: Fine-tuning a general LLM on clinical notes or financial reports while preserving reasoning/coding abilities.
- Expected outcome: Less degradation of general competencies after SFT; smaller hyperparameter search to hit target downstream loss without catastrophic forgetting.
- Dependencies/assumptions: Availability of SAM-annealed or high-LR/short-anneal pretrained checkpoints; benefits depend on similarity between pretraining and downstream domains (smaller gains on Tülu-like data in the paper).
- Improve on-device and edge deployments via “quantization-ready” base models
- Workflow: Prefer base models trained with sharpness-aware annealing before post-training; apply standard PTQ (e.g., bitsandbytes NF4 4-bit).
- Expected outcome: Lower quality drop at 4-bit; broader hardware coverage; reduced inference cost.
- Dependencies/assumptions: Quantization method matters (results shown for NF4); evaluate per accelerator and calibration set; small additional compute in training stage.
- LLMOps and tooling
- Add “learning–forgetting” dashboards to training evaluation
- Product/workflow: Track Pareto frontier of (fine-tuning loss, pretraining loss) across SFT learning rates; include a “quantization readiness score” (degradation at target bit-width).
- Expected outcome: Early detection of catastrophic overtraining; better model selection by downstream robustness, not just base loss.
- Dependencies/assumptions: Requires standardized validation sets for pretraining and fine-tuning; modest automation to sweep SFT LRs.
- Provide a “sharpness-aware annealing” plugin
- Product: A training framework extension that automatically switches optimizers and logs curvature proxies during anneal.
- Expected outcome: Easy adoption and reproducibility across teams.
- Dependencies/assumptions: Implementation of SAM and schedule switching; monitoring of stability metrics.
- Continual learning and frequent updates
- Reduce drift when models are regularly refreshed with new data
- Use sharpness-aware annealing before packaging base models that will receive frequent LoRA/adapter updates (news, code, product catalogs).
- Expected outcome: Less forgetting with each adaptation; better cumulative performance over time.
- Dependencies/assumptions: Proven at 20M–1B scales and common SFT tasks; expect retuning for very large models and diverse domains.
- Safety/compliance and model editing
- More stable behavior under targeted edits (fact/concept updates) and small weight perturbations
- Workflow: Combine SAM-annealed bases with editing methods (ROME, MEMIT, etc.) or safety patches; expect smaller collateral damage.
- Expected outcome: Reduced unintended capability loss; safer rapid updates.
- Dependencies/assumptions: Paper validates robustness with Gaussian noise and PTQ; direct evaluation with editing methods is advised.
- Sector-specific benefits (deployable now)
- Healthcare: Fine-tune hospital-specific assistants while preserving general medical knowledge; deploy 4-bit on clinician laptops with less degradation.
- Finance: Update models on recent market data without erasing econometrics/statistics knowledge; quantize for low-latency desk tools.
- Education: Create curriculum-specific tutors while retaining broad knowledge; run quantized models on student devices.
- Software engineering: Fine-tune code models for internal repos while keeping general coding ability; improve quantized IDE integrations.
- Robotics/embedded: Maintain general policies while adapting to new tasks; robust low-bit models for edge controllers.
Long-Term Applications
These require further R&D, scaling studies, or ecosystem maturation.
- Scaling to frontier models and complex post-training (RLHF, DPO, mixture-of-experts)
- Objective: Validate sharpness-aware annealing at 7B–70B+ with full RLHF pipelines and safety constraints.
- Potential products: “RLHF-ready” base checkpoints with certified forgetting/robustness metrics.
- Dependencies/assumptions: Compute budgets; interplay with preference optimization; stability with very large batch sizes and optimizer variants.
- Automated curvature-aware training control
- Objective: Online monitoring of curvature proxies and edge-of-stability to adapt LR/anneal length and trigger SAM automatically.
- Potential products: “Curvature controller” in training stacks; adaptive anneal length tuner.
- Dependencies/assumptions: Scalable Hessian proxies; reliable signals across architectures.
- Model merging, federation, and multi-tenant adaptation
- Objective: Use flatter-minima checkpoints to improve model merging quality and reduce interference across tenants.
- Potential products: “Mergeability score” integrated with learning–forgetting dashboards; federated learning recipes using sharpness-aware bases.
- Dependencies/assumptions: Validation across diverse tasks and merge methods; privacy/communication constraints.
- Robustness-aware compliance and procurement standards
- Objective: Standardize reporting of learning–forgetting curves and quantization degradation in model cards and procurement.
- Potential tools: Third-party audits/certifications (“post-training robustness grade”).
- Dependencies/assumptions: Industry consensus on benchmarks; alignment with regulatory bodies.
- Cross-modality extensions (vision, speech, multimodal)
- Objective: Apply sharpness-aware annealing to vision-LLMs, ASR, and diffusion backbones to preserve capabilities during domain adaptation and compression.
- Potential products: “Quantization-ready” multimodal bases for edge devices (e.g., AR glasses, automotive).
- Dependencies/assumptions: Architecture-specific SAM/optimizer behavior; task-appropriate robustness metrics.
- Efficient alternatives to SAM for late-stage robustness
- Objective: Develop training-free or low-cost SAM variants (e.g., approximate ascent, stochastic perturbations) specialized for annealing.
- Potential products: Drop-in “cheap SAM” modules for large-scale runs.
- Dependencies/assumptions: Maintaining gains without stability regressions; validation at scale.
- Safety and security hardening
- Objective: Leverage flatter minima to resist weight-bit flips, transient hardware errors, and adversarial fine-tuning.
- Potential products: “Resilient base” certifications and fault-tolerant deployment profiles.
- Dependencies/assumptions: Empirical linkage from curvature reductions to real-world fault models; hardware-lab testing.
- Data and curriculum design co-optimization
- Objective: Combine data selection/mid-training curricula with sharpness-aware annealing to maximize post-training robustness.
- Potential outcome: Token-efficient training that preserves plasticity without catastrophic overtraining.
- Dependencies/assumptions: Joint optimization infrastructure; domain-tailored curricula.
- Theoretical and diagnostic tools
- Objective: Task-conditional directional sharpness estimators and predictive metrics for forgetting risk pre-deployment.
- Potential products: “Forgetting risk forecast” integrated in model evaluation; task-agnostic robustness indices.
- Dependencies/assumptions: Computation-friendly approximations; correlation to downstream performance across settings.
Notes on feasibility and assumptions across applications:
- Results are shown on OLMo-style architectures with small-to-moderate batch sizes and NF4 PTQ; verify on your stack (e.g., MoE, transformers with different norms/activations).
- Gains are strongest at higher token budgets and for tasks farther from the pretraining distribution; benefits may be smaller when downstream data closely matches pretraining.
- Some base-model metrics may worsen slightly; focus selection on downstream Pareto frontiers (learning–forgetting and compression–forgetting), not only pretraining loss.
- Hyperparameters (ρ, anneal fraction, peak LR) require light tuning per model/dataset/hardware; start with ρ≈0.05, anneal 5–10%, and a higher peak LR with careful stability monitoring.
Glossary
- AdamW: An Adam optimizer variant that decouples weight decay from the gradient update to improve generalization and stability. Example: "SAM consistently yields pretrained checkpoints that forget less when fine-tuned to the same performance as AdamW counterparts."
- Annealing (learning rate): A scheduled decrease of the learning rate during training, often near the end, to refine convergence and affect loss landscape sharpness. Example: "shortened learning rate annealing periods."
- bf16: A 16-bit floating-point format (bfloat16) with an 8-bit exponent that preserves dynamic range while reducing memory and compute costs. Example: "full bit-width precision (bf16)"
- bitsandbytes NF4: A 4-bit quantization format (NormalFloat4) implemented in the bitsandbytes library, used for low-precision weight storage. Example: "4-bit quantization (bitsandbytes NF4; Figure~\ref{fig:1b-main}, left and right respectively)."
- Catastrophic forgetting: A phenomenon where a model loses previously learned capabilities when adapted to new tasks or data. Example: "Catastrophic forgetting---the failure of neural networks to retain prior knowledge while learning new information---is a central challenge in deep learning"
- Cosine schedule: A learning-rate schedule that follows a cosine decay curve, often paired with warmup, to control training dynamics and sharpness. Example: "We pretrain OLMo-60M models with a cosine schedule using AdamW and SAM on 192B tokens and fine-tune on five datasets."
- Directional curvature: The second-order curvature (via the Hessian) of the loss function along a specific parameter-space direction, which governs sensitivity to perturbations in that direction. Example: "the directional curvature of the loss landscape with Hessian along the direction of a given vector is the quantity:"
- Directional sharpness: Curvature (sharpness) of the loss specifically along the direction induced by fine-tuning updates, tied to forgetting after adaptation. Example: "SAM and higher peak learning rates reduce directional sharpness along the fine-tuning direction, which empirically upper-bounds and explains their gains in post-fine-tuning loss."
- Edge of Stability: A training regime where the largest Hessian eigenvalue is implicitly constrained by the learning rate, affecting sharpness and convergence. Example: "Learning rate is thought to implicitly regularize curvature via the ``Edge of Stability'' phenomenon"
- EWC (Elastic Weight Consolidation): A continual learning method that penalizes changes to parameters important to prior tasks, mitigating forgetting during fine-tuning. Example: "We further find that SAM's benefits compound with explicit continual learning techniques: combining SAM-pretrained checkpoints with EWC \citep{kirkpatrick2017overcoming} during fine-tuning yields a strictly better learning--\allowbreak forgetting frontier than EWC applied on top of AdamW (Appendix~\ref{subsec:ewc})."
- Hessian: The matrix of second derivatives of the loss with respect to model parameters, capturing local curvature and sharpness of the loss landscape. Example: "where is the Hessian of the pretraining loss."
- Isotropic Gaussian noise: Random parameter perturbations drawn from a spherical Gaussian distribution, used to probe model sensitivity independent of task specifics. Example: "we use a task-agnostic proxy: isotropic Gaussian noise added to the pretrained weights, with sensitivity measured by pretraining validation loss."
- Learning-forgetting tradeoff: The balance between achieving low loss on a downstream task (learning) and retaining pretraining performance (forgetting). Example: "SAM dominates AdamW on the learning--\allowbreak forgetting tradeoff (e.g., 80\% less forgetting on StarCoder at matched fine-tuning loss)."
- Maximum eigenvalue: The largest eigenvalue of the Hessian, indicating the sharpest curvature direction and influencing stability and learning-rate constraints. Example: "the maximum eigenvalue of the Hessian "
- Mid-training: An additional training phase applied to a pretrained checkpoint before post-training, often with different optimization settings to adjust geometry. Example: "a short SAM mid-training phase applied to an existing OLMo-2-1B checkpoint reduces forgetting by 31\% after MetaMath post-training and by 40\% after 4-bit quantization."
- Pareto frontier: The set of optimal tradeoff points where improving performance on one metric would worsen another, used here to summarize learning vs. forgetting. Example: "We are interested, primarily, in the Pareto frontier of this set"
- Peak learning rate: The highest value reached by the learning rate within a schedule, which can implicitly regulate sharpness. Example: "We sweep the peak AdamW learning rate under cosine pretraining schedule, then fine-tune on StarCoder."
- Quantization (4-bit): Compressing model weights to low-bit representations (e.g., 4 bits) to reduce memory and compute, often at the cost of accuracy. Example: "Under 4-bit quantization, the SAM mid-trained model loses 40\% less benchmark performance than the OLMo baseline"
- Robust optimization: An optimization framework that seeks solutions resilient to worst-case perturbations within a defined neighborhood. Example: "SAM solves the robust optimization problem:"
- SAM (Sharpness-Aware Minimization): An optimizer that seeks parameters with uniformly low loss in a neighborhood by ascending along the gradient to find adversarial perturbations before descent. Example: "Sharpness-Aware Minimization (SAM) explicitly searches for minima that remain low-loss under parameter perturbations within a specified neighborhood."
- Sharpness: A measure of how rapidly loss increases around a solution (i.e., curvature); flatter minima are associated with lower sensitivity to parameter changes. Example: "Sharpness as a local approximation for forgetting"
- Taylor expansion: A series approximation of the loss around current parameters; the second-order form uses the Hessian to predict loss changes under small perturbations. Example: "a second order Taylor expansion yields:"
- Trace of the Hessian: The sum of Hessian eigenvalues, representing average curvature across directions; sometimes targeted to reduce overall sharpness. Example: "minimize the trace of the Hessian, "
- WSD (warmup-stable-decay) schedule: A learning-rate schedule with an initial warmup, a constant (stable) phase, and a final decay (anneal), shaping late-stage training geometry. Example: "We vary the WSD decay length :"
Collections
Sign up for free to add this paper to one or more collections.

