- The paper introduces a modular pipeline to extract citation-claim pairs and assess link accessibility, topical relevance, and factual consistency.
- Benchmarking 14 LLM models, it reveals a disconnect between high surface citation metrics and significantly varied factual accuracy.
- Findings indicate that deeper retrieval strategies degrade factual support, highlighting the need for citation-efficient approaches in LLM research agents.
Source Attribution Evaluation for LLM Research Agents: A Multi-Dimensional, Claim-Level Audit
Introduction
The proliferation of LLM-powered deep research agents capable of converting heterogeneous web content into structured, citation-rich Markdown reports has catalyzed new possibilities for scalable information synthesis. However, the reliability of citation attribution within this paradigm remains largely unverified. This paper presents a comprehensive and rigorous framework for extracting and evaluating inline source attributions in LLM-generated reports, exposing systematic gaps between surface citation metrics and factual support. Distinct from prior work, the framework combines AST-based parsing for deterministic citation-claim alignment and large-scale, multi-dimensional evaluation—including link accessibility, topical relevance, and factual consistency—benchmarked across leading commercial and open-source LLMs.
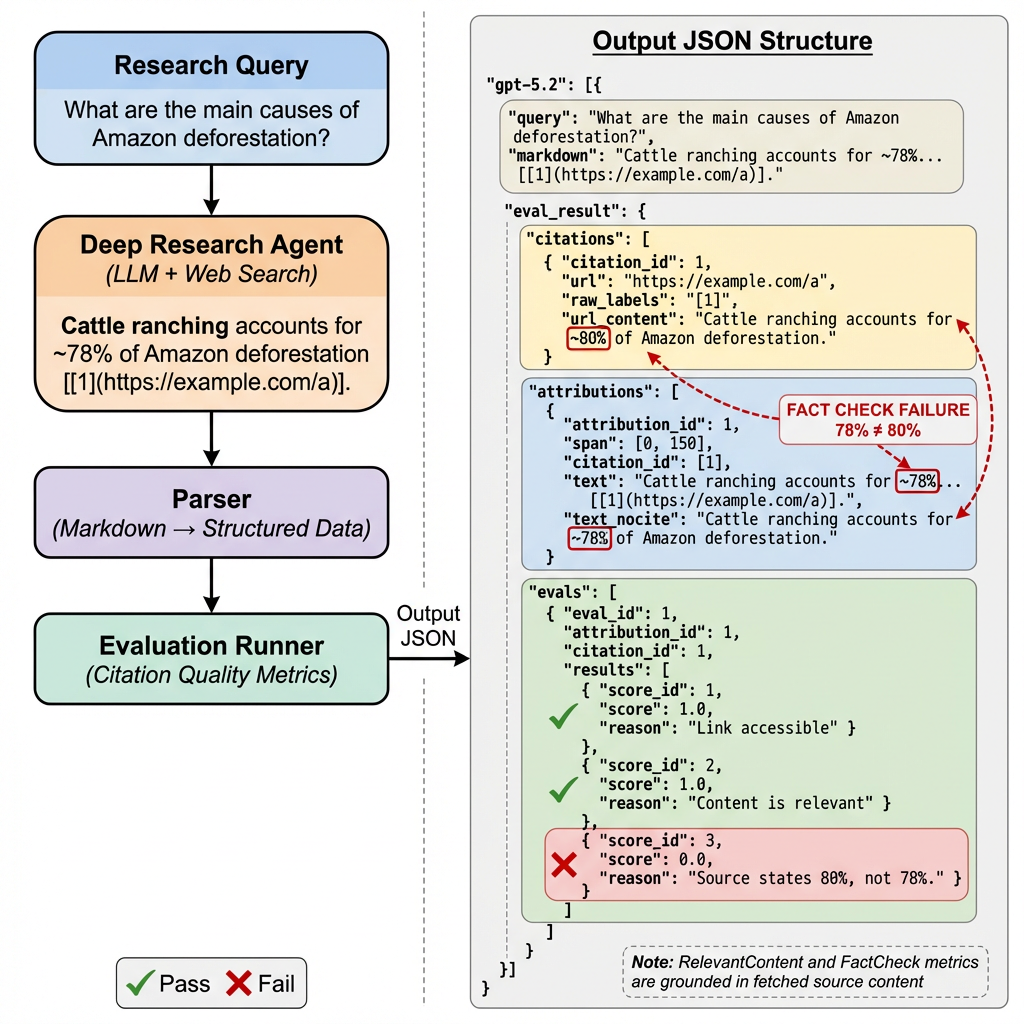
Figure 1: The proposed evaluation framework automatically parses LLM-generated Markdown, pairs citations with claims, and evaluates surface and factual attribution quality.
Evaluation Framework and Methodology
A three-stage modular pipeline is established to enable large-scale citation-level auditing. LLM-generated Markdown is parsed into structured citation-claim pairs by an AST parser, supporting the full spectrum of commonly encountered link notations (numbered, inline, autolink, ranges) and applying backward attribution heuristics for ambiguous references. Each citation’s referenced content is extracted, and three targeted evaluators score each citation-claim pair:
- Link Works: Binary detection of URL accessibility using robust HTTP request and content extraction infrastructure.
- Relevant Content: LLM-as-a-judge scoring of topical alignment, calibrated with human assessment.
- Fact Check: Rigorous LLM-as-a-judge consistency audit between the claim and its cited evidence, with binary pass/fail and justification.
This methodology isolates surface citation metrics from underlying factual support, enabling fine-grained error analysis at scale and providing direct evidence regarding the real-world verifiability of LLM-synthesized research.
Comparative Benchmarking Results
Evaluation of 14 models—including OpenAI GPT-5.2/5.4, Anthropic Claude Opus/Sonnet/Haiku, Gemini 3.1/Flash, and open-source OSS-120B/Llama 4 Maverick/Pixtral Large—across 130 research queries demonstrates:
- High Surface Metric Performance: Frontier models consistently yield URL accessibility above 94% and topical alignment above 80%.
- Divergent Factual Accuracy: Fact Check pass rates are highly variable (24% to 77%), indicating that surface citation metrics do not reliably proxy factual verifiability.
- Provider/Model Differentiation: Anthropic Claude Opus 4.5 leads in factual consistency (76.8%), while OpenAI models generate more citations but with lower accuracy, and open-source models exhibit low task success rates and limited output.
These findings signal that the surface credibility of LLM-generated citations often masks significant underlying factual failures; consumers may encounter working, contextually relevant links that ultimately do not support the explicit factual claims made.
Ablation studies varying tool call budgets per query systematically demonstrate that increased retrieval depth precipitates a monotonic decline in Fact Check accuracy, with an average 42% drop from minimal to maximal search depth. While link accessibility and topical relevance remain stable, factual support degrades precipitously.
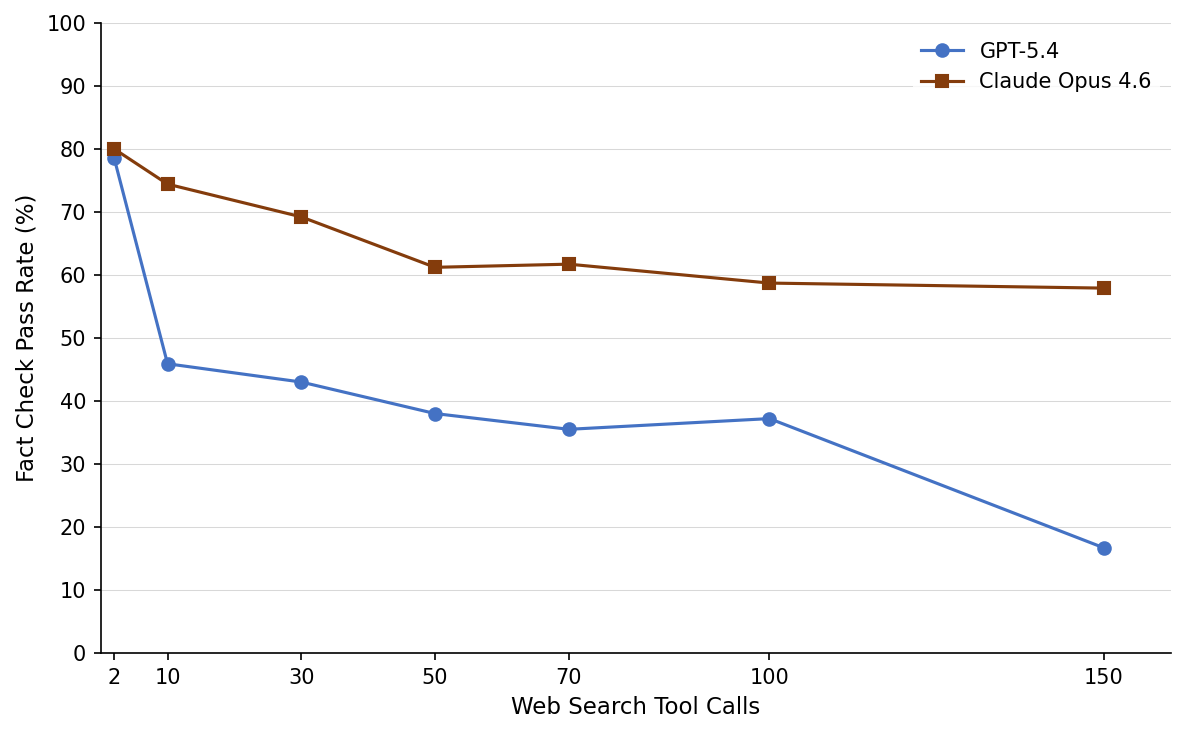
Figure 2: Factual accuracy declines sharply with increased search depth, while link reliability and relevance remain high, confirming an information overload effect.
The effect is model-dependent (e.g., GPT-5.4: 79%→17%; Claude Opus 4.6: 80%→58%), but robust across architectures. This strongly implicates an information overload phenomenon: increased source aggregation complexity outstrips LLMs’ ability to rigorously verify and synthesize accurate claims.
Error Analysis
Link Works failures are predominantly due to HTTP status errors (404, 403), paywall or bot-blocked domains, with rate limits a minor secondary effect. Factual failures result from over-aggregation, hallucinated detail, and misattribution across source documents, accentuated by higher retrieval budgets. Notably, open-source models fail primarily at the generation stage, unable to reliably produce cited Markdown in end-to-end settings.
Theoretical and Practical Implications
These results have important implications for LLM-based research agents and the next phase of agentic citation infrastructure:
- Surface metric reliability is decoupled from factual accuracy: Monitoring only superficial citation quality systematically overestimates user trust in research reports.
- Exhaustive retrieval strategies degrade factual reliability: Systems must trade off breadth against depth, with selective, citation-efficient strategies preferable for accuracy-sensitive workflows.
- Evaluation infrastructure must operate at the claim-citation pair level: Document- or passage-level assessments are insufficient for auditing real-world research outputs.
- LLM-as-a-judge evaluation requires ongoing calibration: Potential biases and overestimation of correctness necessitate hybrid or ensemble judging strategies for robust deployment.
Expansion to temporally persistent citations (to handle citation rot) and closed knowledge domains (e.g., enterprise RAG) remains an open challenge, along with integrating such auditing directly into agent pipelines for proactive error reduction.
Future Directions
Future systems should incorporate active attribution monitoring, joint retriever-synthesizer optimization for factual density, and domain-adaptive evaluation for regulated environments. Investigating mechanisms to summarize or filter sources before factual synthesis, and extending longitudinal studies for citation durability, are high-priority.
Conclusion
A reproducible, multi-dimensional auditing pipeline reveals a systematic disconnect between the surface quality and factual verifiability of LLM research agent citations. While commercial models excel in citation accessibility and topical targeting, factual accuracy remains a pronounced weakness, especially as retrieval depth increases. These outcomes demand renewed focus on factual synthesis and evaluation rigor, as LLM-based research systems are increasingly deployed in critical information environments.