- The paper introduces Token Superposition Training (TST) to reduce pre-training time by up to 2.5x without altering the model architecture.
- TST employs a two-phase approach using input superposition and multi-hot cross-entropy for output prediction to boost tokens-per-FLOP.
- Experimental results across scales show robust improvements in loss and downstream task performance while preserving inference behavior.
Efficient Pre-Training of LLMs via Token Superposition Training
Introduction and Motivation
Efficient scaling of LLMs is critically bottlenecked by data throughput and compute efficiency during pre-training, especially as state-of-the-art models increasingly leverage overtraining far beyond compute-optimal regimes to maximize inference-time performance. Existing methods to improve efficiency modulate input representations (tokenization advances, auxiliary losses), decrease per-token compute (sparse MoEs, attention), or compress intermediate representations (compressive architectures). However, none decouple training-time efficiency from architectural and inference changes without adding system or model complexity.
This paper introduces Token Superposition Training (TST), a self-contained training paradigm that achieves up to a 2.5x reduction in pre-training time at 10B parameter scale, strictly via increased data throughput per FLOP, making no changes to optimizer, parallelism, tokenizer, data pipeline, or model architecture (2605.06546). TST applies in two phases: (i) a "superposition" regime where s contiguous tokens are embedded and predicted jointly as bags via a multi-hot cross-entropy (MCE) objective, and (ii) a recovery phase reverting to canonical autoregressive (AR) training, feeding forward the initialization from TST. Crucially, inference-time behavior and architecture are unaffected.
Method: Token Superposition Training
TST comprises two orthogonal mechanisms:
Input Superposition: During phase (i), token sequences are folded into non-overlapping bags of size s. These bags are superposed by averaging their embeddings prior to model input, reducing effective sequence length to L/s per training example, but increasing raw data consumption and thus tokens-per-FLOP by sx.
Output Superposition: Rather than predicting a single next token, the model predicts the next bag of s tokens (the next s contiguous tokens, unordered) using a multi-hot cross-entropy (MCE) loss. The target distribution is uniform over the correct bag. This modifies training to encourage latent representations informative of multiple continuation possibilities.
After r fraction of training steps with TST, the model resumes exactly standard AR next-token prediction, leveraging the updated weights—with no architectural, optimizer, or data changes.
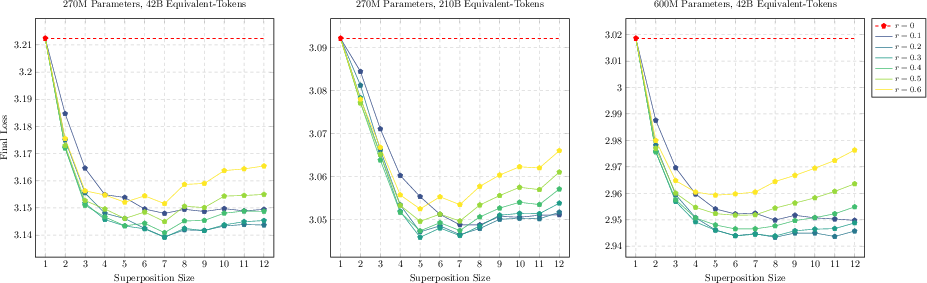
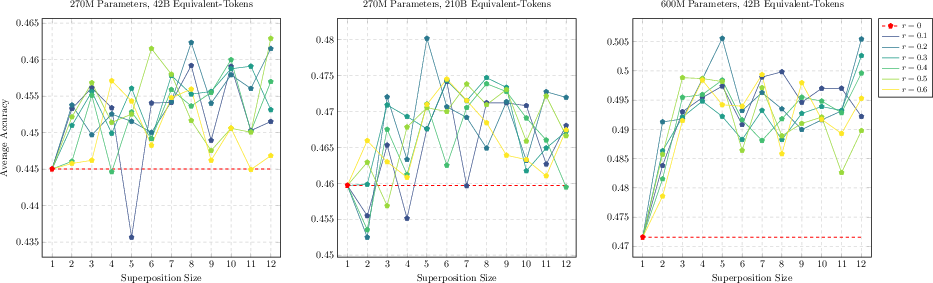
Figure 2: Superposition results with respect to loss at varying bag sizes and superposition step ratios, showing strong improvement as TST is applied.
Experimental Results
Extensive experiments are reported at 270M, 600M, 3B, and 10B (MoE) scales, including the Qwen3-derived A1B MoE architecture:
(TST is found robust to bag hyperparameter; performance degrades only for excessive s1 or s2.)
Analysis and Ablations
Ablation experiments demonstrate that both input and output superposition independently improve over standard AR training, but their combination realizes synergistic gains. Input superposition alone can be interpreted as coarse-to-fine curriculum, echoing recent findings from ViT patch resizing and subword-to-byte training schedules.
Loss Weighting
The MCE loss can be weighted across tokens in the output bag. Empirically, uniform weighting is optimal for s3; at larger s4, a power-law weighting (reflecting the long-range decay of token mutual information) gives slight improvements.
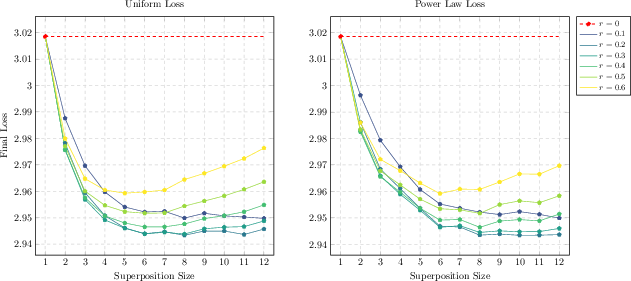
Figure 6: Comparison between uniform and power-law output loss weighting at various superposition settings; power-law improves stability for large s5.
Phase Alignment
If the embedding and output layers are not aligned across the two TST phases (e.g., via random re-initialization before recovery), all gains are lost, highlighting the criticality of representation alignment when transferring from superposition regime to AR—explaining why previous compressive methods required explicit adapters.
Comparison to Prior Art
TST differs fundamentally from Multi-Token Prediction (MTP) or future summary prediction [gloeckle_better_2024; mahajan_beyond_2025]: these add auxiliary loss terms or heads, but do not increase tokens-per-FLOP nor yield robust improvements without extra parameters or tuning. TST is orthogonal, as it directly increases data efficiency per compute.
Unlike compressive or byte-level architectures [minixhofer_bolmo_2025; pagnoni_byte_2025], TST does not modify autoregressive inference at all, evading post-training adaptation or complexity.
Limitations and Future Work
TST is most advantageous in the compute-bound regime; if data is scarce, its increased data appetite may be a liability. Output-only superposition, however, provides moderate improvements without increased data consumption, and future work should combine TST with auxiliary losses or alternate tokenization (e.g., byte-level or concept-level). The mechanistic basis (curricular vs. geometric regularization) for TST’s effect remains open; interpretability and scaling law analyses are warranted.
Theoretical and Practical Implications
TST demonstrates that token-level input/output granularity and training curriculum can be decoupled from inference architecture, increasing training efficiency without architectural reforms. This supports the hypothesis that much of subword tokenization’s advantage is via induced training throughput, rather than subword priors per se [gigant_decoupling_2026]. Compressing training inputs or outputs—without increasing inference cost or sacrificing expressivity—constitutes a reusable, domain-agnostic optimization applicable to LLMs and potentially other sequence models.
Conclusion
Token Superposition Training provides a robust, easily-integrable framework for accelerating LLM pre-training by maximizing sample throughput under fixed compute. It yields consistently lower loss and improved evaluation scores with no inference cost or system complexity, and outpaces alternative methods that require auxiliary architectural changes. The framework opens new directions for hybrid curricula, multi-granularity LMs, and principled data-compute co-optimization. The alignment of representation space across learning phases emerges as the critical element for successful compressive curriculum, resolving limitations of prior approaches.
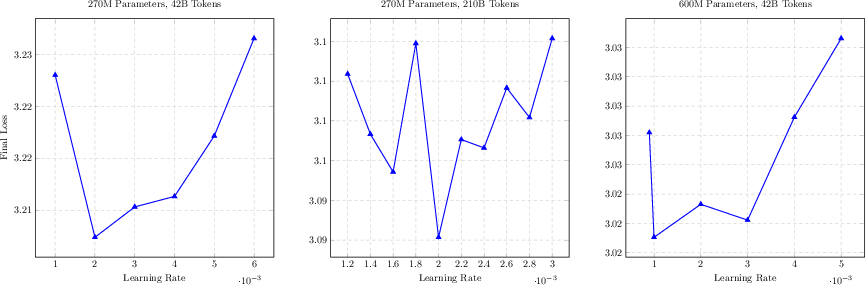
Figure 1: Learning rate sweeps validate optimal hyperparameters for all model sizes; TST performance is robust given correct scheduling.
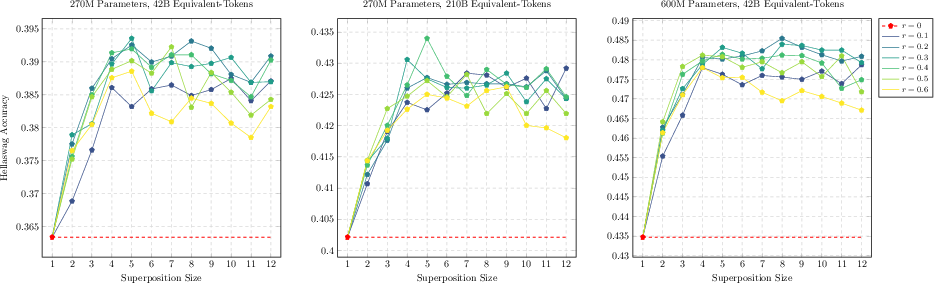
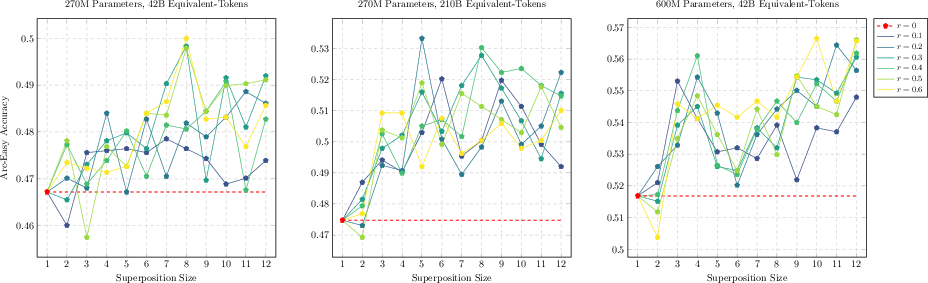
Figure 3: Downstream evals (HellaSwag, ARC-Easy) across TST settings confirm systematic, stable improvement compared to baseline AR models.
Reference:
Efficient Pre-Training with Token Superposition (2605.06546)