Layer-adaptive Expert Pruning for Pre-Training of Mixture-of-Experts Large Language Models
Abstract: Although Mixture-of-Experts (MoE) LLMs deliver superior accuracy with a reduced number of active parameters, their pre-training represents a significant computationally bottleneck due to underutilized experts and limited training efficiency. This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. In particular, when pre-training the 1010B Base model from scratch, LAEP achieves a 48.3\% improvement in training efficiency alongside a 33.3% parameter reduction, while still delivering excellent performance across multiple domains.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making a special kind of LLM—called a Mixture-of-Experts (MoE) model—train faster and use less memory, without hurting how well it works. The authors introduce a method called Layer-Adaptive Expert Pruning (LAEP) that removes “experts” that aren’t being used much during training and rearranges the remaining ones to balance the work across computers.
Think of an MoE model like a school with many tutors (experts). For each question (token), only a couple of tutors help, not all of them. This saves time—but during training, some tutors get swamped while others sit idle. LAEP helps stop wasting time on idle tutors and spreads the work fairly across classrooms (computers).
What questions did the researchers ask?
They focused on three simple questions:
- During training, how does the model decide which experts get used a lot and which barely get used?
- Can we safely remove rarely used experts during training (not just after), so the model is smaller and faster, but still accurate?
- After removing some experts, can we shuffle the remaining experts across computers so each computer gets a fair workload and runs faster?
How did they do it?
They studied how tokens (the pieces of text the model reads, like words or parts of words) flow to different experts while training from scratch. They found two phases:
- Early “transition” phase: usage is chaotic because everything is randomly initialized—some experts get lots of tokens, others get almost none.
- Later “stable” phase: usage settles down; some experts consistently get many tokens, and others consistently get very few.
LAEP kicks in only after things become stable, so decisions are reliable.
Here’s what LAEP does:
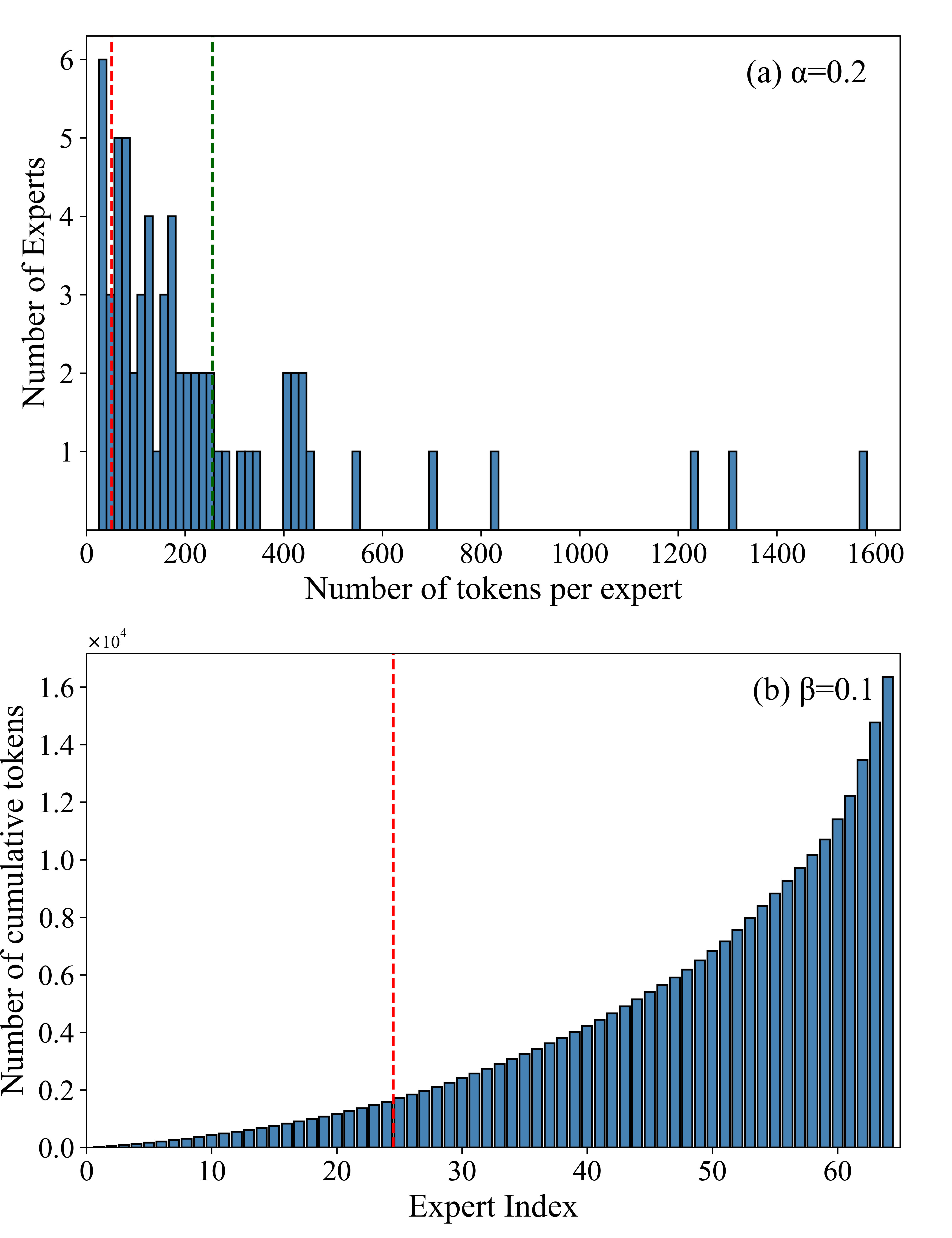
- Prune underused experts, layer by layer: In each layer of the model, it looks at how many tokens each expert actually handled. It has two “dials” to decide what to prune:
- α (alpha): a per-expert rule. If an expert is far below the average usage, it’s a candidate to be removed.
- β (beta): a cumulative rule. If the group of least-used experts together handles only a small fraction of tokens, those experts are pruned.
- This is like deciding to phase out tutors who rarely get any students.
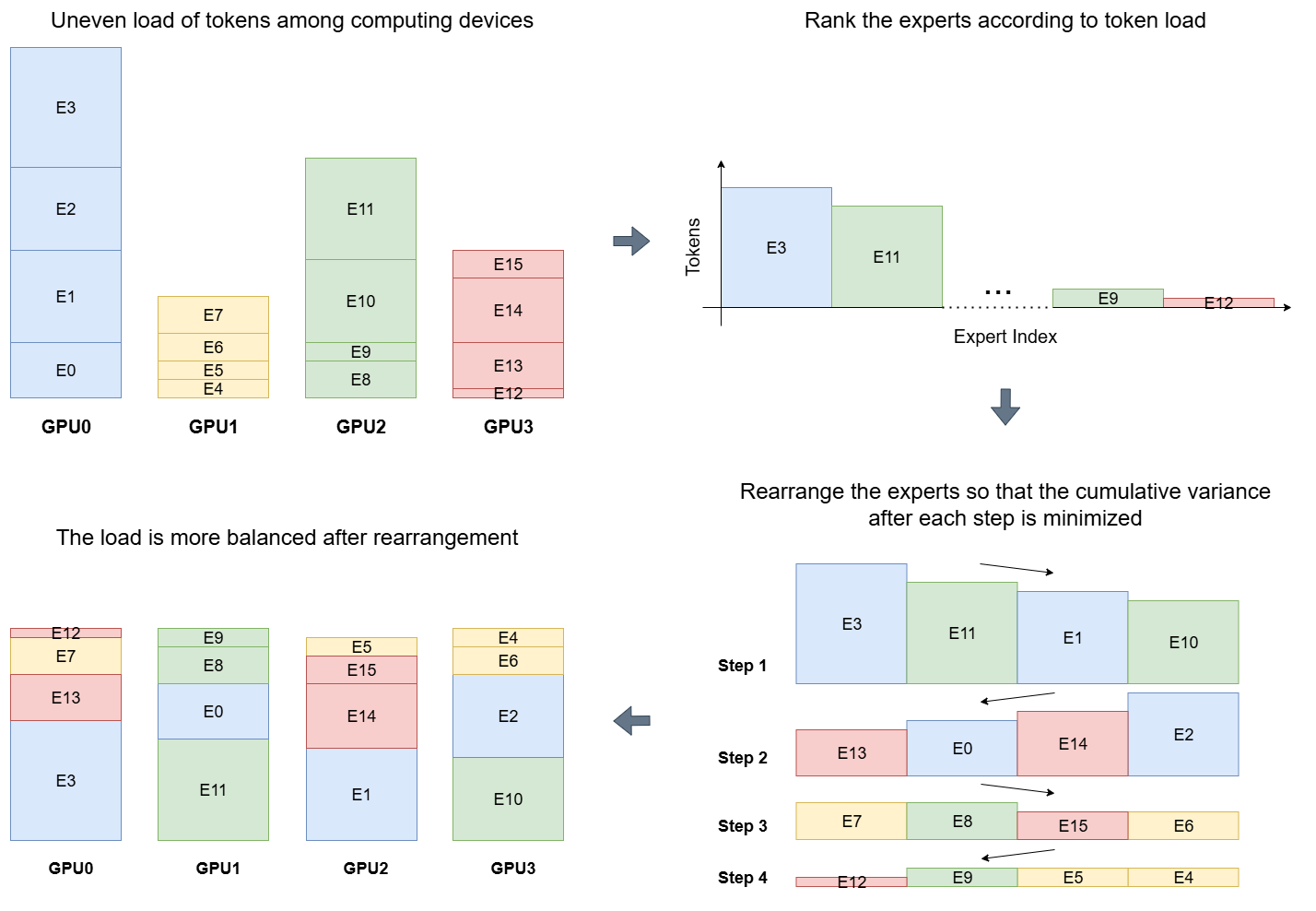
- Rearrange experts across devices: MoE experts live on different computers (GPUs). If a few heavy-traffic experts end up on the same computer, that machine slows everyone down. So they rank experts by how busy they are and then redistribute them so each computer gets a balanced mix. This is like making sure every classroom has a fair mix of busy and quiet tutors so no room is overloaded.
They tested LAEP in multiple sizes:
- A small 10B-parameter model to study usage patterns.
- A mid-size 20B model for detailed experiments on pruning settings.
- A massive 1,515B-parameter model where they applied LAEP in real pre-training and reduced it to 1,010B.
Technical terms in everyday language:
- Token: a small chunk of text (like a word or part of a word).
- Expert: a specialized mini-network inside the MoE that handles certain kinds of tokens.
- Router/Gate: a decision-maker that chooses which experts should handle each token.
- Pre-training: the big first training stage on huge amounts of text so the model learns general language skills.
- FLOPs/TFLOPs: measures of how much computation is being done; higher TFLOPs per GPU means the hardware is being used more efficiently.
What did they find?
Key results show that pruning during pre-training and balancing the load works well:
- Faster training and smaller models:
- On their giant model, LAEP cut total parameters from 1,515B to 1,010B (about 33.3% smaller).
- Training efficiency jumped by 48.3% (from about 62 to 92.6 TFLOPs per GPU).
- Rearranging experts across devices alone added a big boost on top of pruning.
- Accuracy stayed strong or improved:
- On smaller and mid-size models, modest pruning actually lowered test loss (a good thing), meaning the model learned better.
- On the huge model, performance across math, code, and language tasks was comparable to leading systems like DeepSeek-V3 Base and LLaMA-3.1-405B on many benchmarks, and best-in-class on some math and coding tasks.
- Better than common “load-balancing losses”:
- Some MoE systems add an extra training rule (an “auxiliary loss”) to force experts to be used more evenly. The authors found these rules are tricky: making usage too balanced can hurt accuracy. LAEP avoids that trade-off by pruning and rearranging based on real usage statistics, not by forcing balance with a penalty.
Why does this matter?
- Lower costs and faster training: Cutting unnecessary experts and balancing work across computers means you can train big models faster and cheaper.
- Smaller memory footprint: Fewer total parameters mean less memory needed for training and for running the model later, making deployment easier.
- Greener AI: More efficient training uses less energy.
- Better design for MoE models: LAEP shows that pruning during pre-training (not just after) can make MoE models both leaner and better, which helps future big models scale more smoothly.
In short, this research shows a practical way to speed up and slim down very large MoE LLMs—by trimming the experts that don’t pull their weight and smartly spreading the rest across machines—while keeping or even improving how well the models perform.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues, uncertainties, and missing analyses that, if addressed, would strengthen the paper and guide future research.
- Stable-phase detection is not formally defined: specify quantitative criteria, thresholds, and algorithms to detect the transition from the volatile phase to the stable phase across model sizes and datasets.
- Pruning schedule design is unclear: determine whether pruning is one-shot or multi-stage, how often pruning occurs, and how schedules impact convergence, stability, and final performance.
- Risk to long-tail specialization is not assessed: evaluate whether low-load experts encode rare languages, domains, or niche skills; quantify the impact of pruning on minority-language and domain-specific benchmarks.
- Router behavior after pruning is under-specified: detail how gating networks are updated, reinitialized, or constrained post-pruning; measure routing entropy, collapse risks, and load re-distribution dynamics.
- Formal correctness of pruning conditions needs clarification: fix notational ambiguities in Equations for and (e.g., indices and the definition of ), and provide the exact implementation corresponding to the math.
- Overhead and scalability of token-load measurement are not quantified: report the compute, memory, and communication costs of collecting per-expert token statistics at scale and their impact on training throughput.
- Expert rearrangement algorithm lacks optimality guarantees: analyze convergence and optimality versus known load-balancing strategies (e.g., bin packing, min-cost flow), and quantify sensitivity to device heterogeneity.
- Rearrangement frequency and adaptivity are unspecified: study how often to rearrange experts, whether loads drift over time, and the trade-offs between rearrangement benefits and its operational overhead.
- Accuracy impact of rearrangement is not measured: beyond TFLOPS, report test loss and downstream task performance before/after rearrangement to rule out adverse effects on learning.
- Large-scale baselines are incomplete: compare LAEP against tuned auxiliary-loss methods (e.g., coefficients around 1e-4–1e-3) and auxiliary-loss-free strategies at the 1T-token, 1T-parameter scale.
- Theoretical understanding is missing: develop analyses explaining when and why pruning improves test loss, the relationship between load imbalance, effective capacity, and generalization, and conditions under which pruning harms performance.
- No exploration of reversible or elastic expert capacity: investigate re-growing pruned experts, dynamic capacity allocation, or conditional reintroduction when loads or tasks change later in training or fine-tuning.
- Sensitivity to the number of activated experts () is unexplored: evaluate LAEP across top-1, top-2, top-4 gating, different temperatures/noise levels, and assess the interaction with pruning.
- Layer-wise pruning policy is heuristic: move beyond the 1/6–2/3–1/6 hybrid to data-driven or learned per-layer schedules; correlate layer token-entropy or specialization with optimal pruning aggressiveness.
- Robustness across random seeds and datasets is not reported: quantify variance in expert load ranking stability and model outcomes across seeds, data compositions, and multilingual corpora.
- Inference implications are unmeasured: evaluate memory footprint, latency, throughput, and all-to-all communication during inference after pruning and rearrangement, including batch size and sequence length effects.
- Optimizer state handling is unspecified: describe how optimizer moments for pruned experts are disposed of, whether this induces momentum shocks or instability, and any mitigations (e.g., warm restarts).
- Fairness and bias risks are unassessed: analyze whether pruning disproportionately harms underrepresented languages or topics and include fairness metrics to detect systematic degradations.
- Failure-case analysis is missing: investigate tasks where the 1010B model underperforms (e.g., MMLU, ARC) to identify whether pruning or rearrangement contributes and propose mitigation strategies.
- Practical guidance for hyperparameter selection is limited: provide robust procedures to choose , target pruning fractions, and detection thresholds under different scales and data regimes.
- Benchmark coverage is narrow: broaden evaluation across multilingual, commonsense, reasoning, long-context, safety, and generation tasks to detect regressions not captured by the current suite.
- Hardware generality is uncertain: validate LAEP on diverse hardware (e.g., different GPUs, TPUs, interconnects), and assess sensitivity to network topology, bandwidth, and heterogeneous device performance.
- Reproducibility is constrained: release code, complete appendices (model architecture, router design, data details), training curves, seeds, tokenizers, and full hyperparameter settings to enable independent verification.
- Interaction with other parallelisms is not studied: quantify how LAEP affects data/tensor/pipeline parallel schemes, memory fragmentation, and collective communication efficiency (e.g., NCCL all-to-all).
- Communication load changes are not measured: report all-to-all bytes, network utilization, straggler effects, and end-to-end pipeline efficiency before/after LAEP to attribute TFLOPS gains to specific bottleneck reductions.
- Long-term load dynamics are uncertain: test whether expert load rankings remain stable across trillion-token training and monitor for drift that could necessitate dynamic re-pruning or rebalancing.
- Generalization to other MoE variants is untested: evaluate LAEP with hierarchical experts, different capacity factors, shared experts, router architectures (MLP vs. attention), and alternative dispatch mechanisms.
- Representational diversity and forgetting risks are unquantified: measure diversity (e.g., mutual information or subspace overlap across experts) and assess whether pruning induces catastrophic forgetting for subsets of skills.
- Combining LAEP with auxiliary losses is unexplored: systematically study hybrid schedules (aux-loss + LAEP), including staged or cyclical application, to test for additive or synergistic benefits.
- Alternative pruning criteria are not compared: evaluate expert importance via gradient norms, Fisher information, gate probabilities over time, activation magnitudes, or contribution to loss, and benchmark against token-load heuristics.
- Imbalance metrics and assignment objectives lack formalization: define load variance measures per layer/device, formulate device assignment as an optimization problem, and compare greedy rearrangement to optimized solutions.
Practical Applications
Below is a structured synthesis of practical applications that follow from the paper’s findings and methods, organized by deployment horizon and linked to relevant sectors. Each item includes specific use cases, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
These are deployable now with standard MoE training frameworks and common GPU clusters.
- Industry (Software/AI): Integrate LAEP into MoE pre‑training pipelines
- Use case: Add LAEP’s layer‑adaptive pruning and expert rearrangement to DeepSpeed‑MoE, Megatron‑LM, or ColossalAI training runs to cut GPU hours, memory, and time‑to‑model (observed ~33% parameter reduction and up to ~48% training efficiency gains).
- Tools/workflows: A LAEP library/plugin with α/β pruning controls, stable‑phase detection, router token‑load logging, automatic expert re‑sharding.
- Assumptions/dependencies: MoE architecture with expert parallelism; instrumentation of per‑expert token counts; capability to modify model topology mid‑training and re‑load checkpoints.
- Cloud/Infrastructure/Energy: Cluster‑level expert load rebalancing
- Use case: Deploy LAEP’s expert rearrangement algorithm to rebalance device‑level loads and eliminate stragglers, improving TFLOPS/GPU even without pruning (paper shows ~10–16% throughput boost from rearrangement alone).
- Tools/workflows: Scheduler/orchestrator plugin that ranks experts by token load and greedily redistributes them across devices to minimize variance.
- Assumptions/dependencies: Support for moving experts across devices; sufficient interconnect bandwidth (e.g., NVLink/InfiniBand) and checkpoint/reshard tooling.
- Model Serving (Inference/Hosting): Lower memory footprint for MoE bases trained with LAEP
- Use case: Host pruned MoE base models that require less RAM and have fewer experts per layer, reducing serving cost and enabling denser model packing per node.
- Tools/workflows: Inference runtimes that accept pruned expert layouts and routing tables; capacity planning using reduced parameter counts.
- Assumptions/dependencies: The model must be pre‑trained with LAEP; inference stack must support the pruned expert configuration; task coverage remains adequate.
- Academia/Education: Medium‑scale MoE training on modest budgets
- Use case: University labs replicate 10–20B total parameter MoE pre‑training with LAEP to improve test loss and throughput without relying on finely tuned auxiliary losses.
- Tools/workflows: Open‑source recipes for α/β schedules, stability detection, and pruning intervals; logging dashboards for expert loads.
- Assumptions/dependencies: Availability of MoE framework; sufficient data; correct α/β tuning (e.g., β≈0.1 and α≤0.4 per reported results).
- Sector‑specific Model Development (Healthcare, Finance, Legal, Robotics, Software): Budget‑aware domain MoE training
- Use case: Train domain‑specialized MoE models and prune under‑utilized experts once token loads stabilize, lowering compute requirements and accelerating iteration.
- Tools/workflows: Domain corpora ingestion + LAEP trigger after initial iterations; periodic re‑prune/rearrange checkpoints.
- Assumptions/dependencies: Early detection of stable phase; domain datasets with consistent token routing behavior.
- MLOps/DevOps: Expert‑load monitoring and automated pruning triggers
- Use case: Add real‑time per‑expert token‑load dashboards, alarms for imbalance, and automated LAEP actions when stable phase is detected.
- Tools/workflows: Telemetry from router; metrics such as Max/Min token ratio per layer; auto‑execute pruning and rearrangement scripts.
- Assumptions/dependencies: Reliable router stats; clear stability heuristics; change‑management procedures for mid‑training topology edits.
- Finance/Policy (Green AI in organizations): Compute and carbon reduction practices
- Use case: Adopt LAEP in internal sustainability playbooks to meet energy and budget targets for foundation model training.
- Tools/workflows: Cost/carbon calculators updated with expected LAEP gains (e.g., ~30–50% training efficiency improvement).
- Assumptions/dependencies: Training teams willing to modify pipelines; transparent reporting of pre/post LAEP energy use.
- Open‑source Tools: LAEP reference implementation and training recipes
- Use case: Release a minimal, framework‑agnostic implementation of α/β‑based pruning and greedy expert rearrangement with loggers and unit tests.
- Tools/workflows: Python package, config templates, reproducible example scripts for 10B/20B MoE runs.
- Assumptions/dependencies: Community maintenance; compatibility with major MoE stacks.
Long‑Term Applications
These require further research, broader ecosystem support, or hardware/runtime co‑design.
- Hardware/Systems Co‑Design (Robotics, Cloud, Energy): MoE‑aware accelerators and runtime
- Use case: Create interconnects and memory managers optimized for dynamic expert relocation and sparse activation patterns, minimizing cross‑device imbalance.
- Tools/workflows: MoE‑aware topology planners; hardware scheduling firmware that supports on‑the‑fly expert migration.
- Assumptions/dependencies: Vendor adoption; validation at trillion‑token scales; robust failure‑handling when hot‑moving experts.
- AI Frameworks (Software): Fully automated LAEP with adaptive α/β, periodic pruning, and potential re‑growth
- Use case: AutoML‑style controllers adjust pruning strength per layer over time; combine with router training for joint optimization.
- Tools/workflows: Policy engines (e.g., bandits/RL) for α/β tuning; safety guards to avoid over‑pruning; rollback strategies.
- Assumptions/dependencies: Convergence guarantees; generalization across datasets and modalities; robust checkpoint surgery.
- Standards/Policy (Sustainability, Procurement): Efficiency benchmarks and reporting norms
- Use case: Establish efficiency standards for foundation model pre‑training that credit pruning‑based methods; include LAEP‑style metrics in RFPs and compliance.
- Tools/workflows: Standardized reporting of TFLOPS/GPU, Max/Min expert load ratio, energy per token.
- Assumptions/dependencies: Industry consensus; third‑party audits; alignment with regulatory bodies.
- Multimodal Expansion (Healthcare imaging, EdTech, VLMs): LAEP for vision‑language and other sparse expert architectures
- Use case: Apply layer‑adaptive pruning across multimodal routers (text, vision, audio) to reduce training costs while maintaining accuracy.
- Tools/workflows: Modality‑specific stability detectors; cross‑modal load balancing; expert co‑location strategies.
- Assumptions/dependencies: Existence of stable load phases in multimodal routers; careful handling of cross‑modal dependencies.
- Edge/On‑Device AI (Mobile, IoT, Robotics): Train MoEs that can be pruned to fit edge servers or high‑end devices
- Use case: Use LAEP during pre‑training to produce compact sparse models, then distill to edge deployments with better performance than purely dense baselines.
- Tools/workflows: LAEP + distillation pipelines; lightweight inference runtimes for sparse experts.
- Assumptions/dependencies: On‑device support for MoE or distilled dense targets; validation of latency and energy trade‑offs.
- Privacy/Security (Federated/Distributed Training): Device‑aware expert placement across sites
- Use case: Federated MoE pre‑training where experts are allocated to data‑local devices and rearranged to reduce imbalance without exposing raw data.
- Tools/workflows: Secure routing telemetry; privacy‑preserving rearrangement protocols; differential privacy where needed.
- Assumptions/dependencies: Reliable cross‑site synchronization; privacy guarantees; network constraints.
- Data/Training Diagnostics (Academia/Industry): Use token‑load statistics to detect dataset issues and degenerate experts
- Use case: Identify “persistently underutilized” experts as signals of data imbalance, gating pathologies, or curriculum problems; guide data curation and router redesign.
- Tools/workflows: Analytical dashboards; correlation analysis between expert loads and data sources; experiment management.
- Assumptions/dependencies: Interpretable expert assignments; trust in load metrics; careful causal analysis before corrective action.
- Managed Services (Cloud/Platforms): End‑to‑end LAEP training offerings
- Use case: Cloud providers offer managed MoE pre‑training with built‑in pruning/rearrangement, SLAs around throughput and cost per token.
- Tools/workflows: Turnkey templates, autoscaling, observability integrations; cost/energy dashboards.
- Assumptions/dependencies: Market demand; seamless integration with customer code and datasets; support for diverse router/attention variants.
In all cases, feasibility hinges on accurate detection of the stable phase of expert loads, reliable per‑expert token statistics, and infrastructure that supports safe model topology changes mid‑training. Appropriate hyperparameter tuning (e.g., β≈0.1 and α≤0.4 in reported experiments) and careful validation on target datasets/tasks are critical to preserve accuracy while realizing efficiency gains.
Glossary
- Auxiliary load-balancing loss: An extra training objective used to encourage even utilization of experts in MoE models. Example: "Prior work primarily relies on auxiliary load-balancing losses, notably introduced in the Switch Transformer ... to regulate expert utilization through gating probabilities."
- BF16: A 16-bit floating-point format (bfloat16) commonly used to speed up training while maintaining numerical stability. Example: "The tests are conducted on 824 AI chips, while the numerical precision during the training process is set to BF16."
- Cumulative load constraint: A pruning threshold that limits the total token load contributed by the least-used experts up to a specified fraction (β). Example: "α is the individual load constraint, and β is the cumulative load constraint."
- Device-level load imbalance: Uneven computational workload across devices due to uneven expert token loads, hurting throughput. Example: "To mitigate this device-level load imbalance, we propose an expert rearranging algorithm..."
- Expert parallelism: A distributed training strategy that places different experts on different devices to scale MoE models. Example: "MoE LLMs typically employ expert parallelism by distributing experts across distinct computing devices."
- Expert pruning: Removing experts that contribute little during training to reduce model size and improve efficiency. Example: "Expert pruning is a technique that structured pruning the model by identifying and removing experts that have minimal impact on performance during training..."
- Expert Rearrangement: An algorithm that reassigns experts across devices to balance load after pruning. Example: "Illustration of the Expert Rearrangement algorithm for load balancing among computing devices in MoE LLM pre-training."
- Gating probabilities: Probabilities produced by a router/gating mechanism to decide which experts process each token. Example: "to regulate expert utilization through gating probabilities."
- Layer-Adaptive Expert Pruning (LAEP): The paper’s method that prunes experts per layer based on stable token-load statistics to boost pre-training efficiency. Example: "This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs."
- Localized Filtering-based Attention (LFA): An attention variant that enhances local dependencies using successive 1D convolutions. Example: "we incorporate Localized Filtering-based Attention (LFA) to enhance local-dependency on self-attention through two successive one-dimensional convolutions"
- Mixture-of-Experts (MoE): A model architecture that routes tokens to a subset of specialized sub-networks (experts) to increase capacity with limited active computation. Example: "Although Mixture-of-Experts (MoE) LLMs deliver superior accuracy with a reduced number of active parameters..."
- One-shot pruning: Pruning performed in a single step (often with minimal/no retraining) using criteria like weights or activations. Example: "one-shot pruning criteria based on weights or router-weighted activations with minimal or no retraining"
- Perplexity: A metric for LLM quality; lower values indicate better predictive performance. Example: "often degrading perplexity and overall performance when overemphasized."
- Router-weighted activations: Activation signals weighted by the router/gating mechanism, used as pruning signals. Example: "one-shot pruning criteria based on weights or router-weighted activations with minimal or no retraining"
- Sequence-wise auxiliary loss: An auxiliary loss applied at the sequence level to encourage balanced expert usage. Example: "models integrated with sequence-wise auxiliary loss from Deepseek-V3"
- Sparse MoE: An MoE model where only a small subset of experts is active per token, reducing computation relative to total parameters. Example: "we apply LAEP to pre-train a 1515B-parameter sparse MoE model"
- Structured pruning: Removing structured components (e.g., entire experts) rather than individual weights to achieve efficient compression. Example: "Representative methods include structured or heuristic pruning strategies"
- Super experts: Highly influential experts whose preservation determines compression limits. Example: "a small number of “super experts” whose preservation defines the effective limit of expert-level compression"
- TFLOPS: Trillions of floating-point operations per second; a throughput metric for hardware/model training speed. Example: "Overall computational performance increases from 62.14 TFlops per GPU to 92.6 TFlops per GPU"
- Underutilized experts: Experts that receive persistently few tokens and contribute little to training, making them candidates for pruning. Example: "Once expert loads enter the stable phase of pre-training, LAEP selectively prunes underutilized experts and rearranges the remaining experts to alleviate load imbalance across computing devices."
Collections
Sign up for free to add this paper to one or more collections.

