MiA-Signature: Approximating Global Activation for Long-Context Understanding
Abstract: A growing body of work in cognitive science suggests that reportable conscious access is associated with \emph{global ignition} over distributed memory systems, while such activation is only partially accessible as individuals cannot directly access or enumerate all activated contents. This tension suggests a plausible mechanism that cognition may rely on a compact representation that approximates the global influence of activation on downstream processing. Inspired by this idea, we introduce the concept of \textbf{Mindscape Activation Signature (MiA-Signature)}, a compressed representation of the global activation pattern induced by a query. In LLM systems, this is instantiated via submodular-based selection of high-level concepts that cover the activated context space, optionally refined through lightweight iterative updates using working memory. The resulting MiA-Signature serves as a conditioning signal that approximates the effect of the full activation state while remaining computationally tractable. Integrating MiA-Signatures into both RAG and agentic systems yields consistent performance gains across multiple long-context understanding tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI LLMs to handle very long information (like whole books or long collections of notes). The main idea is to make a tiny “signature” that captures the big picture of what’s relevant, instead of trying to read or retrieve lots of small pieces one by one. The authors call this tiny, big‑picture summary a MiA‑Signature (Mindscape Activation Signature).
They take inspiration from how the human brain works: when we notice or think about something, many parts of our memory “light up” at once, but we can only report a small part of it. The paper tries to give AI a similar shortcut—a compact signal that stands in for that large, hard‑to‑list “lighting up.”
What questions are the authors asking?
- Can we model memory access in two steps—first “light up” everything relevant globally, then make a short, useful representation of that global activation?
- Can a small, carefully chosen set of high‑level concepts help a model search, retrieve, and reason better over very long texts?
- Does this approach improve both classic retrieval‑augmented generation (RAG) systems and more advanced “agent” systems that reason step by step?
How does their method work?
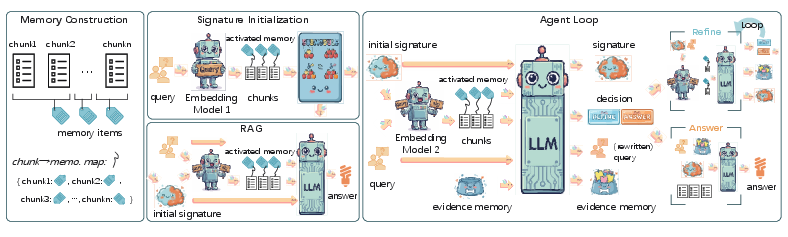
The authors use a few simple ideas. Think of an AI’s memory like a school binder full of organized notes.
Key ideas
- Mindscape: This is the AI’s organized memory space for a source (like a series of books). It can include:
- fine details (passages/chunks),
- higher‑level summaries (like “chapter summaries” or “topic summaries”),
- and other structured notes (entities, events, etc.).
- Activation: When you ask a question, lots of related parts of the binder “light up.” Not just one paragraph, but a whole region of related notes becomes relevant.
- MiA‑Signature: Instead of trying to list everything that lit up, the system picks a small set of high‑level summaries that together cover the important region. This “signature” is a compact, query‑specific guide that says, “These are the main areas you should pay attention to.”
Building the signature (plain analogy)
Imagine you need to study for a test covering five different topics spread across a thick binder. You can’t carry every page, so you choose a handful of summary cards that together cover all the key topics without repeating. The paper does something similar using a math method that prefers:
- high relevance to the question,
- broad coverage (not missing parts of the “lit up” region),
- low redundancy (not picking five cards that all say the same thing).
This selection method is sometimes called “submodular selection,” but you can think of it as a smart greedy pick of a small, diverse, useful set.
Using the signature in two types of systems
- Static RAG (one‑shot):
- Step 1: Do a quick, broad search to see what’s likely relevant, then build the MiA‑Signature from high‑level summaries.
- Step 2: Use the signature to guide a second, better search for the exact passages to feed into the model that writes the answer.
- Optionally, also give the signature itself to the answer‑writing model as a global hint.
- Agent (multi‑step reasoning):
- Start with an initial MiA‑Signature.
- At each step, the agent:
- retrieves new evidence using both the current question and the current signature,
- updates its working notes (things it has already figured out),
- refines the signature to reflect what it has learned.
- After a few steps, it answers using the retrieved passages, and possibly the final signature and working notes.
In short: the signature guides search at a global level; the retrieved chunks provide the concrete details.
What did they find, and why does it matter?
Across several long‑context tasks (multiple‑choice over detective novels, open‑ended questions about stories, multi‑hop reasoning over novels, and claim checking), the MiA‑Signature:
- Helped find better evidence: Retrieval improved when the system was guided by the signature, not just the question alone. This mattered most when answers depended on spread‑out information (characters, events, and clues across a series).
- Worked in both setups: It improved static RAG and also helped multi‑step agents stay focused on the right “region” of memory across steps (preventing the search from drifting too narrowly).
- Was most reliable for search: Using the signature to guide retrieval gave consistent gains. Using it during answer writing helped sometimes—but not always—because if the needed evidence is already in the retrieved chunks, extra global context can be distracting.
Why this matters: Long texts are hard for AI because relevant information is scattered. A small, well‑chosen global hint—MiA‑Signature—helps the system search smarter and stay oriented, making answers more accurate and robust.
What’s the bigger impact?
- Better long‑context understanding: Systems can handle long books, series, or large memory collections more efficiently by carrying a compact “global compass” alongside detailed evidence.
- A brain‑inspired design: The method echoes how people use a big, mostly unconscious activation of memory but rely on a smaller, usable sketch to guide thinking.
- Practical upgrades for many tools: The same idea plugs into classic RAG and newer agent systems, improving retrieval and making multi‑step reasoning more stable.
- Efficient memory use: Even if the memory store is huge and repetitive, the signature picks just enough high‑level concepts to cover what matters, saving computation and attention.
In simple terms: MiA‑Signature gives AI a pocket‑sized map of what’s important before it dives into the details—making it better at finding the right information in very long contexts and more reliable when reasoning step by step.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research:
- Formalization of activation: The activation function a_q(m) is conceptually introduced but not operationally specified; provide a concrete algorithm (features, model, supervision) for estimating a_q beyond proxy retrieval scores.
- Objective clarity and guarantees: The submodular objective F(·) is deferred to the appendix; state its exact form in main text and analyze properties (monotonicity, submodularity), approximation guarantees, and conditions under which greedy is near-optimal.
- Sensitivity to hyperparameters: No systematic analysis of α, K0, signature size Ksum, window size W, and step budget N_stop; quantify performance–cost tradeoffs and robustness across tasks.
- Initialization dependence: Assess failure and recovery when step-0 retrieval misses the relevant region (cold-start error); test strategies like broader initial recall, diversified seeds, or back-off rescoring.
- Scalability and efficiency: Report and compare latency, GPU/CPU memory, and cost per query for each stage (mindscape construction, submodular selection, iterative retrieval), and benchmark against simply increasing retrieval K.
- Overcomplete memory evaluation: Although motivated, the system is not evaluated on truly overcomplete, consolidated memory; construct and test on large redundant memory pools to validate claimed benefits.
- Mindscape construction alternatives: Compare simple window summaries to structured mindscapes (entity/event graphs, hierarchies like RAPTOR, knowledge graphs) to test whether concept granularity improves signature quality.
- Concept unit selection: Explore concept extraction (entities, relations, events, topics) as high-level units versus sliding-window summaries; measure coverage and redundancy reduction impact.
- Learning the selector: Replace hand-crafted F(·) with a learned scoring function (e.g., contrastive, RL, or differentiable submodular surrogates) and evaluate generalization and data efficiency.
- Dynamic α and K: Investigate adaptive control of α (signature strength) and signature size K across steps and queries (e.g., learned schedules, uncertainty-aware tuning).
- Iterative update mechanism: Specify and ablate the state-update model M_upd (objective, training data, prompting); disentangle contributions of query rewriting, signature refinement, and evidence memory updates.
- Convergence and drift: Analyze stability of iterative signature updates (oscillation, drift, forgetting) and design principled stopping criteria (learned halting, uncertainty thresholds).
- Generator integration of signatures: Provide a principled method to feed signatures to LLMs (prefix-tuning, adapters, control tokens) and identify when it helps vs distracts; compare to simply giving more retrieved chunks.
- Evaluation beyond R@10: Devise metrics for “global activation coverage” (e.g., alignment to gold entities/events/evidence sets) to directly measure how well signatures approximate the activated region.
- Human and causal evaluation: Include human studies for coherence/faithfulness and causal ablations to test whether gains come from diversity, coverage, or reweighting (e.g., controlled oracle/distractor setups).
- Hallucination and calibration: Measure how signatures affect hallucination rates, factuality, and confidence calibration under noisy or conflicting memory.
- Robustness to noise/adversaries: Stress-test with noisy, contradictory, or adversarial memory items; measure brittleness and propose robust objectives or regularization.
- Multilingual and cross-lingual settings: Evaluate with cross-lingual queries/documents (beyond EN/ZH novels) and test language-specific mindscape construction and signature transfer.
- Non-text modalities: Extend mindscapes to tables, code, images, and multimodal sources; test whether signatures generalize across modality boundaries.
- Domain generalization: Validate on non-narrative, knowledge-intensive domains (scientific papers, software repos, legal contracts) where “global activation” may differ.
- Comparison to strong baselines: Run controlled comparisons against hierarchical retrievers (e.g., RAPTOR), graph retrievers (HippoRAG), long-context LMs (1M-token windows), and simple global summaries appended to queries.
- Fairness of retriever comparisons: Detail training data and objectives for MiA-Emb/MiA-Gen vs Qwen baselines; control for parameter counts, domain match, and data leakage.
- Oracle upper bounds: Include oracle-signature experiments (e.g., signature from gold evidence or gold entities) to quantify headroom and identify bottlenecks (retrieval vs generation vs signature quality).
- Online/streaming corpora: Study how to maintain and update mindscapes/signatures under streaming data and evolving memory (incremental summaries, consolidation).
- Cost-aware design: Compare end-to-end cost-effectiveness (compute, latency, $) of MiA-Signature vs alternative strategies (more hops, larger K, larger contexts).
- Step budget scaling: Evaluate performance as a function of agent step budget (>3) and propose adaptive step-allocation policies.
- Privacy and safety: Analyze whether signatures risk leaking sensitive global context and design privacy-preserving or filtered signature construction.
- Reproducibility: Release code, mindscape construction scripts, and series-book aggregation; quantify variance due to nondeterministic GPT-4o summaries and provide seeds/deterministic alternatives.
- Failure analysis: Provide systematic error typology (missed regions, over-broad signatures, distraction at generation) and targeted fixes (e.g., sparsity penalties, contrastive negatives).
- Cognitive grounding: Empirically test hypotheses inspired by global ignition (e.g., interventions that simulate partial awareness) and quantify correspondence between cognitive constructs and model behaviors.
- Integration with long-context LMs: Study complementarity of signatures with extended-context transformers (e.g., as priors to focus attention or as memory tokens), not just retrieval pipelines.
- Tool-use and planning agents: Evaluate whether signatures improve tool selection, browsing/search planning, and multi-tool coordination beyond QA-style tasks.
Practical Applications
Below is a structured mapping from the paper’s findings to practical applications across sectors. Each item names the use case, explains how MiA-Signature would be used, proposes tools/workflows, and notes assumptions or dependencies.
Immediate Applications
- Enterprise knowledge assistants for sprawling document bases (Software/Enterprise)
- Use: Build a “mindscape” of wikis, tickets, emails, and docs; use MiA-Signature to condition retrieval and generation so assistants answer with both local evidence and a global organizational context.
- Tools/Workflows: Mindscape builder that summarizes source-order windows; submodular selection to create signatures; signature-aware retriever plug-ins for vector DBs (e.g., Milvus/Weaviate/Pinecone); adapters for RAG frameworks (LangChain/LlamaIndex).
- Assumptions/Dependencies: High-quality offline summaries; availability of a signature-aware retriever (or fine-tuning to emulate it); permissions/PII controls for aggregated corpora.
- Customer support agents spanning KBs and historical tickets (Customer Support/CRM)
- Use: MiA-Signature captures global problem themes (e.g., known outages, past resolutions) while retrieving local troubleshooting steps.
- Tools/Workflows: CRM integration to construct per-product mindscapes; step-0 retrieval + submodular selection; iterative refinement in multi-turn chats.
- Assumptions/Dependencies: Unified ticket schemas; robust deduplication across redundant KB content.
- Legal e-discovery and case research (Legal)
- Use: Condition retrieval with signatures that represent relevant doctrines, precedents, and fact patterns across long case files and statutes.
- Tools/Workflows: Jurisprudence mindscape built from case law and memos; signature-conditioned search; evidence memory to track citations; generation with signature when drafting memos.
- Assumptions/Dependencies: Accurate legal summarization; up-to-date corpora; confidentiality controls.
- Literature review and systematic evidence synthesis (Academia/Pharma/Policy)
- Use: MiA-Signature spans concept clusters (methods, outcomes, populations) across thousands of papers; retrieval focuses on locally relevant evidence while preserving global research context.
- Tools/Workflows: Domain mindscapes (e.g., PubMed/arXiv); submodular concept coverage; agent loop to refine signatures as new papers are found.
- Assumptions/Dependencies: Domain-tuned summarization; handling of multi-hop chains (where global signatures help but don’t replace explicit reasoning).
- Longitudinal EHR search for clinical question answering (Healthcare)
- Use: Signatures represent a patient’s global clinical context (comorbidities, meds, prior events) guiding retrieval from long histories for differential diagnosis or chart review.
- Tools/Workflows: EHR window summaries; signature-aware retrieval; evidence memory tracks grounded facts; optional signature exposure during generation for global constraints.
- Assumptions/Dependencies: HIPAA-compliant pipelines; medical-grade summarization; clinical validation; integration with EHR systems.
- Regulatory and policy Q&A across evolving rule sets (Policy/Compliance)
- Use: MiA-Signature captures a compact global view of applicable rules/interpretations; retrieval fetches precise clauses and enforcement actions.
- Tools/Workflows: Regulatory mindscapes (laws, guidance, enforcement notices); dual-signal retrieval; agentic refinement as policies change.
- Assumptions/Dependencies: Frequent refresh of sources; jurisdiction-aware indexing.
- Codebase and design reasoning in large monorepos (Software Engineering)
- Use: Mindscapes over code modules and design docs; signatures identify globally relevant subsystems and architectural constraints; retrieval surfaces exact APIs and files.
- Tools/Workflows: Code/window summaries (e.g., per directory/class); signature-conditioned search; agent loop for multi-step refactoring or debugging.
- Assumptions/Dependencies: Code summarization quality; alignment of summaries with code evolution (CI/CD hooks).
- Project/meeting memory assistants (Workplace Productivity)
- Use: Signatures summarize project-wide context (decisions, risks, owners), guiding retrieval from notes/transcripts for updates or action items.
- Tools/Workflows: Automatic meeting/window summaries; signature-aware retrieval during prep and follow-ups; evidence memory for commitments.
- Assumptions/Dependencies: Reliable ASR and diarization; access control across teams.
- Financial research and due diligence (Finance)
- Use: Global activation signatures over filings, earnings calls, and news to contextualize company/sector themes; retrieval for precise figures and disclosures.
- Tools/Workflows: Financial mindscapes; step-0 submodular signature creation; iterative refinement for multi-entity analyses; generator optionally conditioned on signature for holistic summaries.
- Assumptions/Dependencies: Timely ingestion; hallucination controls; domain-tested prompts.
- Incident response and root cause analysis across logs (Security/IT Ops)
- Use: Signatures represent global incident context (hosts, services, known patterns) while retrieval pinpoints precise log lines and alerts.
- Tools/Workflows: Log mindscapes (windowed summaries); query–signature retrieval; evidence memory for verified indicators and timelines.
- Assumptions/Dependencies: Summarization for semi-structured logs; noise handling; data retention/PII policies.
Long-Term Applications
- Multimodal mindscapes for robotics and AR assistants (Robotics/AR)
- Use: Extend signatures to capture global activation across video, sensor streams, and maps for long-horizon tasks; retrieval fetches frames/landmarks with local relevance.
- Tools/Workflows: Multimodal summarizers; signature-aware retrievers over embeddings unified across modalities; agentic refinement during task execution.
- Assumptions/Dependencies: Reliable multimodal embeddings; grounding and real-time constraints.
- Continual clinical decision support with evolving patient trajectory signatures (Healthcare)
- Use: Online signature updates as new labs/notes arrive; guide retrieval and alerting for trajectory-aware care planning.
- Tools/Workflows: Streaming mindscape updates; safety guardrails; integration with CDS systems.
- Assumptions/Dependencies: Regulatory approval; rigorous evaluation for safety and bias.
- Autonomous research agents with co-evolving signatures and searches (Academia/Industry R&D)
- Use: Agents maintain a global hypothesis space (signature) while iteratively retrieving, critiquing, and refining evidence and queries.
- Tools/Workflows: RL/feedback-driven update policies; integrated search and memory controllers; provenance-aware evidence memory.
- Assumptions/Dependencies: Stable update policies; robust critique mechanisms; compute cost controls.
- Data governance and retrieval across enterprise data lakes (Enterprise/Data Platforms)
- Use: Signatures summarize global schema and data lineage to steer retrieval from tables, notebooks, dashboards.
- Tools/Workflows: Catalog-aware mindscapes; table/column/window summaries; signature-conditioned cross-source queries.
- Assumptions/Dependencies: Quality metadata; tabular summarization methods; privacy-by-design.
- Streaming compliance monitoring and risk detection (Finance/Policy)
- Use: Real-time signature updates capturing global risk posture; retrieval for specific events/transactions driving alerts and explanations.
- Tools/Workflows: Low-latency mindscape maintenance; dual-signal retrieval in streaming; explainability artifacts tied to evidence memory.
- Assumptions/Dependencies: Event-time processing; audit trails; low false-positive tolerance.
- Personal “second brain” with on-device mindscapes (Consumer Productivity/Privacy)
- Use: Private, on-device signatures spanning emails, notes, and files; retrieval fetches precise items while preserving a holistic personal context.
- Tools/Workflows: Local summarization; compact signature stores; offline-first RAG/agent runtimes.
- Assumptions/Dependencies: On-device models; storage/compute budgets; strong privacy guarantees.
- Energy and industrial operations log analysis (Energy/Manufacturing)
- Use: Signatures encode global system states (maintenance cycles, seasonal loads); retrieval pulls specific sensor records for anomaly and RCA.
- Tools/Workflows: Time-windowed plant/grid summaries; signature-aware retrieval; operator-in-the-loop agents.
- Assumptions/Dependencies: Domain-tuned summarization; integration with SCADA/Historians; safety review.
- Cross-lingual organizational assistants (Multilingual Enterprises/Government)
- Use: Signatures represent global activation across languages, improving retrieval and synthesis in multilingual corpora.
- Tools/Workflows: Multilingual mindscape construction; cross-lingual signature-aware embeddings; dynamic updates as translations arrive.
- Assumptions/Dependencies: High-quality multilingual embeddings; nuanced handling of locale-specific policies.
- Architecting models that internalize signature conditioning (ML Systems)
- Use: Train/fine-tune LLMs and retrievers to natively accept and exploit compact global states (signatures) as inputs or latent variables.
- Tools/Workflows: Pretraining objectives for global-state conditioning; adapters for signature tokens; evaluation suites for long-context coherence.
- Assumptions/Dependencies: Dataset availability for supervision; stability of training; generalization across domains.
Notes on feasibility and generalization:
- The paper’s gains are strongest in long textual narratives; domains with dense multi-hop reasoning may still need explicit chain construction alongside signatures.
- Quality and neutrality of high-level summaries are pivotal; poor summarization can misguide signatures.
- Privacy, compliance, and data freshness must be addressed when constructing mindscapes.
- Benefits accrue even without changing generators (retrieval-side improvements), but generator-side gains depend on models that can leverage global conditioning.
Glossary
- Agentic systems: Multi-step LLM-based systems that maintain and update internal state while acting (e.g., retrieve, plan, generate) over iterations. "Integrating MiA-Signatures into both RAG and agentic systems yields consistent performance gains across multiple long-context understanding tasks."
- CLS embeddings: Vector representations derived from the [CLS] token of a transformer, often used as sentence-level embeddings for scoring or retrieval. "scores all three terms with BGE-M3 CLS embeddings"
- claim verification: An NLP task that assesses whether a given claim is supported, refuted, or unverifiable based on evidence. "and claim verification."
- coarser-grained projection: A mapping from fine-grained items to more abstract, aggregated units to reduce detail and redundancy. "obtained as a coarser-grained projection of ."
- coverage-aware objective: A set-selection objective that balances relevance and diversity to cover a target region while reducing redundancy. "We instead select the initial signature with a coverage-aware objective:"
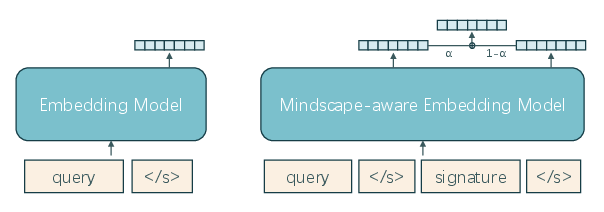
- dual-signal retrieval score: A retrieval scoring scheme that combines query relevance and a global conditioning signal (e.g., a signature) with a tunable weight. "The dual-signal retrieval score uses to balance query relevance and signature consistency."
- evidence memory: A working store of grounded facts accumulated during iterative reasoning to maintain continuity across steps. "the evidence memory stores grounded facts accumulated so far"
- First- truncation: An initialization heuristic that deduplicates and keeps the first K items from a ranked list without explicit coverage modeling. "A simple way to construct the initial signature is First- truncation: deduplicate the summaries according to the ranking induced by the step-$0$ retrieval and keep the first $K_{\mathrm{sum}$."
- global activation: A broad, distributed pattern of relevance or neural-like activation over a memory or semantic space induced by a query. "a compressed representation of the global activation pattern induced by a query."
- Global Neuronal Workspace (GNW) theory: A neurocognitive framework positing that conscious access arises from large-scale, recurrent neuronal broadcasting (global ignition). "the Global Neuronal Workspace (GNW) theory"
- Global Workspace Theory (GWT): A cognitive theory proposing that information becomes consciously accessible when it is globally broadcast to distributed modules. "originates from the Global Workspace Theory (GWT)"
- graph-based memory index: A retrieval structure where memory items are nodes linked by semantic relations to support structured search. "builds a graph-based memory index inspired by hippocampal retrieval."
- greedy approximation: A heuristic optimization approach that iteratively adds the locally best item to approximate a combinatorial objective. "We optimize this set-selection objective with a greedy approximation."
- hierarchy of recursive summaries: A multi-level structure where documents are summarized recursively to create coarse-to-fine retrieval units. "organizes documents into a hierarchy of recursive summaries"
- high-level memory units: Coarser memory abstractions (e.g., session summaries or concepts) derived from fine-grained evidence to support global reasoning. "denote a set of high-level memory units---e.g., session summaries or concept-level abstractions"
- Integrated Information Theory (IIT): A theory of consciousness emphasizing that conscious states reflect highly integrated, structured information. "Integrated Information Theory (IIT)"
- long-context agents: Agents designed to read, navigate, and reason over very long inputs using explicit memory and iterative strategies. "Recent long-context agents go further by equipping the model with explicit memory states"
- mindscape: An organized, global semantic memory space associated with a source, over which activation and retrieval are defined. "we introduce the notion of a mindscape, a global semantic memory space over which activation can be defined."
- Mindscape Activation Signature (MiA-Signature): A compact, query-conditioned representation that approximates the globally activated region of a mindscape. "Mindscape Activation Signature (MiA-Signature), a compressed representation of the global activation pattern induced by a query."
- mindscape-aware generator: A generator that can consume a global memory signal (e.g., a signature) in addition to local evidence during answer generation. "or for a smaller mindscape-aware generator trained for this interface, such as MiA-Gen-14B"
- mindscape-aware retriever: A retriever whose query representation is conditioned on both the current query and a global memory signal (signature). "The second, , is a mindscape-aware retriever"
- multi-hop QA: Question answering requiring the composition of multiple pieces of evidence across steps or documents. "multi-hop QA"
- overcomplete memory: A memory pool containing more items than the raw inputs, often with redundancy due to consolidation or abstraction. "MiA-Signatures naturally cooperate with such overcomplete memory."
- pair accuracy: An evaluation metric that jointly assesses correctness across paired items (e.g., main and auxiliary labels) for tasks like claim verification. "and accuracy together with pair accuracy for NoCha."
- parametric knowledge: Knowledge encoded within a model’s parameters (as opposed to retrieved externally). "by combining parametric knowledge with external memory."
- query-conditioned global state: A global memory signal derived from a query that conditions downstream retrieval and reasoning. "A MiA-Signature is a compact, query-conditioned global state that approximates the memory region activated by a query"
- query-only retriever: A retriever that encodes and searches using only the input query, without additional global signals. "The first, , is a query-only retriever"
- query rewriting: The process of transforming the current query during iterative search to refine or redirect retrieval focus. "studies query rewriting in the agent loop."
- Recall@10: A retrieval metric measuring whether relevant items appear within the top 10 results. "We also report Recall@10 when gold evidence annotations are available."
- Recurrent Processing Theory (RPT): A theory distinguishing local recurrent processing from global broadcasting, implying partial accessibility of activated representations. "Recurrent Processing Theory (RPT)~\cite{lamme2006towards} distinguishes between local recurrent processing and global broadcasting"
- Retrieval-augmented generation (RAG): Systems that retrieve external evidence to augment LLM generation for knowledge-intensive tasks. "retrieval-augmented generation (RAG) pipelines"
- rerankers: Components that reorder retrieved candidates using additional signals or models to improve evidence selection. "such as retrievers, rerankers, or reasoning modules"
- semantic memory space: A structured space of memory representations organized by meaning, over which activation and coverage are defined. "a global semantic memory space over which activation can be defined."
- series-book construction: Dataset preparation where multiple books from a series are merged into a single long source to increase retrieval difficulty. "we adopt a series-book construction."
- sleep-time consolidation: Offline processes that transform and summarize raw inputs into more stable memory items, potentially increasing redundancy. "e.g., generated by sleep-time consolidation"
- state-update model: The component that updates the agent’s state (decision, next query, signature, and evidence memory) after each retrieval step. "The state-update model then updates the agent state:"
- submodular-based selection: A set-selection approach leveraging submodular objectives to balance relevance, coverage, and diversity efficiently. "submodular-based selection of high-level concepts"
- surrogate: A compact stand-in representation used to approximate a more complex or inaccessible signal (e.g., global activation). "the MiA-Signature as a compact surrogate of that activation"
- top-K retrieval: A retrieval strategy that returns the K highest-scoring candidates according to a ranking function. "we retrieve the top- candidates with ."
- working memory: A transient memory used during iterative reasoning to refine representations or guide subsequent steps. "optionally refined through lightweight iterative updates using working memory."
Collections
Sign up for free to add this paper to one or more collections.

