- The paper presents a stochastic adjoint sensitivity method that extends gradient computation to SDEs using a backward Stratonovich formulation.
- It introduces a virtual Brownian tree to evaluate intermediate values efficiently, ensuring constant memory overhead during backward simulation.
- The approach achieves competitive performance on latent SDE models and real datasets, facilitating scalable Bayesian learning and time series modeling.
Scalable Gradients for Stochastic Differential Equations
Introduction
The paper "Scalable Gradients for Stochastic Differential Equations" proposes a method to efficiently compute gradients for stochastic differential equations (SDEs) by extending the adjoint sensitivity method, traditionally used for ordinary differential equations (ODEs), to SDEs. This work addresses challenges in both mathematical formulation and computational implementation to enable scalable and memory-efficient gradient computations. The proposed approach, termed the stochastic adjoint sensitivity method, is noteworthy for allowing the use of high-order adaptive solvers in SDEs while maintaining constant memory overhead.
The stochastic adjoint sensitivity method derives a backward SDE from the original forward SDE. The primary mathematical challenge is how stochastic calculus, particularly the Itô and Stratonovich integrals, can be adapted to allow running the SDE backwards in time. The paper demonstrates that the backward dynamics can be expressed as a Stratonovich SDE by negating the drift and diffusion functions. This approach ensures the correct reconstruction of the forward path when simulated backwards, as depicted in Figure 1.
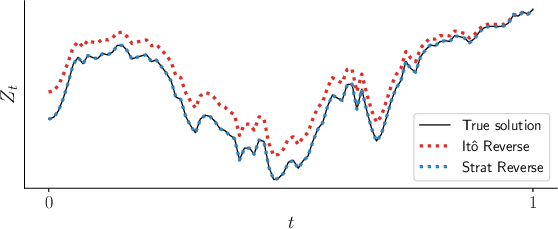
Figure 1: Negating the drift and diffusion functions for an Itô SDE and simulating backwards from the end state gives the wrong reconstruction. Negating the drift and diffusion functions for the converted Stratonovich SDE gives the same path when simulated backwards.
Numerical Computation
For practical implementation, the concept of a virtual Brownian tree is introduced to manage stochastic processes running forward and backward in time without storing large amounts of Brownian motion data. This algorithm utilizes Brownian bridges to efficiently compute intermediate values in a path while maintaining a low memory footprint.
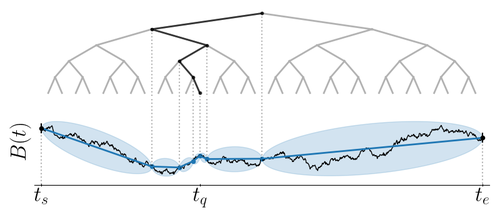
Figure 2: Evaluating a Brownian motion sample at time tq using a virtual Brownian tree. Our algorithm repeatedly bisects the interval, sampling from a Brownian bridge at each halving to determine intermediate values. Each call to the random number generator uses a unique key whose value depends on the path taken to reach it.
Latent SDE Models
The paper also demonstrates the application of the stochastic adjoint method combined with stochastic variational inference for fitting latent SDE models. The examples include synthetic datasets, such as the Lorenz attractor, showing the model's capability to learn complex, multimodal, and stochastic dynamics. This model is capable of handling irregularly-sampled time series with missing data, offering a significant advantage over traditional state-space and deep learning models.
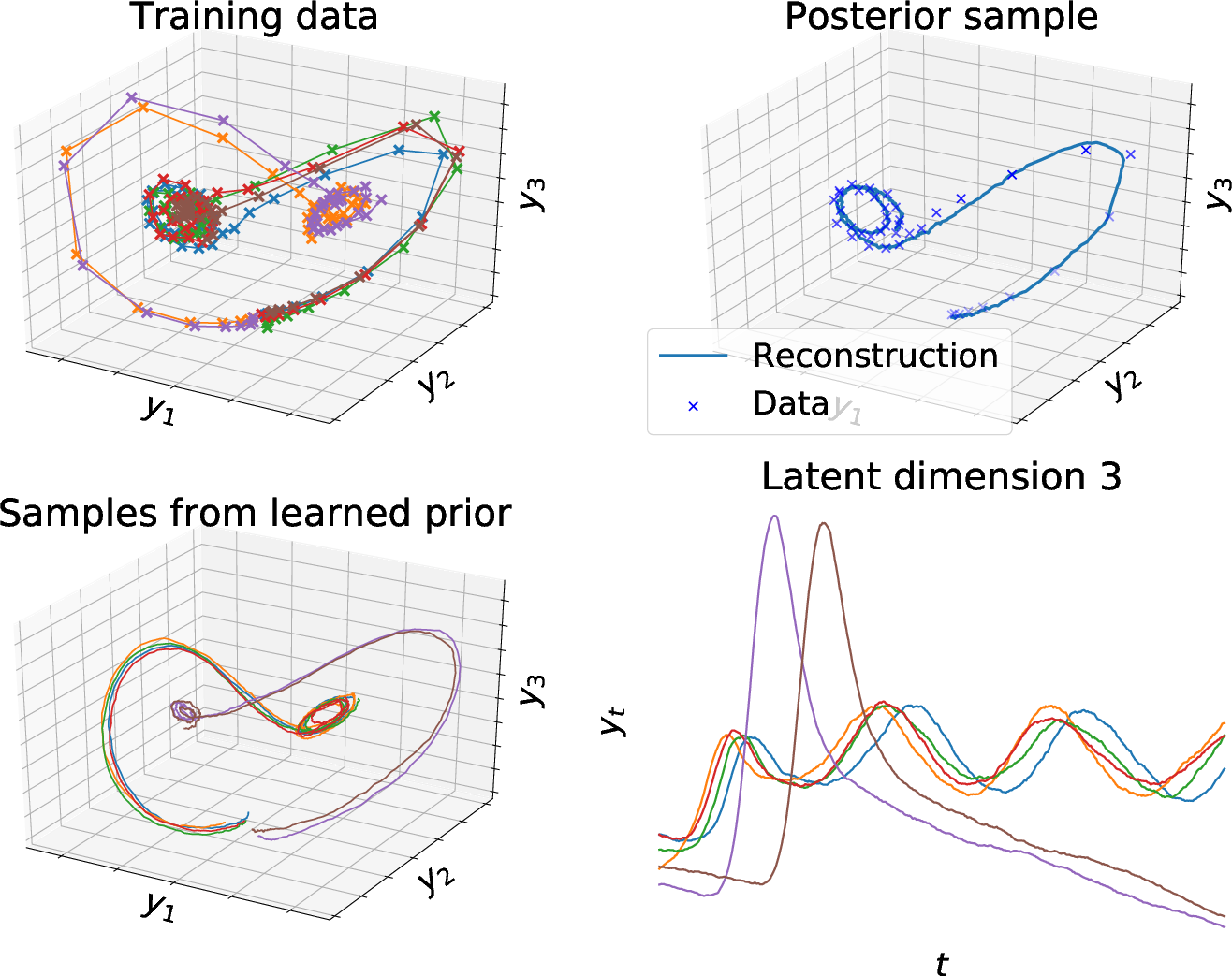
Figure 3: Learned posterior and prior dynamics on data from a stochastic Lorenz attractor. All samples from our model are continuous-time paths, and form a multi-modal, non-Gaussian distribution.
Implementation and Results
The algorithm is implemented using PyTorch, integrating with modern automatic differentiation libraries for scalability and ease of use. The virtual Brownian tree is crucial for reducing memory requirements, particularly in applications like motion capture data, where large state dimensions are common. The results on a motion capture dataset show competitive performance against existing models, highlighted by improved performance metrics.
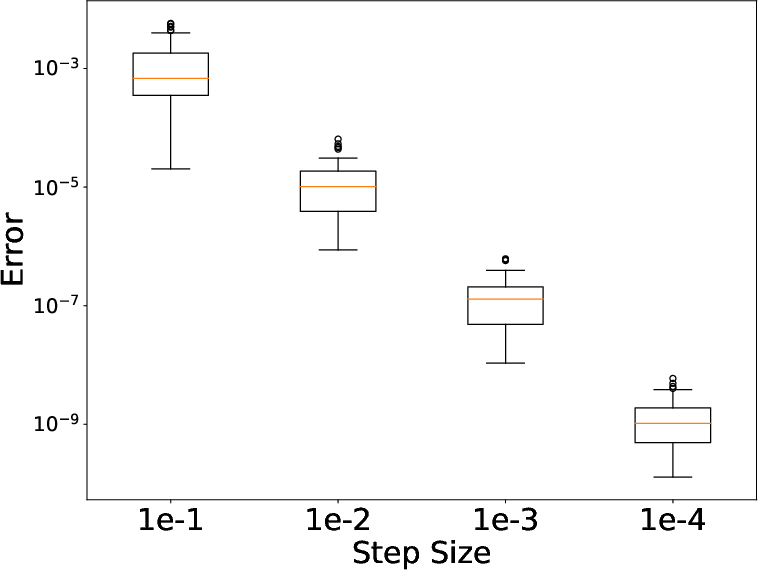
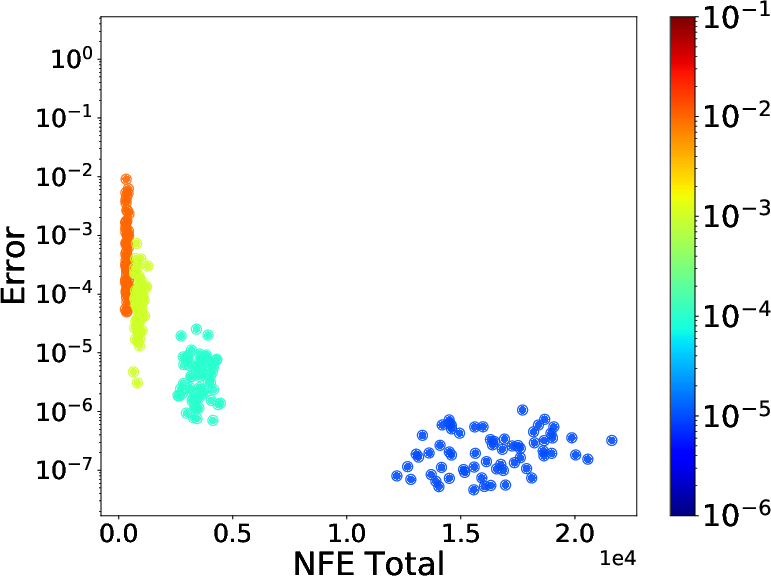
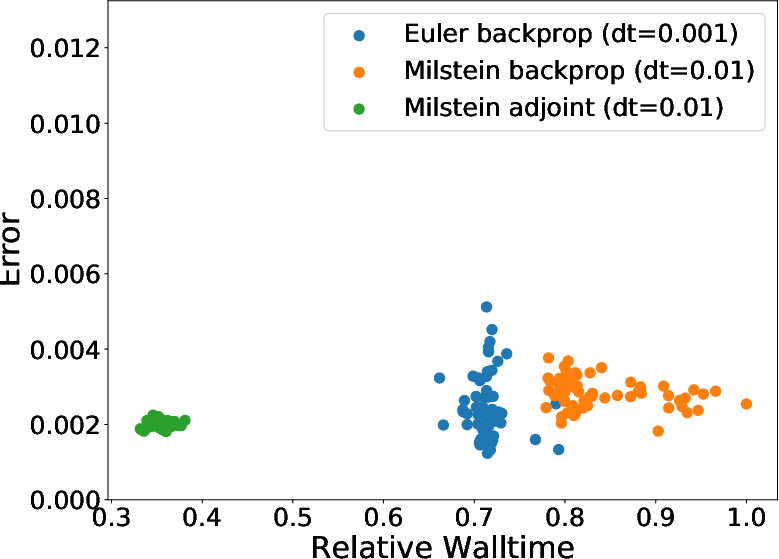
Figure 4: (a) Same fixed step size used in both forward and reverse simulation. Boxplot generated by repeating the experiment with different Brownian motion sample paths 64 times. (b) Colors of dots represent tolerance levels and correspond to the colorbar on the right. Only atol was varied and rtol was set to 0.
Conclusion
The stochastic adjoint sensitivity method introduced in this paper effectively extends the applicability of adjoint methods to SDEs, thereby facilitating efficient gradient computation for systems defined by such equations. This enables a range of applications, including Bayesian learning with SDEs and modeling high-dimensional time series data. The work opens avenues for future exploration into high-order numerical schemes and alternative inference techniques that may further enhance the robustness and applicability of SDE models in practice.

