- The paper introduces ConvRec, a hierarchical convolution model that efficiently aggregates item interactions and attributes for sequential recommendation.
- It employs pyramidal convolution with residual connections to capture both local and global sequence patterns while mitigating quadratic scaling.
- Experimental results demonstrate ConvRec outperforms attention-based models with improvements in HR@10 and NDCG@10 across diverse datasets.
Rethinking Convolutional Networks for Attribute-Aware Sequential Recommendation
Introduction
This paper addresses the computational and modeling bottlenecks in attribute-aware sequential recommendation, a setting where the goal is to predict a user's next interaction based on temporally ordered historical actions enriched with item and context attributes. The majority of state-of-the-art methods in this domain leverage self-attention (Transformer-style) architectures for their global receptive field and parallelization capabilities. However, self-attention incurs quadratic complexity in both time and memory with the sequence length, severely constraining scalability and impeding exhaustive modeling of long user histories.
The authors introduce ConvRec, a hierarchical convolutional framework that constructs sequence representations by progressively aggregating user-item interactions and associated attributes via a sequence of convolutional down-scaling operations. Unlike prior CNN-based models with strictly local receptive fields, ConvRec employs pyramidal stacking of convolutional layers, growing the receptive field at each stage and ultimately compressing the entire sequence to a single dense vector. This structure enables efficient global sequence modeling with memory and time costs scaling linearly with input length.
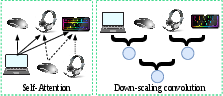
Figure 1: Illustration contrasting the receptive fields of self-attention (global all-pairs) versus hierarchical down-scaling convolution (progressive aggregation with increasing coverage).
ConvRec Architecture
ConvRec's design comprises two central innovations: an attribute-aware item encoding module and a hierarchical Convolution Down-scaling Component (CDS).
Attribute-Aware Item Encoding
Each item in a user's interaction history is represented by the concatenation of three vectors: item ID embedding (with shared embeddings for infrequent items, focusing learning capacity on frequent items), item attribute embedding (transformed via a fully connected layer), and context embedding (in this study, temporal attributes such as year, month, and day). These are combined and normalized, and the time intervals between consecutive interactions are explicitly calculated and appended to the feature sequence—acknowledging the critical role of temporal dynamics in sequential preference modeling.
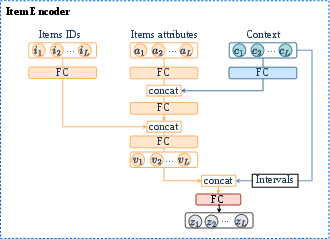
Figure 2: The item encoding module, fusing item, attribute, and context information with explicit interval calculation.
Hierarchical Down-Scaling via Convolution
Encoded item sequences are fed through a series of 1D convolutional blocks configured with increasing kernel sizes and strides. At each block, convolutions aggregate neighboring items, and strided down-sampling reduces the sequence length, progressively distilling the sequence until only a single vector remains. Each block further incorporates residual connections: one from the original input (via average pooling) and one progressive residual linking outputs from previous blocks, ensuring stable gradient propagation and retention of essential global signals.
The architecture is parameter-efficient and supports large input lengths, in contrast to the quadratic cost of attention-based architectures.
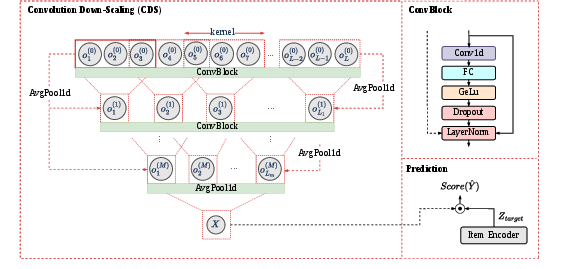
Figure 3: The ConvRec framework: attribute-aware item encoding, hierarchical convolutional downscaling, and final item ranking.
Experimental Results
ConvRec was benchmarked against both classical and contemporary state-of-the-art baselines—including BERT4Rec, SASRec, S3-Rec, SASRec++, CARCA, and ProxyRCA—across four Amazon recommendation datasets (Beauty, Games, Fashion, Men). Evaluation employed leave-one-out splits with matched negative sampling protocols.
Numerical performance highlights:
- ConvRec consistently outperforms all baselines in both HR@10 and NDCG@10 across all datasets.
- Improvements relative to the strongest attention-based model (ProxyRCA) range up to 4.08% in HR@10 and 7.82% in NDCG@10 (notably on the Fashion dataset).
- In full recall (all-item) settings on the Beauty and Games datasets, ConvRec achieves up to 3.6% higher HR@10 and 8.0% higher NDCG@10 over ProxyRCA.
Efficiency claims:
- Memory usage and training time for ConvRec increase linearly with sequence length; for ProxyRCA, both scale quadratically—demonstrated empirically up to sequence lengths of 500.
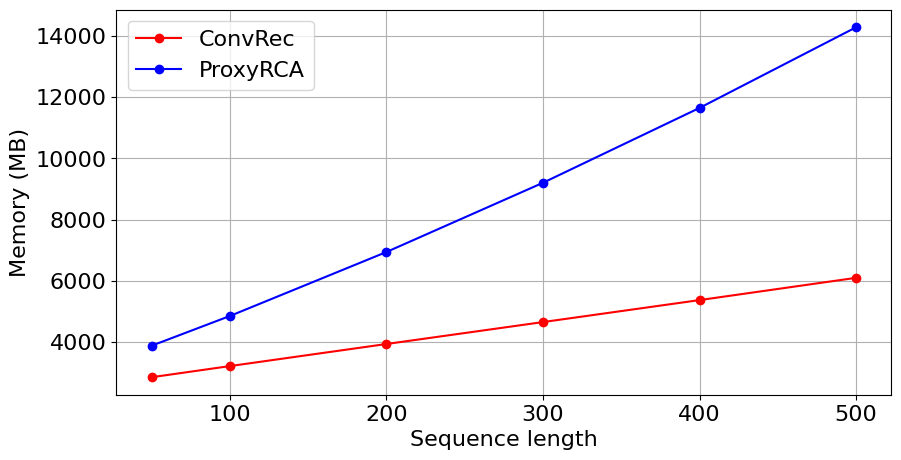
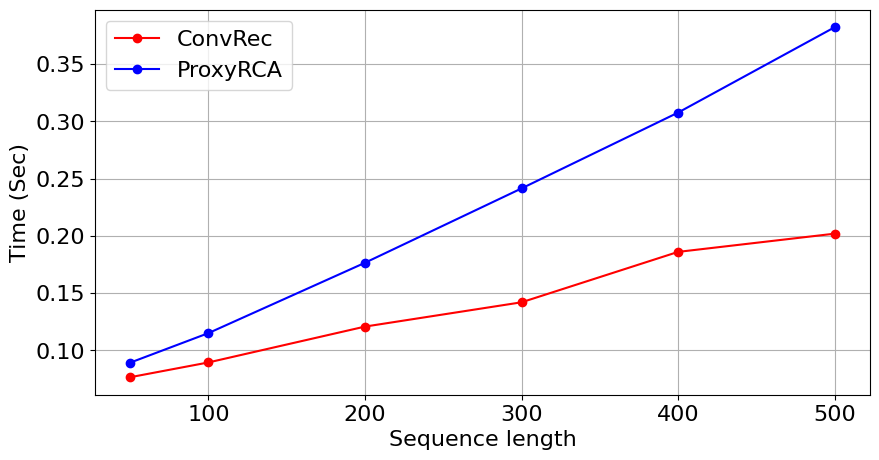
Figure 4: Memory usage and execution time of ConvRec and ProxyRCA at batch size 128; ConvRec's linear scaling offers practical benefits for long sequences.
Extensive ablations confirm the necessity of each architectural component:
- Removing time interval encoding or residual connections results in marked degradation of performance.
- Average pooling or non-hierarchical convolution drastically reduces accuracy, reaffirming the hierarchical design.
- Large kernel sizes with stride equal to kernel performed best, confirming that broader aggregation per convolutional stage is advantageous.
Hyperparameter Sensitivity and Robustness
Experiments demonstrate robust model behavior to a range of embedding dimensions (optimal at 256) and dropout rates, with diminishing returns beyond moderate embedding sizes. Convolutional kernel sizes and strides significantly affect performance, and network depth (number of ConvBlocks) is critical for capturing both local and long-range dependencies. ConvRec outperforms ProxyRCA not only on average but particularly in user groups with shorter histories, suggesting improved generalization to data regimes where attention models are most prone to overfitting or underfitting.
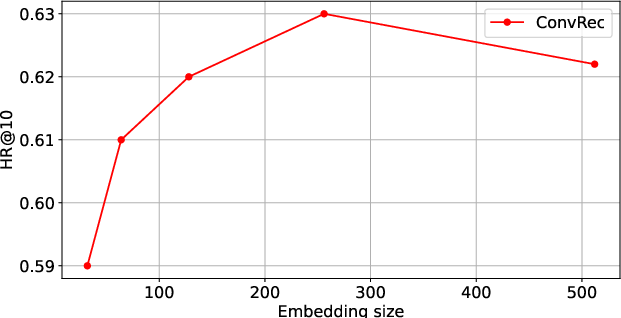
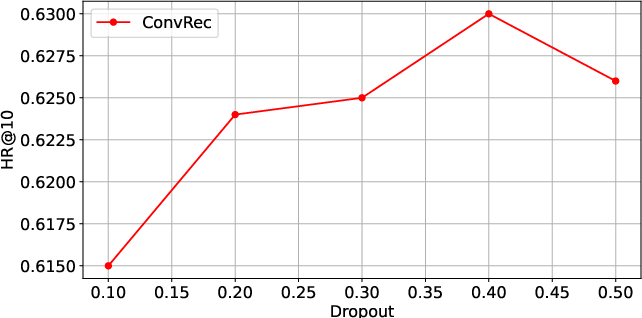
Figure 5: Effect of changing embedding size and dropout on model performance confirms the model's robustness to these hyperparameters.
Implications and Future Directions
ConvRec's hardware- and time-efficient design enables real-world deployment of attribute-aware recommendation on platforms where latency and memory are principal constraints, such as e-commerce and streaming services with long user histories. The model design offers a viable alternative to the dominant attention paradigm, especially for sequences too long to be tractably handled by self-attention. The explicit modeling of time intervals and the stratified feature aggregation method may inspire further research on efficient sequence models in related domains, including session-based recommendation, event prediction, and temporal knowledge graph reasoning.
Theoretically, ConvRec represents a step toward reconciling the locality benefits of convolutions with the necessity for global sequence summarization, leveraging progressive structural compression and strong regularization from its residual pathways. Future work could explore hybridizing convolutional and attention modules, scaling to multi-modal contexts, or integrating richer graph-relational side information.
Conclusion
ConvRec establishes a new state-of-the-art for attribute- and context-aware sequential recommendation in both accuracy and efficiency. Its linear time and memory complexity with sequence length, combined with strong empirical gains over attention-based models, highlight the under-explored potential of hierarchical convolutional architectures in sequential modeling tasks. These results challenge the prevailing reliance on self-attention and encourage further investigation of scalable alternatives in recommendation and temporal sequence modeling.
Reference: "Rethinking Convolutional Networks for Attribute-Aware Sequential Recommendation" (2605.04723)