- The paper introduces HyenaRec, adapting the Hyena operator with Legendre polynomial parameterization to tackle sparse, long user sequences.
- It employs a novel architecture integrating input embeddings, stacked Hyena Blocks, and a top-k prediction layer to fuse local and long-range dependencies.
- Experimental results show significant improvements in NDCG and Recall, with near-linear computational complexity that scales efficiently for ultra-long histories.
Hyena Operator for Fast Sequential Recommendation: Technical Summary
Motivation and Background
Sequential recommender systems must efficiently capture complex temporal dependencies in user interaction histories, especially as sequence lengths scale to hundreds or thousands of steps, often under sparse feedback regimes. Conventional approaches—Markov chains, RNNs, CNNs, and attention-based models—encounter fundamental issues such as limited receptive field, gradient bottlenecks, summary bias, or prohibitive quadratic complexity in sequence length. Recent advances in sequence modeling, particularly the Hyena operator, have demonstrated the efficacy of long convolutional filters with sub-quadratic complexity for language tasks. However, direct application of Hyena in recommendation faces challenges in sparse, non-periodic data and highly variable sequence lengths.
HyenaRec Architecture
HyenaRec adapts the Hyena operator to sequential recommendation tasks through an architecture composed of three core components: input embedding, a Hyena-based sequential backbone, and a top-k prediction layer.
The input embedding layer maps item identifiers to dense vectors and encodes position either explicitly (in attention-based backbones) or implicitly via complex exponential bases for Hyena-based backbone. This latter method ensures temporal information is consistently integrated within the convolutional kernel generation process.
The sequential backbone consists of multiple stacked Hyena Blocks—each containing a mixer layer (Hyena Operator), feed-forward MLP, residual connections, and normalization. The Hyena Operator itself comprises a short path (gated convolutions) and a long path (channel-wise depthwise convolutions parameterized by LegendreHyenaFilter), efficiently mixing both fine-grained local bursts and long-range dependencies.
Prediction is accomplished via projection from the final block's hidden states to item logits using parameter tying, followed by softmax normalization for ranking.
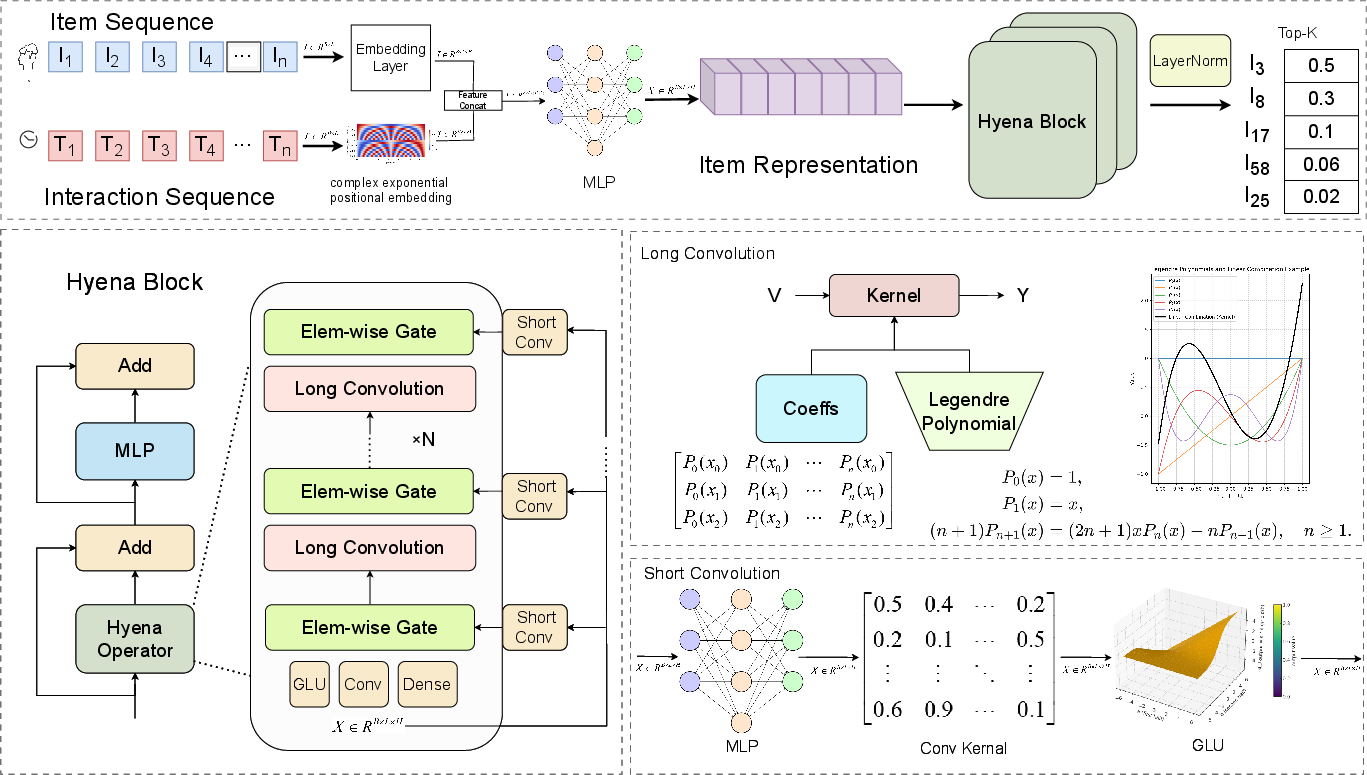
Figure 1: Overall Architecture of HyenaRec, illustrating embedding, Hyena-based sequential modeling, and top-k prediction for next-item recommendation.
LegendreHyenaFilter: Structured Parameterization of Long Convolutions
A critical innovation in HyenaRec is the LegendreHyenaFilter. Unlike prior Hyena kernels generated via implicit MLP/Fourier bases, LegendreHyenaFilter employs explicit parameterization through orthogonal Legendre polynomials. Each kernel is represented as a linear combination of K Legendre bases, ensuring smoothness, orthogonality, stable boundary behavior, and efficient computation via three-term recurrence. ℓ1-normalization per channel guarantees signal stability across stacked convolution layers.
This approach addresses the instability and overfitting issues of previous kernel generators in sparse, variable-length recommendation sequences. Empirically, the energy-based selection of K achieves a favorable trade-off; K=64 captures >95% of relevant sequence dynamics without unnecessary complexity.
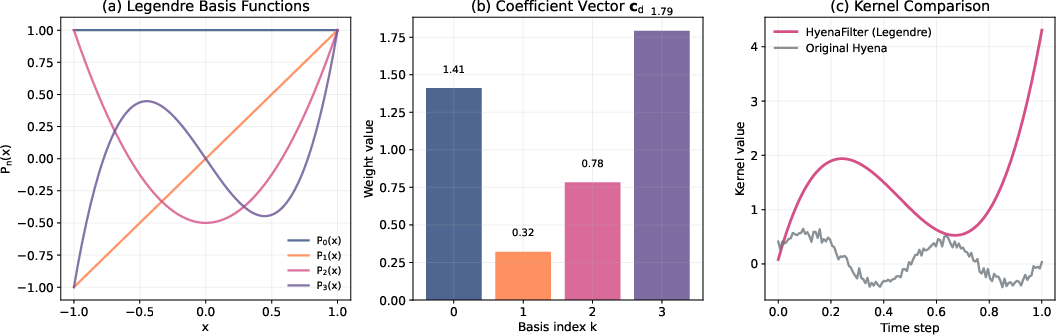
Figure 2: Visualization of the LegendreHyenaFilter: (a) Legendre polynomial basis functions; (b) channel-specific coefficient weighting; (c) comparison with original Hyena kernel—smoother and more stable for long, sparse sequences.
Experimental Results
HyenaRec was evaluated on four datasets (ML-1M, Steam, Video, XLong) spanning diverse domains and sequence characteristics. Across all metrics (NDCG@10/20, Recall@10/20), HyenaRec consistently outperformed state-of-the-art baselines including GRU4Rec, NARM, SASRec, BERT4Rec, EulerFormer, HSTU, and LRURec.
On long-sequence benchmarks (e.g., XLong), HyenaRec achieved a substantial 17.65% improvement in NDCG@10 and 13.83% in NDCG@20 relative to the strongest baseline. On short-medium sequences, advantages averaged 3–5%. The model maintained linear or near-linear computational complexity with respect to sequence length, allowing efficient scaling to ultra-long histories.
Ablation studies validated the necessity of polynomial kernel parameterization (PK), GLU gating, and the superiority of Legendre bases over Fourier or Chebyshev alternatives. Removal of any module led to significant performance degradation, especially under long or sparse sequence regimes.
Efficiency and Hyperparameter Sensitivity
HyenaRec demonstrated pronounced improvements in training efficiency: all baselines required more training time (beyond 1.6×, peaking at 4.25× for BERT4Rec). This efficiency is attributed to its convolution-based hierarchical architecture.
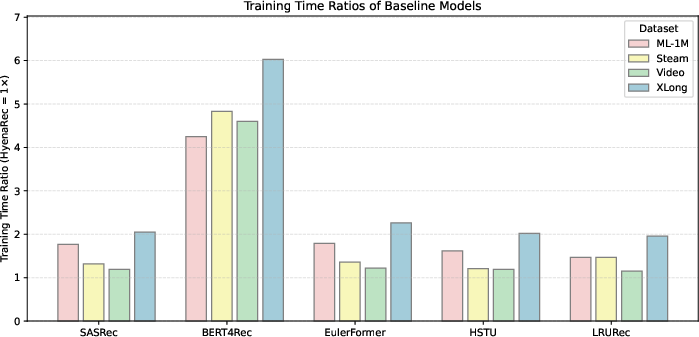
Figure 3: Training time ratios (TTR) of baseline models relative to HyenaRec, normalized to 1×.
Hyperparameter sensitivity studies showed robustness to dropout rates (optimal around 0.2) and weight decay (optimal at 10−4). Additionally, performance was stable across a range of Legendre filter orders K, peaking at K=64.
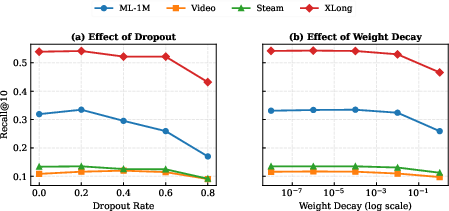
Figure 4: Hyperparameter sensitivity of HyenaRec with respect to dropout rate and weight decay.
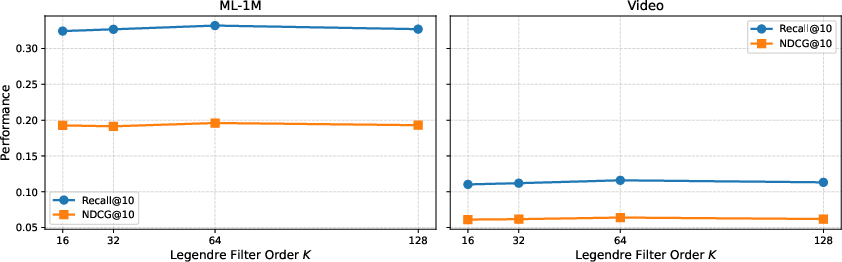
Figure 5: Performance of HyenaRec under different Legendre filter orders K, showing optimal results at K=64 for both Recall@10 and NDCG@10.
Practical and Theoretical Implications
HyenaRec establishes structured convolutional operators with orthogonal polynomial parameterization as a principled alternative to attention and recurrence for sequential recommendation. The Legendre basis not only provides numerical stability and inductive bias suitable for non-periodic, sparse user behavior but also boosts scalability. This contributes to a broader paradigm wherein highly-regularized, interpretable convolutional filters supplant expensive attention modules without loss in accuracy.
Implications for future AI developments include:
- Deployment of efficient, scalable recommenders for ultra-long and sparse histories in production.
- Transferability of polynomial-based kernel parameterization to other domains (e.g., time-series forecasting, anomaly detection).
- Potential integration with selective recurrence (e.g., Mamba4Rec) for further enhancement of expressiveness.
Conclusion
HyenaRec offers an efficient solution to long-sequence modeling in sparse recommendation scenarios, achieving superior ranking accuracy and training/inference efficiency. The structured LegendreHyenaFilter enables stable and expressive modeling of user temporal dynamics. Results indicate that polynomial kernel parameterization constitutes a scalable and robust substitute for attention mechanisms. Further research may explore broader application of structured convolutions in sequential representation learning and their integration with emerging state-space architectures.